Understanding the Scenario
Imagine you have multiple servers with Elasticsearch installed. In this setup, you maintain two indices: one for web application logs (web_app_logs) and another for login application logs (login_app_logs). The logs from your web application are stored in the web_app_logs index, while the login_app_logs index contains logs from your login application.
In production environments, infrastructure challenges are inevitable. For instance, if one node in your Elasticsearch cluster fails, the indices hosted there are at risk. Without proper replication, losing a node could result in the loss of critical data.
The Role of Shards
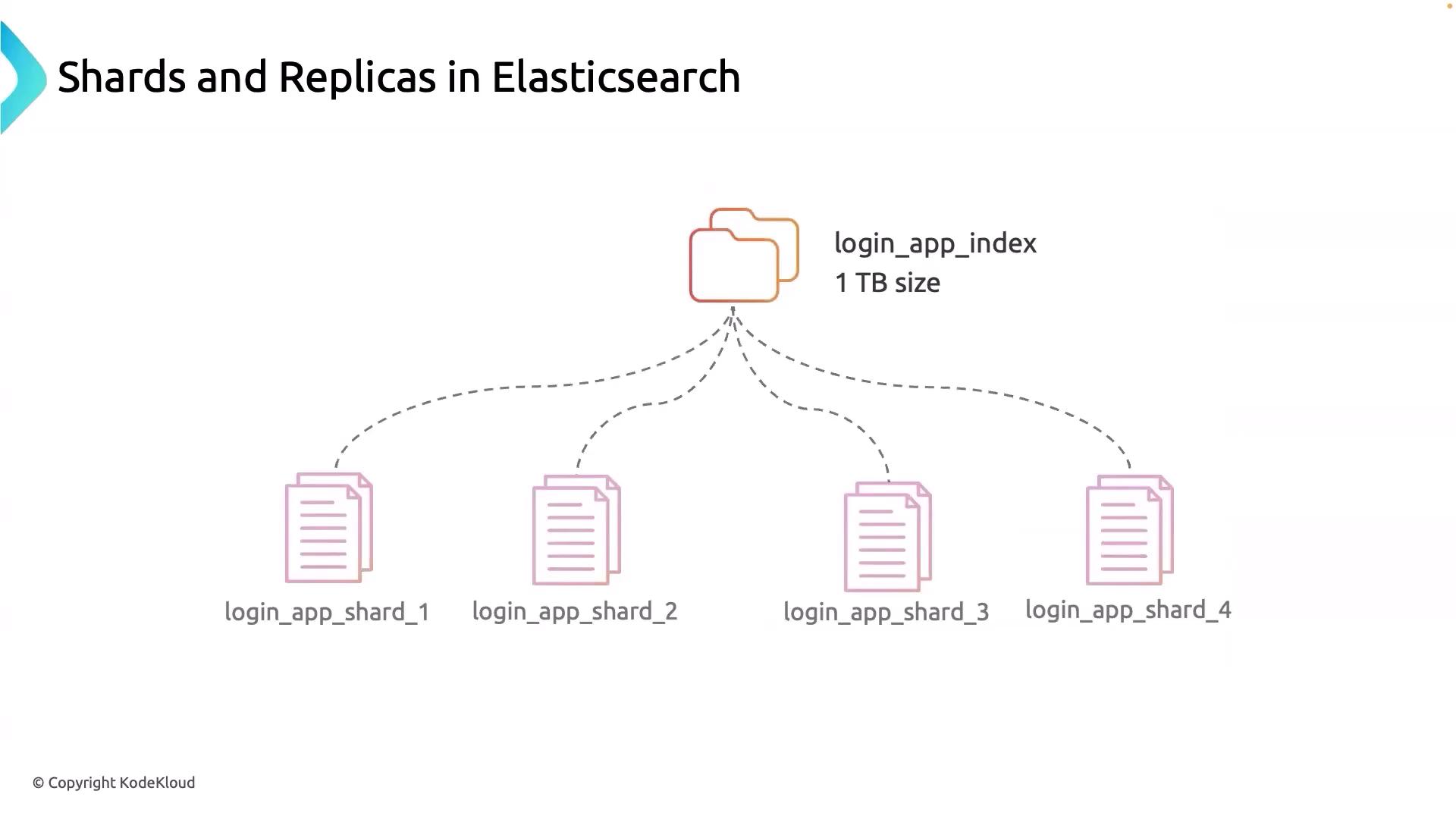
Replicating an entire index might seem like an idea, but for massive datasets—such as terabytes of log files—it becomes impractical. Elasticsearch addresses this challenge by using shards to break the index into smaller, manageable pieces. Consider a 1-terabyte login_app_logs index. By dividing this index into 4 shards, each shard would be roughly 256 GB. This segmentation has several key benefits:- Efficient Data Management: Each shard acts like a self-contained index that stores and processes a portion of the overall dataset.
- Parallel Processing: Shards allow for parallel search and indexing, which significantly boosts performance.
- Enhanced Fault Tolerance: If a node fails, Elasticsearch can relocate the affected shards to other nodes, ensuring data remains accessible.
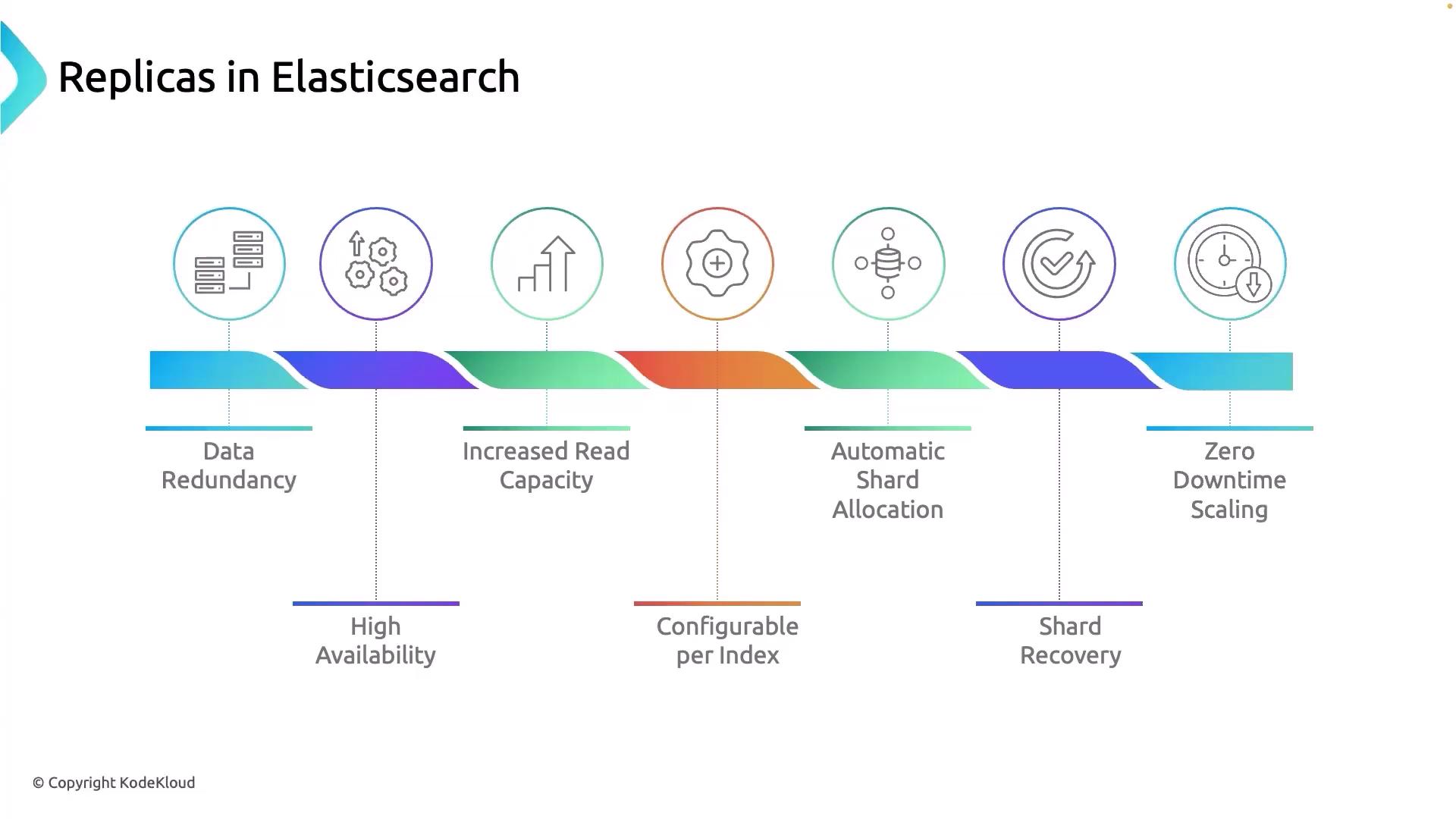
The Importance of Replicas
While shards improve scalability and parallelism, they alone do not guarantee fault tolerance. This is where replicas come in. A replica is an exact copy of a shard, and its primary functions include:- Data Redundancy: Multiple copies of your data ensure that even if one node fails, the information remains available.
- Increased Read Capacity: Distributing read operations across several nodes reduces the load on individual nodes and enhances performance during peak times.
- Automated Shard Allocation and Recovery: Elasticsearch automatically allocates replicas across the cluster and promotes a replica to a primary shard if a node fails.
- Zero Downtime Scaling: The dynamic allocation of replicas supports seamless scaling, allowing nodes to be added or removed without any downtime.
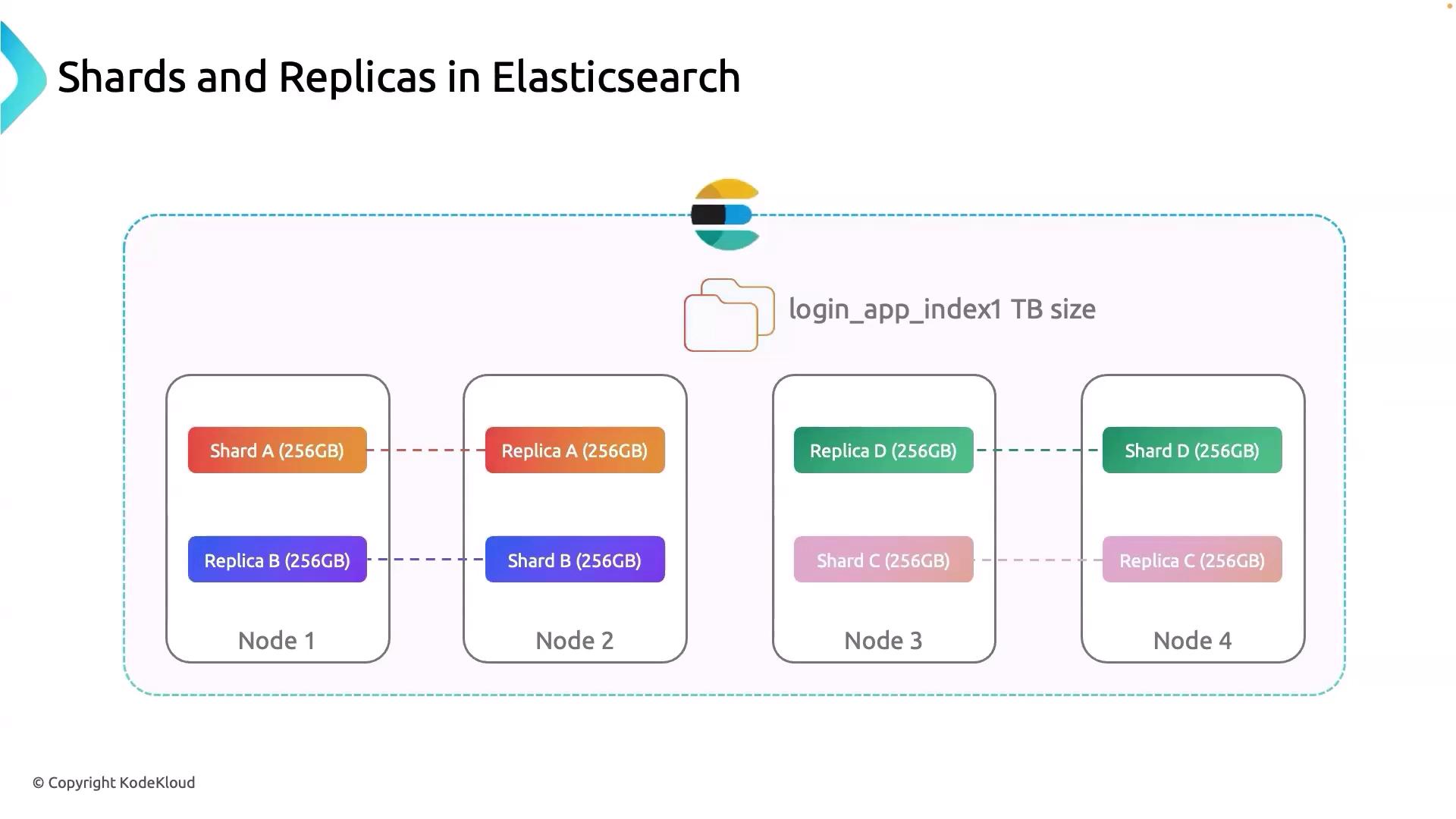
Each shard in your Elasticsearch cluster should have a corresponding replica to ensure high availability. For example, consider Shard A on Node 1; it is replicated as Replica 1 on Node 2. This replication strategy guarantees that your data remains accessible even if a node becomes unavailable.
Key Benefits of Replicas
| Benefit | Description |
|---|---|
| Data Redundancy | Multiple copies of data across different nodes protect against node failures. |
| Enhanced Read Performance | Distributing read requests reduces individual node load and improves query speed. |
| Automated Shard Recovery | If a primary shard fails, a replica is automatically promoted to primary. |
| Seamless Scaling | Replicas facilitate the addition or removal of nodes without causing downtime. |
Putting It All Together
To visualize the complete operation within an Elasticsearch cluster, consider a scenario where a 1 TB login_app_logs index is distributed over 4 nodes (Shard A, Shard B, Shard C, and Shard D, each about 256 GB). If Node 1, housing Shard A, goes down, the replicated Shard A on Node 2 ensures that your data remains safe and accessible.