EFK Stack: Enterprise-Grade Logging and Monitoring
Mastering Elasticsearch Fundamentals
Mastering Fundamentals of Elasticsearch
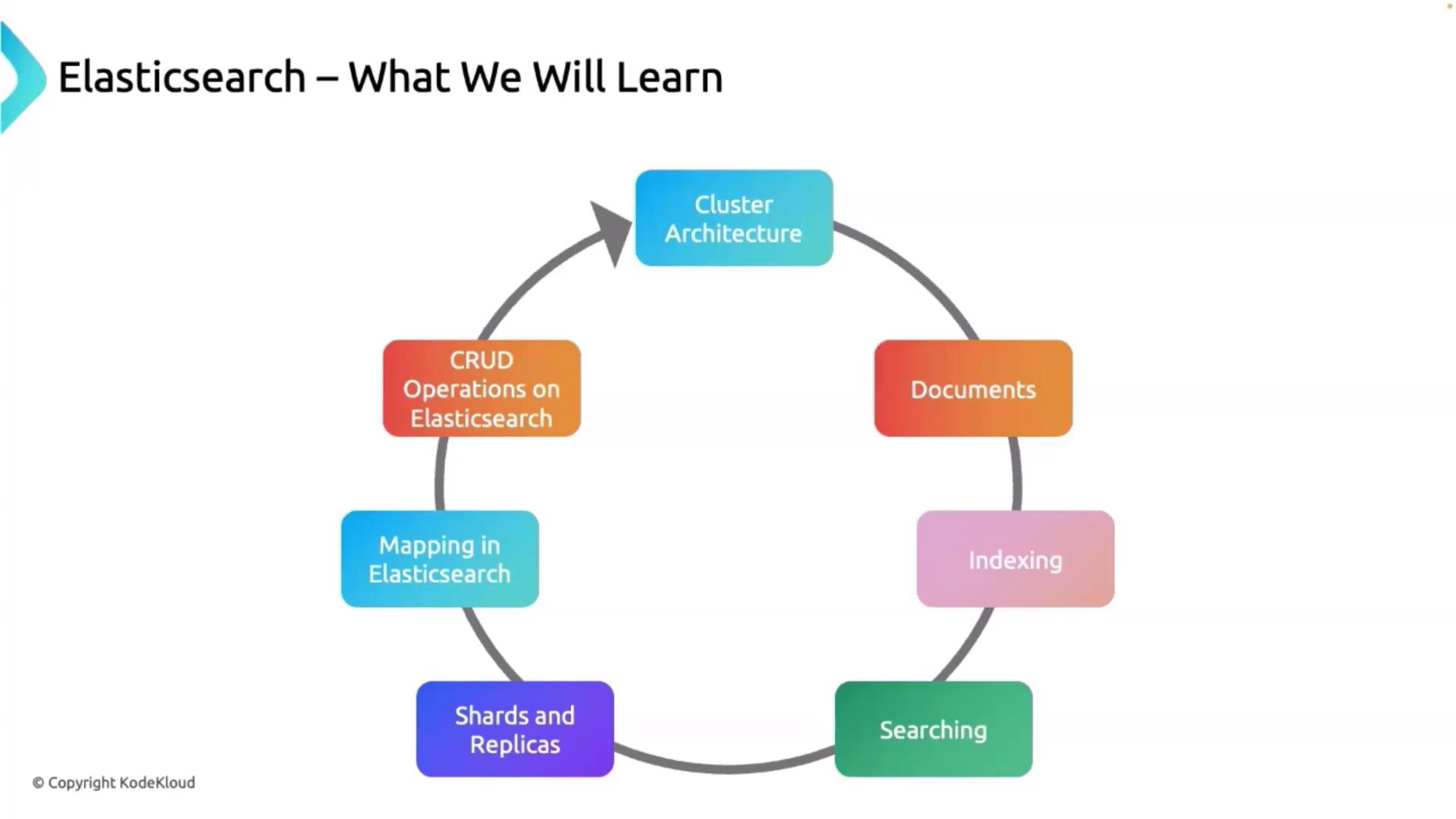
Welcome to the comprehensive guide on Elasticsearch fundamentals. In this lesson, we dive deep into the core concepts of Elasticsearch, including its architecture, indexing and querying processes, and document management strategies.
Cluster Architecture
An Elasticsearch cluster is a collection of one or more nodes that work together to store data and deliver high-performance indexing and search capabilities. Clusters enhance scalability by adding more nodes, which increases both storage capacity and search throughput.
Data within Elasticsearch is stored as JSON documents, with each document acting as an individual searchable unit. These documents are organized into indices, similar to tables in traditional SQL databases.
Note
An effective cluster design not only improves performance but also ensures data redundancy and fault tolerance.
Indexing and Searching
Indexing involves storing documents in Elasticsearch to enable rapid retrieval. When a document is indexed, Elasticsearch creates an inverted index that facilitates fast, full-text search operations. Leveraging the robust Lucene search library, Elasticsearch ensures that searches are both efficient and scalable.
Elasticsearch supports a variety of query types, including term queries, match queries, and boolean queries. To handle large datasets, each index is divided into shards. Each shard functions as an independent index that can reside on any node in the cluster. Additionally, replicas (copies of shards) are maintained to ensure high availability and enhanced fault tolerance.
Mapping
Mapping in Elasticsearch serves a similar purpose as a schema in traditional databases. It defines how documents and their fields are stored, indexed, and analyzed. Through proper mapping, you can specify data types and determine how fields are processed during storage and retrieval.
CRUD Operations
Elasticsearch offers robust support for CRUD (create, read, update, and delete) operations, making it easy to manage documents within your cluster. These operations are fundamental for inserting new data, retrieving existing information, modifying records, and removing documents as needed.
Conclusion
In this guide, we've provided an overview of the essential components that make Elasticsearch a scalable and efficient solution for production environments. Upcoming content will cover the cluster architecture in more detail, offering deeper insights into the inner workings of Elasticsearch.
Thank you for reading, and we appreciate your ongoing interest in mastering Elasticsearch fundamentals. For more technical resources and tutorials, be sure to explore additional articles on our website.
Watch Video
Watch video content