- Introduction to tokenization
- Key tokenization strategies
- Role of tokenization in AI model performance
- Tokenization in modern architectures (GPT, DALL·E)
- Challenges and best practices
What Is Tokenization?
Tokenization breaks raw text into tokens—words, subwords, characters, or punctuation—enabling AI models to convert language into numerical embeddings. Since LLMs cannot directly interpret raw text, tokenization standardizes inputs, making them suitable for tasks like generation, classification, or translation.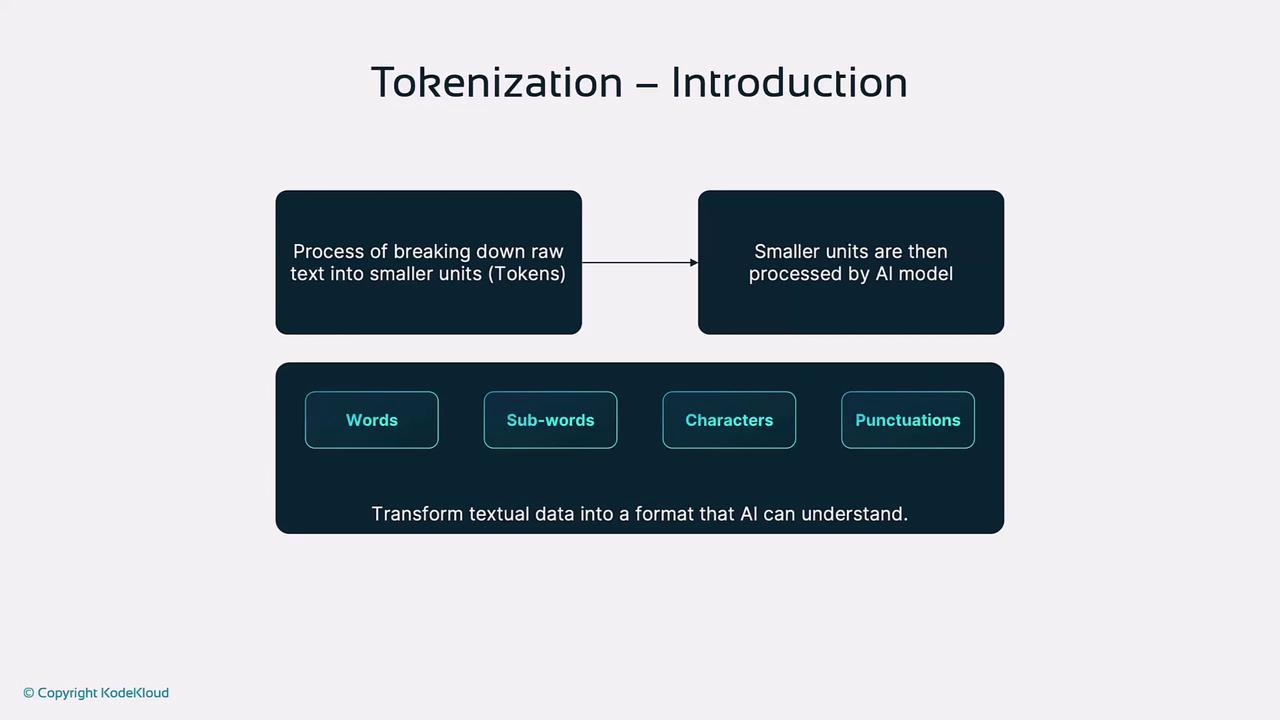
Types of Tokenization
Each tokenization strategy balances vocabulary size, sequence length, and model performance. Here is a comparison of the main approaches:| Tokenization Type | Description | Advantages | Disadvantages |
|---|---|---|---|
| Word-Level | Splits text into full words. | Simple; preserves full word semantics. | Large vocabulary; cannot handle OOV words |
| Subword-Level (BPE) | Merges frequent character/subword pairs (Byte Pair Encoding). | Reduces OOV issues; smaller vocabulary. | More complex; may split meaningful units |
| Character-Level | Treats every character as a token. | No OOV issues; fine-grained control. | Very long sequences; low semantic density |
1. Word-Level Tokenization
Word-level tokenization treats each word as an individual token. For example, “the cat wore a hat” becomes:the, cat, wore, a, hat.

- Simple implementation
- Preserves whole-word meaning
- Large vocabulary required
- Cannot handle new or rare words (OOV)

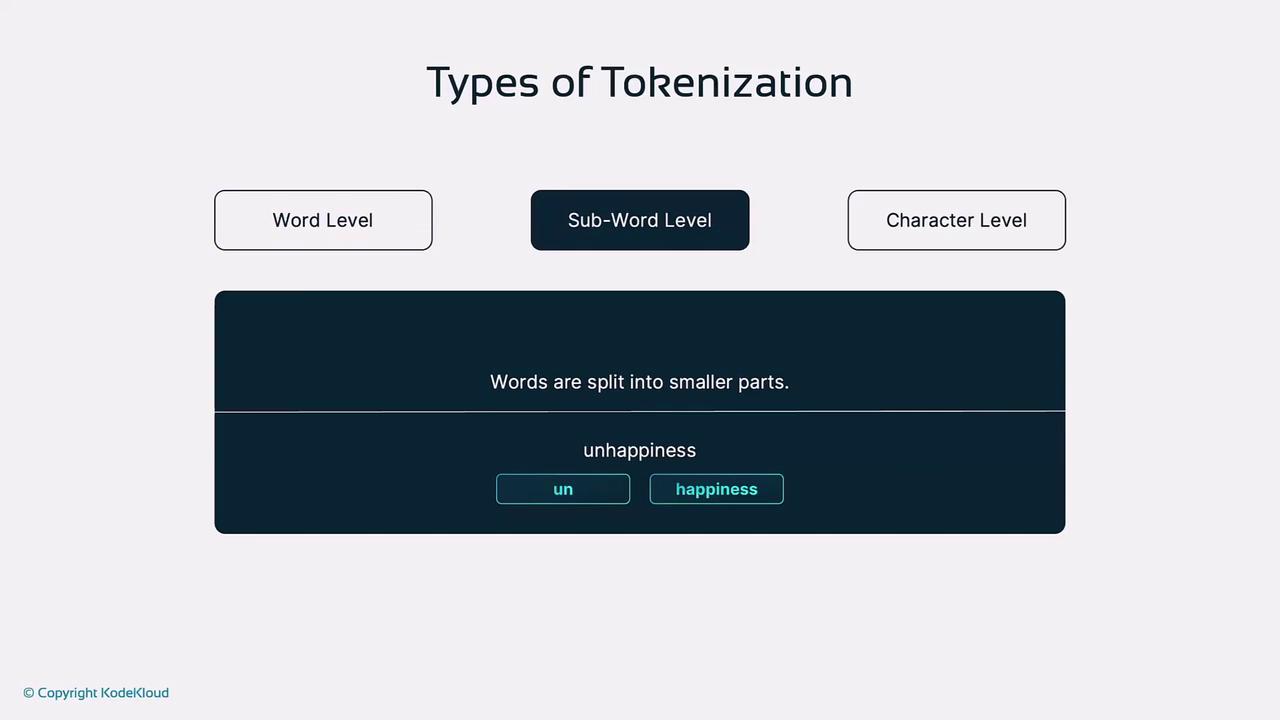
2. Subword-Level Tokenization
Subword techniques like Byte Pair Encoding (BPE) iteratively merge the most frequent character or subword pairs, creating a flexible vocabulary.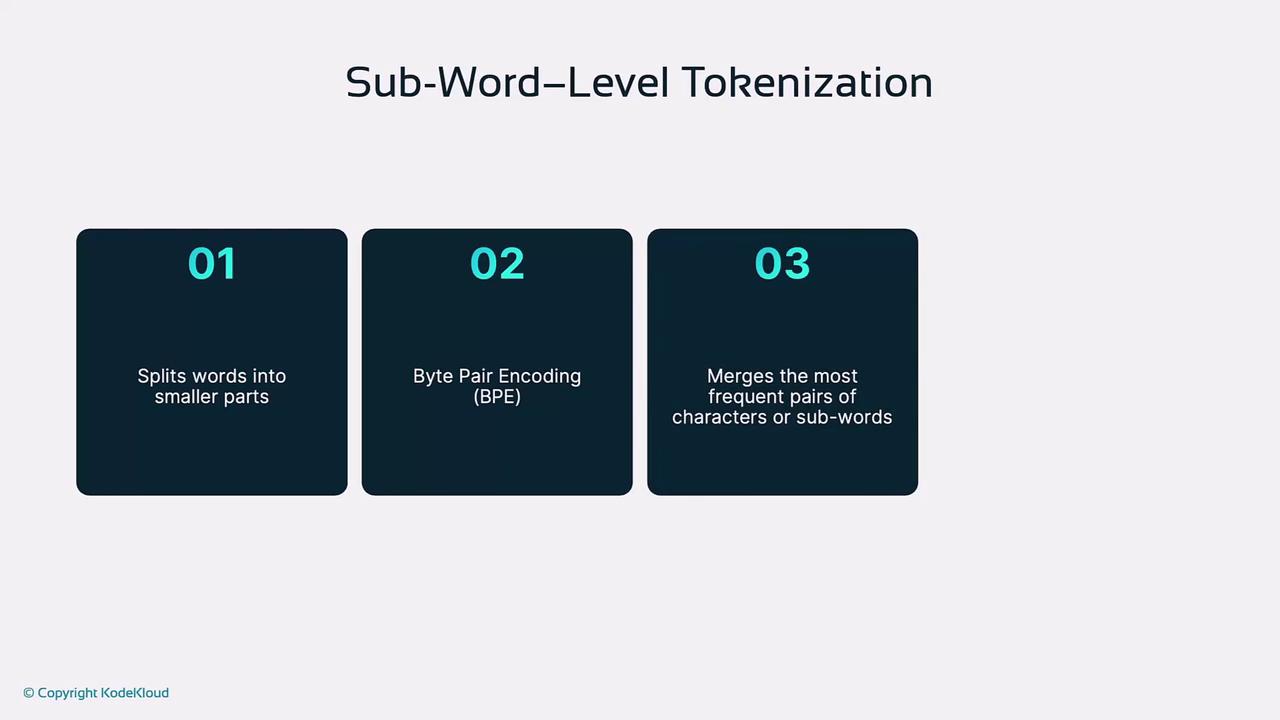
un + happiness, and “don’t waste food” could split into: don + 't, waste, food.
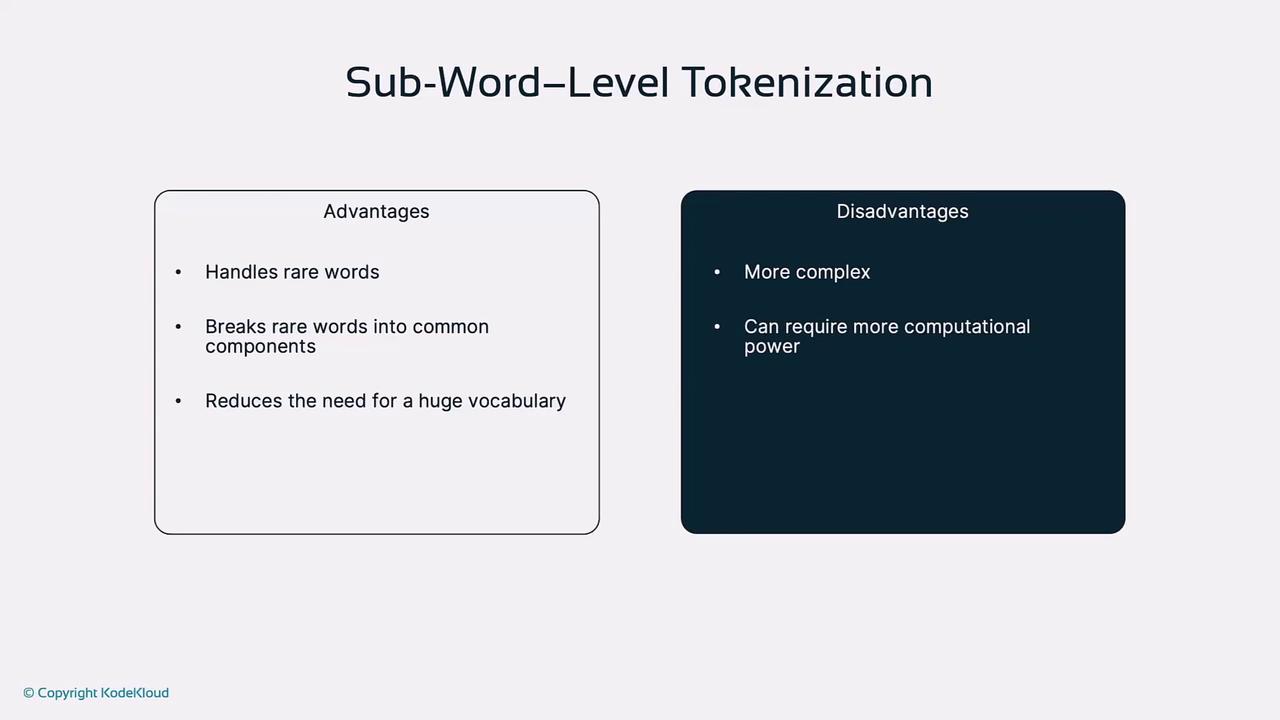
- Handles rare and compound words
- Balances vocabulary size and coverage
- More complex to implement
- Split tokens can reduce readability
Subword tokenization (BPE, WordPiece) is the most common approach in state-of-the-art language models to mitigate OOV issues and control vocabulary size.
3. Character-Level Tokenization
This method breaks text into individual characters, including spaces and punctuation. E.g., “It is raining.” becomesI, t, , i, s, , r, a, i, n, i, n, g, ..


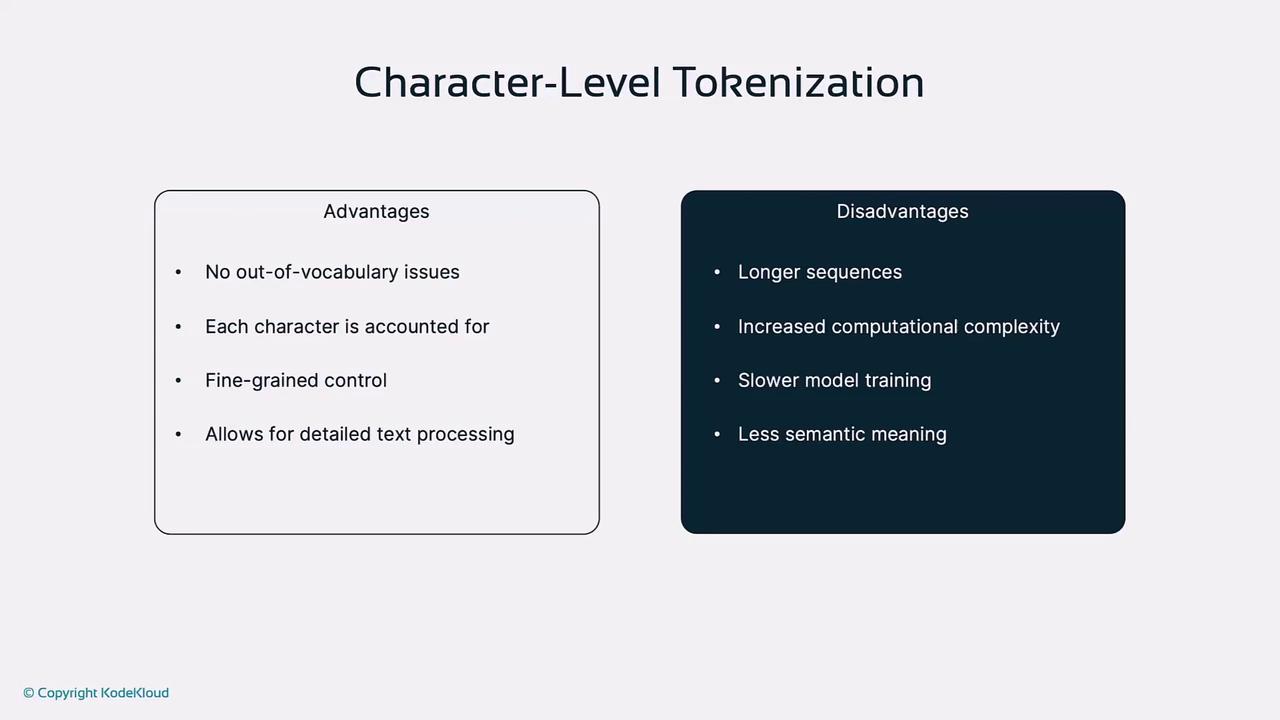
- Resolves all OOV issues
- Fine-grained text analysis
- Very long sequences increase compute
- Low semantic density per token
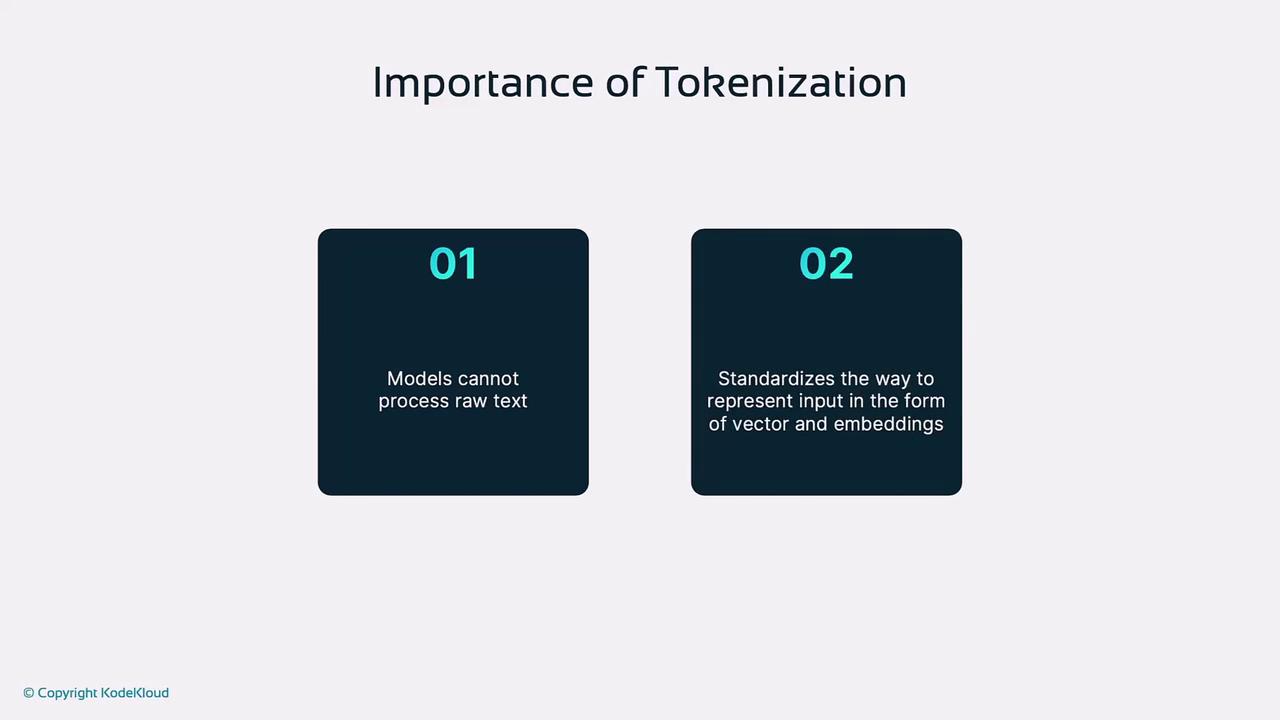
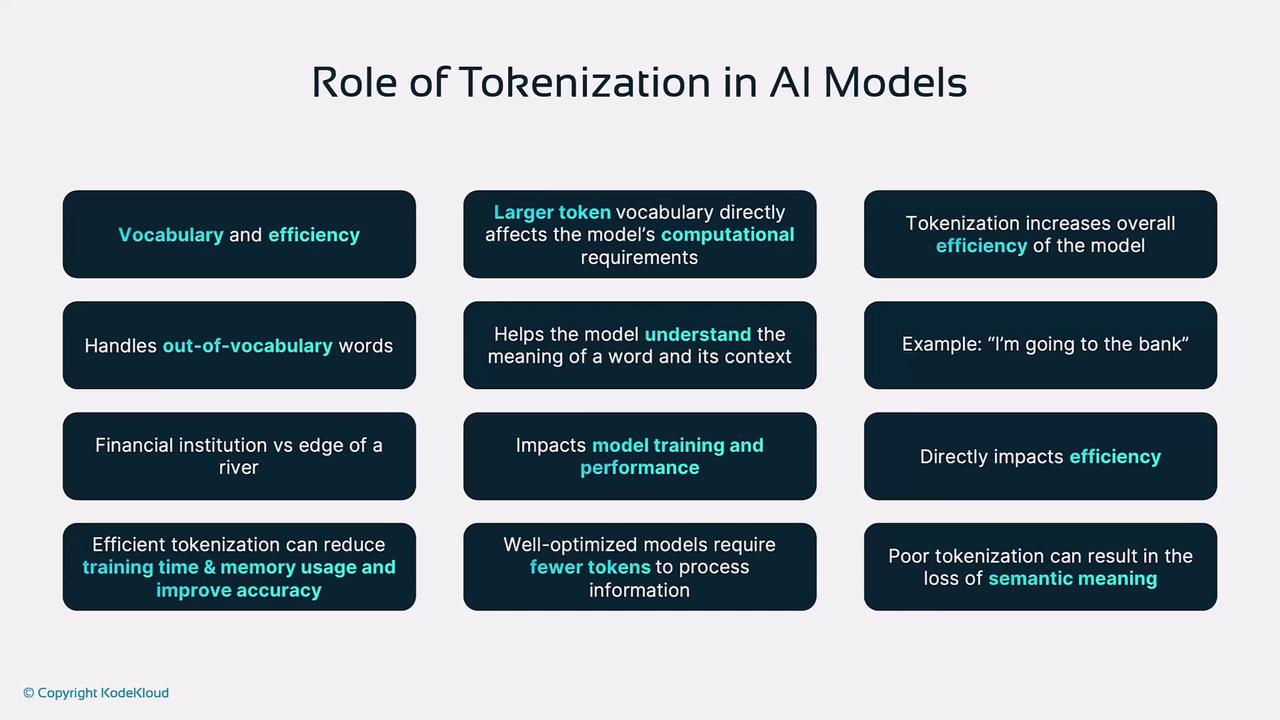
Role of Tokenization in AI Models
Effective tokenization influences:- Vocabulary & Memory
A larger vocabulary demands more memory and compute. - Handling OOV Words
Subword methods mitigate unseen-word errors. - Contextual Clarity
Proper token boundaries improve self-attention and disambiguation (e.g., “bank”). - Training Efficiency
Optimized tokenization reduces sequence length and speeds up convergence.
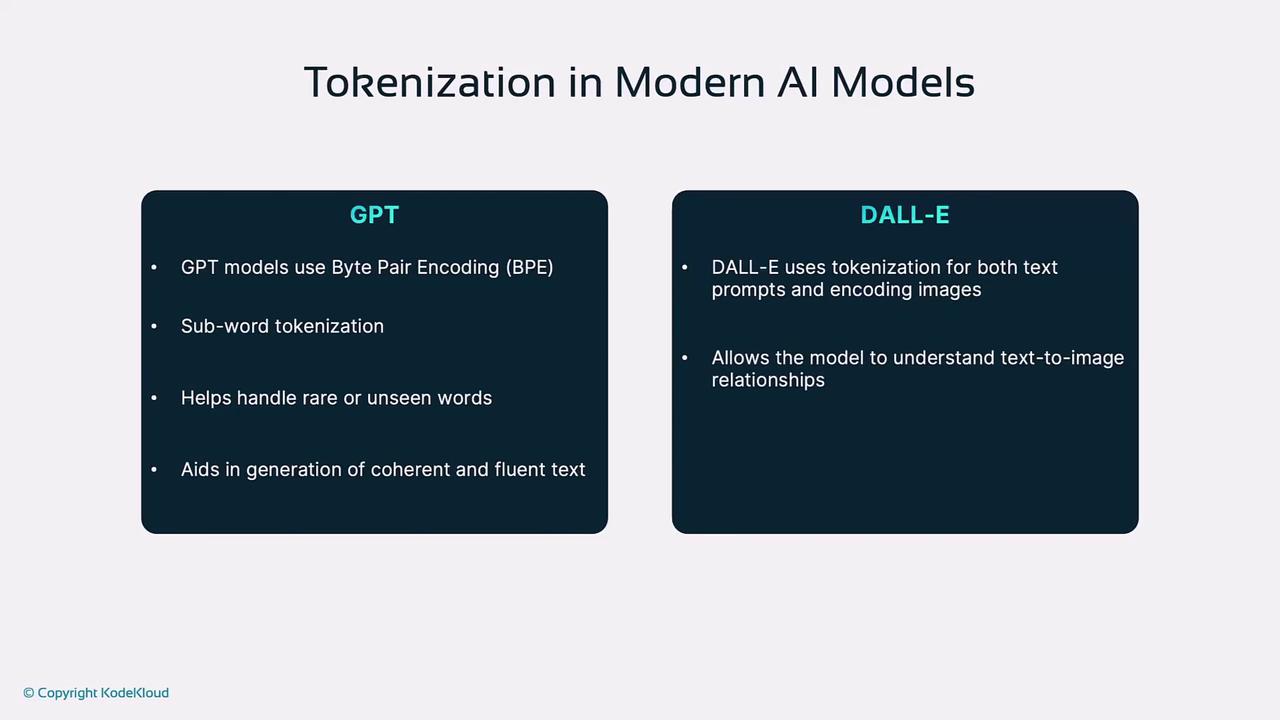
Tokenization in Modern AI Models
GPT Series (e.g., GPT-4)Employs BPE-based subword tokenization to manage vocabulary size while handling rare or novel terms for coherent text generation. DALL·E
Applies tokenization to both textual prompts and image patches, enabling cross-modal learning for text-to-image synthesis.
Challenges and Considerations
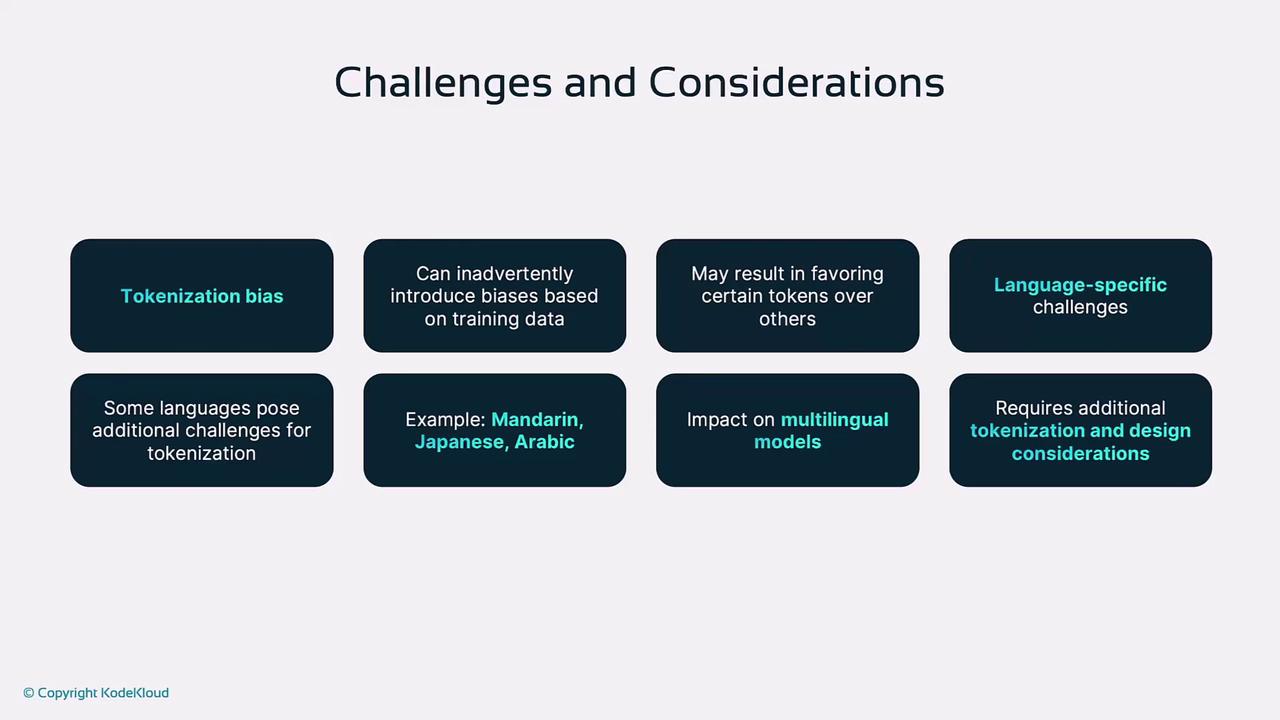
- Tokenization Bias
Frequency imbalances in training data can introduce model bias. - Language-Specific Tokenization
Scripts without spaces (Mandarin, Japanese) require specialized tokenizers. - Multilingual Models
Must efficiently handle diverse scripts and vocabularies for cross-lingual tasks.
Inadequate tokenization may amplify bias or degrade performance in specialized or multilingual scenarios. Always evaluate your tokenizer on representative data.