- Why pre-training is essential
- Pre-training objectives and methods
- What fine-tuning entails
- A step-by-step workflow
- Real-world use cases
- Key success factors and challenges
Importance of Pre-Training
Pre-training lays the foundation for an LLM’s broad language understanding by leveraging large, unlabeled text corpora. This unsupervised phase enables models to learn:- General language patterns: grammar, syntax, semantics
- Transferable knowledge: facts, relationships, real-world context
- Efficiency: reuse of pre-trained weights for multiple downstream tasks

Pre-trained LLMs act as versatile foundations. By adapting them to new tasks, you avoid training models from scratch and leverage existing knowledge.
Pre-Training Objectives
During pre-training, an LLM processes diverse text sources (books, articles, web pages) using unsupervised learning. The two most common objectives are:
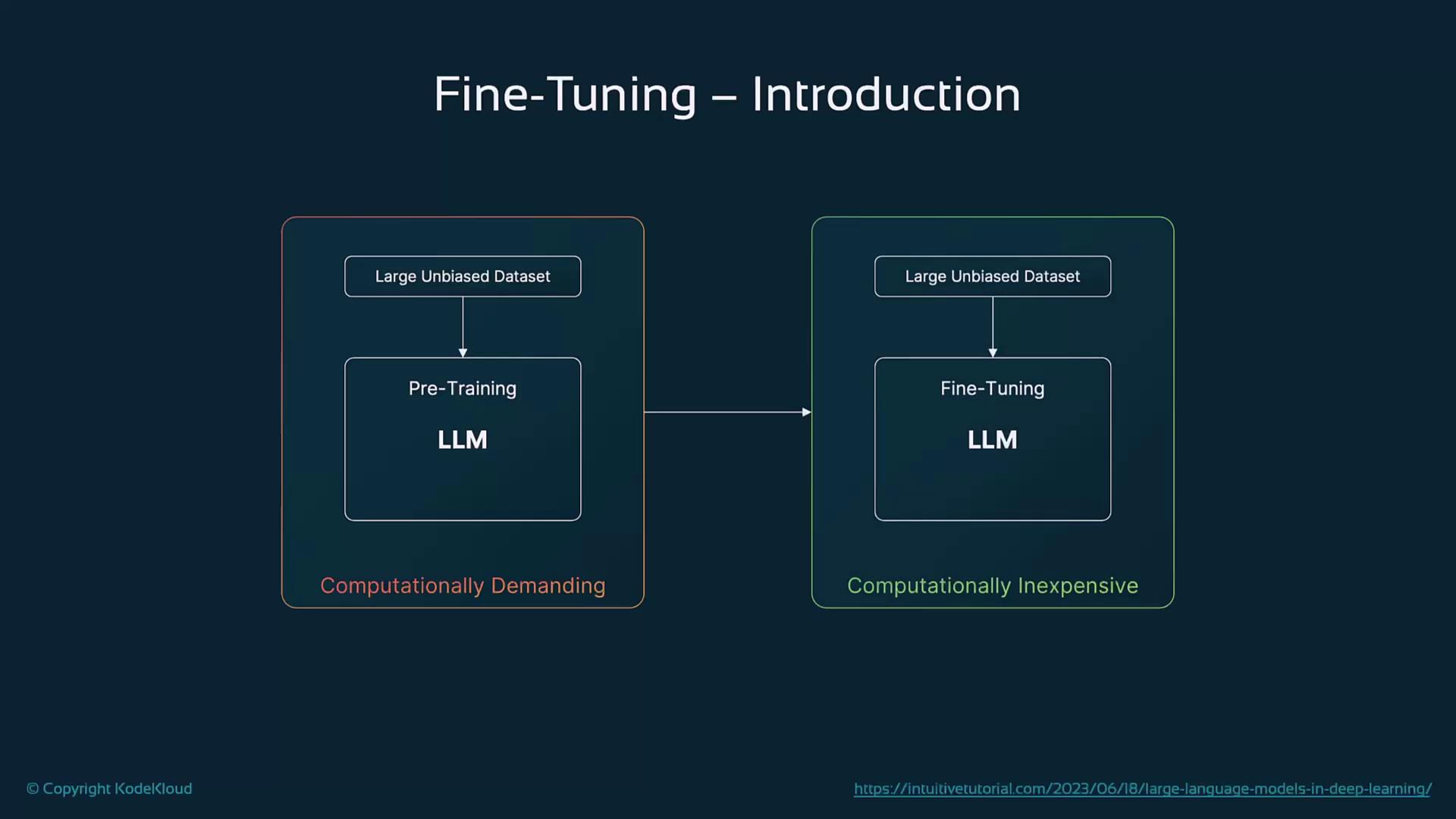
Introduction to Fine-Tuning
Fine-tuning specializes a pre-trained LLM for a downstream task by training on a smaller, labeled dataset in a supervised manner. This phase refines the model’s parameters to capture the nuances of the target task, such as translation, sentiment classification, or question answering.
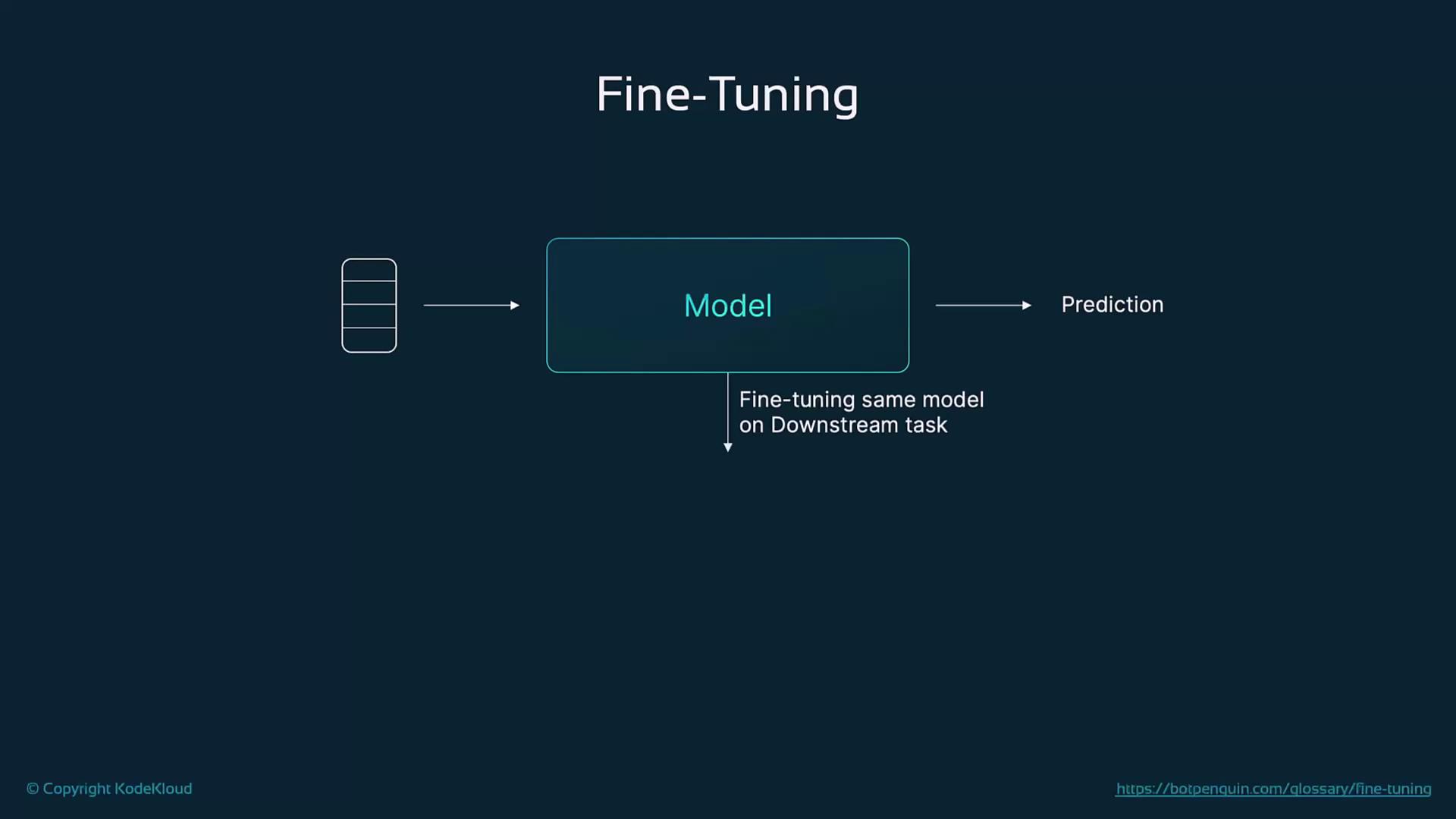
Fine-tuning adjusts only the existing weights rather than learning new ones from scratch, making it computationally more efficient than full-scale pre-training.
Fine-Tuning Process
- Task-Specific Data: Assemble a labeled dataset (e.g., reviews labeled positive/negative, parallel sentences for translation).
- Supervised Learning: Train on input–label pairs to minimize task-specific loss.
- Weight Updates: Gradually adapt the pre-trained parameters to improve performance on the new task.

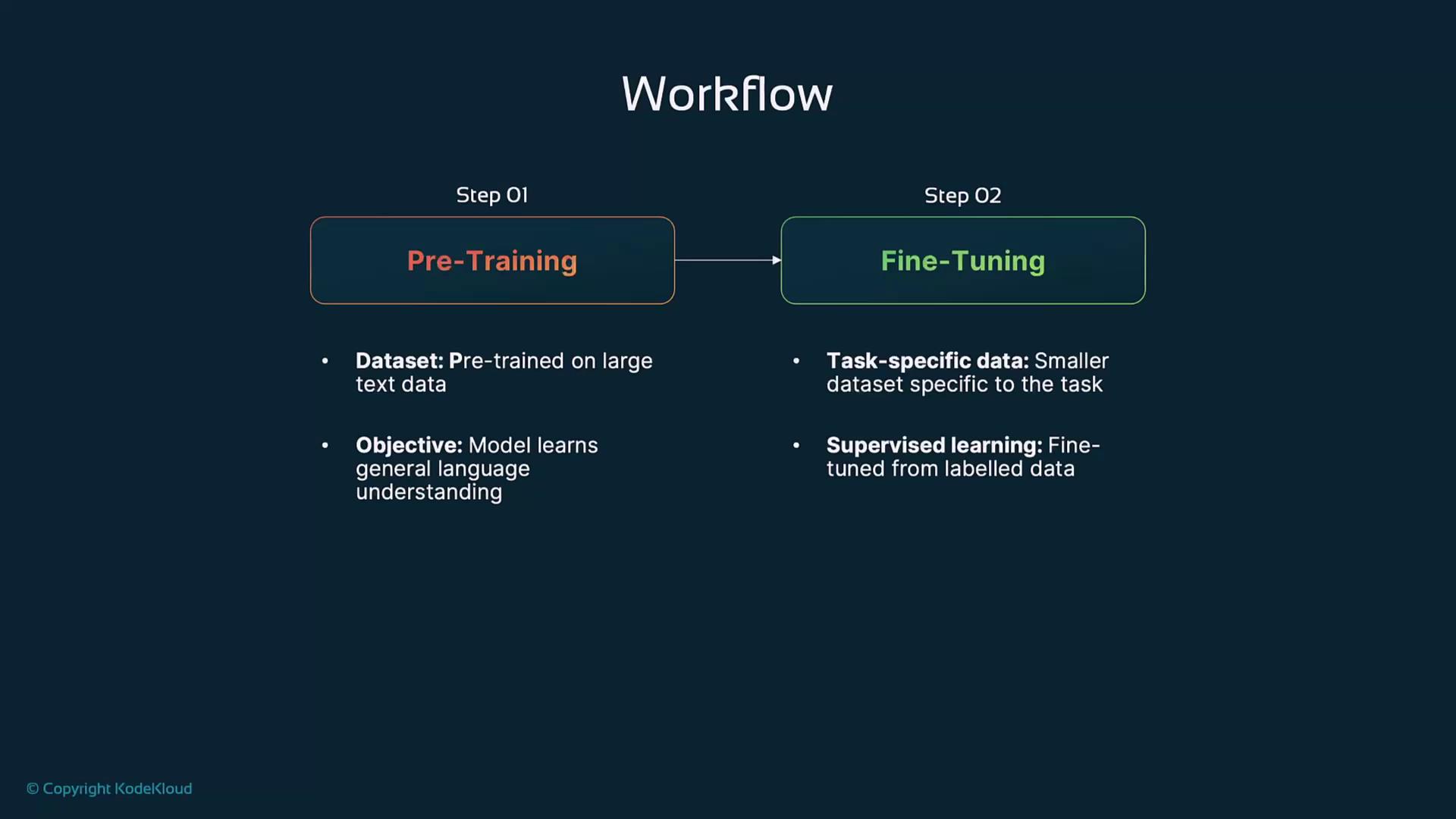
Pre-Training and Fine-Tuning Workflow
A typical LLM development pipeline consists of three stages:- Pre-Training
- Data: massive text corpora (books, research papers, web content)
- Objective: unsupervised (next-word or masked-token prediction)
- Fine-Tuning
- Data: smaller, labeled datasets for specific tasks
- Objective: supervised learning to adjust model weights
- Evaluation
- Metric: performance on held-out test sets (accuracy, F1-score, BLEU, etc.)
Real-World Examples
- GPT family (e.g., GPT-4): Pre-trained on web-scale corpora, then fine-tuned for chatbots, code generation, and creative writing.
- BERT: Pre-trained with masked language modeling and next-sentence prediction; fine-tuned on SQuAD for question answering and on sentiment corpora for classification.
Success Factors and Challenges
LLMs owe their success to:- Scalability: training on vast amounts of unlabeled data
- Flexibility: adapting to multiple tasks without full retraining
- Efficiency: lower compute and data needs for downstream tasks

- Computational Cost: Pre-training and fine-tuning require significant GPU/TPU resources.
- Data Bias: Models can inherit and amplify biases in training data; mitigation strategies are essential.
Biases in training datasets can lead to unfair or harmful model outputs. Always evaluate and mitigate bias when fine-tuning.
