This article explains how documents are organized into indices in Elasticsearch, enhancing data management and search efficiency.
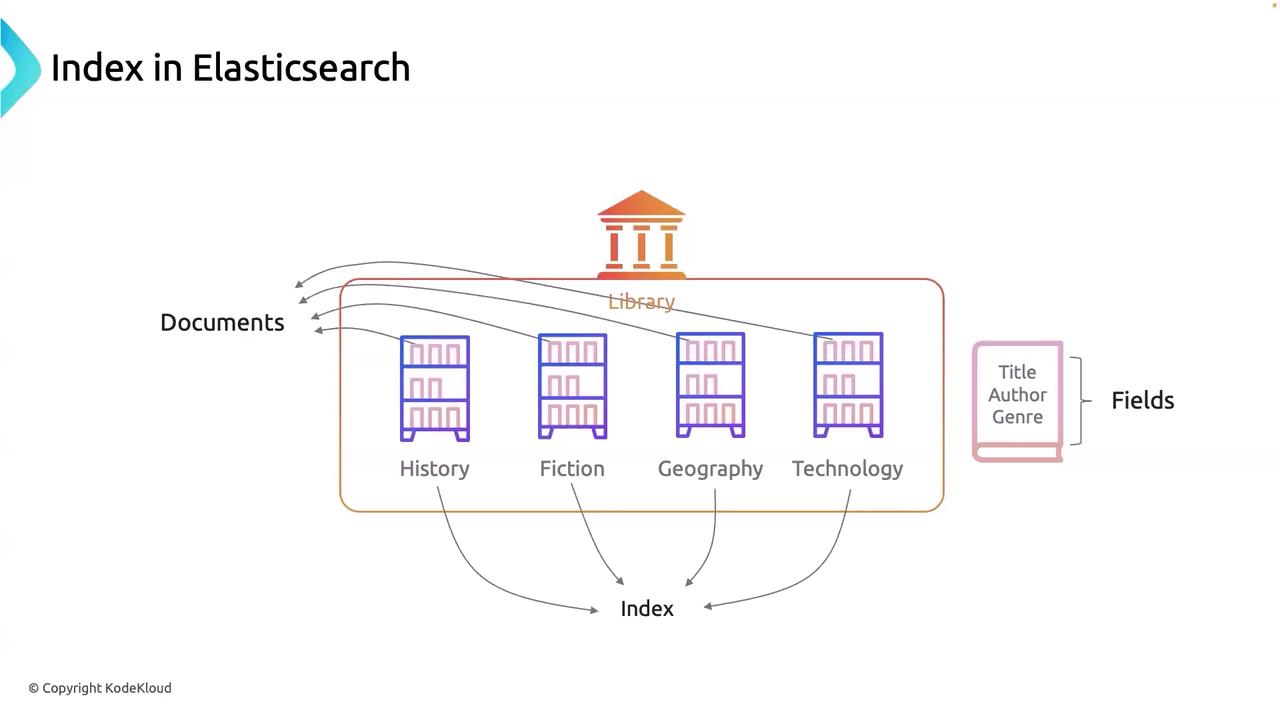
Welcome back! In our previous lesson, we explored the concept of an inverted index—the foundation that enables fast search operations by organizing how documents are stored in Elasticsearch. In this lesson, we delve into how documents are grouped into indices, which play a critical role in managing and querying your data.Imagine a library where books are systematically arranged into different categories such as History, Fiction, Geography, and Technology. In this analogy, each category represents an index, and the books on each shelf are similar to the documents stored within that index. Grouping related documents into an index allows you to efficiently manage and search within specialized sets of data.Consider that in Elasticsearch, documents are grouped based on shared attributes. For example, common information like title, author, and genre serves as fields that help organize these records into their respective indices.
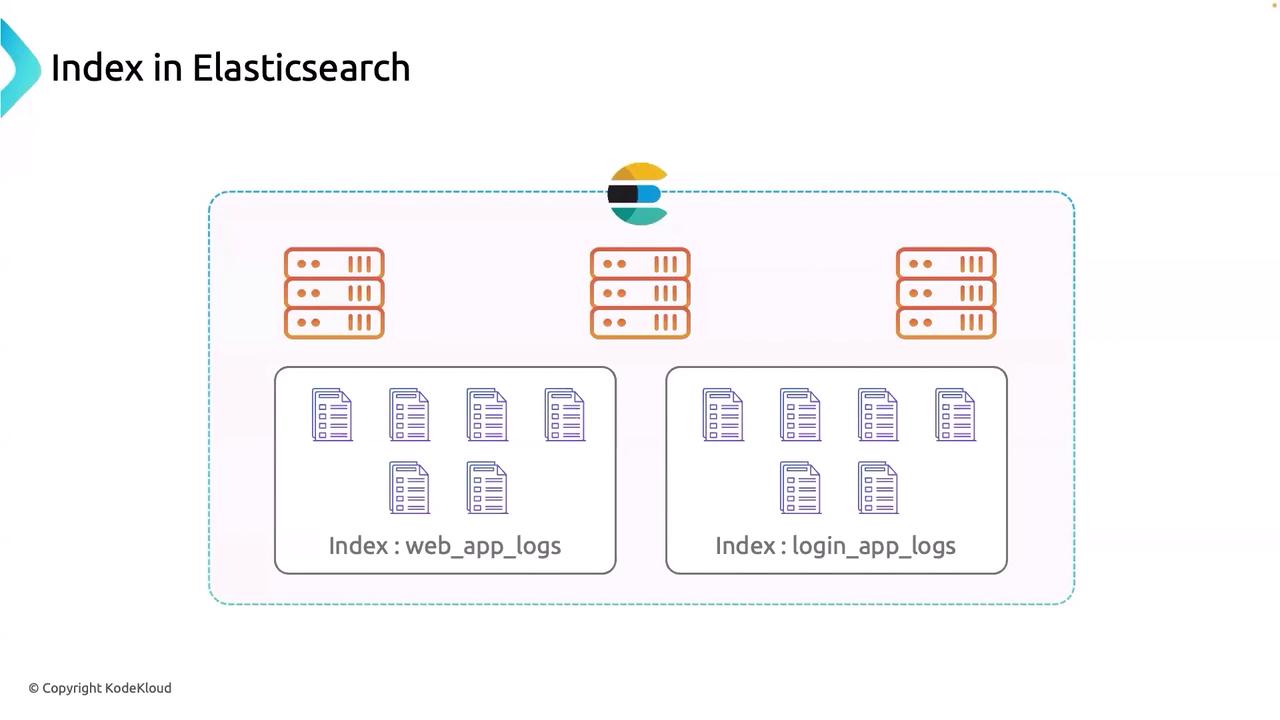
Imagine needing a history book—just as a librarian directs you to the History section, Elasticsearch searches within a designated index. For example, logs from a web application might be stored in an index called “web_app_logs”. Similarly, a separate index named “login_app_logs” could house logs from a Login App microservice. This clear segregation ensures that data from various sources is managed efficiently, simplifying search operations and maintenance.
When documents are stored, Elasticsearch leverages its inverted index structure to guarantee rapid search performance, a key benefit for real-time data querying.
Logical Segmentation: Each index acts as a container for a specific set of documents.
Efficient Searching: The inverted index structure enables fast information retrieval.
Schema Flexibility: Data can be stored with flexible or defined schemas.
Let’s review some of the key features of an index in Elasticsearch:
Logical Container
An index functions as a logical container, similar to how a database serves in SQL systems. It comprises a collection of documents that share common attributes. For instance, a library catalog might have separate indices for books, magazines, and digital media, which simplifies data management and querying.
Documents
Within an index, each document is the fundamental unit of information, typically stored in JSON format. Documents can include multiple fields—ranging from basic details like schema definitions to various metadata. One of Elasticsearch’s strengths is the default ability to index every field, which enhances its advanced search capabilities.
Schema Flexibility
Documents within an index do not necessarily need to follow a strict schema, which adds considerable versatility. This feature is especially useful in scenarios such as a Login App where log fields may change over time. While Elasticsearch supports schema flexibility, it also provides mechanisms to enforce specific schemas when required. Future lessons will explore how to define and manage these schemas effectively.
In summary, each index in Elasticsearch serves as a container for documents that share similar characteristics. This design not only optimizes search performance by utilizing an inverted index structure but also provides the flexibility to adapt to varying data schemas.Thank you for reading! We look forward to exploring more advanced Elasticsearch topics in our next lesson.For additional information, visit the Elasticsearch Documentation.