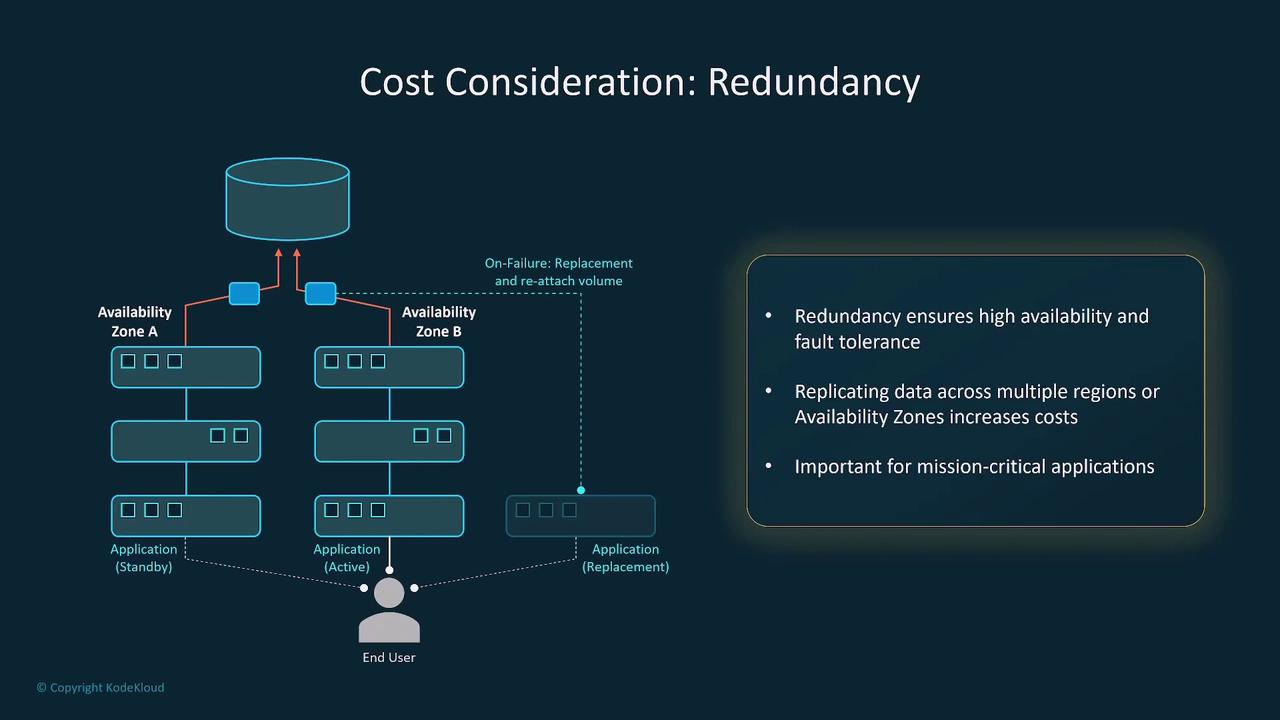
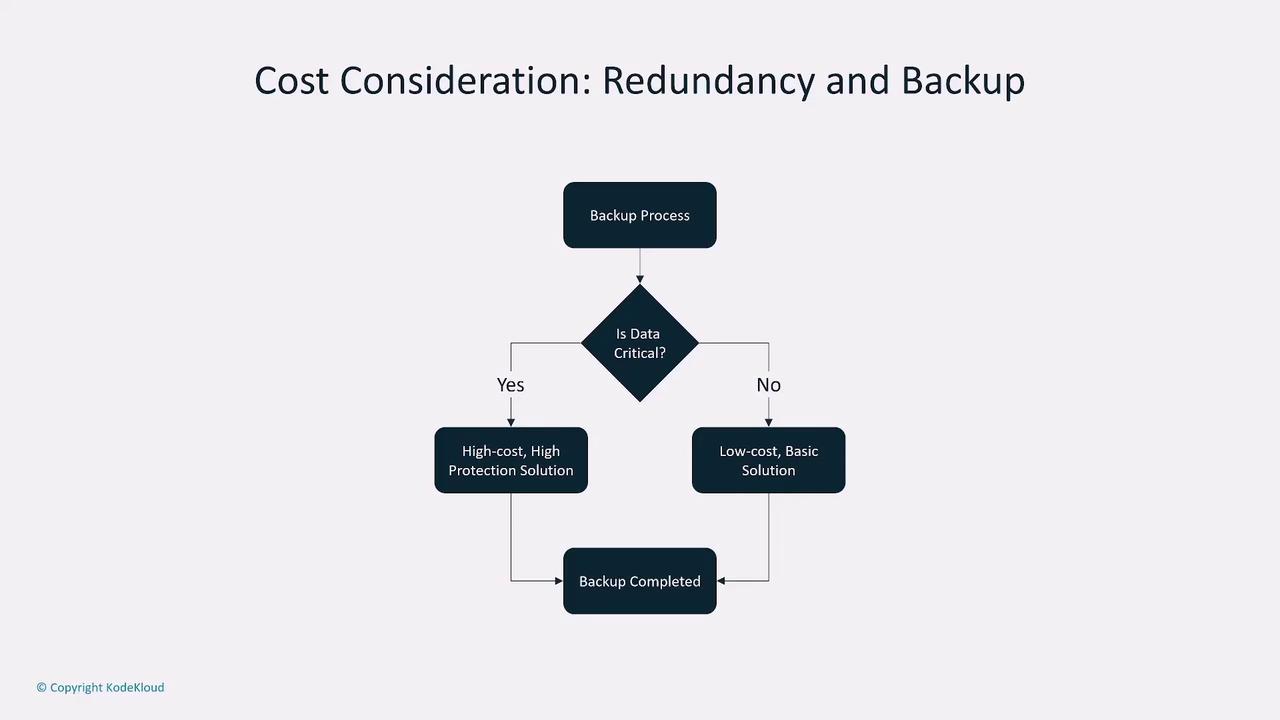
Redundancy Considerations
One critical factor is redundancy. For instance, ensure that your model’s storage is both redundant and highly available by distributing it across multiple availability zones and regions. Although additional redundancy increases costs, it’s a necessity when data loss cannot be tolerated or when high uptime is expected by your users.
Performance and Compute Options
Performance is a significant cost factor, particularly when choosing between GPUs, AWS Inferentia, or standard CPUs. For example, GPUs can greatly enhance inference speed for machine learning applications, whereas AWS Inferentia offers a cost-effective solution for high-throughput ML workloads. Meanwhile, training-focused services like AWS Trainium may deliver superior throughput than GPUs, albeit at a higher price. Consider whether your workload is batch or real-time and how mission-critical it is when selecting the appropriate compute option.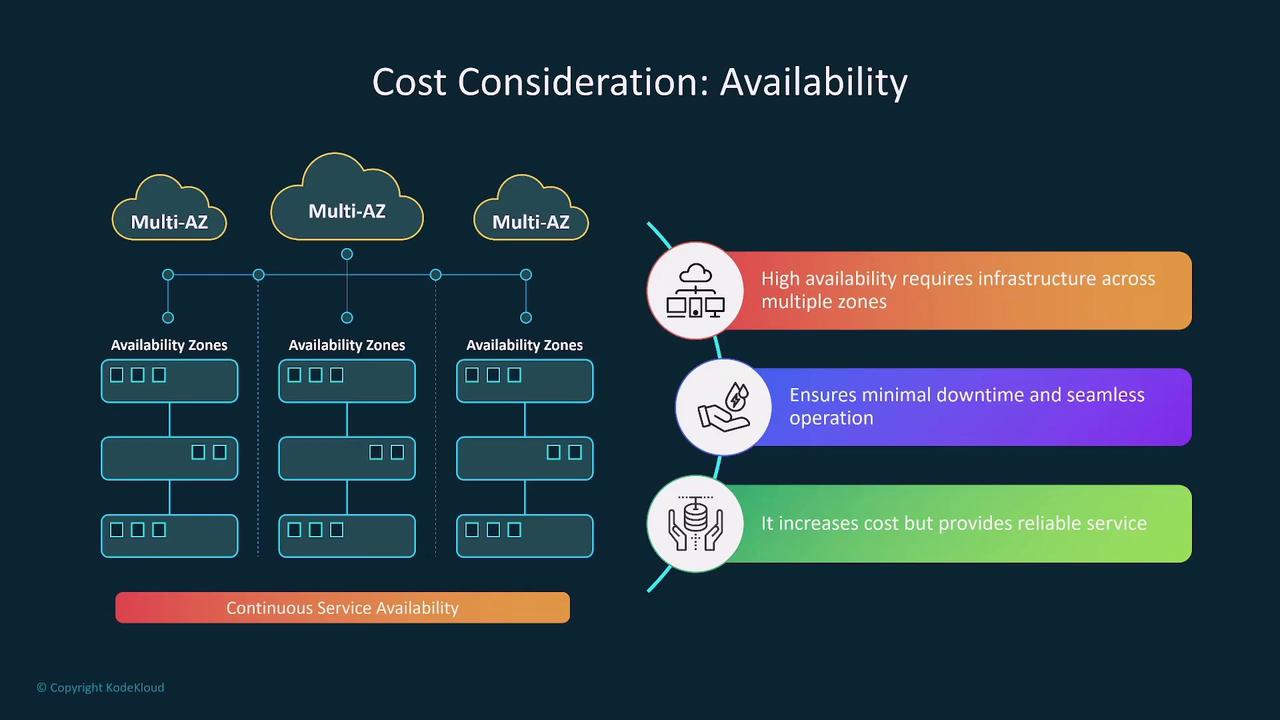

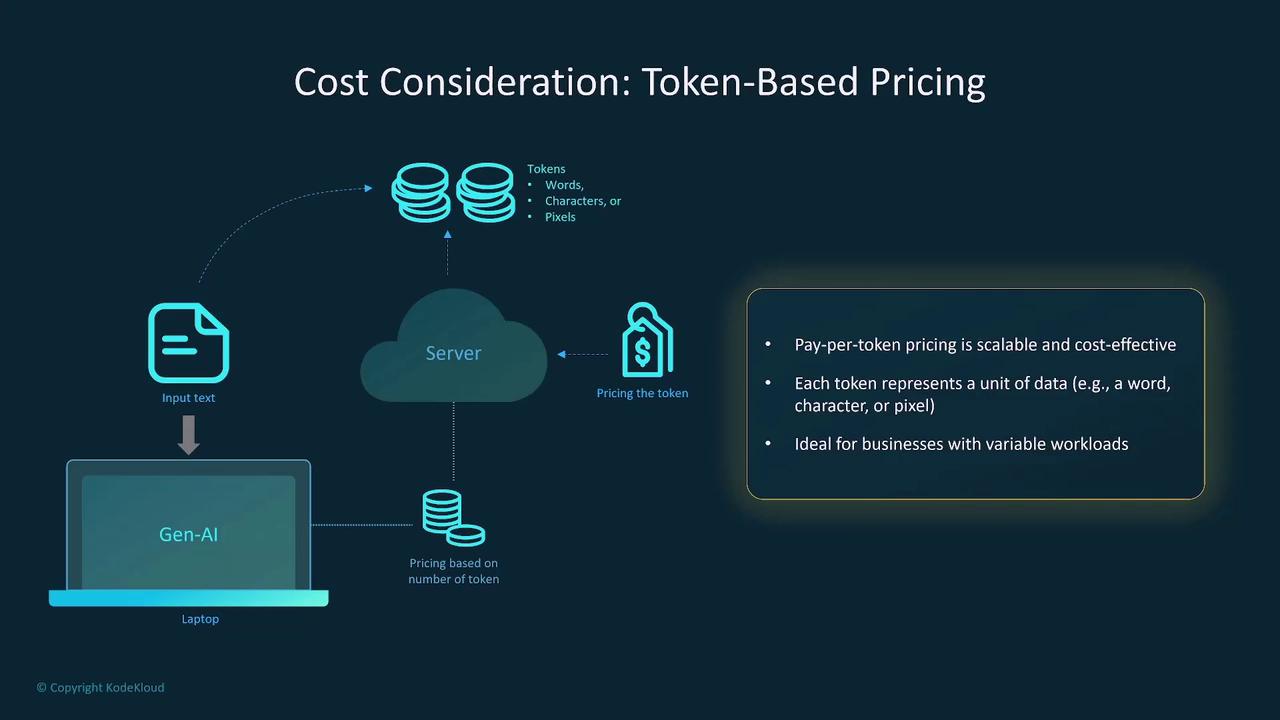
Provisioned Throughput Versus Auto Scaling
Provisioning throughput at a fixed level ensures consistent performance; however, if usage is variable, it can lead to resource wastage. For predictable workloads, provisioned throughput is effective. Conversely, auto scaling adjusts resources dynamically based on demand, reducing waste in fluctuating workloads.
Custom vs. Pre-Trained Models
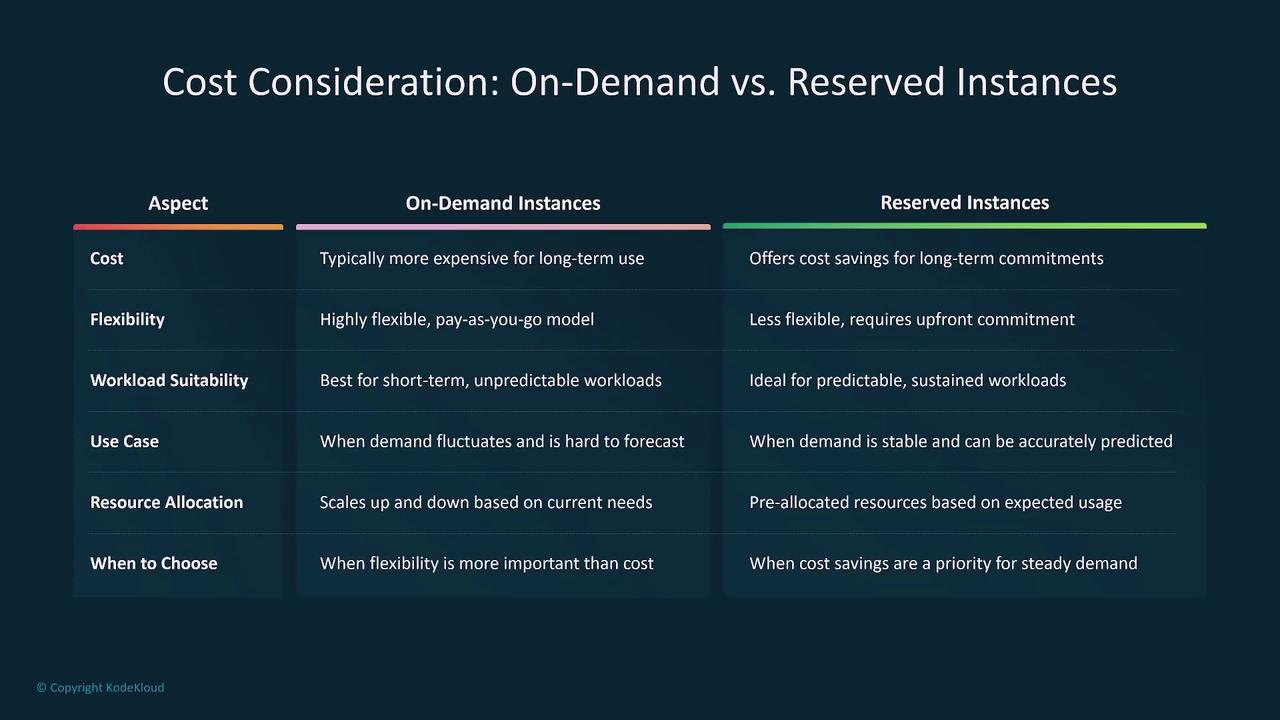
Deciding between custom and pre-trained models often comes down to efficiency and cost. Pre-trained models can quickly be fine-tuned for specific use cases at a lower cost and with easier deployment, making them a suitable choice in about 80% of cases. Custom models, while offering greater control, typically require a higher investment.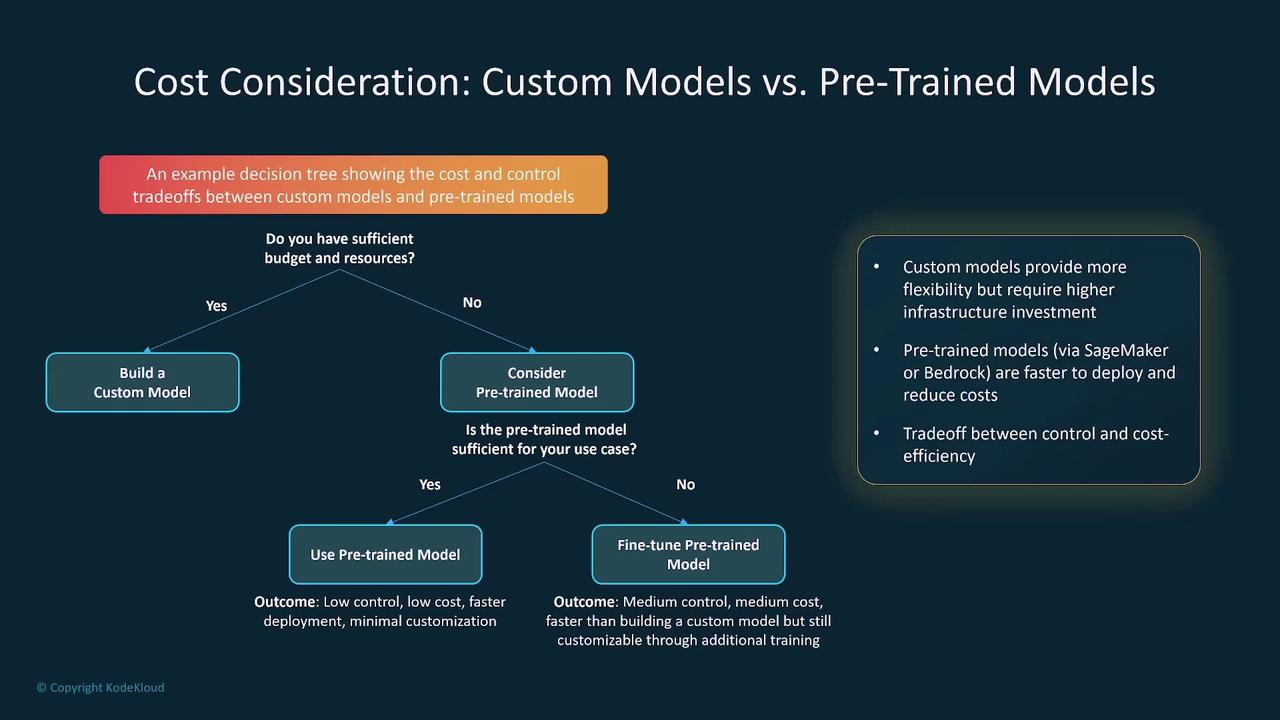

Additional Cost Considerations
Low latency is crucial for many applications, yet boosting performance by adding capacity invariably increases costs. It is essential to balance enhanced performance against client expectations and budget constraints. Backup strategies are also important, especially for critical data such as vector databases. Consider the frequency of backups, the level of detail required, and whether additional redundancy is necessary to support disaster recovery and business continuity. AWS Backup or more granular backup solutions can be employed depending on your data’s criticality.

Balancing Cost, Performance, and Business Objectives
Ultimately, successful cost optimization on AWS involves continuously assessing your infrastructure’s performance, availability, and redundancy in line with your business objectives. AWS offers various tools to help monitor and manage costs, including AWS Budgets, Cost Explorer, the Cost and Usage Report, Trusted Advisor, and Compute Optimizer.
Conclusion
In summary, AWS provides a variety of flexible pricing models tailored to meet different performance, availability, and redundancy requirements. Regular monitoring and evaluation of your infrastructure are crucial to ensure that your cost optimization strategies align with both technical demands and business goals. By selecting the right mix of on-demand versus reserved capacity, custom versus pre-trained models, and leveraging auto scaling, you can establish a cost-effective setup for your generative AI applications on AWS.Using a balanced approach to cost, performance, and availability is essential for optimizing your AWS infrastructure while meeting both technical needs and business objectives.
