
What Is Grounding?
Grounding ties an LLM’s responses to verified information or external data sources, reducing the risk of generating plausible-sounding but incorrect statements (hallucinations). A grounded model answering “What is the capital of Australia?” will reliably return “Canberra,” whereas an ungrounded model might invent an incorrect city.The grounding process involves receiving a user prompt, retrieving or verifying information from external data sources to prevent hallucinations, and producing a fact-checked response.
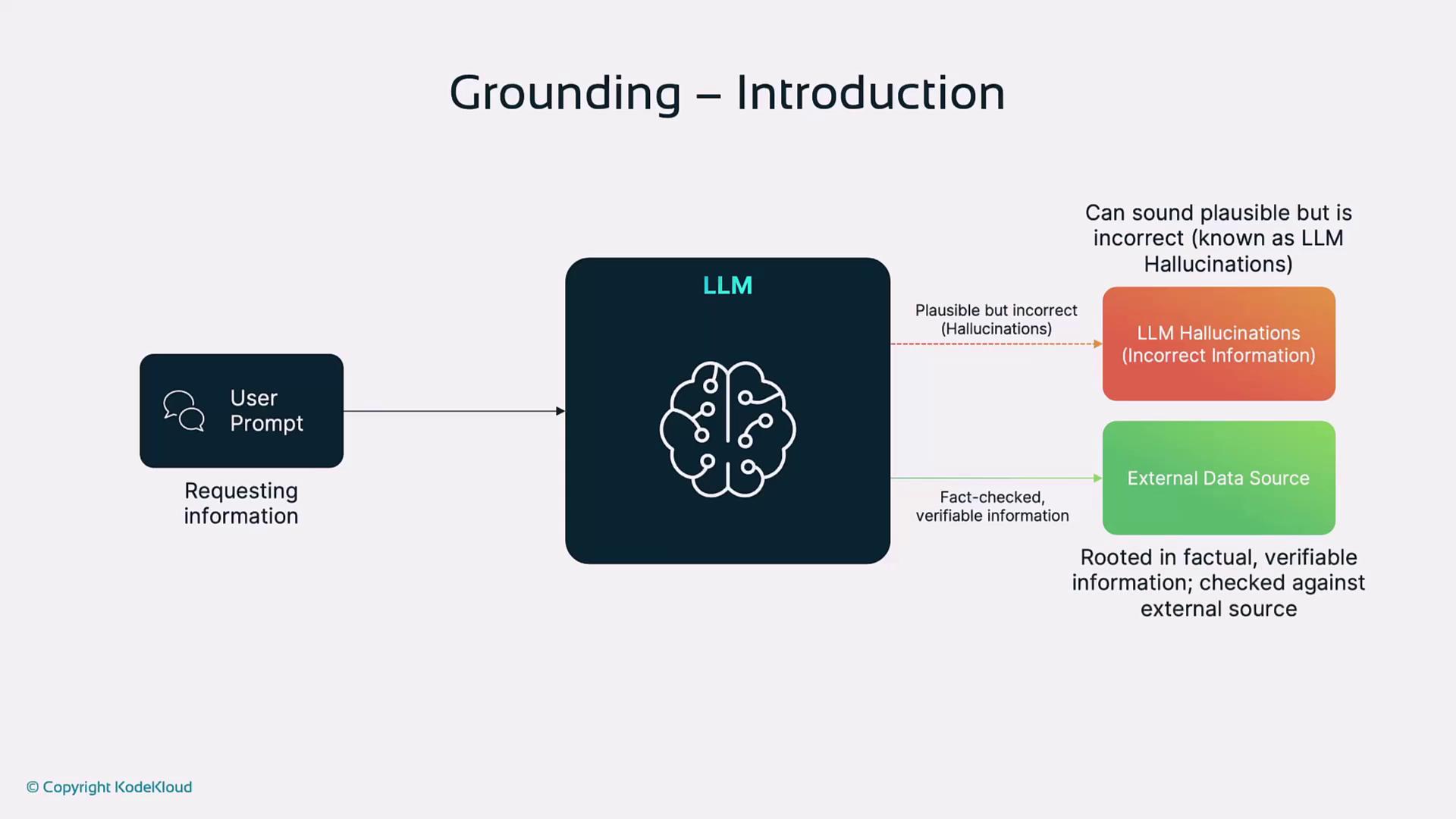
Why Grounding Matters
- Accuracy: Dramatically reduces hallucinations by referencing reliable sources.
- Trustworthiness: Builds user confidence—critical for research, customer support, and decision-making.
- Consistency: Ensures repeatable, verifiable answers across multiple queries.

Grounding Techniques
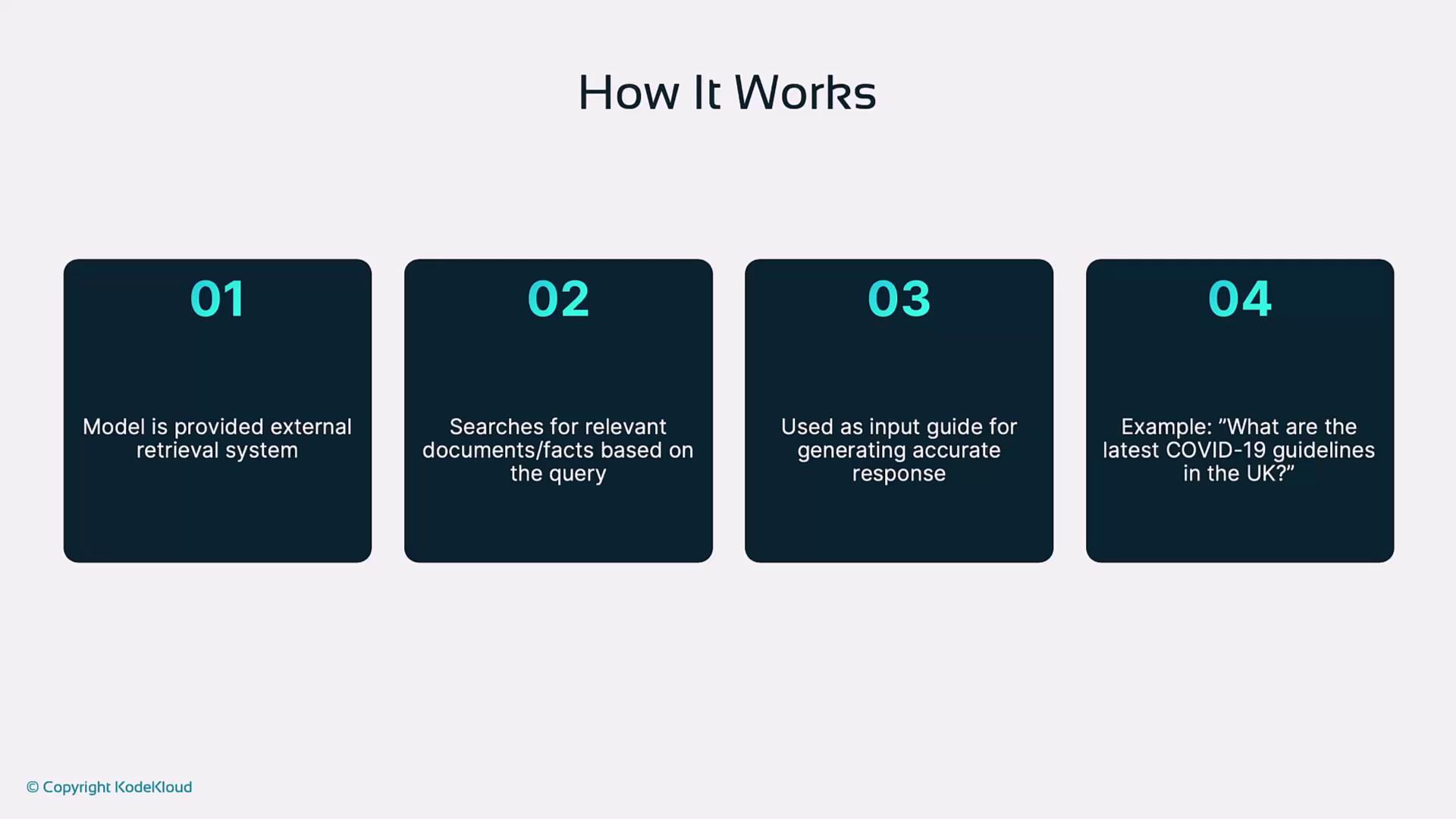
Below are four common approaches to ground an LLM:1. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation enriches language output with documents fetched from an external knowledge store. Steps:- The client submits a question.
- Perform a semantic search on a vector database to find relevant documents.
- Pass retrieved context into the LLM.
- The LLM generates a response, which may be post-processed before return.

In a simplified four-step workflow, the system performs external retrieval, searches for relevant documents, uses that context for accurate response generation, and provides the final answer based on the original query.
2. External Knowledge Injection
In this approach, structured knowledge bases (e.g., Wikidata, DBpedia) are embedded into the model’s architecture. Process:- Incorporate a database of factual entities and relationships.
- Enable the LLM to query this knowledge during generation.
- Reference well-defined facts to ensure accuracy.


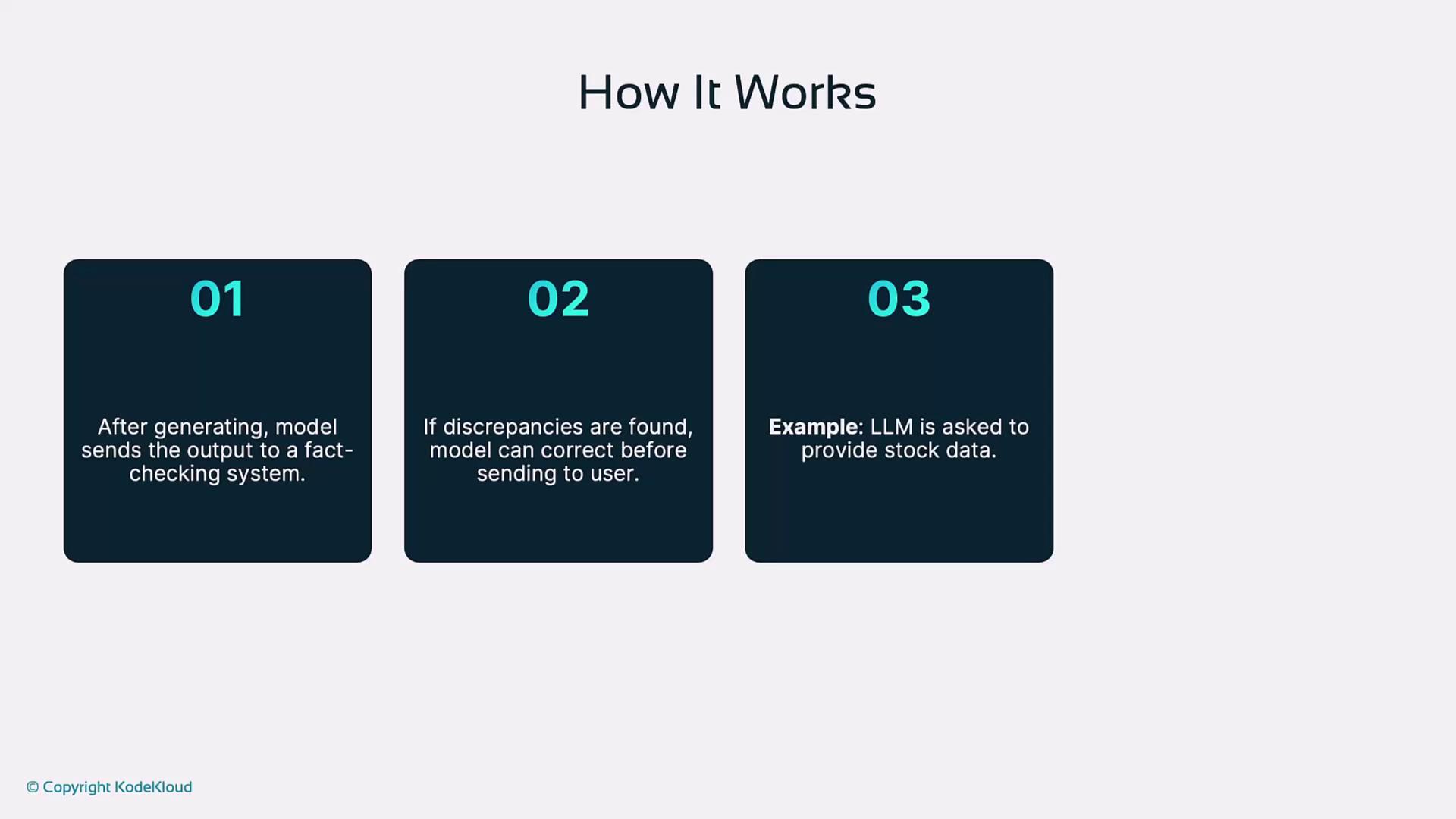
3. Post-Generation Fact-Checking
After the LLM generates its response, you validate and correct its claims against trusted external sources or APIs. Workflow:- LLM outputs a draft response.
- A fact-checking system verifies key statements.
- Discrepancies are corrected, and the final answer is returned.

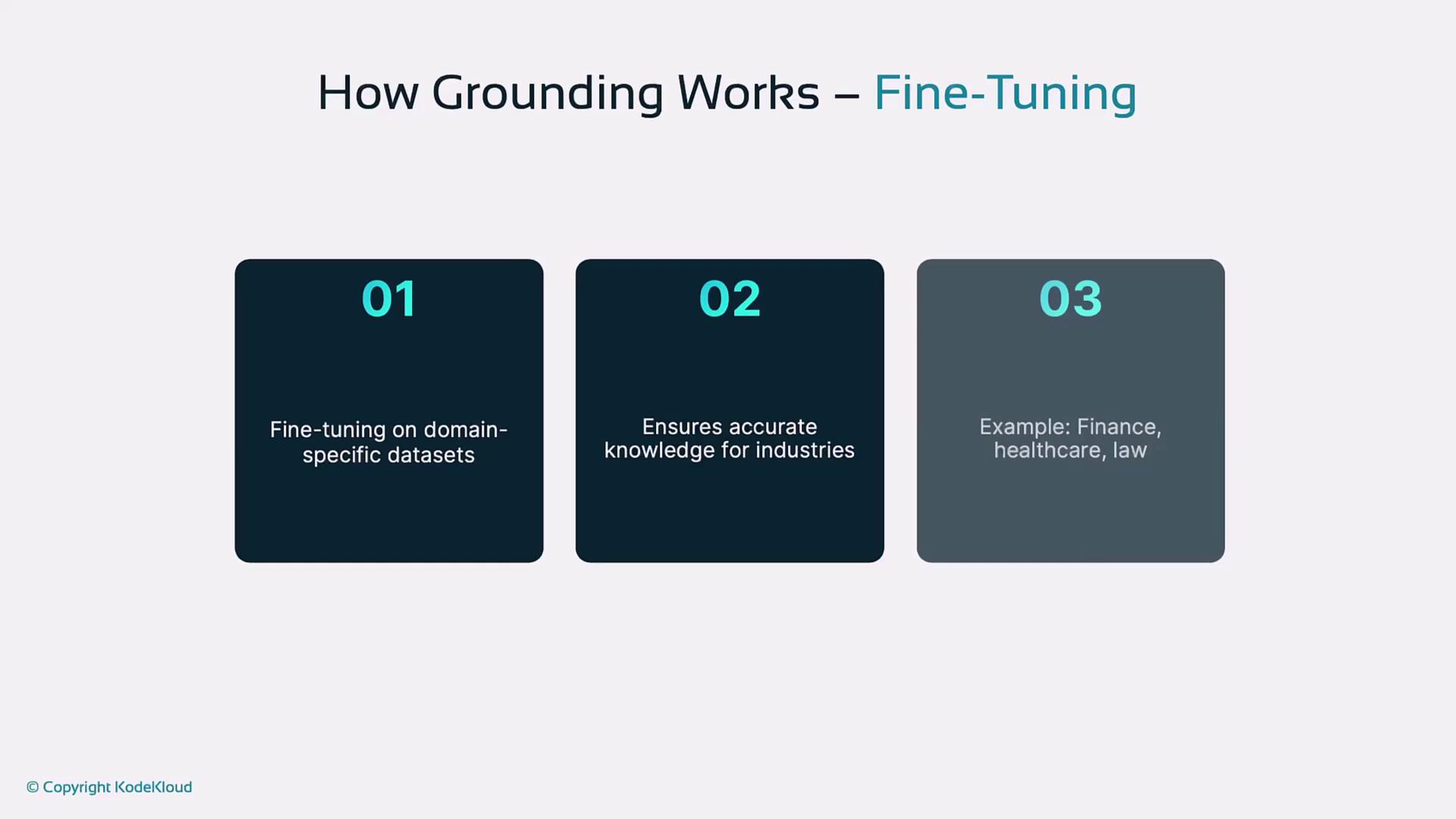
4. Domain-Specific Fine-Tuning
Fine-tune an LLM on a curated dataset specific to your industry to enhance domain knowledge. Procedure:- Start with a pre-trained LLM.
- Fine-tune on specialized data (e.g., medical journals).
- Deploy the tuned model for more precise, context-aware responses.

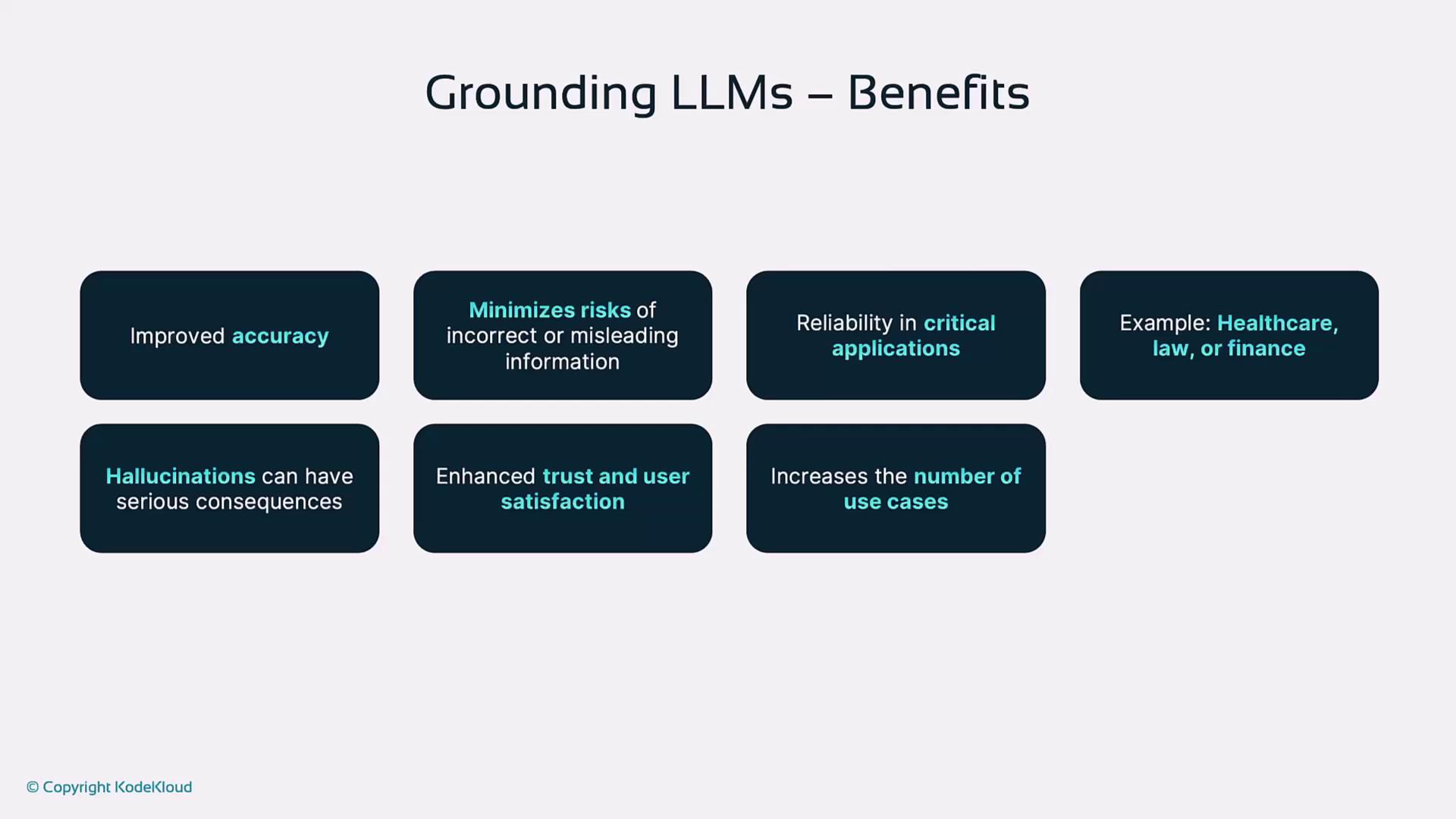
Benefits of Grounding LLMs
Grounding your LLM unlocks several advantages:| Benefit | Description |
|---|---|
| Improved Accuracy | External references greatly reduce factual errors and hallucinations. |
| Enhanced Trust | Users rely on verifiable information for critical decisions. |
| Consistent Outputs | Repeatable answers across multiple sessions and users. |
| Broader Adoption | Greater user satisfaction accelerates deployment in healthcare, finance, and more. |
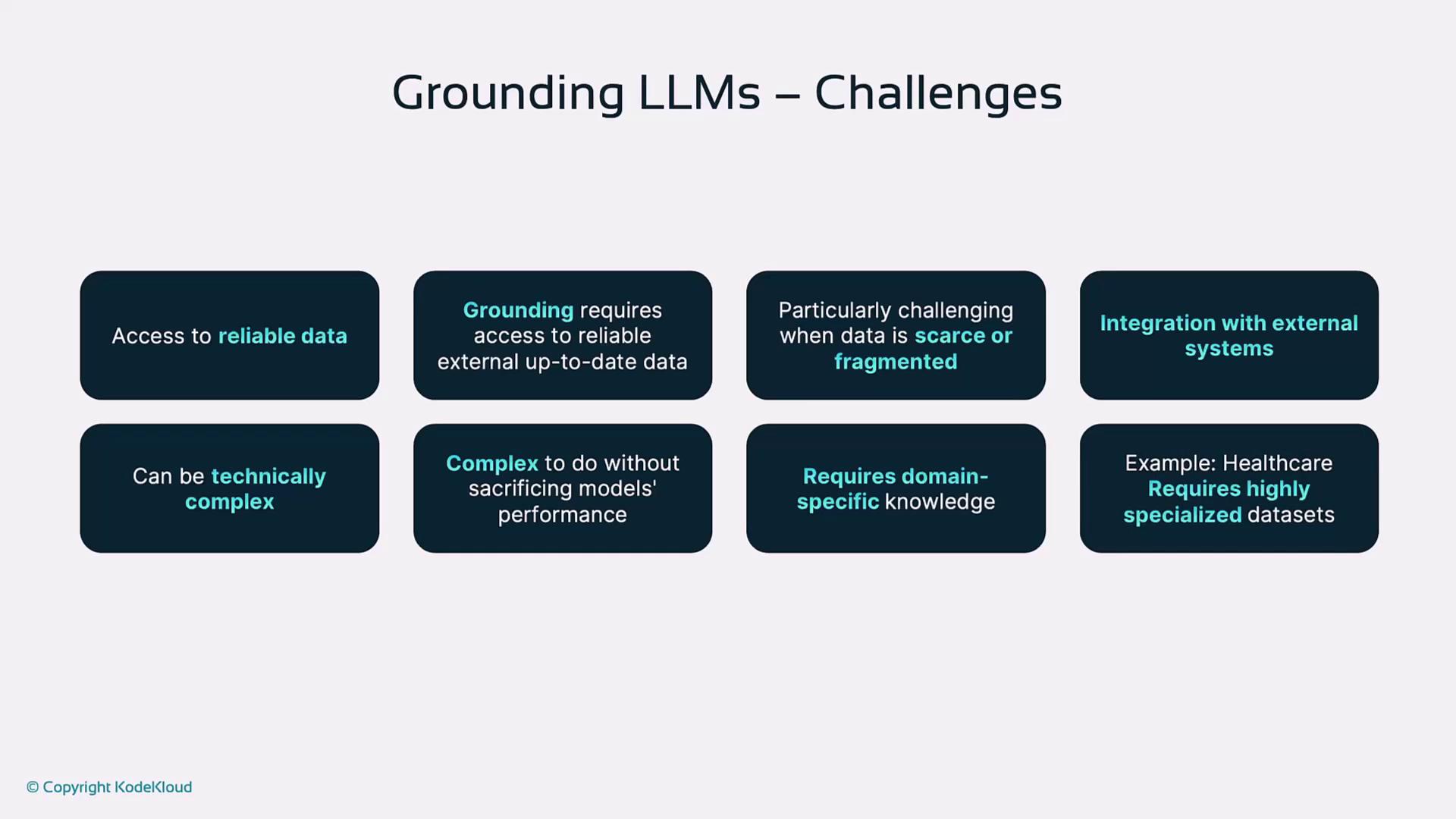
Challenges in Grounding
- Access to Reliable Data
- Technical Complexity in integrating retrieval systems or knowledge graphs
- Domain-Specific Data Requirements and the cost of high-quality datasets
Ensuring access to up-to-date, trustworthy data sources is critical—stale or low-quality inputs can undermine the entire grounding pipeline.
Real-World Applications
| Industry | Use Case | Data Source |
|---|---|---|
| Customer Service | Precise product and policy answers via internal databases | Company knowledge bases |
| Healthcare | Evidence-based guidelines from medical literature | Peer-reviewed journals, EHRs |
| Financial Services | Live market data and financial reports for investment advice | External APIs (e.g., Bloomberg) |