Overview
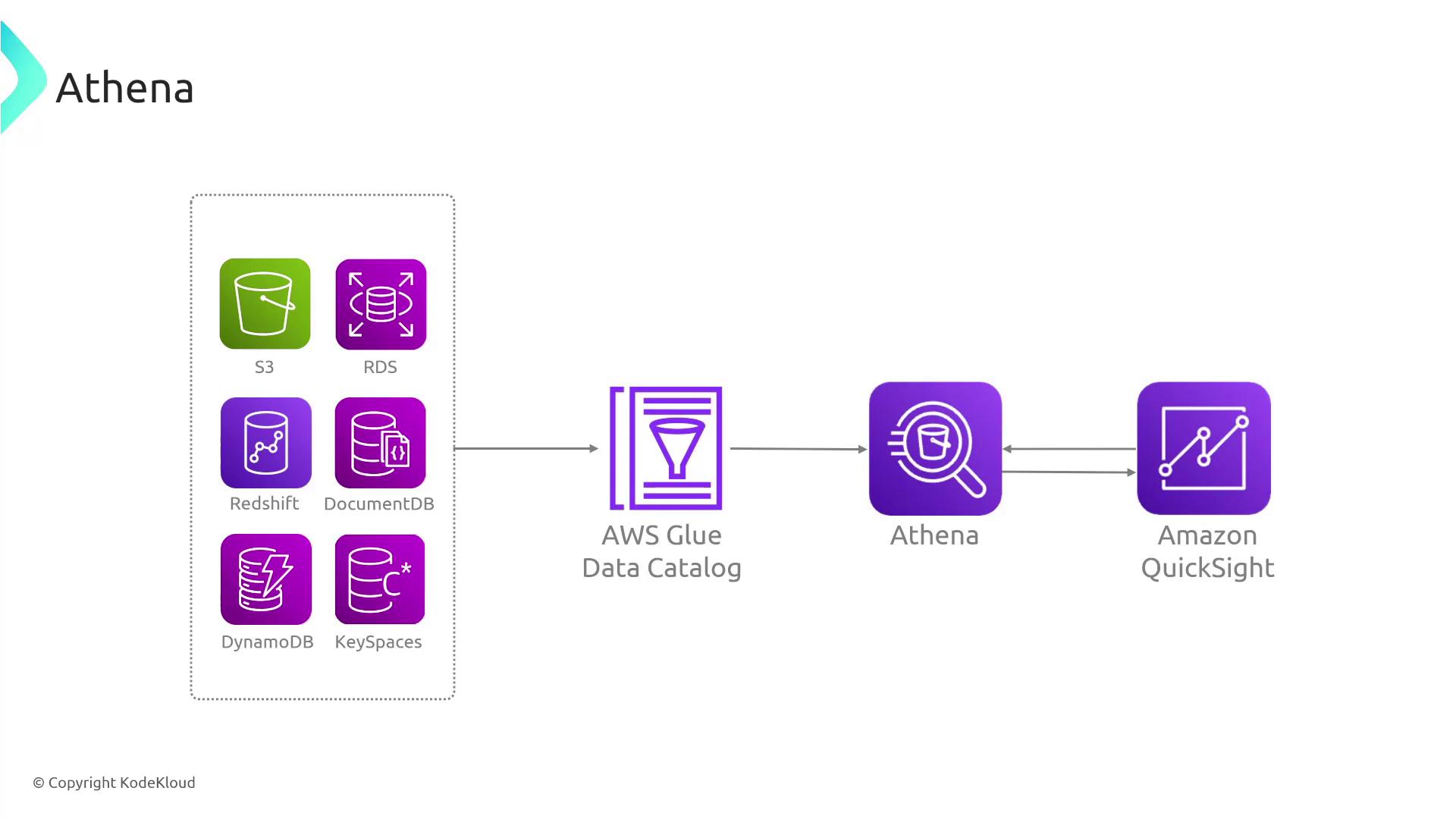
AWS Athena is designed to efficiently analyze both structured and unstructured data. It leverages the AWS Glue Data Catalog as a metadata repository, enabling you to perform SQL queries on data that has been extracted and transformed from various sources. Typical data sources include sales transactions, operational metrics, and more. The data processing workflow generally follows these key steps:- Ingest raw data from diverse sources.
- Use AWS Glue to extract, clean, and convert data into efficient formats (e.g., Parquet, CSV, ORC).
- Store the processed data in an S3 bucket.
- Catalog the dataset with the AWS Glue Data Catalog.
- Query the data using AWS Athena with SQL.
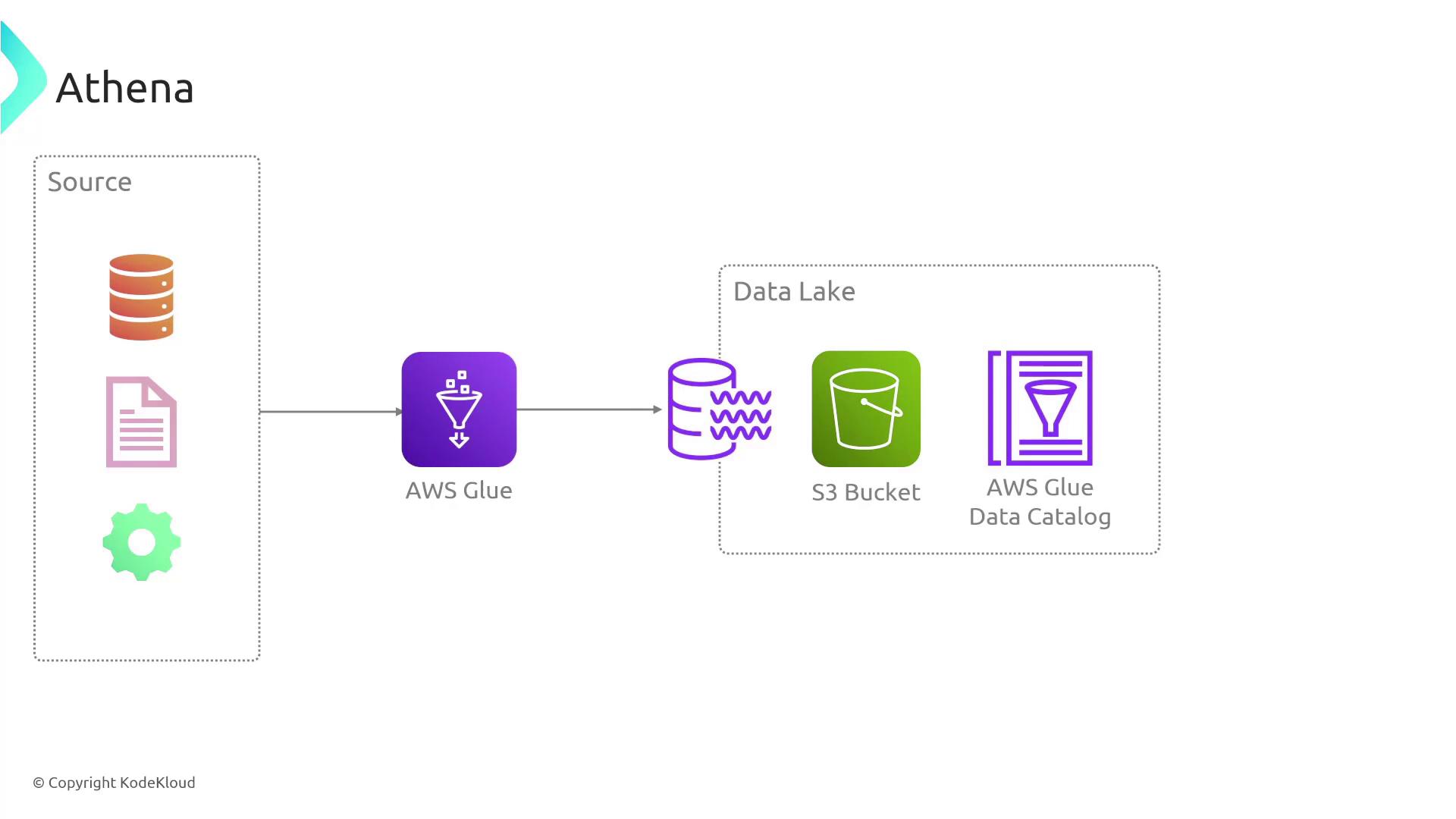
Athena allows you to execute complex, ad hoc queries without managing any underlying infrastructure, making it both simple and cost-effective.
Integration with Visualization Tools
After running queries in Athena, you can seamlessly integrate the results with Amazon QuickSight for data visualization. QuickSight automatically updates dashboards based on the latest Athena query results, streamlining your data analysis and reporting workflow.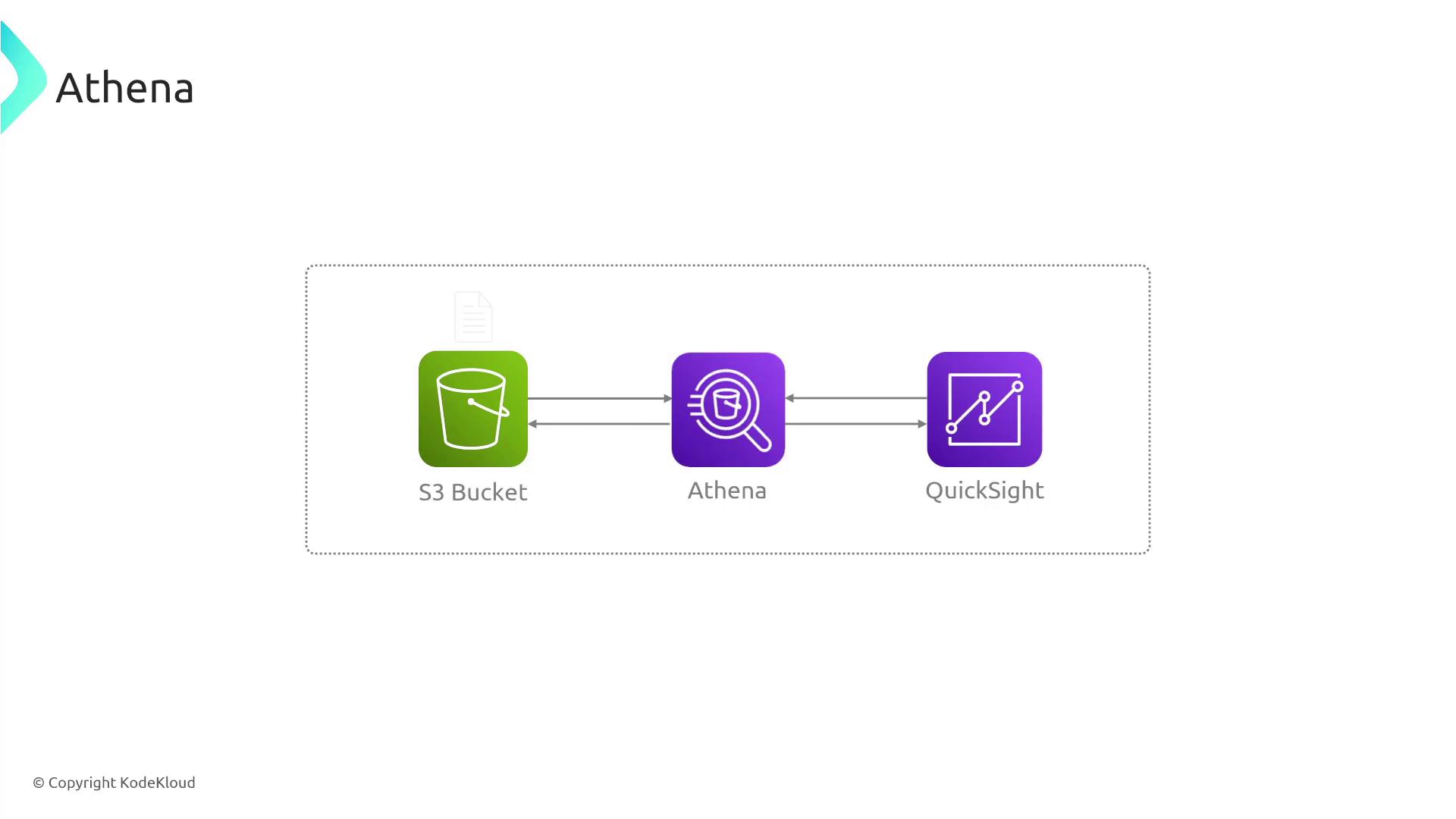
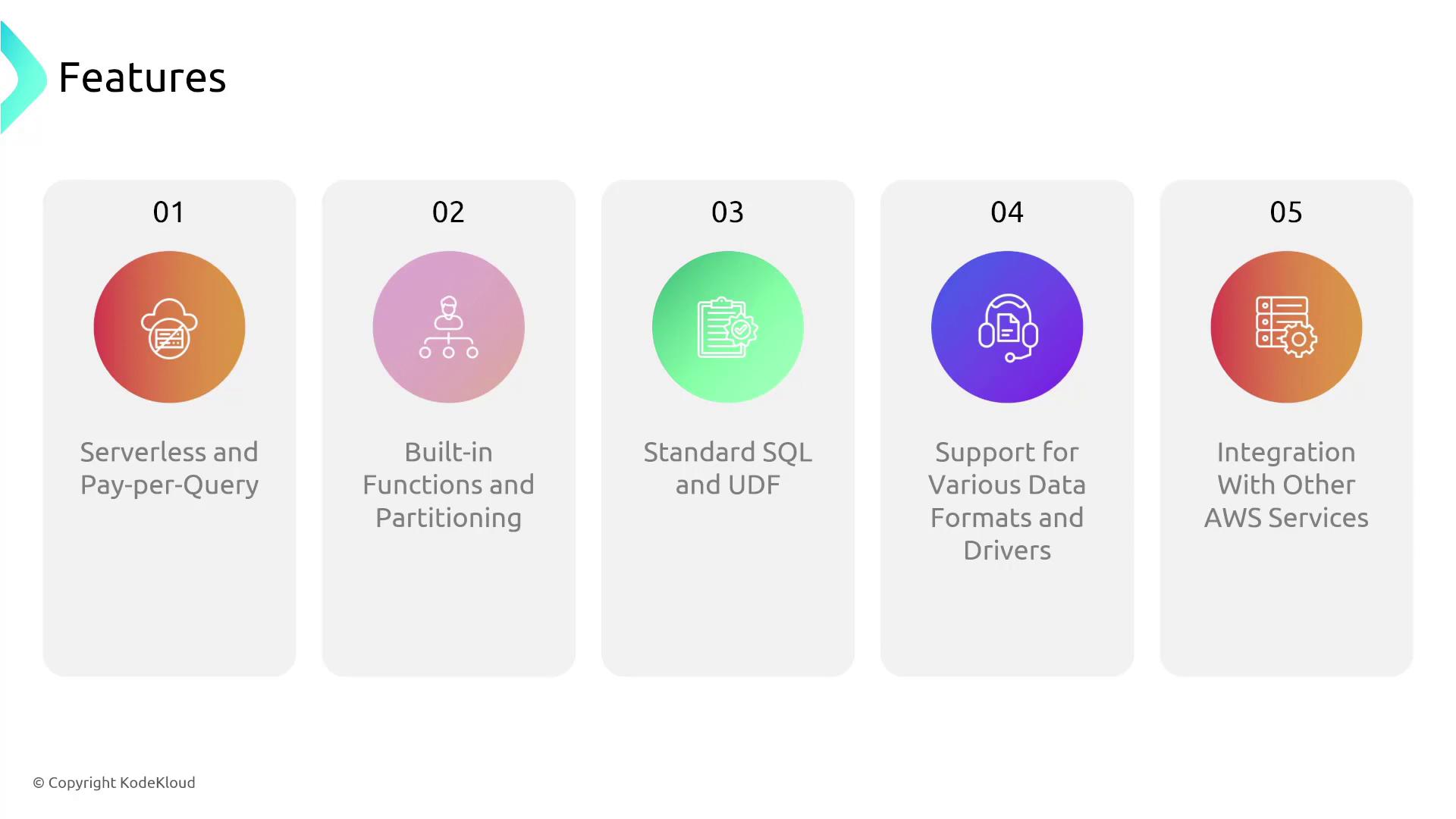
Key Features
- Serverless and Cost-Efficient: Athena is fully serverless, meaning you only pay for your query execution time.
- Performance Optimization: Benefit from built-in functions and data partitioning to significantly boost query performance.
- Standard SQL and UDF Support: Use standard SQL along with user-defined functions (UDFs) written in Java for customized operations.
- Multiple Data Format Support: Query datasets stored in a variety of formats such as Parquet, ORC, JSON, CSV, and TSV.
- Broad Integration: Compatible with JDBC and ODBC drivers, Athena easily serves as a data source for popular BI tools like Power BI, and integrates seamlessly with numerous AWS services.
Conclusion
AWS Athena provides a fast, scalable, and cost-effective way to perform ad hoc SQL queries on large datasets stored in Amazon S3. With effective integration with AWS Glue for data cataloging and Amazon QuickSight for visualization, you can quickly derive insights without the complexity of traditional database management. Whether analyzing customer purchase trends or monitoring operational metrics, Athena is a robust solution for your data analytics needs.For more details on how to optimize your queries and integrate Athena with other AWS services, visit the AWS Athena Documentation.