Use Case: Pharmacy Inventory Prediction
Imagine managing a network of pharmacies where predicting inventory needs is critical. By training a machine learning model with historical data from these pharmacies, you can forecast future inventory requirements accurately. This use case highlights several key considerations that data scientists must address before they begin model development:- Where and how should model development start?
- Which development environment and tools are optimal?
- How can the model be effectively trained on large datasets?
- What are the best practices for model versioning and evaluation?
- How should experiments be tracked to maintain a data-driven research process?

Before initiating model development, it is crucial to outline the challenges and questions mentioned above to ensure a smooth building and training process.
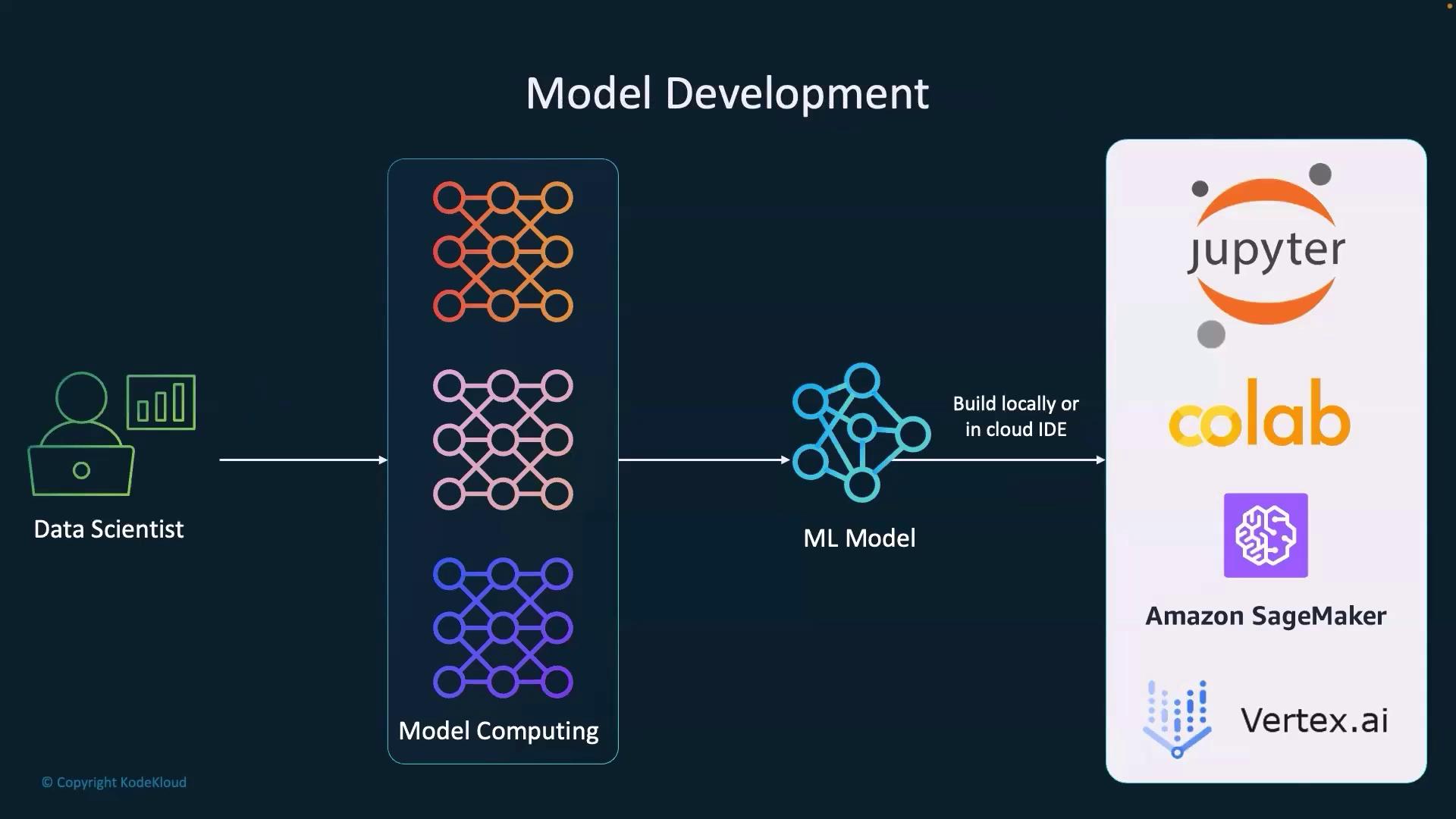
Model Development Process
The initial phase of model development involves selecting the computing strategy best suited for your task. Once you have made this decision, the focus shifts to training the model. Data scientists commonly use several flexible and powerful development platforms such as Jupyter Notebook, Google Colab Notebook, AWS SageMaker, and GCP Vertex AI. Each of these environments offers unique benefits for building, training, and experimenting with machine learning models. The general steps in the model development workflow include:- Installing the required packages in the working environment.
- Connecting to the relevant data sources.
- Building and training the machine learning model.
The Role of MLOps Engineers
MLOps engineers are key players in the model development lifecycle. They ensure that data scientists have access to scalable, efficient environments and tools. Their responsibilities include:- Setting up and managing cloud environments like AWS SageMaker or GCP Vertex AI.
- Facilitating ad hoc deployment of Jupyter Notebooks on Kubernetes.
- Automating infrastructure so that data scientists can concentrate on model experimentation without technical interruptions.
The collaboration between data scientists and MLOps engineers is vital for maintaining an efficient, scalable model development and training pipeline.
Summary
In summary, model development and training encompass the following core aspects:- Choosing the appropriate machine learning algorithms.
- Leveraging cloud-based tools and environments for efficient model building.
- Implementing robust processes for experiment tracking and model versioning.
For further reading and resources, consider checking out the following links: