Prometheus not only gathers current metrics but also stores historical data, enabling you to investigate trends and diagnose issues retrospectively.
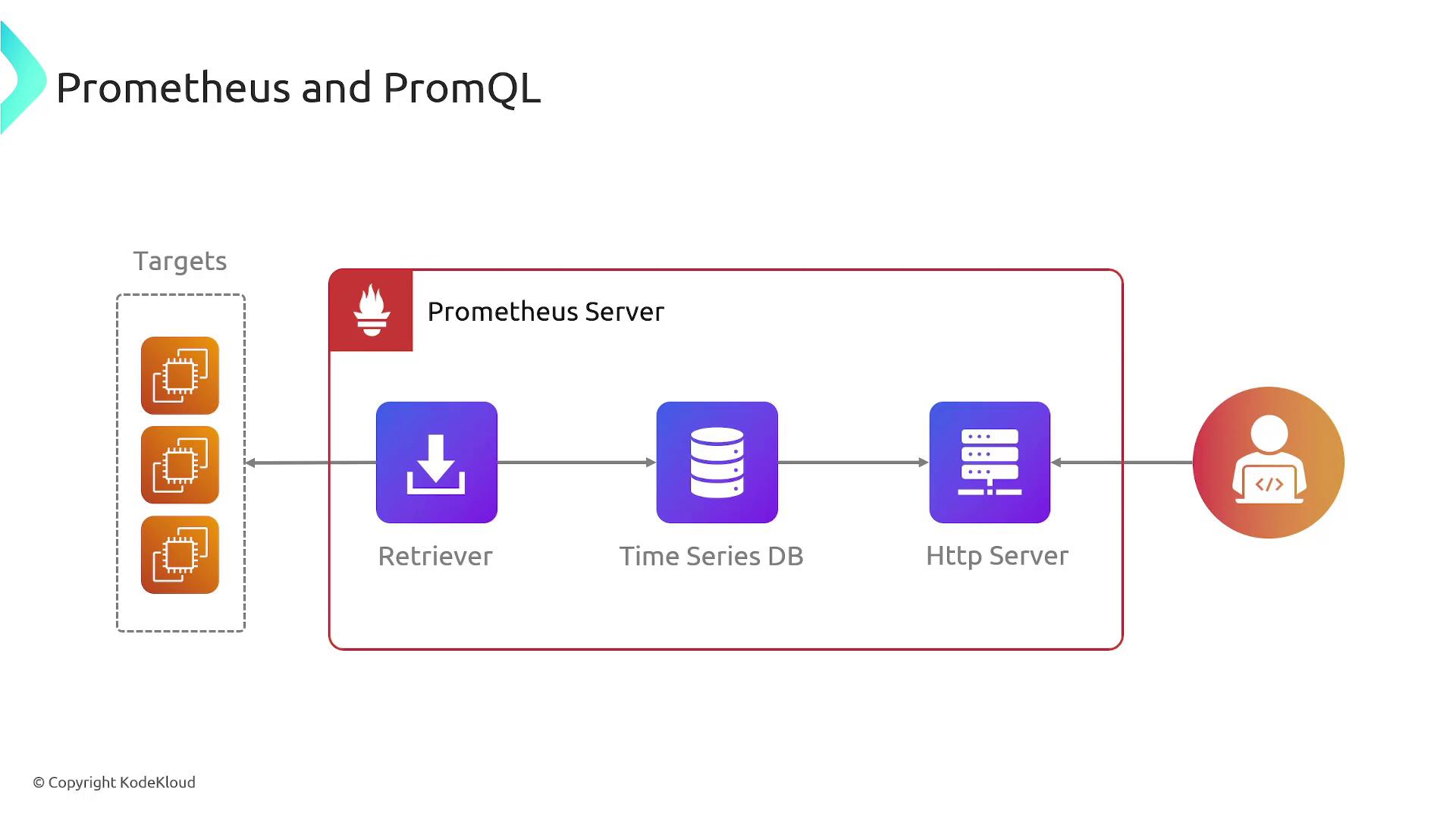
Prometheus Architecture
Understanding the core components of Prometheus is key to leveraging its full potential. The primary elements include:- Targets: These are the services or applications from which metrics are collected.
- Receiver: This component gathers metrics from targets by sending HTTP requests at defined intervals.
- Time Series Database: Metrics are stored here, making historical analysis efficient and responsive.
- HTTP Server: Provides an interface for querying metrics using PromQL, facilitating data analysis and visualization.
Managed Prometheus on AWS
Managing a Prometheus server can be challenging due to the necessity of ensuring its health, handling high traffic, and scaling resources as needed. Amazon Managed Prometheus simplifies these challenges by handling the underlying infrastructure, allowing you to focus on monitoring and analysis. Metrics from various services—such as those running on an Amazon Elastic Container Service (AWS ECS) cluster—can be seamlessly directed to the managed Prometheus instance. Once the data is in the system, you can query these metrics with PromQL or visualize them using dashboarding tools like Grafana.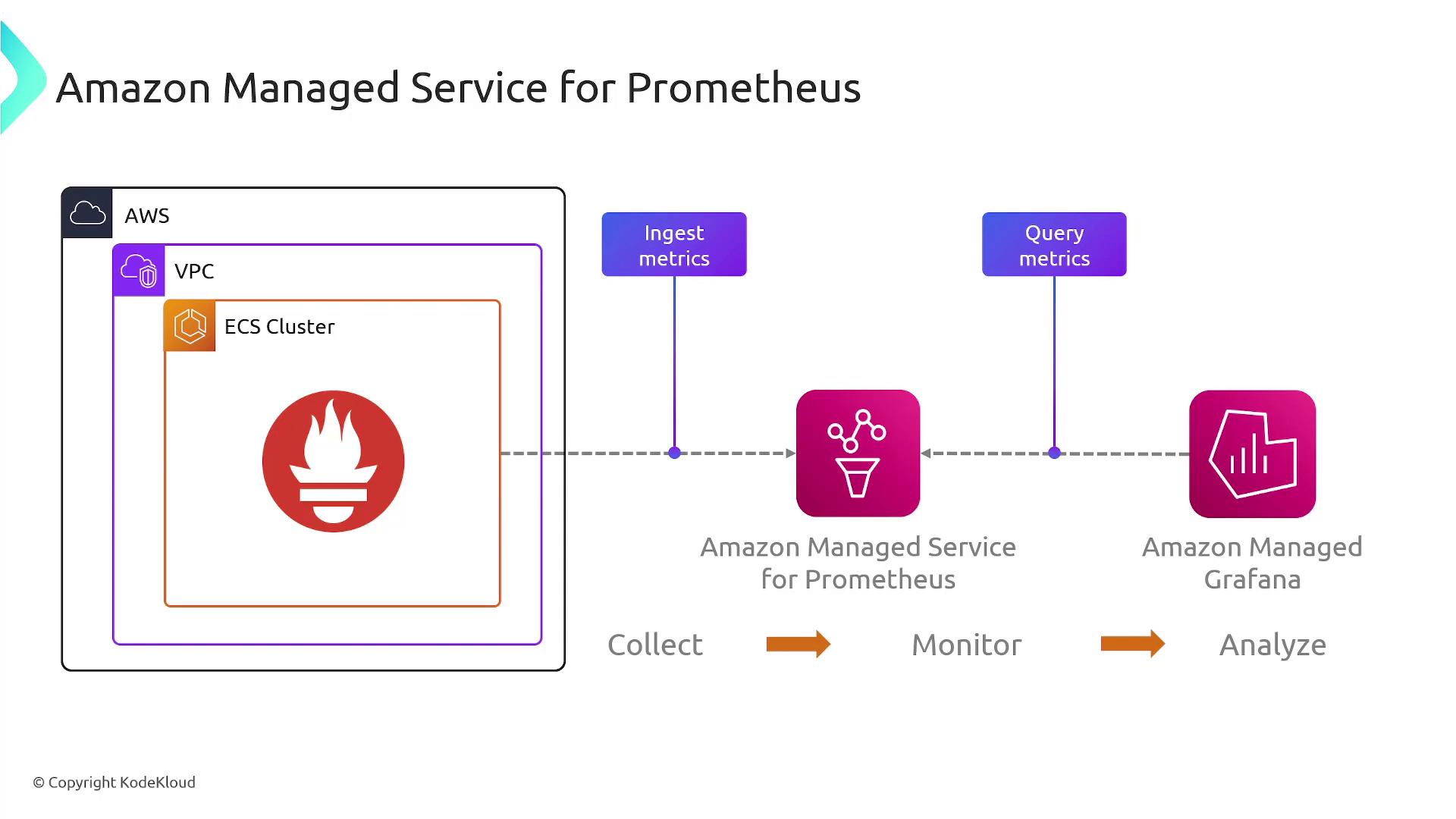
- Automatic scaling to manage increased workloads.
- Seamless integration with AWS services such as Amazon Elastic Compute Cloud (EC2), AWS EKS, AWS Lambda, and Amazon ECS.
- Reduced operational overhead, thanks to AWS managing the infrastructure.
- Robust support for PromQL, empowering you to filter, aggregate, and analyze your metrics efficiently.
- Cost-effectiveness with a pay-as-you-go pricing model.
Integrating Prometheus with CloudWatch
A common and powerful use case is integrating Prometheus with CloudWatch. Imagine a containerized application running not only in an EKS cluster but also in an on-premises environment. Prometheus employs service discovery to identify and monitor all relevant targets, and it allows you to configure alerting rules within its setup. In a standalone Prometheus setup, you might use Alert Manager to send notifications directly via email or Slack. When integrated with AWS, these alerts can be relayed to AWS CloudWatch, which then routes the notifications to your on-call team through channels like SNS. This ensures a prompt and systematic response to any incidents.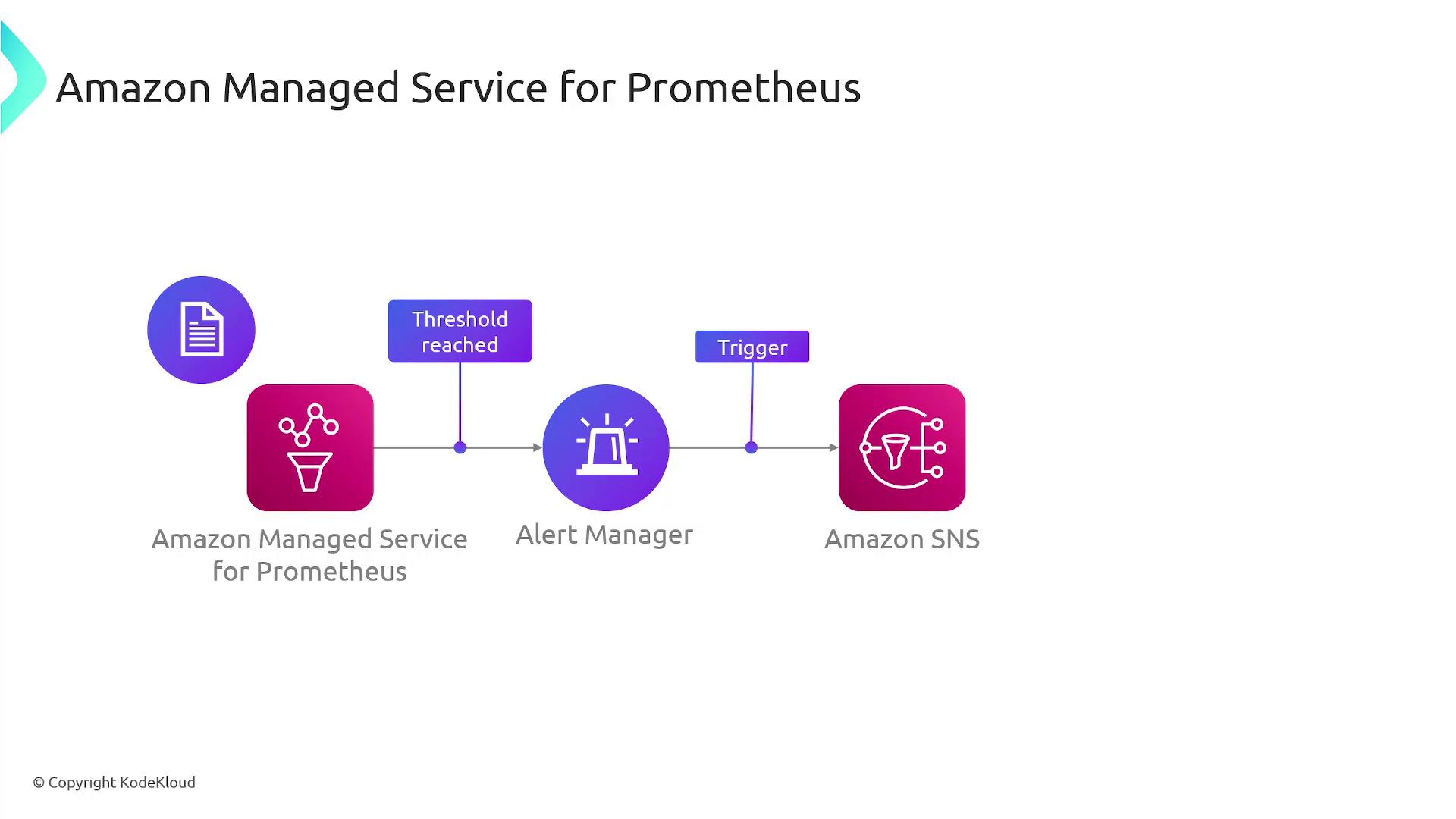
For a deeper dive into how Prometheus compares with other monitoring solutions, explore our detailed articles on modern monitoring practices.