- Tokenizing text
- Mapping tokens to embeddings
- Applying self-attention over text
- Predicting discrete image tokens
- Decoding tokens into pixels
- Assembling and refining image patches
Pipeline Overview
| Stage | Purpose |
|---|---|
| Tokenization | Split prompt into subword tokens using BPE |
| Embedding | Map each token to a high-dimensional vector |
| Text Self-Attention | Capture contextual relationships between tokens |
| Image Token Generation | Predict discrete image tokens for structure & style |
| Image Decoding | Autoregressively convert tokens into pixel values |
| Patch Assembly & Render | Stitch patches and refine pixels into a seamless output |
1. Tokenization
DALL·E begins by tokenizing your input prompt. Using Byte-Pair Encoding (BPE), the model splits text into subword tokens, ensuring efficient coverage of vocabulary.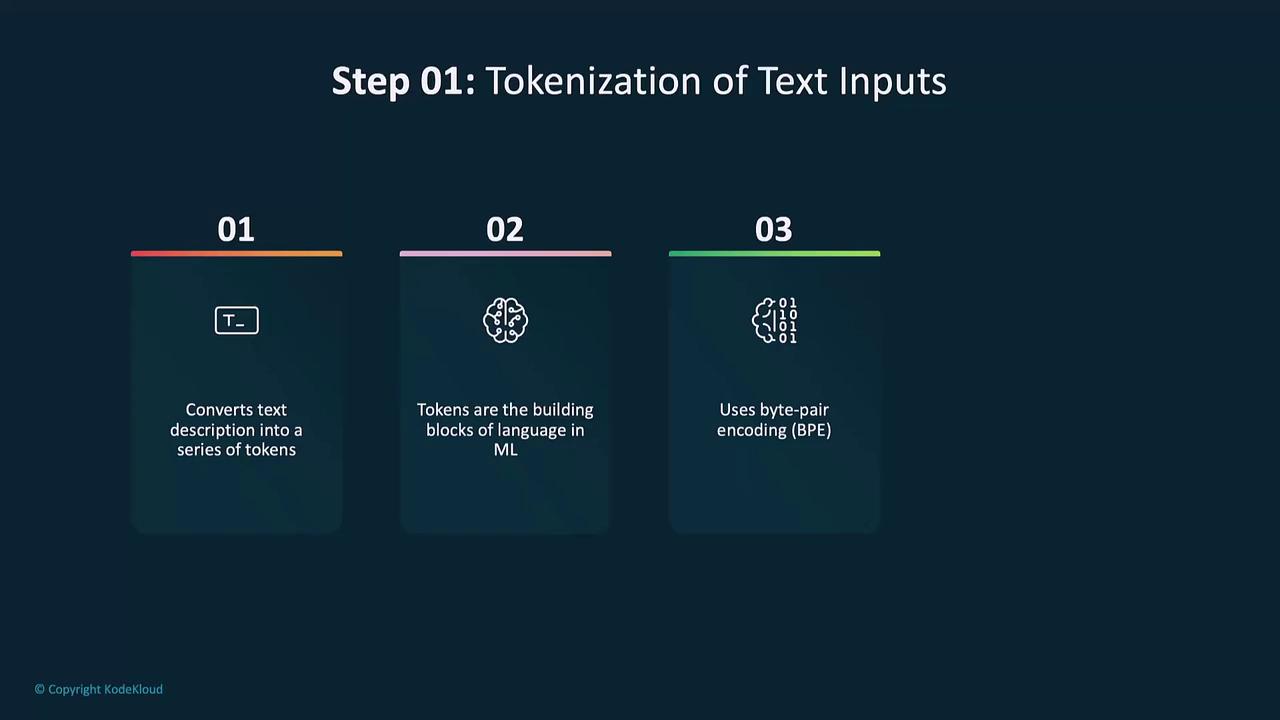
2. Embedding Tokens
Each token is then projected into a continuous embedding space. These dense vectors capture semantic meaning and link text to visual concepts.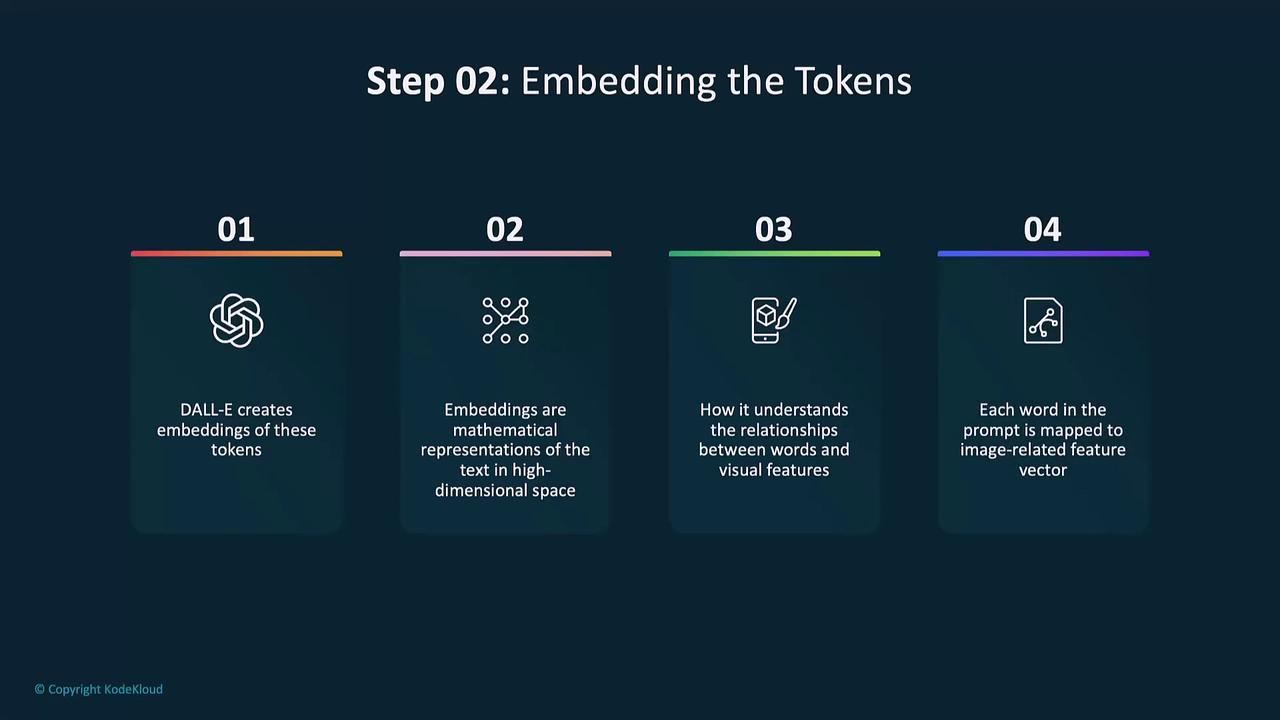
3. Attention Mechanisms for Text
DALL·E employs self-attention to weigh the importance of each token relative to others. This allows the model to focus on key phrases and capture dependencies between words.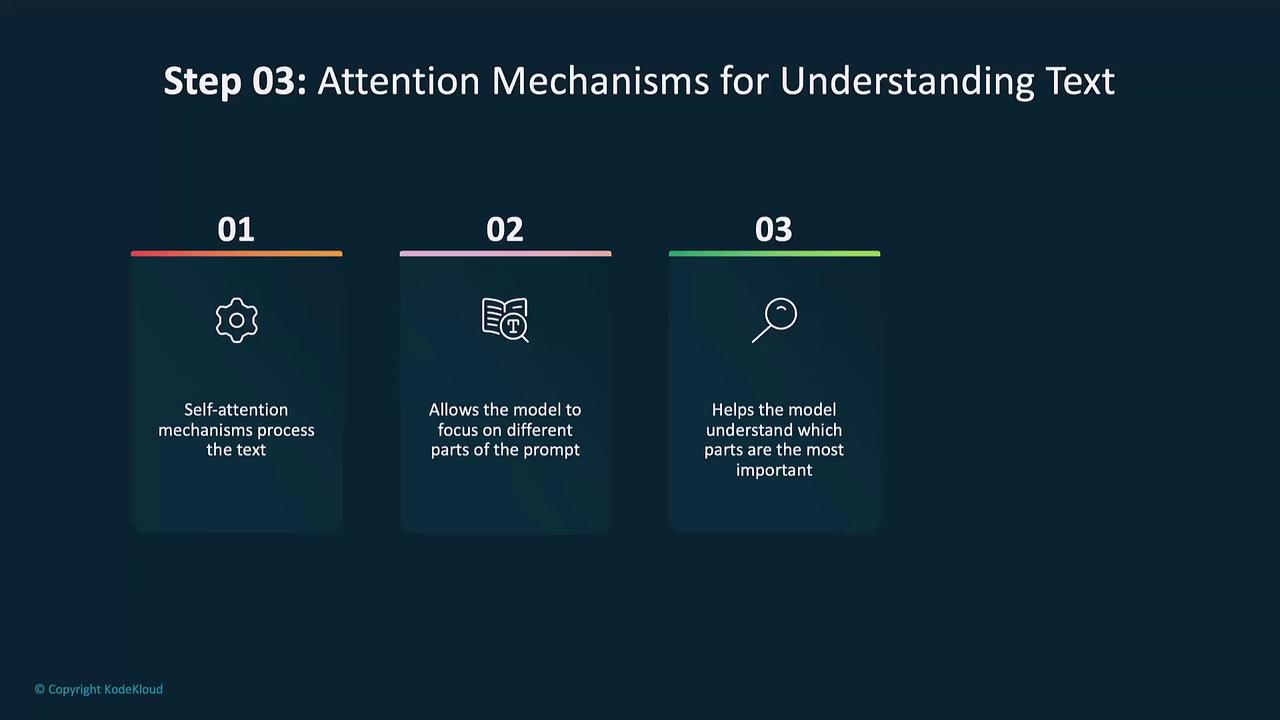
4. Image Token Generation
Once text embeddings are ready, the decoder predicts image tokens. Each token represents discrete visual elements such as shape, color, or texture.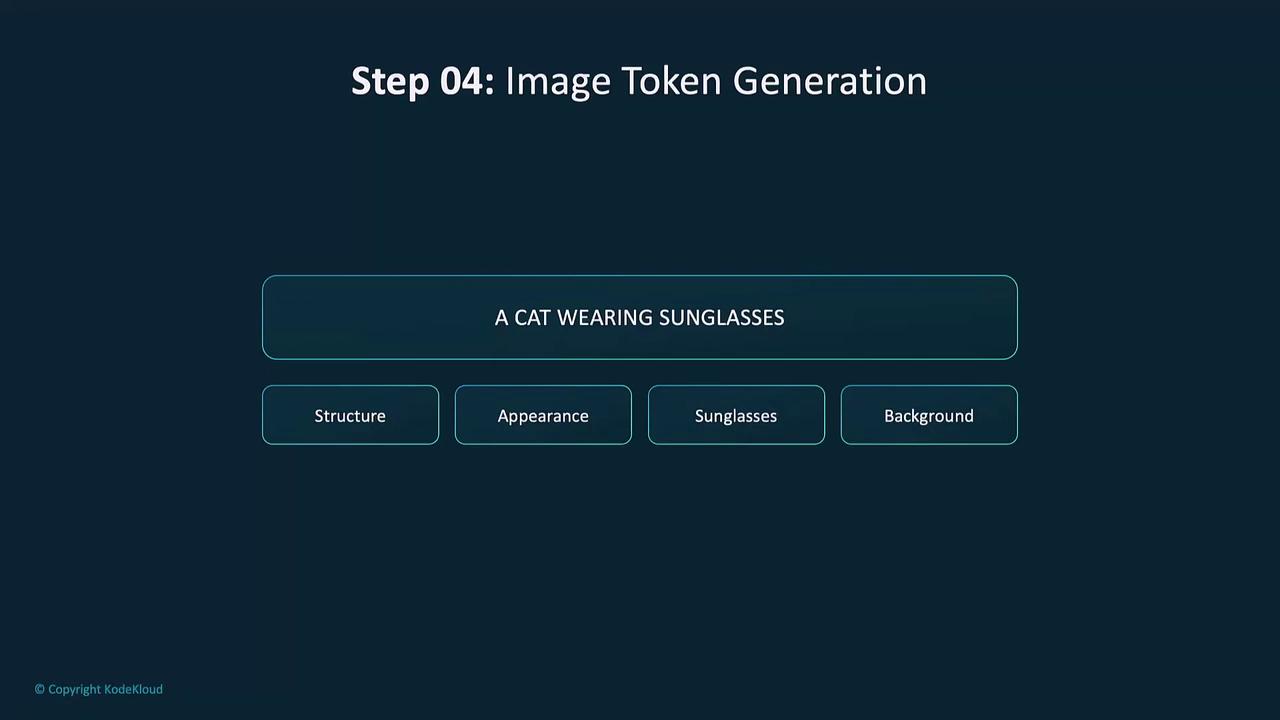
5. Image Decoding
Image tokens are converted into pixel values through autoregressive decoding. Pixels are generated sequentially, ensuring smooth transitions and detailed structure.
Typical output resolutions are 512×512 or 1024×1024. You can adjust this setting via API parameters.
6. Transforming Prompts into Visual Features
DALL·E categorizes tokens into three visual feature types:| Token Type | Role |
|---|---|
| Object Tokens | Main subjects (e.g., “cat,” “cabin”) |
| Attribute Tokens | Qualities (e.g., “red,” “cozy,” “snowfall”) |
| Positional Tokens | Spatial relations (e.g., “next to,” “above”) |


7. Image Patch Generation
Finally, DALL·E composes the image patch by patch. Each patch is generated based on the visual feature tokens. After prediction, patches are stitched together and refined at the pixel level.
If post-processing is skipped, patch seams may become visible. Always apply smoothing or filtering for production-ready images.