What You’ll Learn
- Why transformers have become the foundation of sequence models
- The mechanics behind self-attention, multi-head attention, and positional encoding
- How transformer-based generative AI works
- Key advantages that make transformers so powerful
- Practical applications in text, code, and image generation
1. Why Transformers Matter
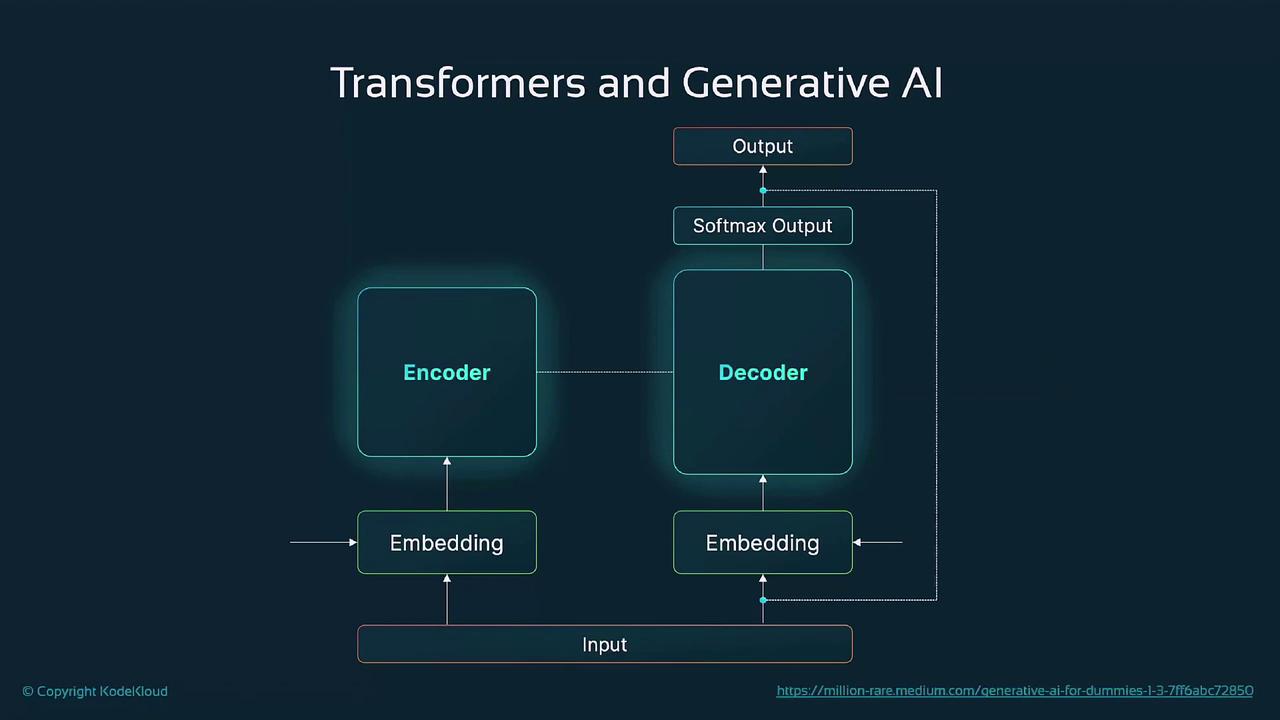
Before transformers, RNNs and LSTMs processed tokens sequentially, which limited long-range dependency capture and slowed down training. Transformers introduced self-attention, allowing all tokens to interact simultaneously and harness parallel hardware like GPUs/TPUs.Self-attention computes attention scores by projecting token embeddings into query, key, and value vectors, enabling the model to weigh the importance of each token pair in a single step.
2. Anatomy of a Transformer
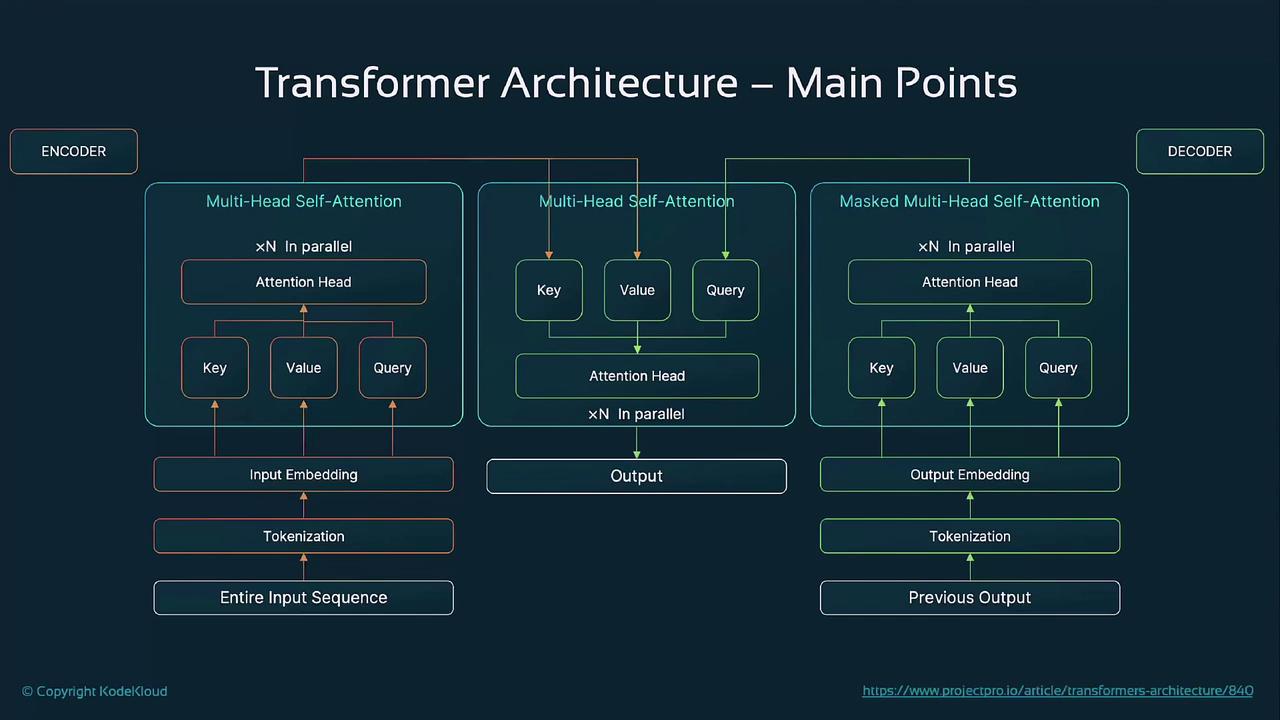
The transformer’s power comes from three core ideas:2.1 Self-Attention Mechanism
- Embedding Tokens
Each input token is mapped to a high-dimensional vector. - Computing Attention Scores
Queries (Q), Keys (K), and Values (V) are derived from embeddings. Attention weights are computed as softmax(QKT / √dₖ). - Weighted Sum
Each token’s output is a weighted sum of V vectors, where weights reflect token relevance.
2.2 Multi-Head Attention
Multiple attention “heads” run in parallel, each learning different relationships. Their outputs are concatenated and linearly transformed, improving representation richness.2.3 Positional Encoding
Since attention is position-agnostic, transformers add sinusoidal positional encodings to embeddings. This injects information about token order without requiring recurrence.Training large transformer models can demand hundreds of GPUs/TPUs and vast memory. Ensure you have sufficient compute resources before scaling up.
3. Overview of Generative AI
Generative AI synthesizes new data—text, images, code, audio—by learning patterns from large datasets. Unlike traditional AI, which focuses on classification or prediction, generative models create novel content.4. Transformers in Generative AI
Transformer-based models like GPT-4 use a next-token prediction objective:- Pre-training
The model learns to predict the next token across billions of text sequences, capturing grammar, facts, and reasoning patterns. - Fine-tuning or Direct Use
After pre-training, you can specialize the model on domain-specific data or use it directly for tasks such as summarization, translation, or creative writing. - Generation
At inference, self-attention considers the full prompt context, and a softmax layer chooses each next token to produce coherent, contextually relevant output.
5. Why Transformers Are So Powerful
Transformers combine three key strengths:- Massive Parallelism for fast training and inference on long sequences
- Deep Contextualization via self-attention, capturing dependencies across entire inputs
- Modality Agnostic Design that applies to text, images, code, and audio
6. Real-World Applications
Transformers are at the heart of many production systems: