Importance of Moderation
Implementing robust moderation controls is critical for any AI system that interacts with users, especially in customer-facing or regulated environments. Without proper filtering, AI models may generate harmful, biased, or inappropriate content, which can damage user trust and lead to legal issues. Key benefits include:- User safety: Prevents exposure to hate speech, violence, explicit material, or other harmful language—vital in healthcare, education, and support.
- Ethical compliance: Guards against biased or discriminatory outputs, promoting fairness and inclusivity.
- Regulatory adherence: Helps organizations meet industry-specific and legal requirements for handling sensitive data.
- Brand protection: Safeguards your reputation by filtering out content that could harm credibility.

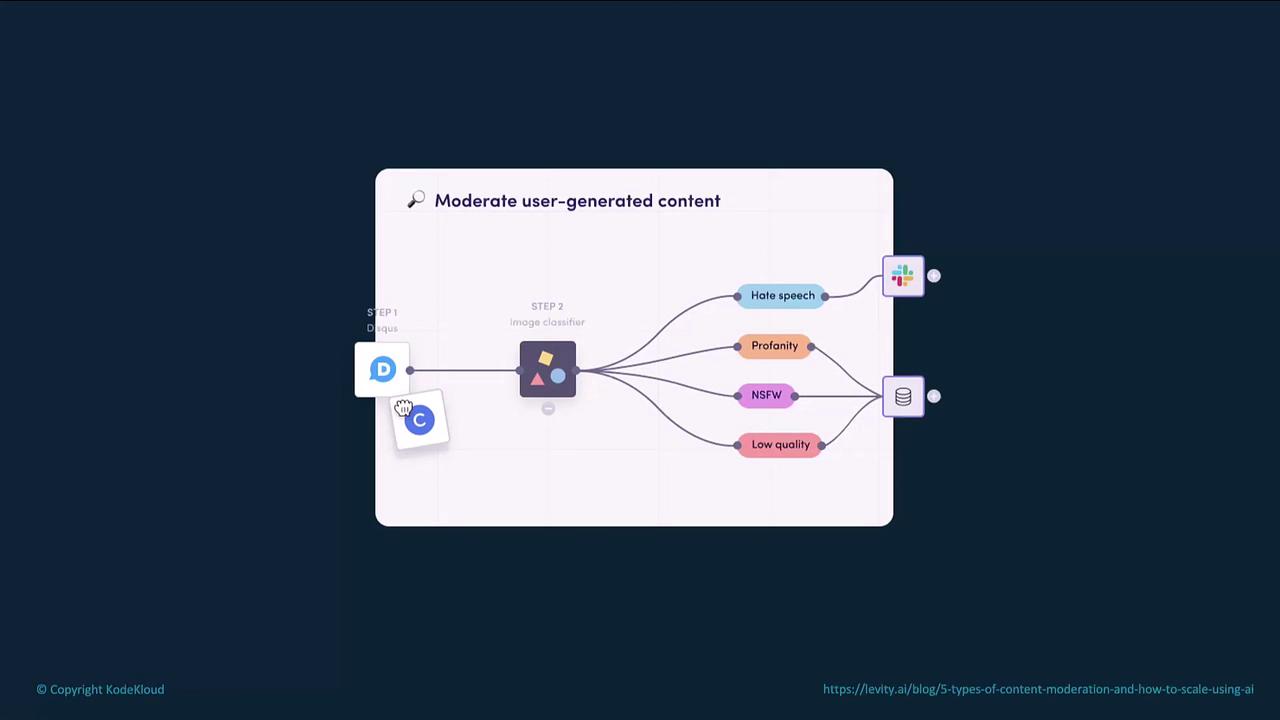
Content Moderation Workflow
A typical moderation pipeline includes the following stages:- Content ingestion
User submissions (text or images) enter your system. - Classification
The moderation model analyzes inputs for categories such as hate speech, profanity, NSFW content, or low-quality submissions. - Action
Flagged items trigger notifications (e.g., Slack, email) or are stored in a review queue. - Review & resolution
Content is either automatically blocked or escalated to human moderators for final decisions.
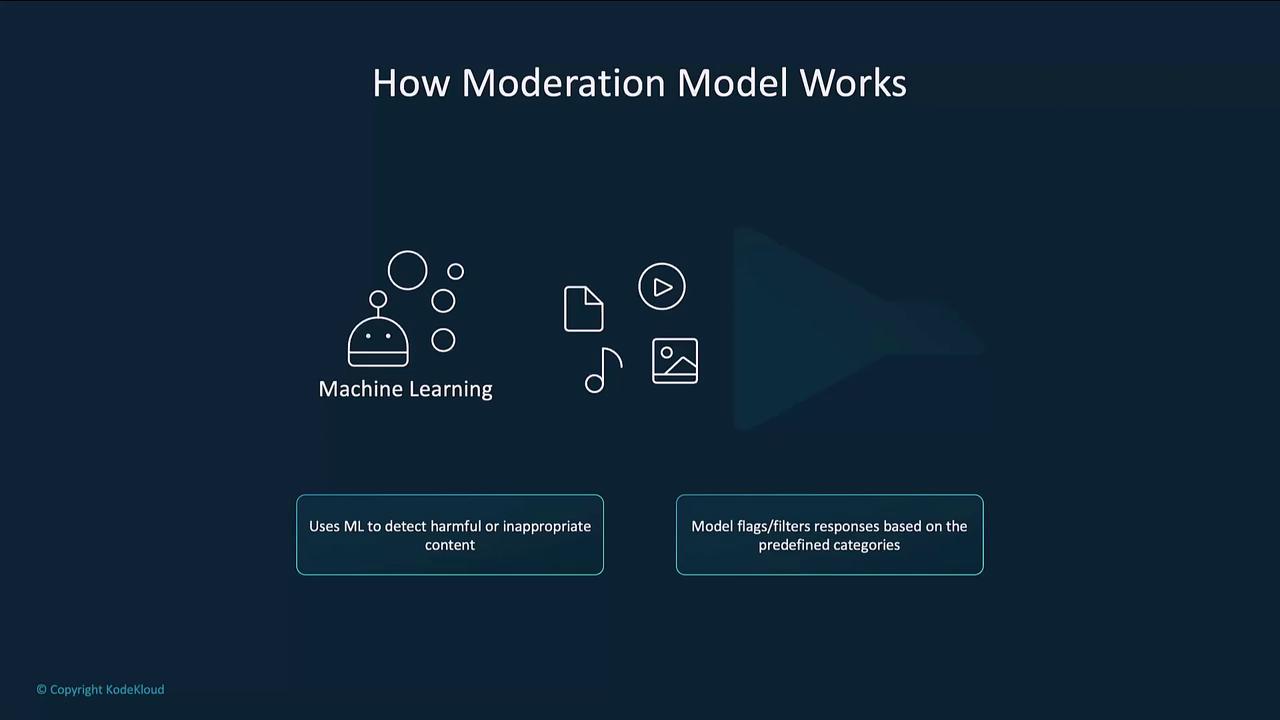
How the Moderation Model Works
OpenAI’s moderation model applies machine learning to detect harmful or inappropriate content in real time. Core features include:- Real-time filtering: Analyzes responses before they reach end users.
- Category detection: Flags violence, hate speech, sexual content, self-harm, harassment, illicit behavior, and more.
- Custom sensitivity: Configure thresholds to match your application’s risk tolerance.
You can adjust the model’s
threshold and combine multiple category scores to fine-tune what content is flagged. This flexibility ensures the moderation pipeline aligns with your brand guidelines and compliance requirements.Industry Use Cases
Moderation is essential across sectors:| Industry | Use Case | Benefit |
|---|---|---|
| Customer Support | Chatbots and live agents | Ensures professional, safe interactions under pressure |
| Social Media | User-generated posts and comments | Prevents offensive or harmful content from going live |
| Education | Online learning platforms | Maintains age-appropriate, safe learning environments |
| Healthcare | Patient portals and telehealth messages | Protects patient safety and confidentiality |

Example: Calling the Moderation Endpoint
Use themoderations.create method to detect whether a piece of text should be flagged:
Review your threshold settings carefully. Overly strict filters may block legitimate content, while lenient settings could let harmful material slip through.
Best Practices

- Combine automated moderation with human review for nuanced cases.
- Tailor sensitivity levels based on content type, audience, and context.
- Continuously monitor and update policies to reflect evolving language and social norms.