Chaos Engineering
Introduction to Real life Application
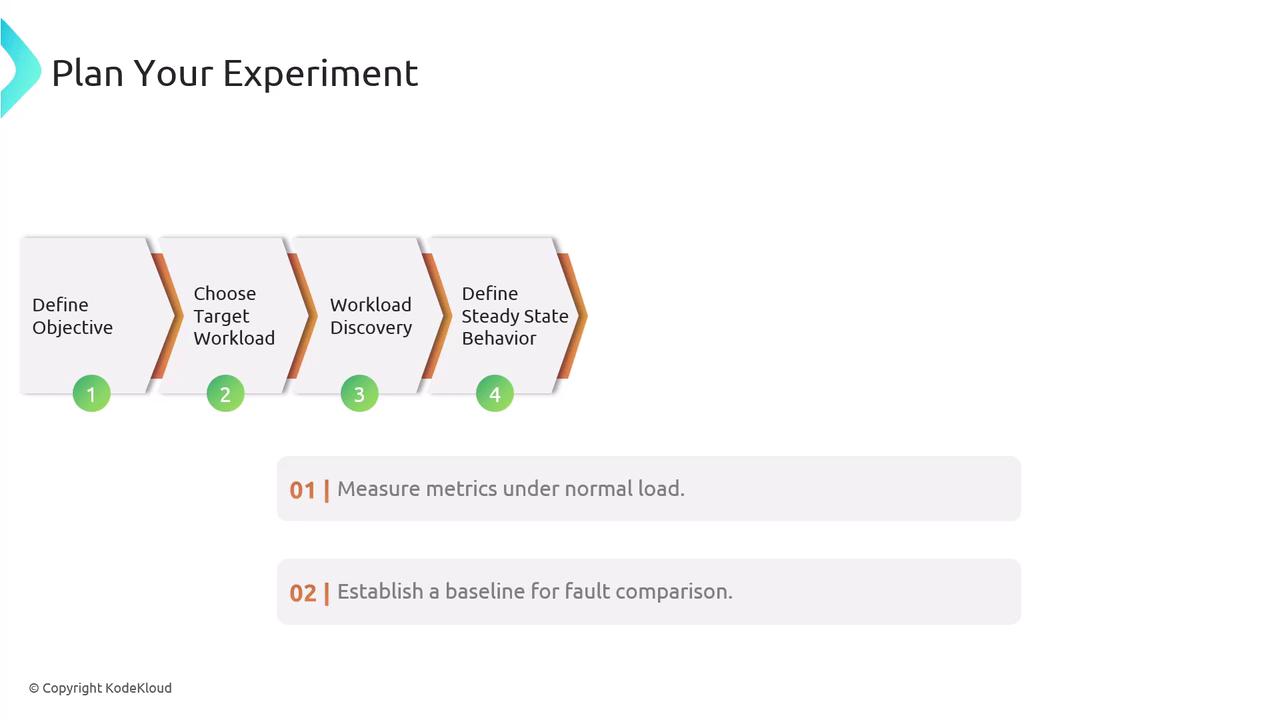
How to Plan Your Experiment Part 1
In this guide, you’ll learn how to design your first Fault Injection Simulation (FIS) experiment (a “game day”) on AWS. A methodical approach helps you uncover weaknesses and build greater system resilience.
Overview of the Four Key Steps
| Step | Activity | Outcome |
|---|---|---|
| 1 | Define Your Objective | Clear goals and success criteria |
| 2 | Choose Your Target Workload | Safe testing in dev/test before production |
| 3 | Perform Workload Discovery | Detailed architecture mapping and SLO alignment |
| 4 | Define Steady State Behavior | Baseline metrics for fault-impact comparisons |
1. Define Your Objective
Begin by asking:
- What is the purpose of this experiment?
- Which past incidents do we want to guard against?
- Are we validating that services recover from failure as expected?
Clearly documented objectives will shape the fault scenarios you select and the criteria for success.
Tip
Framing a precise objective prevents scope creep and ensures you get actionable insights from your game day.
2. Choose Your Target Workload
Select the environment for your experiment. Best practice is to:
- Start in a development or test environment.
- Validate your hypotheses.
- Progress to production once you’re confident in the results.
Warning
Avoid running chaotic experiments directly in production without prior validation—this could cause unintended outages.
3. Perform Workload Discovery
Workload discovery involves mapping out your application’s components and dependencies:
- Review all service interactions (load balancers, auto scaling groups, databases).
- Align your design with the AWS Well-Architected Reliability Pillar.
- Identify single points of failure (for example, a lone EC2 instance).
If you uncover a clear weakness, address it before injecting faults—there’s little value in re-testing a known failure.
4. Define Steady State Behavior
A steady state is your system’s normal, fault-free condition. Establish this baseline to measure the impact of injected failures.
To capture steady-state metrics:
- Monitor key indicators in Amazon CloudWatch (e.g., latency, error rates, throughput).
- Apply a consistent load (using tools like AWS Load Testing) and record performance over time.
Once you have these baseline measurements, you can quantify deviations during your FIS scenarios.
Links and References
- AWS Fault Injection Simulator (FIS)
- CloudWatch Documentation
- AWS Well-Architected Reliability Pillar
- Introduction to Chaos Engineering
Watch Video
Watch video content