Security, Compliance, and Governance for AI Solutions
Source Citation and Data Lineage
This article covers source citation and data lineage in developing generative AI models using AWS SageMaker, emphasizing transparency, compliance, and model integrity.
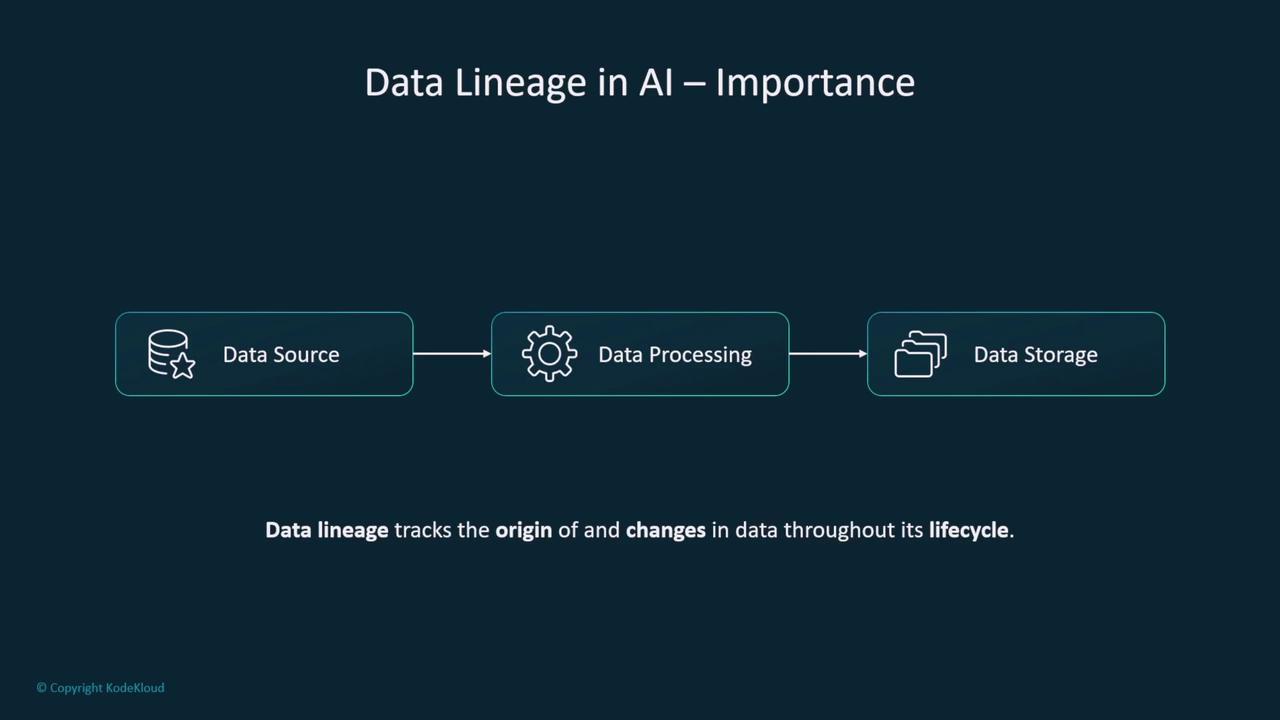
Welcome to this comprehensive lesson on source citation and data lineage—a critical aspect of developing generative AI models using AWS SageMaker. In this lesson, we explore the importance of tracking every step in your data’s lifecycle, ensuring transparency, compliance, and model integrity.Data lineage is fundamental for tracking data sources, monitoring processing steps, and recording how data is pre-processed and stored. Think of it as version control for datasets and models. The process documents the origin and every subsequent change, ensuring that your AI models have a clear audit trail from inception to final deployment.
In this context, the term “feature” refers to an attribute or characteristic of the data—not a software feature. Tracking data lineage means ensuring data integrity, regulatory compliance, and reproducibility of AI models. It essentially provides you with a detailed roadmap of every processing step, much like an audit trail for your AI model development process.
One of the major challenges in model development is keeping track of the numerous artifacts involved, including:
Model artifacts
Data artifacts
Hyperparameter tuning artifacts
Source code
Datasets
Container images
Each component requires versioning, tracking, and backup. Source code and datasets are generally managed through version-controlled repositories and storage systems that support metadata tagging.
For example, version control tools such as GitHub or AWS CodeCommit are used for managing code, while Amazon S3 serves as a robust solution for dataset storage.
When working with container images, using Amazon Elastic Container Registry (ECR) is recommended. Each container image is uniquely tagged (e.g., “Training_v1” or “Inference_v1”) to ensure that every new build creates a distinct version without overwriting existing ones.
Enhancing Model Management with SageMaker Subservices
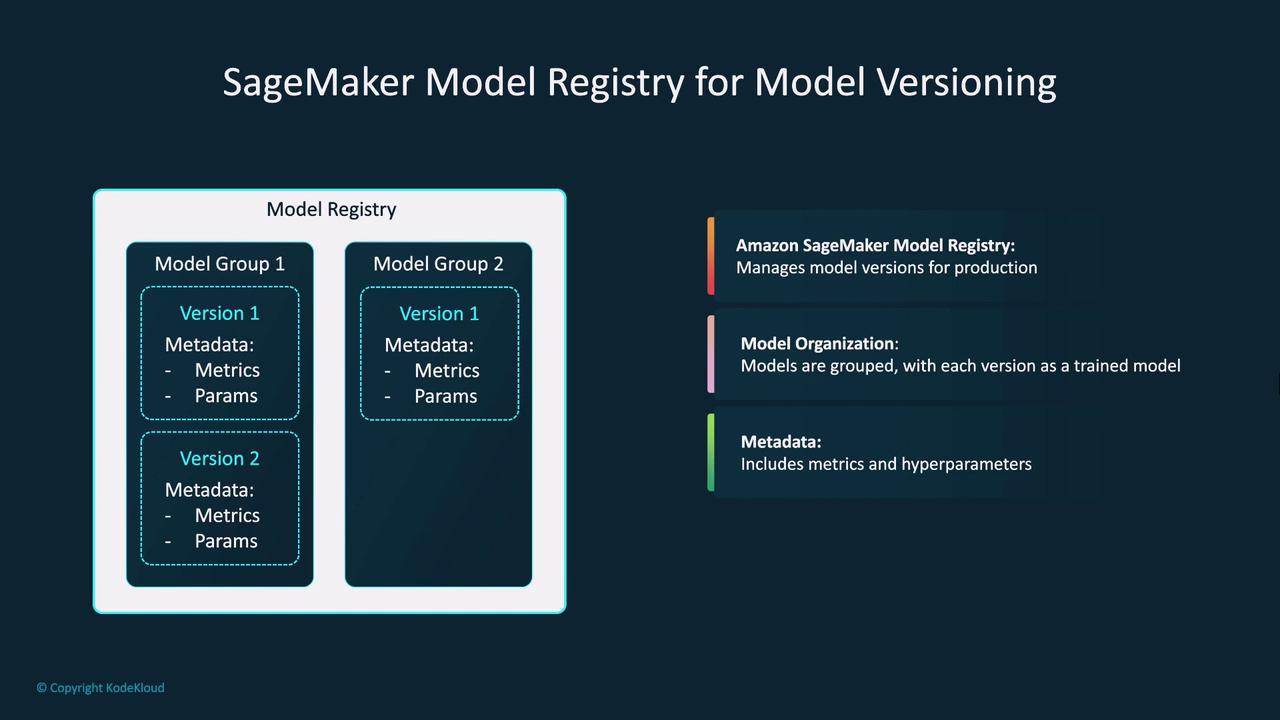
One of the standout SageMaker subservices is the Model Registry. This tool is critical for managing different versions of production models. Each model version is documented with its parameters, evaluation metrics, and associated artifacts, establishing reproducibility and compliance.
Another key tool is Model Cards, which provide detailed documentation for each model. Model Cards include:
Intended uses
Risk assessments
Training details (data sources, parameter adjustments)
Evaluation results (accuracy, precision, recall, F1 scores, etc.)
This documentation framework ensures transparency and compliance for risk managers, data scientists, and stakeholders.
Remember: Detailed documentation through tools like Model Cards is essential for regulatory compliance and understanding model behavior.
In contrast to Model Cards, SageMaker Lineage Tracking offers a graphical representation of your entire machine learning workflow. It maps the flow from datasets to container images, training jobs, and processing jobs, making it easier to pinpoint dependencies and modifications during training.
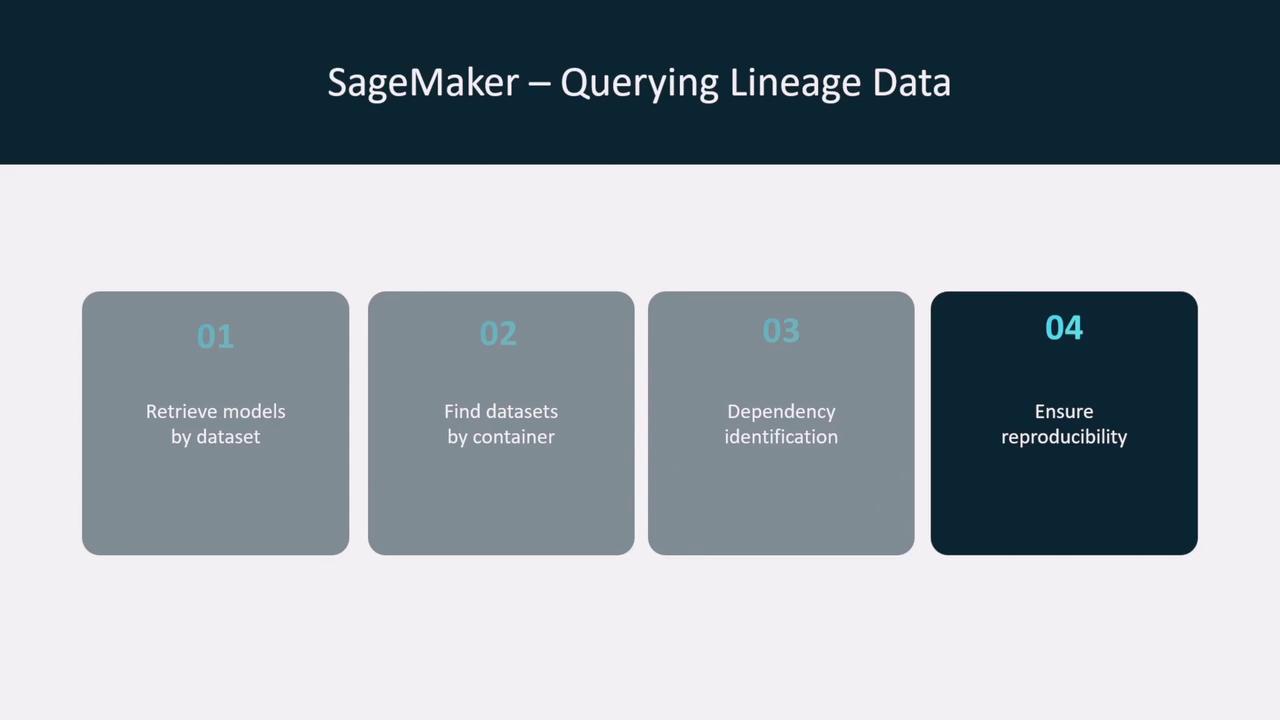
Lineage Tracking not only visualizes the workflow, but it also allows you to query and identify relationships within the process. This means you can retrieve models by dataset, find datasets linked with specific containers, and understand dependencies—crucial for replicating training processes and ensuring compliance.
Moreover, the capability to query lineage data enables you to identify all factors—including third-party libraries and custom feature transformations—that influenced a model’s outcomes.
Another impressive SageMaker subservice is the Feature Store. In this context, a “feature” refers to a specific data attribute rather than a software functionality. Feature Store centralizes and manages reusable machine learning features, facilitating:
Consistent and controlled access to key data features.
Ensured data integrity and compliance with lineage tracking.
Efficient data cataloging and point-in-time queries to validate training or inference conditions.
The table below summarizes the key benefits of SageMaker Feature Store:
Benefit
Description
Controlled Access
Ensures consistent usage of critical data attributes.
Data Integrity & Compliance
Tracks feature lineage to maintain audit trails and regulatory compliance.
Efficient Cataloging
Simplifies data feature reuse with metadata and versioning controls.
In summary, whether you are using Feature Store, Model Cards, Model Registry, or Lineage Tracking, each SageMaker subservice plays a critical role in ensuring that your data and model artifacts are well-documented, reproducible, and compliant with regulations. These capabilities are indispensable for building robust, transparent AI models.
Ensuring transparency, version control, and traceability in your machine learning workflows is essential not only for compliance but also for building reliable AI systems.
Thank you for reading this lesson. The concepts discussed here are integral to understanding AI model development’s complexities and will support your learning journey. Happy learning!