
- The critical role of encoders in NLP
- Core capabilities of transformer encoders
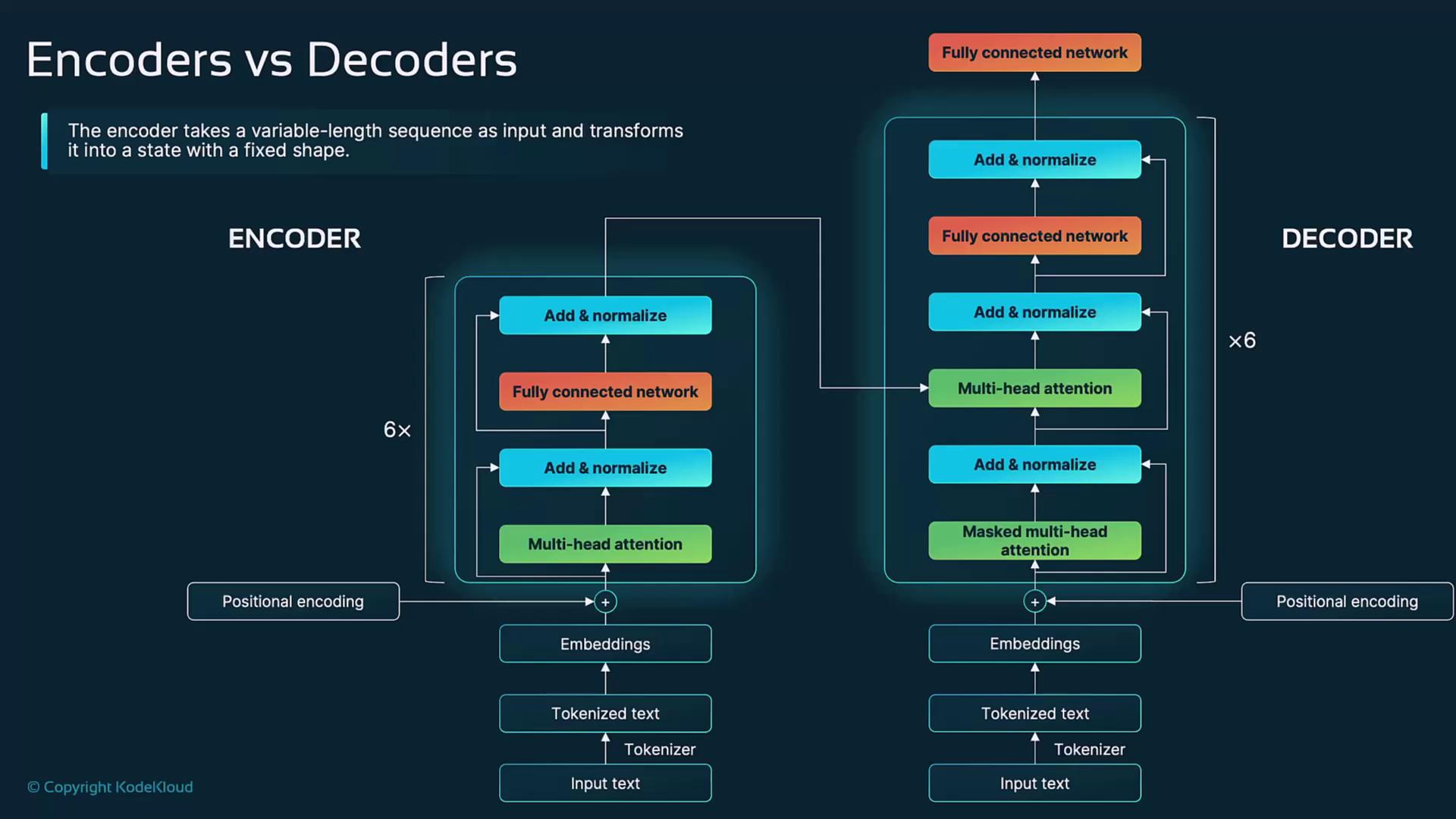
- Encoder vs. decoder architecture comparison
- How GPT-style models handle prompts
- BERT vs. GPT prompt encoding
- Common NLP tasks powered by encoders
- Advantages and limitations of encoder-based LLMs
The Importance of Encoders
Transformer encoders convert raw text into rich, contextual embeddings:- Contextual Understanding
Self-attention lets the model examine all tokens together, capturing local and long-distance dependencies. - Dynamic Embeddings
Each token’s vector reflects its meaning in context, improving downstream predictions. - Parallel Processing
Entire sequences are processed at once, accelerating training and inference compared to RNNs.

Encoder vs. Decoder Architectures
While both use self-attention, feed-forward layers, and normalization, they differ in purpose:| Feature | Encoder | Decoder |
|---|---|---|
| Main Function | Embed input for understanding tasks | Generate new text token by token |
| Attention Mask | Full attention across all tokens | Causal (masked) attention to enforce order |
| Cross-Attention Layer | N/A | Attends over encoder outputs |
| Context Direction | Bidirectional | Unidirectional (left-to-right) |
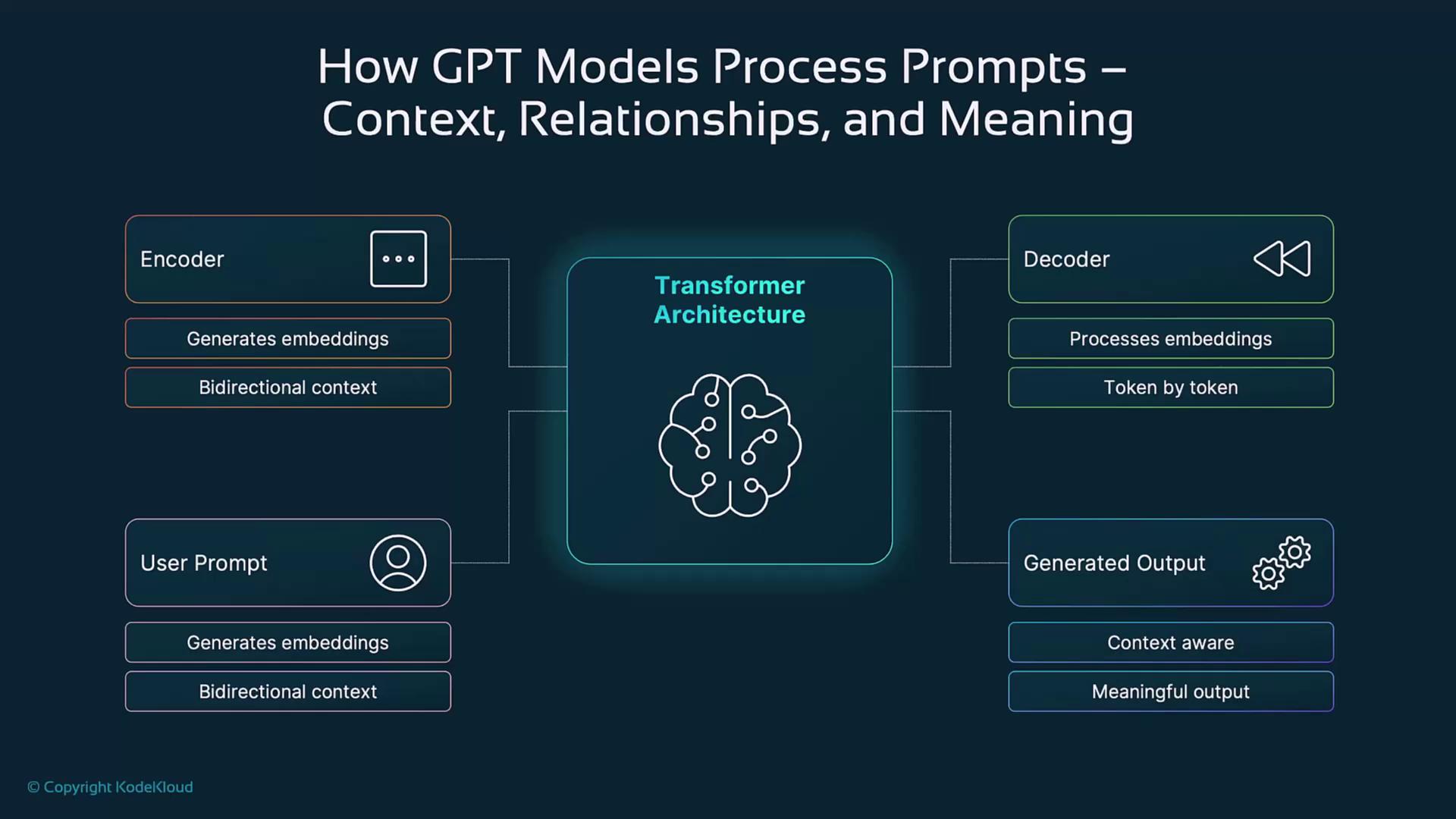
How GPT Models Process Prompts
Generative Pre-trained Transformers (GPT) use a decoder-only architecture to produce context-aware text:- Tokenization & Embedding
Split the prompt into tokens and map each to a vector. - Masked Self-Attention
Ensure each token attends only to previous ones for causal generation. - Autoregressive Decoding
Predict one token at a time, appending each new token to the context. - Output
Generate a coherent, contextually relevant sequence.
Despite lacking an encoder stack, GPT’s masked attention effectively captures context for high-quality text generation.
Encoding Prompts: BERT vs. GPT
| Aspect | BERT (Encoder-Only) | GPT (Decoder-Only) |
|---|---|---|
| Architecture | Transformer encoder | Transformer decoder |
| Context Direction | Bidirectional | Left-to-right |
| Ideal Use Case | Classification, QA, token tagging | Text generation, completion, dialogue |
| Processing Method | All tokens simultaneously | Sequential, autoregressive predictions |
- BERT excels at understanding tasks: “What is the capital of France?” → Embedding leads to “Paris.”
- GPT is optimized for generation: “Write a story about a dragon” → Narrative unfolds token by token.
Handling Long-Range Dependencies
Encoders naturally capture relationships between distant words.For instance, in “The book that I bought last week is on the table,” the encoder links “book” to “on the table,” regardless of the intervening words.
Encoder Applications in NLP Tasks
Text Classification
Convert input sentences into embeddings for classifiers (e.g., sentiment analysis).Question Answering
Encode both question and passage to pinpoint correct answers.Summarization
Process long documents into embeddings that extract key information for concise summaries.
Translation
In models like T5, the encoder transforms source text embeddings that the decoder uses to generate the target language (e.g., “The cat is on the roof” → “Le chat est sur le toit”).Benefits of Encoders in LLMs

- Rich contextual embeddings
- Efficient handling of long sequences
- Parallelized computation for speed and scalability
- Flexible features for diverse downstream tasks
Challenges of Encoders in LLMs
Encoder-based LLMs require substantial computational resources and memory during training and inference.

- Self-attention scales quadratically with sequence length
- Pretraining demands large datasets and high compute
- Performance degrades without extensive pretraining
Links and References
- Transformer Architecture Overview
- BERT Paper (arXiv)
- GPT-3 Paper (arXiv)
- T5: Text-to-Text Transfer Transformer