This article covers essential steps and best practices for optimizing machine learning models through training and hyperparameter tuning.
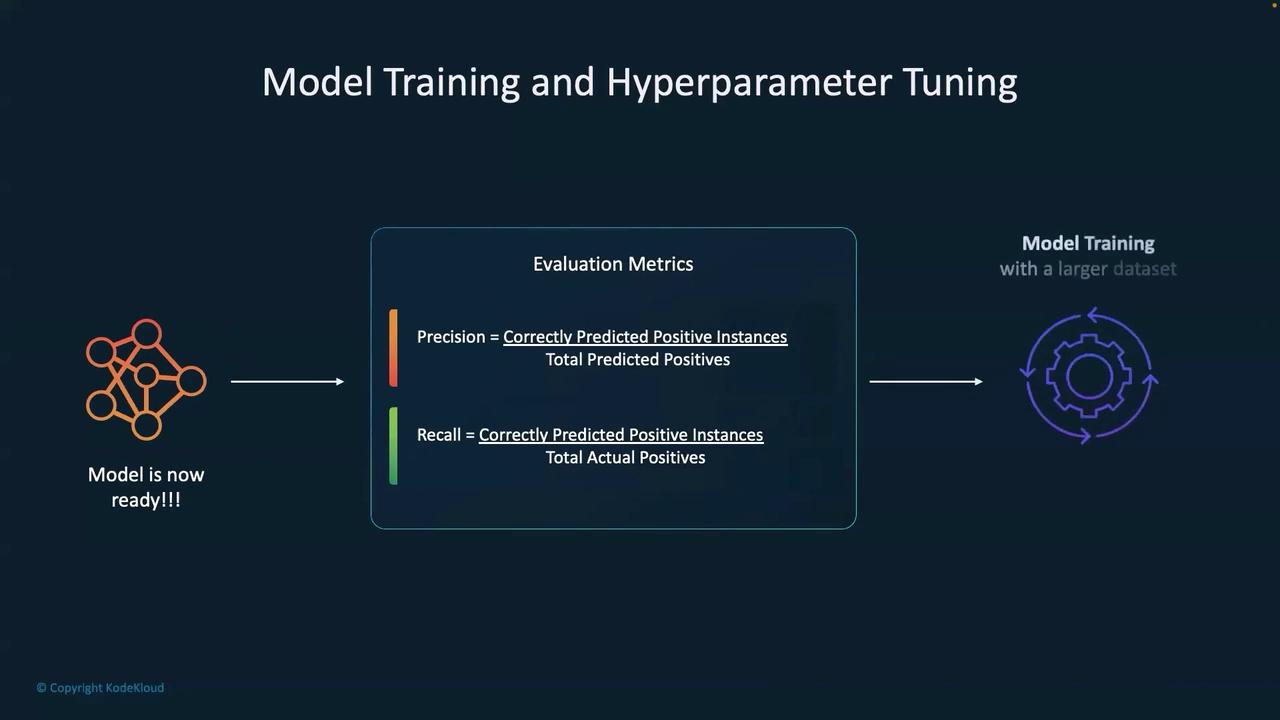
Welcome back to this technical guide on model training and hyperparameter tuning. In this article, we cover the essential steps, evaluation metrics, and best practices to optimize your machine learning model for robust performance.After building your initial model, the first step is to assess its performance using key metrics such as precision and recall. Precision measures the proportion of correctly predicted positive instances among all predicted positives, while recall gauges the proportion of actual positives that are correctly identified. These metrics are fundamental in model evaluation and are widely used by data scientists.
Understanding evaluation metrics like precision and recall is crucial for assessing your model’s ability to generalize effectively. Regular monitoring of these metrics helps identify areas for improvement.
With the evaluation metrics in place, you can refine the model further by training it on larger datasets and applying advanced hyperparameter tuning techniques.
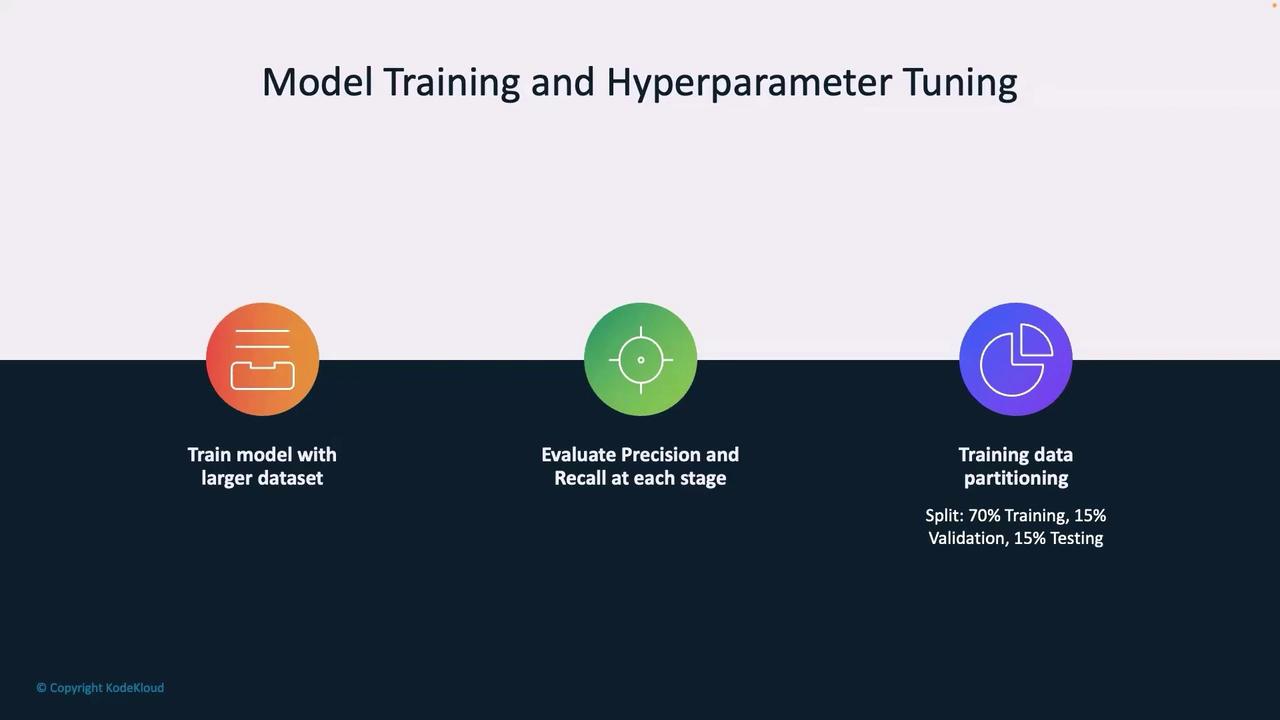
The model training process consists of three core steps:
Training with Larger Datasets:
Training the model on more extensive and diverse datasets enhances its ability to generalize to real-world scenarios.
Evaluating Precision and Recall:
Continuous performance evaluation throughout the training process helps in identifying the model’s strengths and potential areas of improvement.
Data Partitioning:
Splitting the dataset into distinct subsets is key to avoiding overfitting. A common data split involves:
70% for training
15% for validation
15% for testing
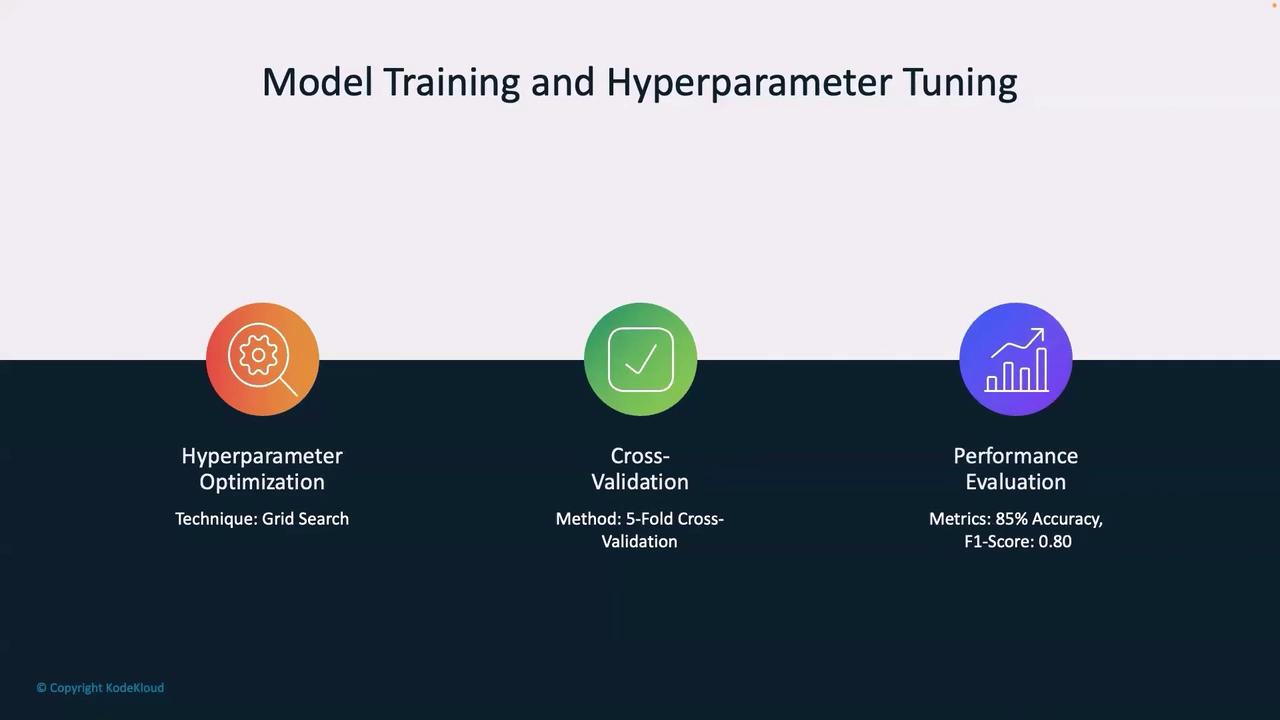
To further enhance model performance, hyperparameter tuning is essential. One common method is grid search, which systematically tests different combinations of hyperparameters to find the optimal configuration. Additionally, cross-validation methods—such as five-fold cross-validation—are employed to robustly assess the model’s performance across various subsets of the data.Evaluation metrics like accuracy and F1 score offer clear insights into the performance of the tuned model. For instance, achieving 85% accuracy with an F1 score of 0.80 suggests that the model is well-balanced and reliable.
Model training and hyperparameter tuning are iterative processes that involve constant refinement, performance evaluation, and optimization. Maintaining a systematic approach ensures that the final model is robust and well-prepared for real-world challenges.
In summary, model training and hyperparameter tuning require a meticulous approach involving expanding your training dataset, rigorously evaluating model metrics, and fine-tuning parameters using techniques like grid search and cross-validation. As an MLOps engineer, you may also be involved in provisioning additional cloud resources, sourcing external data, or cleaning existing datasets to enhance model accuracy and reliability.That concludes this guide. Thank you for reading, and see you in the next lesson.