Understanding Data Warehouses
Data warehouses consolidate data from various sources such as relational databases, log systems, cloud storage, and more. Their primary goal is to provide a unified view of your data, which is critical for making informed business decisions. Unlike traditional databases that focus on transactional operations (inserts, updates, and deletes), data warehouses excel at analytical operations, such as complex queries and reporting. Key points about data warehouses include:- They store historical data that is essential for tracking changes, identifying trends, and performing comparative analysis.
- They incorporate ETL (Extract, Transform, Load) processes to ensure data is cleaned, transformed, and aggregated for quality and consistency.
- They work on structured data at an aggregate level, simplifying large-scale analytics.
- They scale effectively by increasing compute and storage resources as data and query loads grow.
- They often prove more cost-effective for analytical workloads compared to traditional databases.
Introduction to AWS Redshift
AWS Redshift is designed for handling extremely large data sets with enterprise-class performance. Its ability to support a wide range of client connections makes it perfect for business intelligence (BI), reporting, and analytical applications. With Redshift, you benefit from efficient storage, optimized query performance, and seamless integration with various data sources and analytics tools.
Redshift Architecture and Components
Redshift’s architecture comprises several key components that collaborate to deliver high performance and scalability.Clusters and Nodes
The core of a Redshift data warehouse is the cluster:- A cluster consists of one or more compute nodes.
- Once a cluster has multiple compute nodes, a leader node is introduced to coordinate compute nodes and manage external communications with client applications.
- Handles communications with client programs.
- Parses SQL queries, develops execution plans, and distributes compiled code to compute nodes.
- Delegates query operations by assigning portions of the data to each compute node. (Note: Simple queries run exclusively on the leader node, while more complex queries referencing tables stored on compute nodes are distributed accordingly.)
Data Storage
Redshift decouples data storage from compute resources using Redshift Managed Storage (RMS):- RMS leverages Amazon S3 to scale storage to petabytes.
- Compute and storage resources can be scaled independently, allowing clusters to be sized based solely on compute needs.
- It utilizes high-performance SSD-based local storage as a tier-one cache for frequently accessed data.
Database Component
Inside each cluster, one or more databases are maintained. AWS Redshift is a relational database management system (RDBMS) based on PostgreSQL. Despite the similarities, Redshift is optimized specifically for data warehousing applications.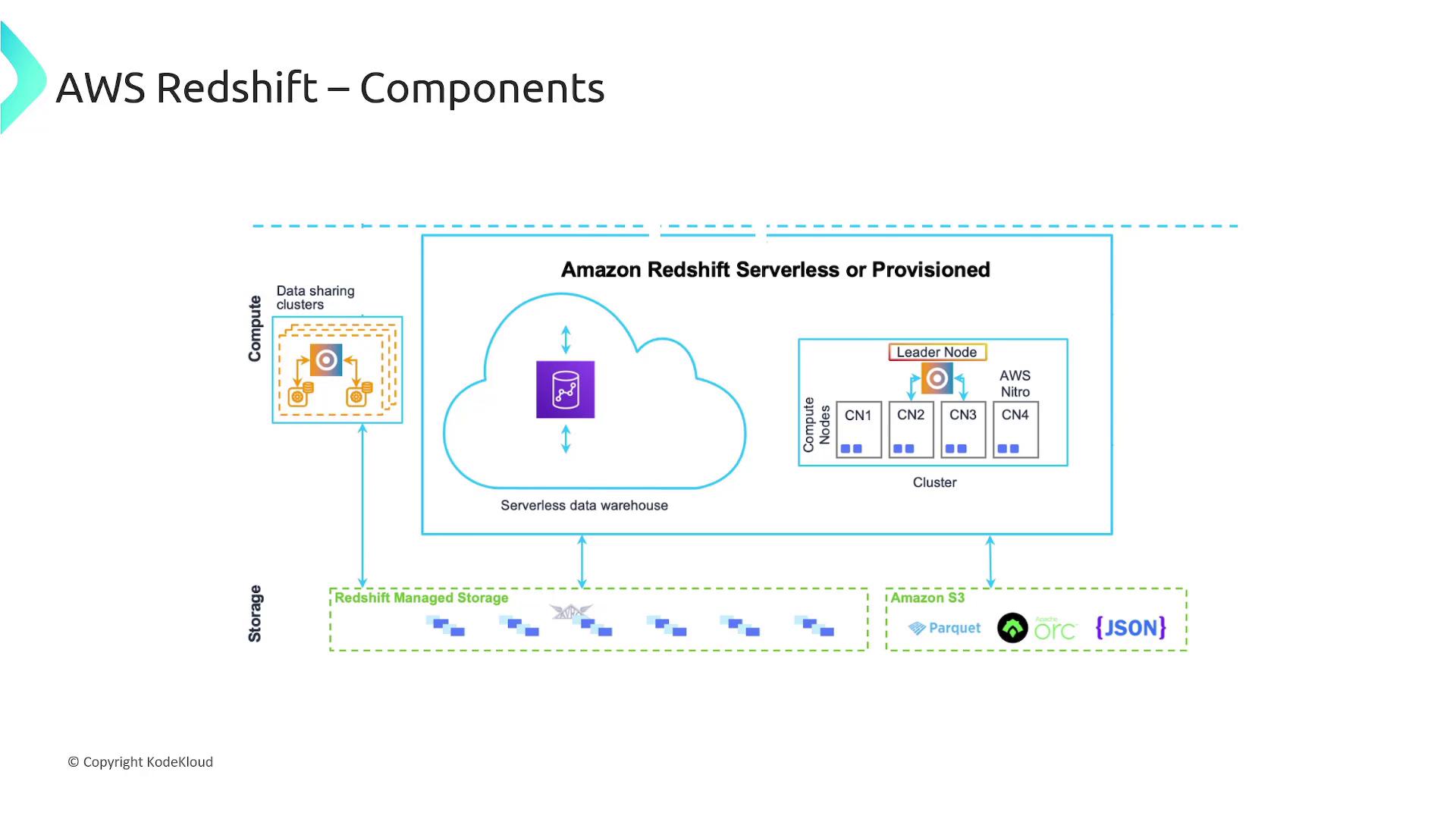
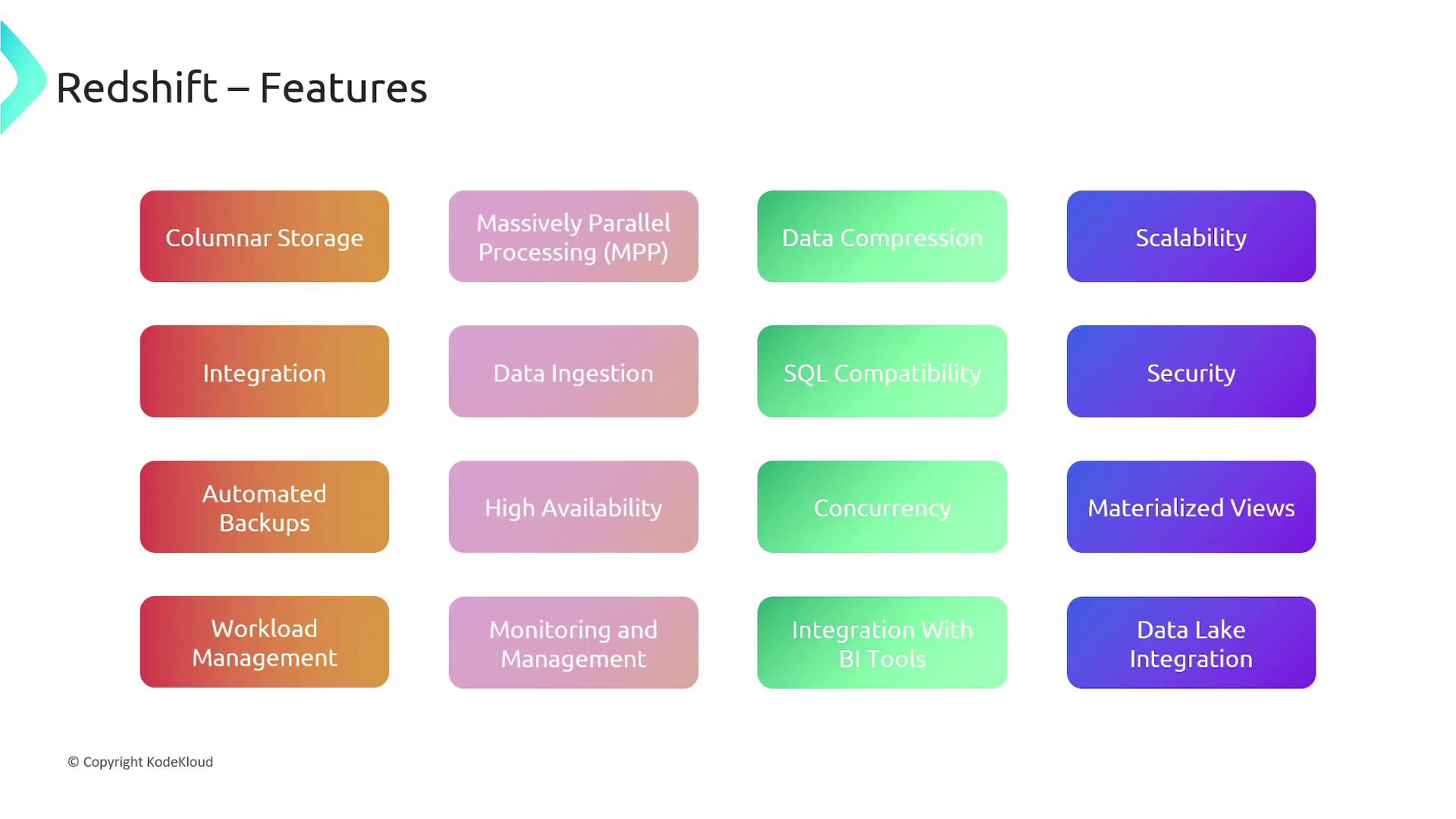
Core Features of Redshift
AWS Redshift offers a rich set of features that empower efficient and secure data warehousing:- Columnar Storage: Speeds up query performance by reading only the necessary columns from disk.
- Massively Parallel Processing (MPP): Distributes query processing across multiple nodes to accelerate execution.
- Automatic Data Compression: Minimizes storage requirements and enhances query performance.
- Elastic Scalability: Adjust compute resources dynamically by adding or removing nodes based on demand.
- Integration with Diverse Data Sources: Provides seamless connections with Amazon S3, Amazon RDS, EMR, and other data sources.
- Data Ingestion Methods: Simplifies data ingestion with COPY commands and direct loading from Amazon S3.
- Standard SQL Support: Enables the use of familiar SQL queries and reporting tools.
- Enhanced Security: Offers encryption at rest and in transit, fine-grained access control, and AWS IAM integration.
- Automated Backups and High Availability: Features continuous automated backups, multi-node clusters, automated failovers, and read replicas.
- Materialized Views: Stores precomputed aggregated data for faster retrieval during complex queries.
- Workload Management: Efficiently allocates query resources through integrated workload management.
- BI Tool Integration: Easily integrates with popular business intelligence tools.
- Data Lake Integration: Combines structured data in Redshift with semi-structured and unstructured data in data lakes for comprehensive analytics.
For a quick comparison of resource types, consider the following table:
| Resource Type | Use Case | Example |
|---|---|---|
| Pod | Basic unit of deployment | kubectl run nginx --image=nginx |
| Deployment | Managed pods with scaling | kubectl create deployment nginx --image=nginx |
| Service | Network access to pods | kubectl expose deployment nginx --port=80 |
Use Cases for Redshift
Redshift is versatile and meets a wide range of analytical and data processing requirements, including:- Enhancing financial and demand forecasting through advanced predictive analytics.
- Securely sharing data across accounts, organizations, and partner ecosystems.
- Building insightful reports and dashboards using industry-standard business intelligence tools.
- Simplifying data ingestion and access from diverse programming languages and platforms without complex configurations.
Summary of Redshift
AWS Redshift stands out as a robust, fully managed, petabyte-scale data warehouse service that delivers:- Two Node Types:
- The leader node to manage query coordination.
- Compute nodes to execute queries and store data.
- Optimized Storage: Automatic data compression and efficient storage architecture to reduce I/O operations.
- Strong Security: Implements encryption at rest, fine-grained access control, and AWS IAM integration to safeguard your data.
- Elastic Scalability: Automatically adjusts capacity to handle fluctuating query loads.
- Backup and Recovery: Provides automated snapshots to Amazon S3 for reliable point-in-time recovery.

For further information, check out these useful links: