- Self-managed databases – where you set up and manage the database infrastructure yourself.
- SQL data stores (relational databases) – which rely on Structured Query Language (SQL) for querying data.
- NoSQL data stores – designed for handling semi-structured data with operational models distinct from SQL databases.
Understanding Data Structures with a Bus Analogy
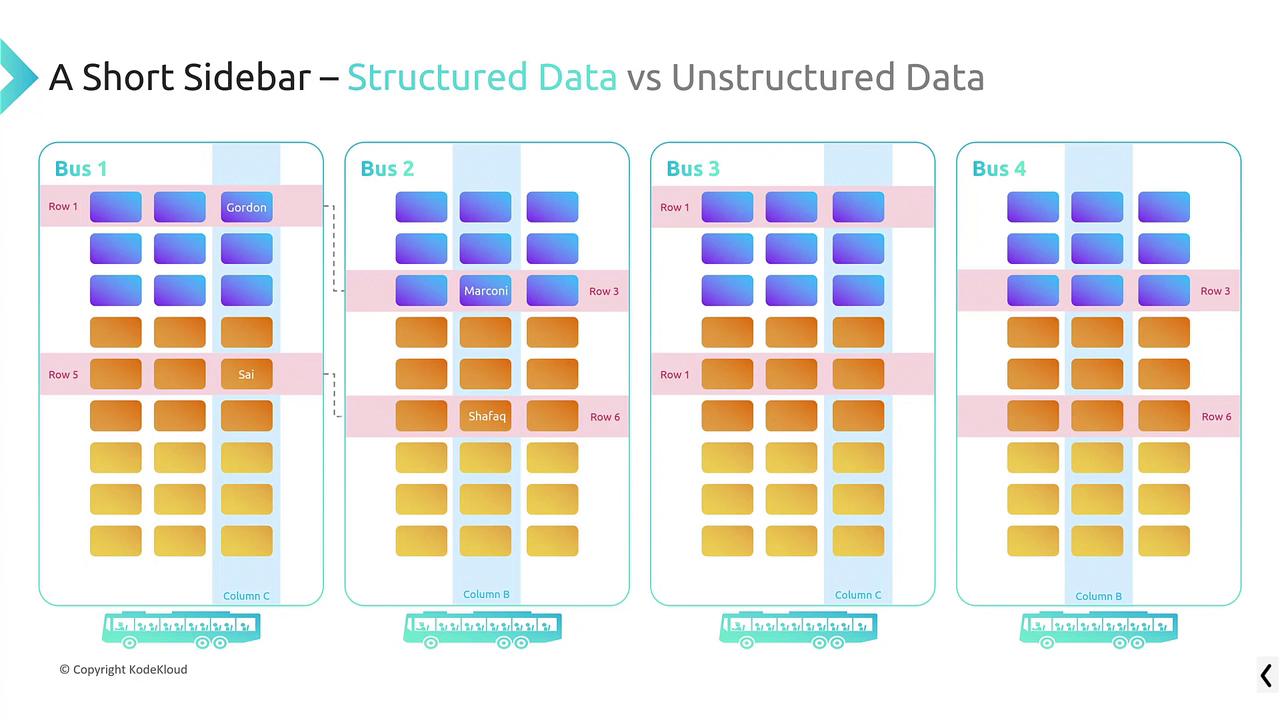
Think of a fleet of buses to understand structured data. In this analogy, each bus symbolizes a table where rows and columns are like specific seats:- In a structured data set, if Gordon occupies row one, column C, you can locate him immediately.
- Relationships, such as Gordon’s connection with Marconi in a different bus, may require changes across multiple tables.
- Structured data resembles multiple buses with fixed seating assignments.
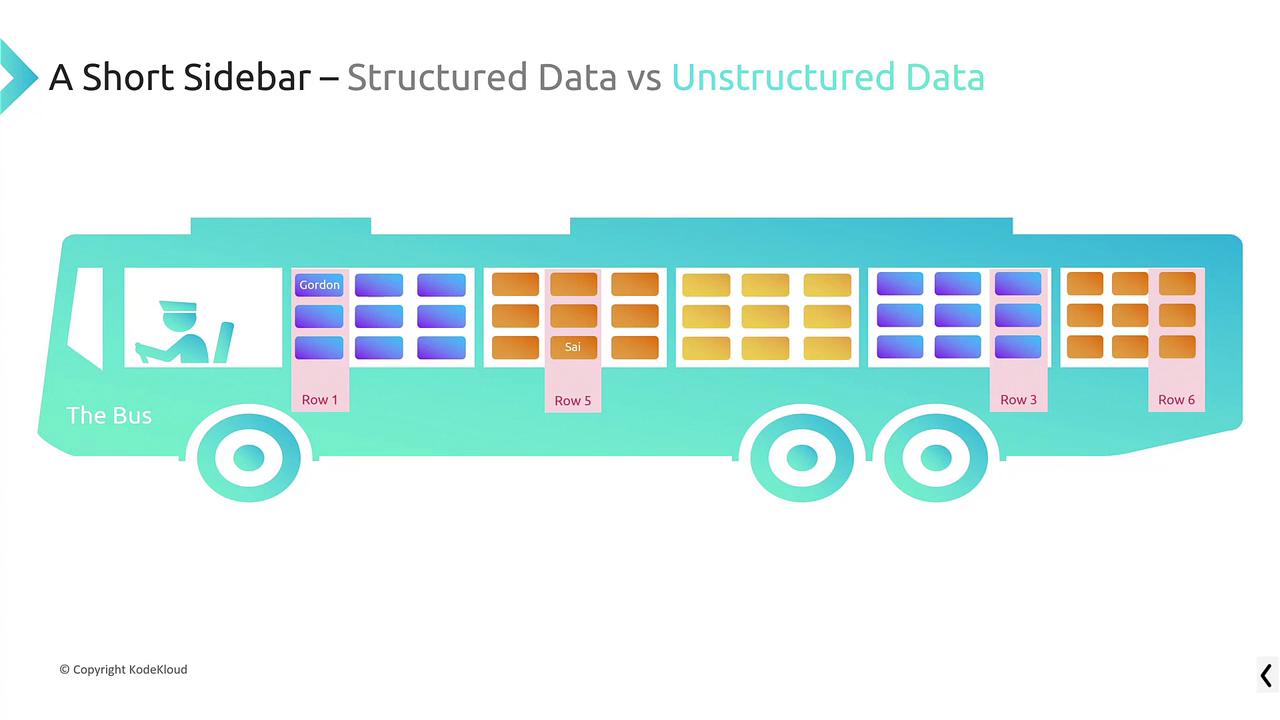
- Unstructured data is like a single, large bus where you search for an individual by a key attribute, regardless of seat arrangement.
- SQL data stores work best in environments with complex relationships, such as transactional systems.
- NoSQL data stores excel at simple, key-based lookups.

Self-Managed Database Options
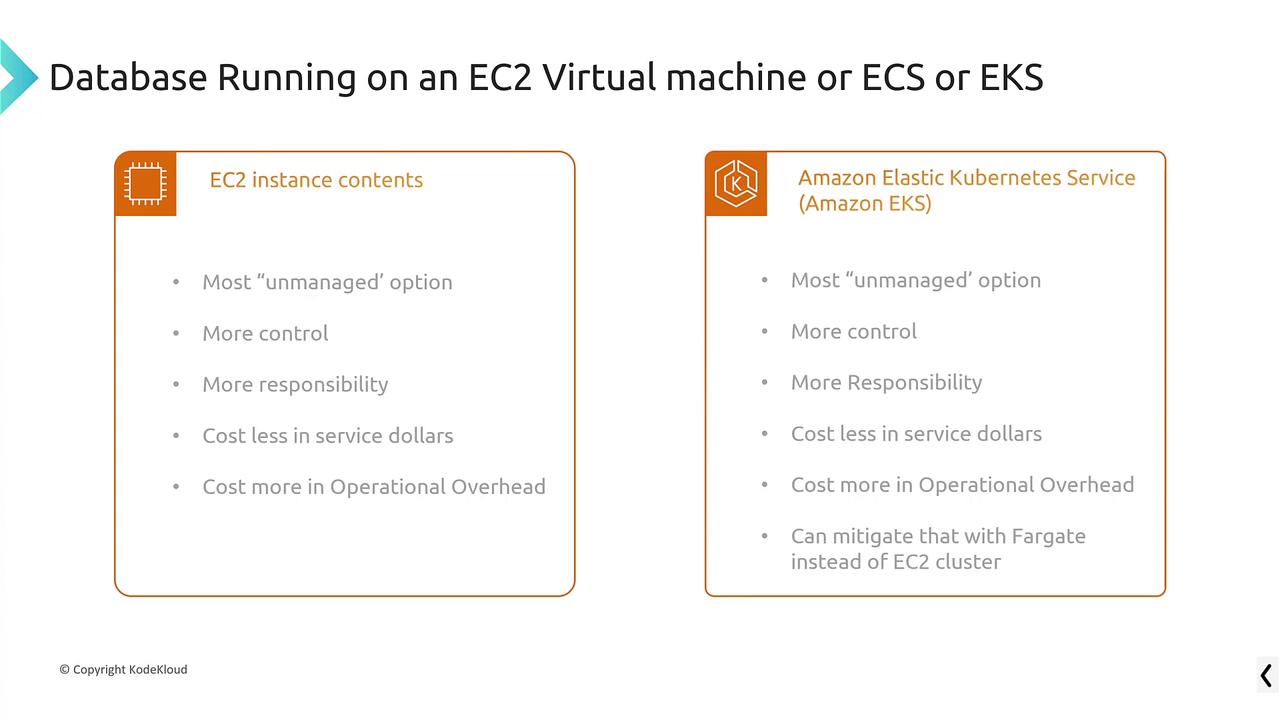
Self-managed databases provide complete control over your database software. You handle setup, operations, and maintenance—similar to owning a car where you manage insurance, repairs, and customization. On AWS, this means running your database on an EC2 instance or within containers hosted on the Elastic Container Service (ECS) or Elastic Kubernetes Service (EKS).
When using EC2, ECS, or EKS, you enjoy significant control and flexibility; however, you also assume full responsibility for operational overhead and maintenance.

SQL Database Services
Before exploring AWS SQL services, ensure you have your notebook handy. AWS offers a variety of SQL solutions that cater to different needs.Amazon RDS (Relational Database Service)
Amazon RDS is AWS’s managed relational database service supporting several database engines, including MySQL, MariaDB, PostgreSQL, Oracle, and Microsoft SQL Server. It is highly suitable for transactional processing (OLTP) environments—such as e-commerce platforms—where data consistency and defined relationships are crucial.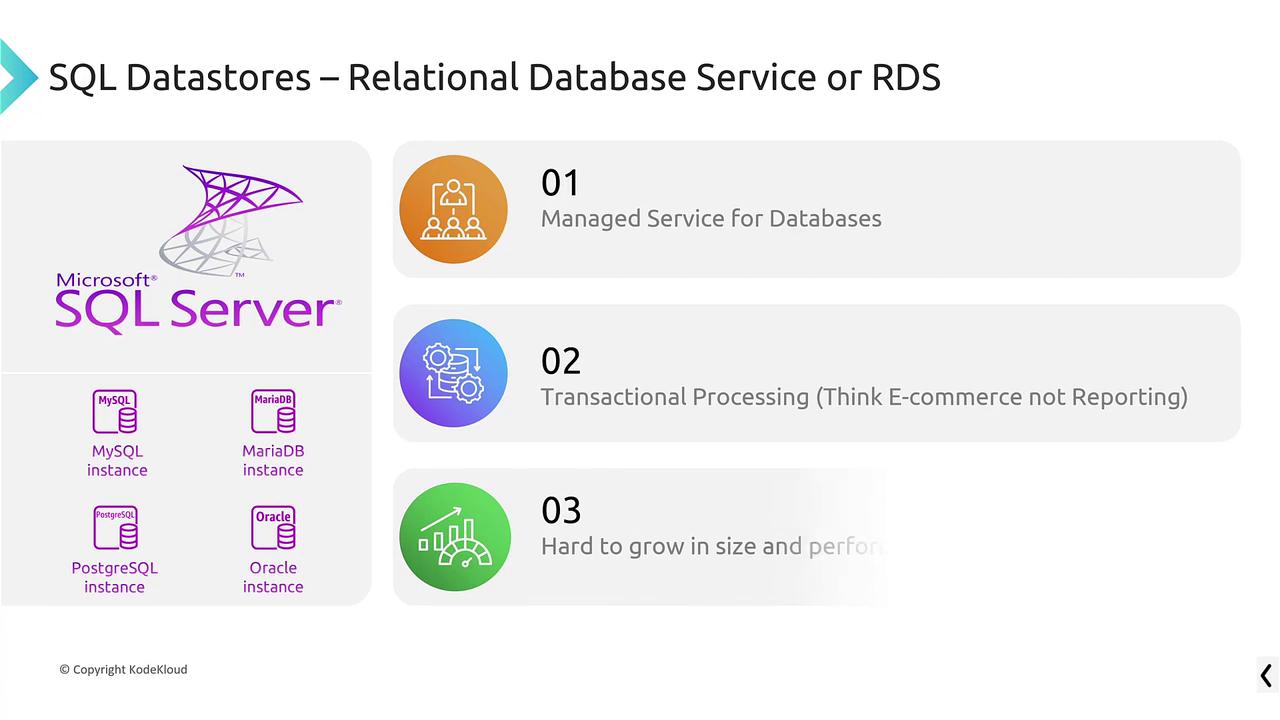
Amazon Aurora and Aurora Serverless v2
Imagine leasing a dedicated car with a driver where you only worry about the backseat; Aurora enhances MySQL and PostgreSQL with cloud-native performance improvements. It is engineered for scalability and high performance. Aurora Serverless v2 automatically scales and charges only for the compute resources you use, making it cost-effective when idle. Both offerings support MySQL and PostgreSQL.
Amazon Redshift
For large-scale reporting and analytics, transactional systems might not be the best fit. Instead, consider a data warehouse like Amazon Redshift. Redshift is designed for online analytical processing (OLAP) and manages petabytes of data, available in both server and serverless variants.

Summary of SQL Services
- Use RDS for traditional, managed relational database needs.
- Leverage Aurora or Aurora Serverless v2 for an enhanced, cloud-native relational experience with MySQL or PostgreSQL.
- Choose Redshift for data warehousing and OLAP reporting scenarios.

NoSQL Database Services
AWS NoSQL database services are optimized for unstructured or semi-structured data and high-speed lookups.Amazon DynamoDB
Amazon DynamoDB is AWS’s leading key-value and document database. It provides extremely fast, low-latency performance, making it perfect for scenarios where you retrieve all attributes with a single key search—ideal for applications like content management or real-time analytics.Amazon DocumentDB
Designed for document storage and retrieval, Amazon DocumentDB offers a MongoDB-compatible service. It excels at managing hierarchical data, making it ideal for storing customer profiles or detailed essays.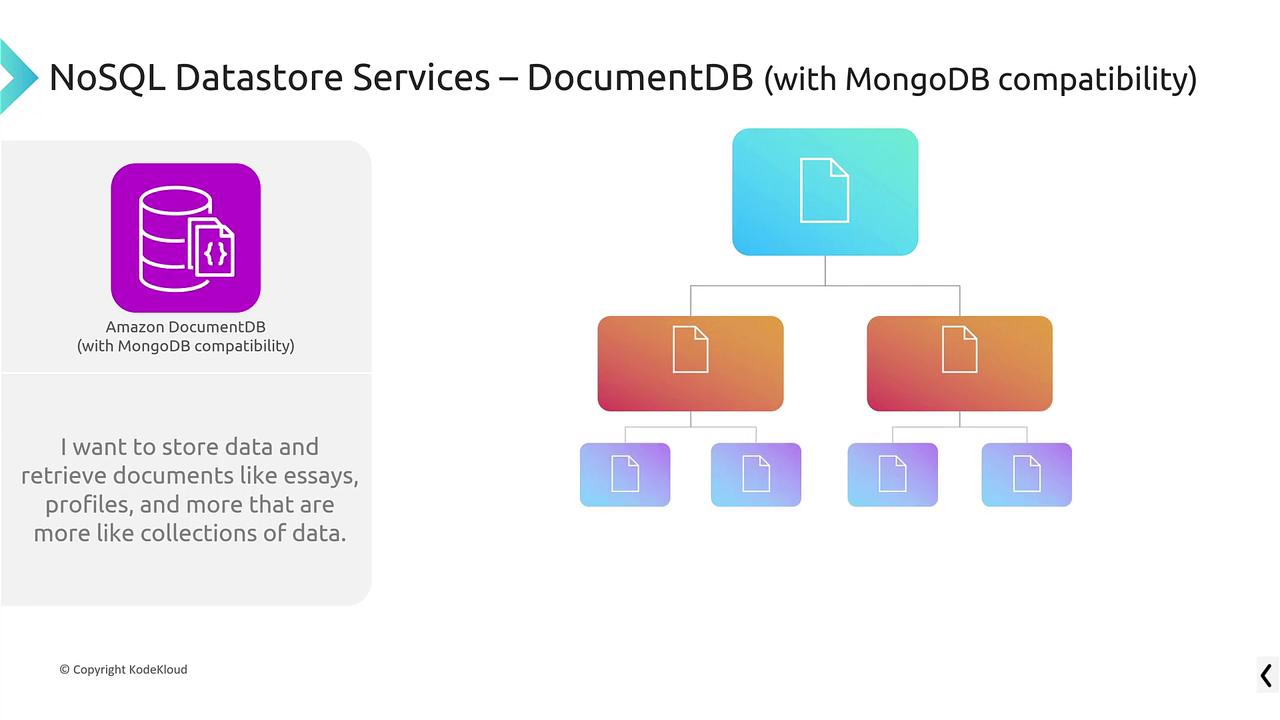
Amazon Keyspaces
Amazon Keyspaces is a scalable, globally distributed database service built for Apache Cassandra. It is tailored for semi-structured data requiring quick, worldwide access.
Amazon Neptune
For graph-based use cases like social networking or fraud detection, Amazon Neptune serves as the dedicated graph database service. It is optimized for efficiently exploring and analyzing complex data relationships.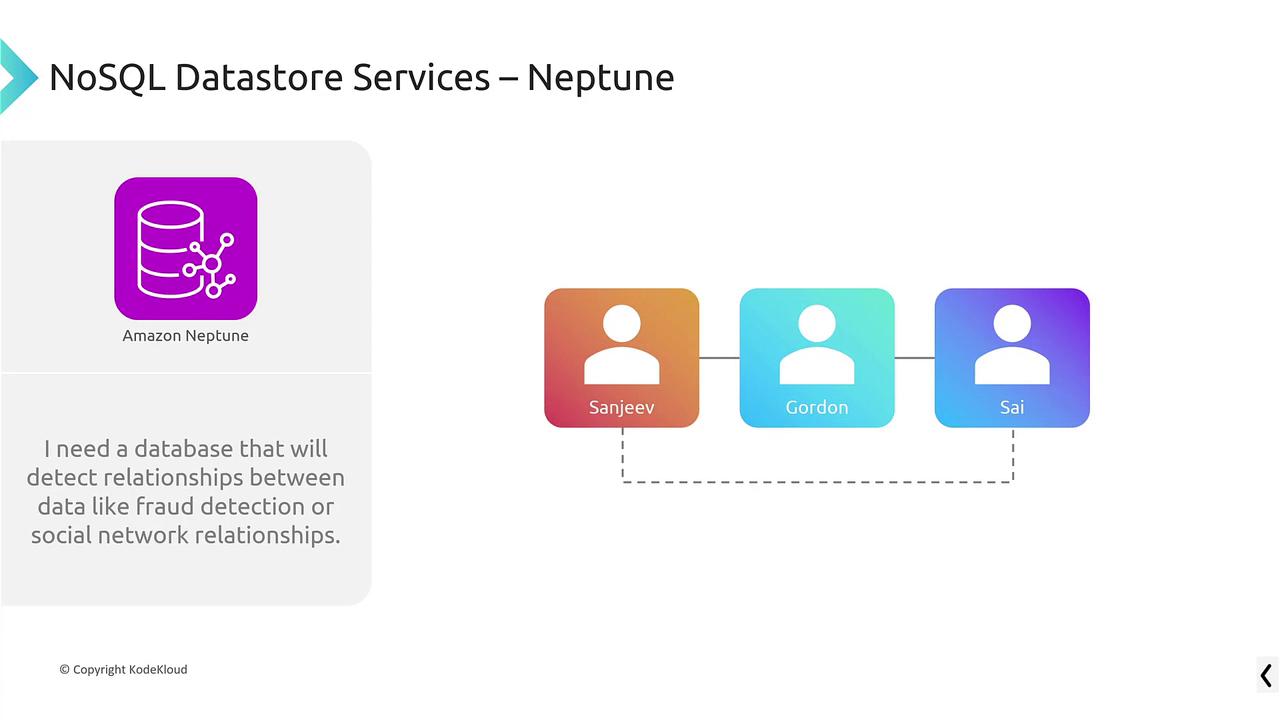
Caching Solutions: ElastiCache
Amazon ElastiCache offers two popular in-memory caching engines: Memcached and Redis. These engines significantly boost application performance by caching expensive database queries or storing transient session data.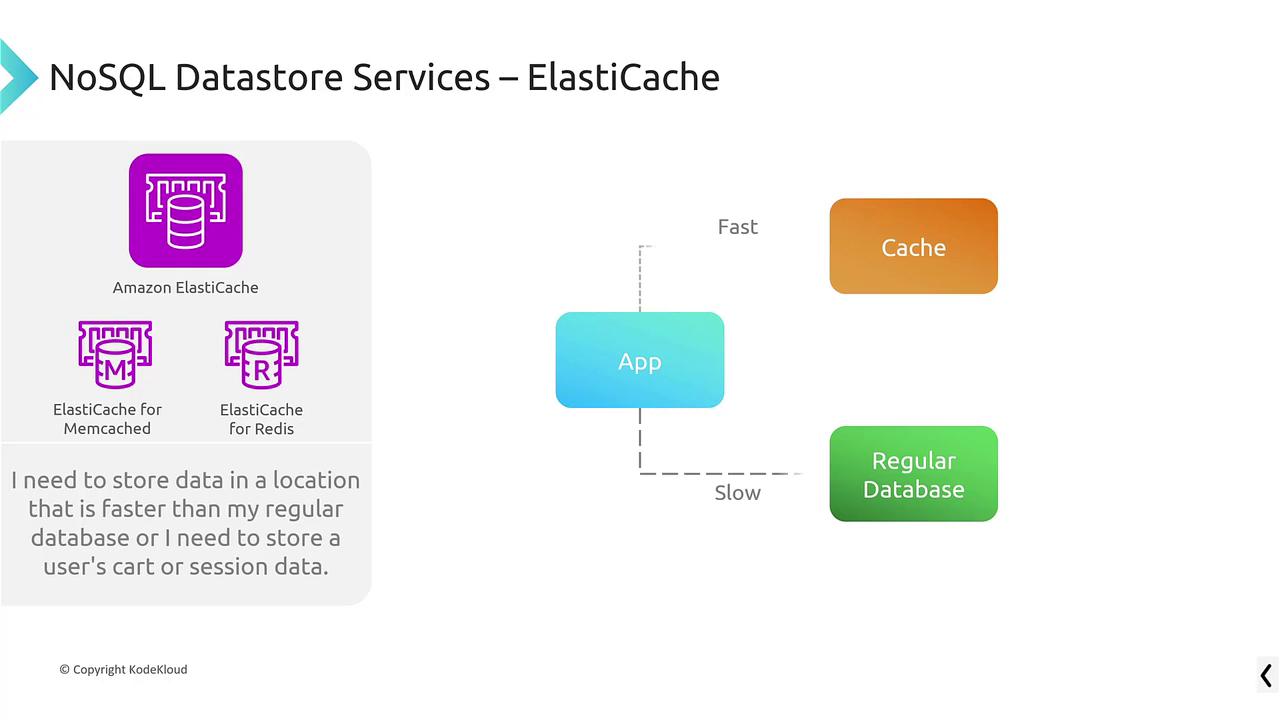
Amazon OpenSearch Service
Formerly known as Elasticsearch, Amazon OpenSearch Service is designed to index and quickly search large volumes of data. It supports features such as autocomplete and approximate matching, functioning much like a Google search for your dataset.
Amazon Quantum Ledger Database (QLDB)
Amazon QLDB is a specialized ledger database that maintains an immutable history of all transactions. Inspired by blockchain principles, it records every change along with detailed metadata—ideal for audit and compliance applications.
Amazon Timestream
Amazon Timestream is purpose-built for ingesting and analyzing time-series data, such as IoT device logs or streaming data. It automatically timestamps incoming data to facilitate efficient event analysis over time.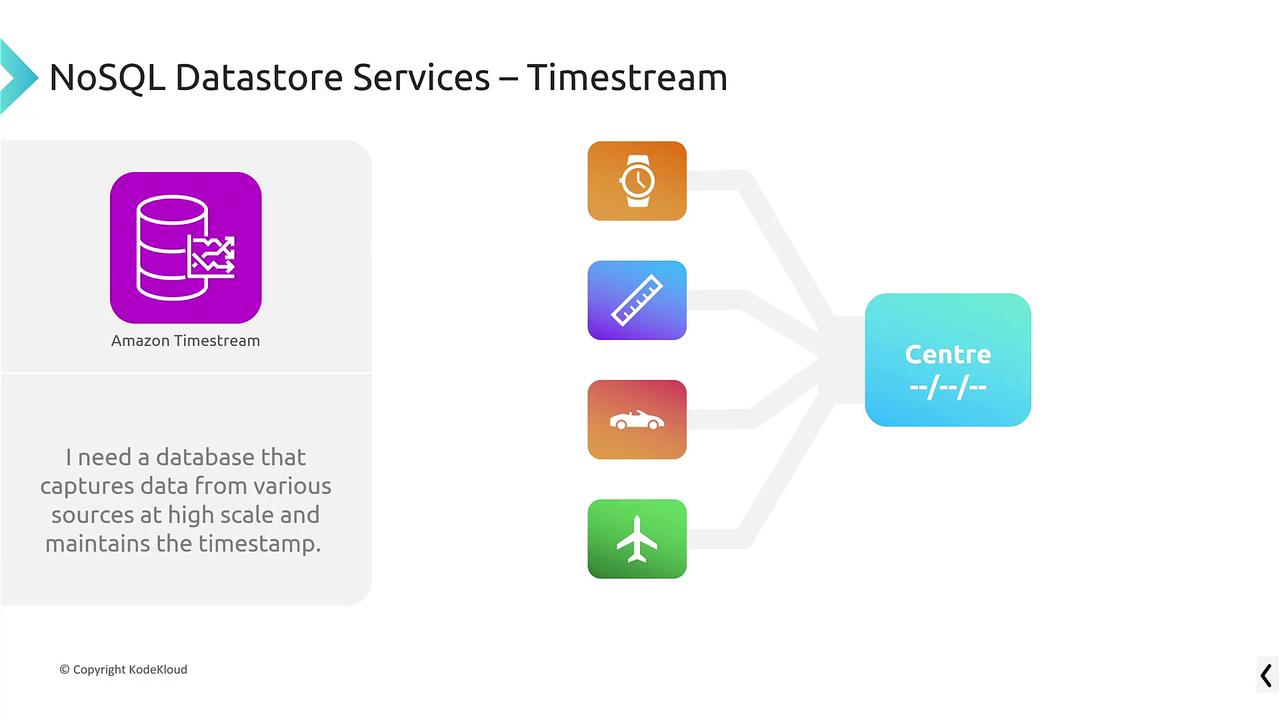
Overview and Use Cases
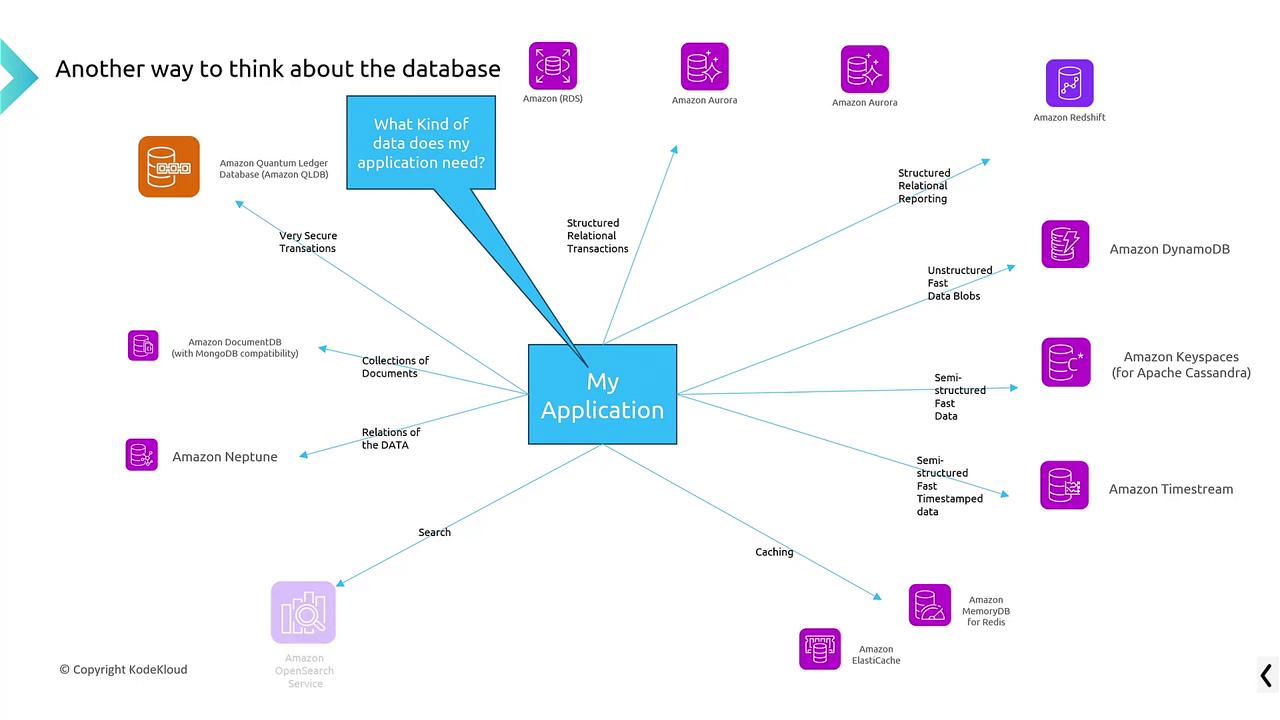
When selecting an AWS database service, consider the following guidelines:- For structured, relational, transactional databases, use Amazon RDS or Aurora (including Aurora Serverless v2).
- For structured reporting and analytics, Amazon Redshift is optimal.
- For fast, key-value lookups and handling large unstructured data, choose DynamoDB.
- Store hierarchical document data with Amazon DocumentDB.
- Use Amazon Keyspaces for globally distributed, Apache Cassandra-compatible requirements.
- Boost application performance with in-memory caching via Amazon ElastiCache (or MemoryDB for Redis).
- Implement fast search capabilities using Amazon OpenSearch Service.
- Explore data relationships with Amazon Neptune for graph-based data.
- Maintain an immutable transaction record with Amazon QLDB.
- Manage time-series data efficiently with Amazon Timestream.
Final Summary
- Self-managed databases grant unparalleled control but require managing operational overhead.
- SQL solutions include Amazon RDS, Amazon Aurora (with Aurora Serverless v2), and Amazon Redshift for OLTP and OLAP use cases.
- NoSQL services like DynamoDB, DocumentDB, Keyspaces, Neptune, ElastiCache, OpenSearch, QLDB, and Timestream offer targeted solutions for diverse data requirements.
