This article explores diverse applications of Large Language Models beyond traditional tasks, including code generation, documentation, and bioinformatics advancements.
In this article, we explore the diverse applications of Large Language Models (LLMs) beyond traditional human language tasks. These models are increasingly used for code generation, documentation, translation (including code translation), and even in cutting-edge domains like bioinformatics. For example, models such as Codex are being trained on non-traditional data sources to extend their versatility.
LLMs leverage neural networks to recognize patterns and relationships in sequence data, making them particularly effective in areas like code generation. Enterprise organizations modernize or recreate code routinely, and transformer-based models—trained on vast repositories of code—can efficiently generate similar, high-quality code.Below is a simple example of a quicksort function implemented in Python, demonstrating basic code generation:
Copy
def quicksort(arr): # Sorting logic here return sorted(arr)
Recent breakthroughs, such as AlphaFold, highlight the adaptability of transformer and transformer-like models in areas outside traditional protein folding. Pharmaceutical companies, for instance, are investing in these advancements for medium- to long-term pipeline development.
While models trained primarily on datasets like Common Crawl can be highly effective, they may require additional fine-tuning to excel in specialized tasks such as RNA analysis.
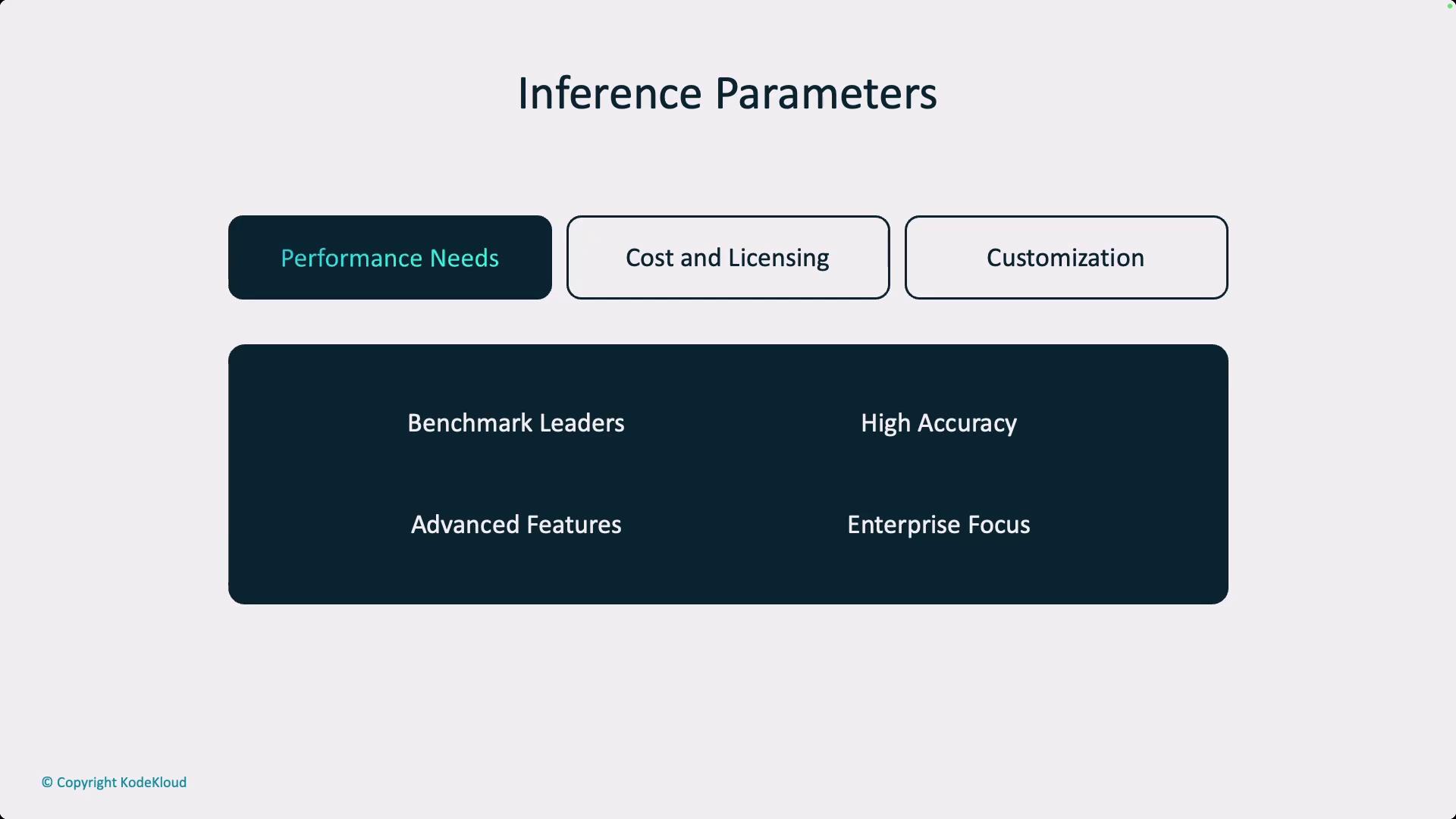
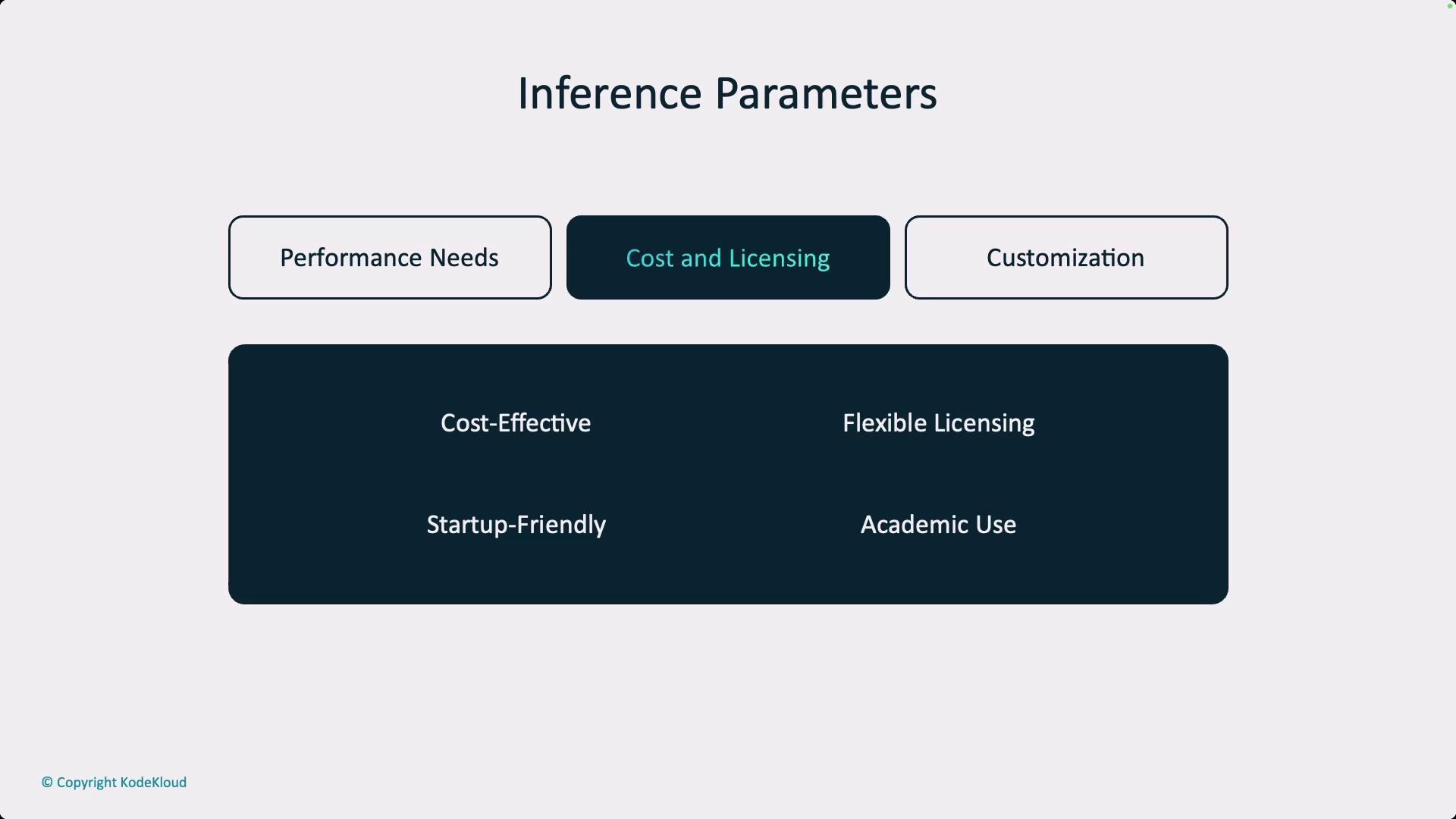
A key decision point when working with LLMs is the choice between open-source and proprietary models. This decision generally depends on three critical factors:
Performance needs
Cost and licensing
Customization
During the early stages of a project, such as proof-of-concept or proof-of-value, an application might only serve a limited user base. However, scaling to support thousands of users (for example, 20,000 users) requires strategic planning to meet performance demands. Large models, often deployed by hyperscalers, deliver the necessary scalability but might involve complex licensing and higher costs.
When evaluating cost and licensing, it is crucial to understand that operating these models can be expensive. However, a smaller model does not necessarily guarantee a lower total cost of ownership (TCO). Teams should assess whether they have the in-house capabilities to manage the infrastructure or if partnering with third-party experts is more appropriate. Licensing arrangements can be complex; for example, some open-source models may include restrictions, such as copyleft clauses, that limit proprietary enhancements.
Customization plays a critical role for domain-specific applications. Open-source models offer greater control and customization. In contrast, larger proprietary models may provide additional fine-tuning options on platforms such as OpenAI, Azure, or Google Gemini. Consider the level of tuning available to ensure it meets your specific project needs. In industries like finance or healthcare where data sovereignty and privacy are of utmost importance, deploying open-source models on-premises or in a private cloud might be the optimal solution.
A flowchart further comparing open-source and proprietary LLMs emphasizes the importance of stringent data privacy and control, especially for financial institutions. This visual aid highlights the deployment of an open-source model on-premises to meet these critical requirements.
When choosing a model, it is vital to evaluate performance, cost, licensing constraints, and customizability. Overlooking any of these aspects can lead to project challenges, such as a promising concept failing due to critical oversights.In the next section of this lesson, we will assess LLM performance using both objective quantitative methods and real-world deployment evaluations. This dual approach ensures that theoretical performance metrics are effectively translated into practical applications across various environments.
Thank you for reading this section. Stay tuned as we dive deeper into performance assessment and further refine our understanding of deploying LLMs efficiently and effectively.