In this tutorial, we’ll configure Kafka Connect to stream events from a Kafka topic into Amazon S3 using Confluent’s S3 Sink Connector. By the end, you’ll have a working pipeline that writes data from Kafka into an S3 bucket in JSON format.
Prerequisites
A running Kafka broker on your EC2 instance.
AWS CLI installed and configured on the same instance.
An IAM role attached to your EC2 instance with S3 access.
Keep your Kafka broker terminal open throughout this demo. Closing it will disconnect you from the cluster.
1. Open a new terminal on the EC2 instance Switch to root and navigate to your home directory:
2. Download the S3 Sink Connector plugin We’ll fetch the Amazon S3 sink connector ZIP from Confluent Hub. In this lab, the ZIP is hosted in an S3 bucket:
aws s3 cp s3://kafka-s3-jar-file-confluent-lab/confluentinc-kafka-connect-s3-10.5.23.zip .
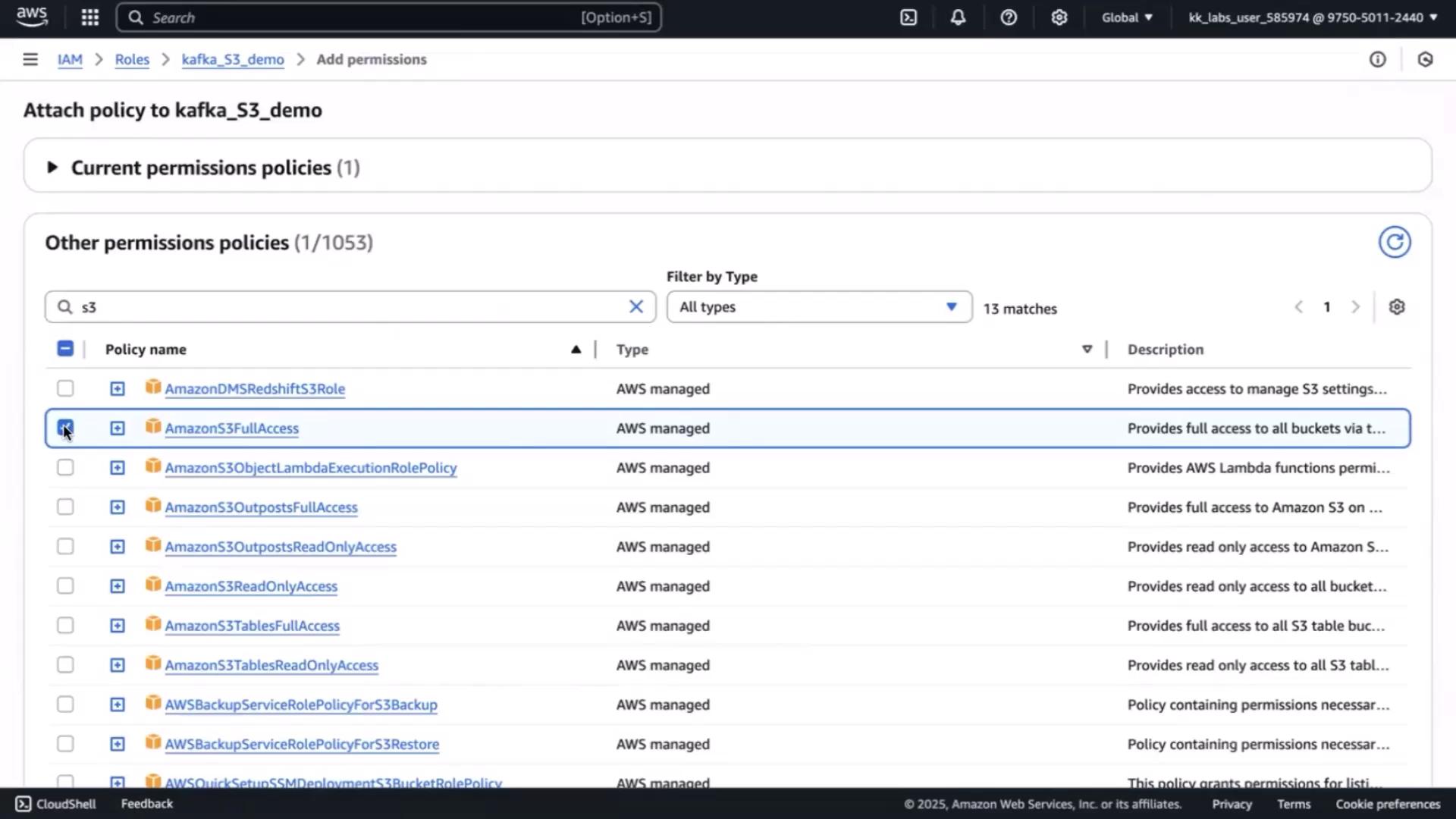
If you see a 403 Forbidden error, you need to attach S3 permissions to your EC2 IAM role.
Open the IAM console , select the role attached to your EC2 instance (e.g., kafka_S3_demo), then click Add permissions .
Attach AmazonS3FullAccess (or a least-privilege policy you define).
Retry the download once the policy is attached:
aws s3 cp s3://kafka-s3-jar-file-confluent-lab/confluentinc-kafka-connect-s3-10.5.23.zip .
On success, verify the file and unzip:
ls -l unzip confluentinc-kafka-connect-s3-10.5.23.zip ls -lrt # drwxr-xr-x 6 root root 74 Feb 4 16:28 confluentinc-kafka-connect-s3-10.5.23
Edit the standalone worker configuration to point at your broker and include the connector plugin path:
vim kafka_2.13-3.0.0/config/connect-standalone.properties
Update or add:
bootstrap.servers =YOUR_BROKER_IP:9092 key.converter =org.apache.kafka.connect.json.JsonConverter value.converter =org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable =true value.converter.schemas.enable =true offset.storage.file.filename =/tmp/connect.offsets offset.flush.interval.ms =10000 plugin.path =/root/confluentinc-kafka-connect-s3-10.5.23
Save and exit.
4. Create the S3 Sink connector properties Define the connector configuration in config/s3-sink-connector.properties:
vim kafka_2.13-3.0.0/config/s3-sink-connector.properties
Paste and customize your bucket name:
name =s3-sink-connector connector.class =io.confluent.connect.s3.S3SinkConnector tasks.max =1 topics =cartevent s3.bucket.name =kafka-connect-s3-sink-example-01 s3.region =us-east-1 flush.size =5 rotate.schedule.interval.ms =60000 storage.class =io.confluent.connect.s3.storage.S3Storage format.class =io.confluent.connect.s3.format.json.JsonFormat partitioner.class =io.confluent.connect.storage.partitioner.DefaultPartitioner timezone =UTC key.converter =org.apache.kafka.connect.json.JsonConverter value.converter =org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable =false value.converter.schemas.enable =false behavior.on.null.values =ignore
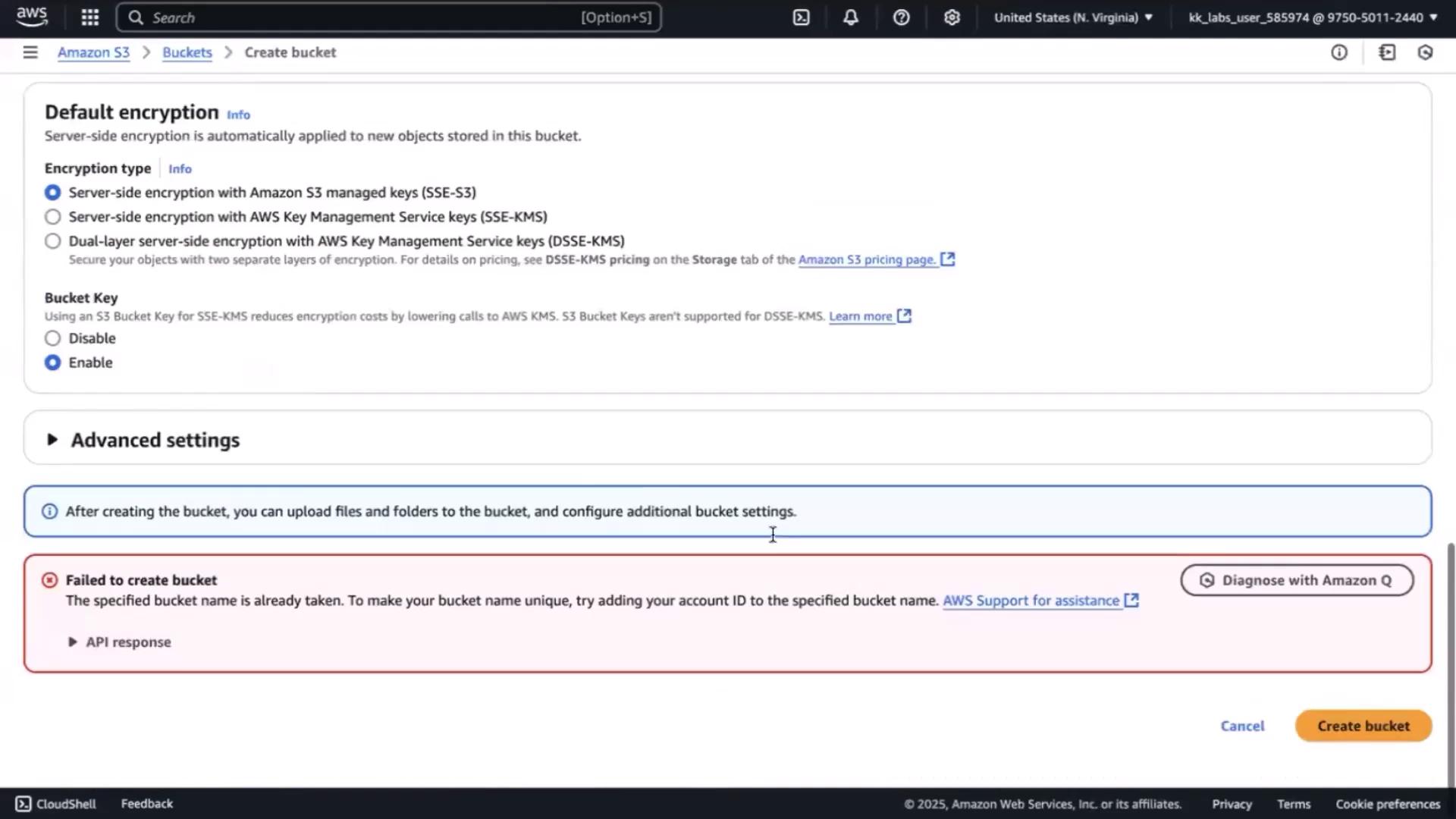
Create the S3 bucket In the S3 console , click Create bucket and specify the same name.-01) and retry.
5. Start Kafka Connect Launch the standalone Connect worker:
cd kafka_2.13-3.0.0 bin/connect-standalone.sh \ config/connect-standalone.properties \ config/s3-sink-connector.properties
Inspect the logs. You should see the connector initialize, subscribe to the cartevent topic, and begin streaming data into S3.
Links and References