

Training vs. Validation Loss
During model training, we compute two key loss metrics: training loss and validation loss. These metrics provide insights into how well the model learns from the provided data.- Training Loss: This metric measures error on the training dataset, which the model uses to iterate and optimize its parameters through methods like gradient descent. A low training loss indicates that the model is learning from the training data, but it doesn’t guarantee good generalization.
- Validation Loss: This loss is computed on an unseen validation dataset after each training epoch (without updating the model parameters). A large discrepancy between training and validation loss is a strong indicator of overfitting.

Overfitting vs. Underfitting
Two common challenges during model training are overfitting and underfitting:- Underfitting: Occurs when the model is too simple to capture the underlying trends in the data, resulting in poor performance on both training and test datasets.
- Overfitting: Happens when a model is overly complex and starts to memorize the training data instead of learning generalizable patterns. Even though it might perform excellently on the training set, its performance on new, unseen data deteriorates.

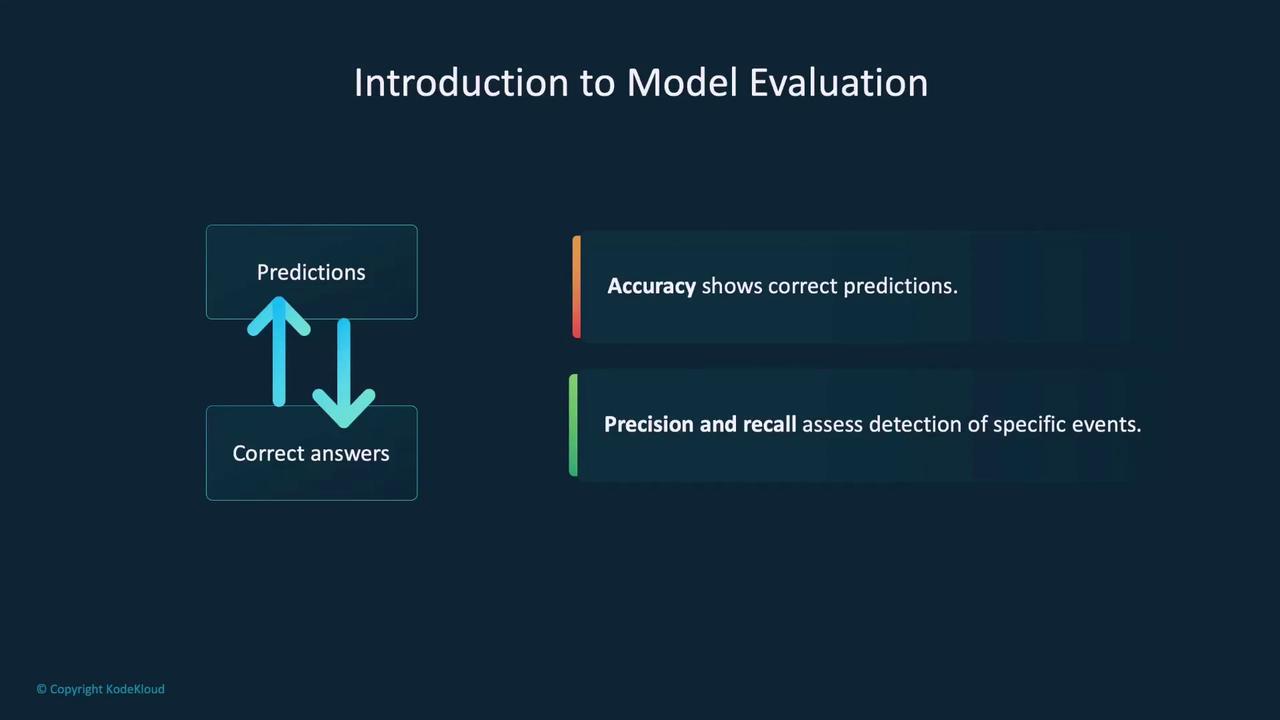
Evaluation Metrics
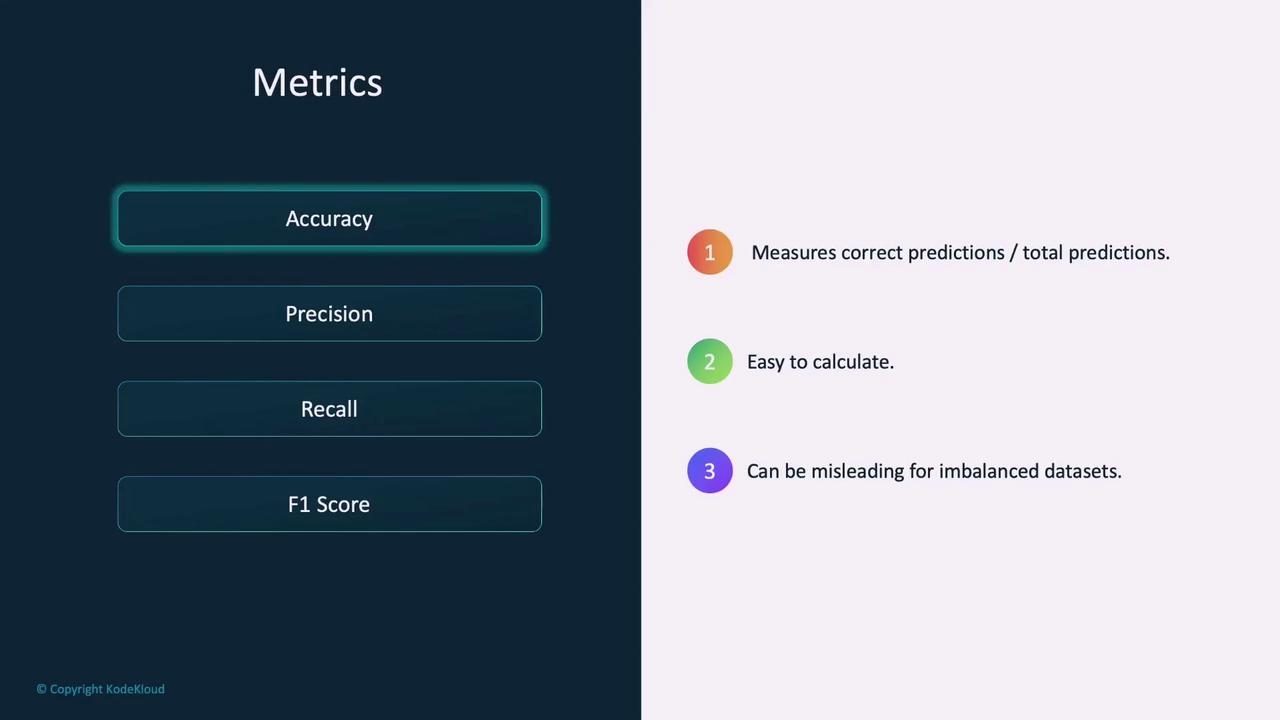
Model evaluation employs several metrics to quantify performance:- Accuracy: Represents the ratio of correctly predicted instances to the total predictions. While accuracy is easy to compute, it can be misleading for imbalanced datasets.
- Precision: Indicates the ratio of true positive predictions to all positive predictions made by the model. This metric is vital in scenarios where false positives carry a high cost, such as spam detection or medical diagnosis.
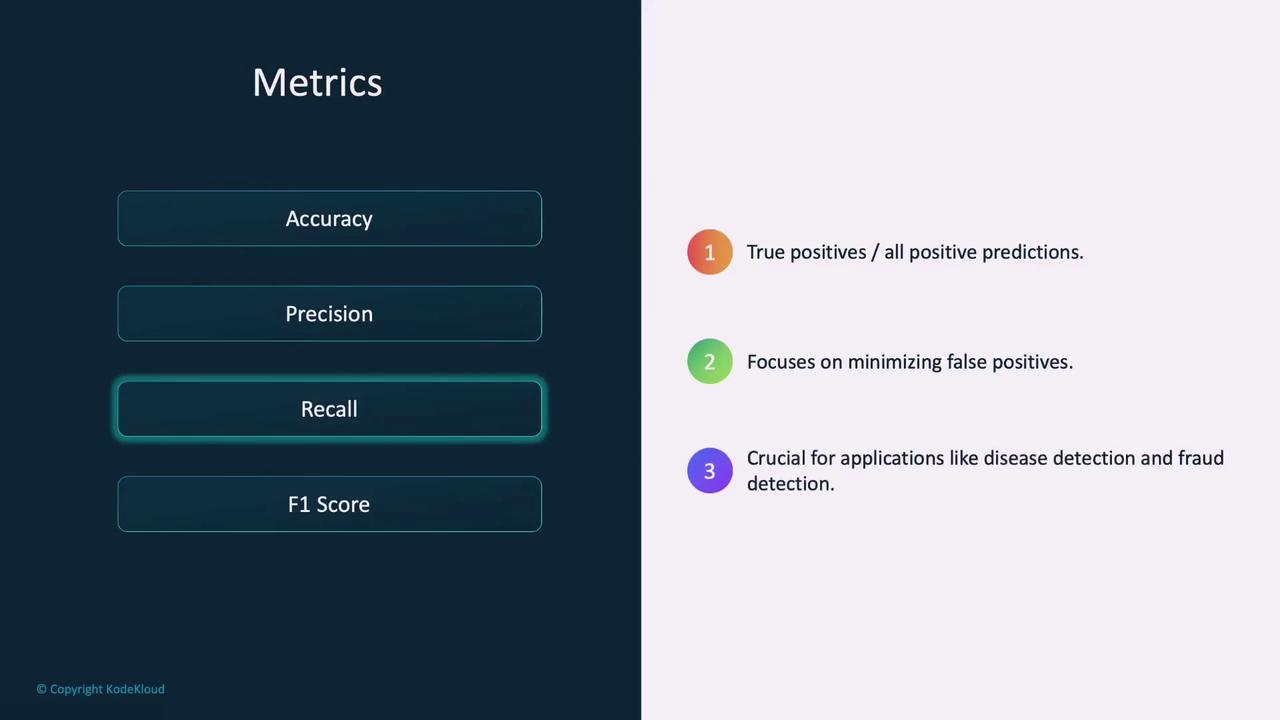
- Recall: Denotes the ratio of true positive predictions to all actual positive cases, focusing on the model’s ability to identify all positive instances. It is especially important in fields like disease detection and fraud monitoring.
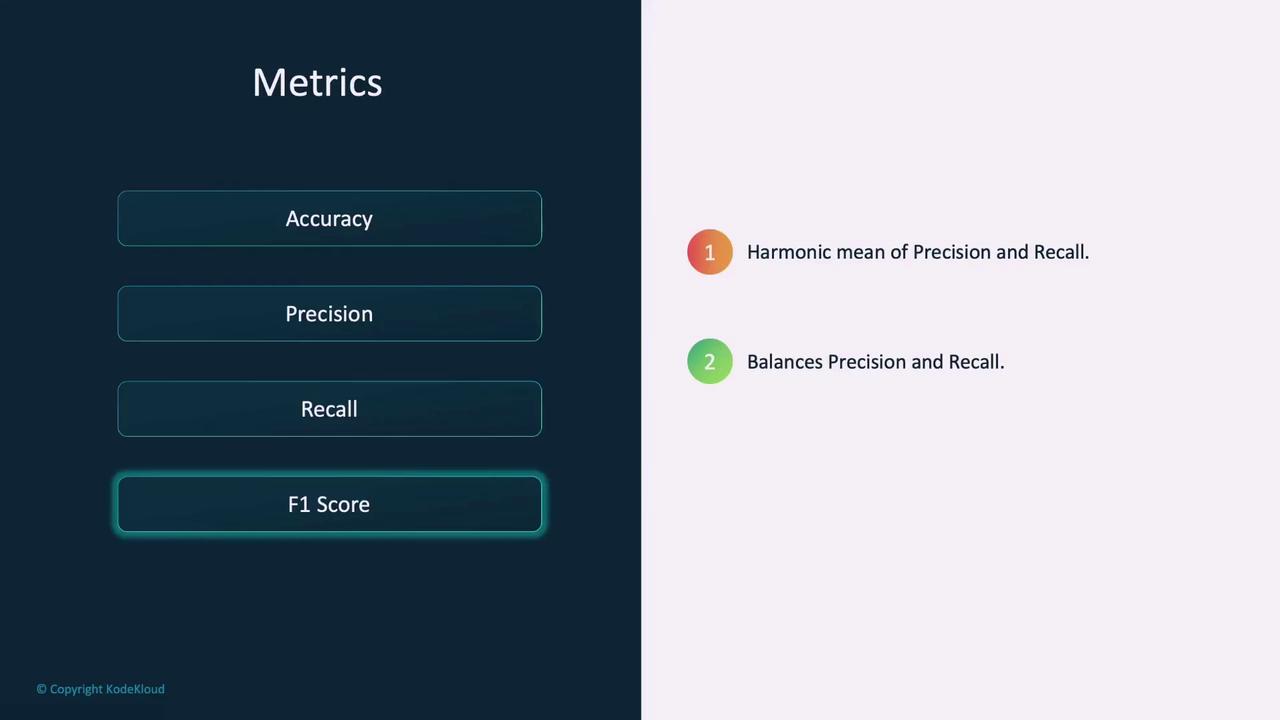
- F1 Score: This is the harmonic mean of precision and recall. It provides a single metric that balances both false positives and false negatives, making it useful when you need a balance between precision and recall.
The Confusion Matrix
A confusion matrix is an essential tool for evaluating classification models. It offers a detailed breakdown by comparing actual labels with the model’s predictions and categorizing them as follows:- True Positives: Both predicted and actual labels are positive (e.g., both are “dog”).
- True Negatives: Both predicted and actual labels are negative.
- False Positives: The model predicts positive while the actual label is negative.
- False Negatives: The model predicts negative while the actual label is positive.


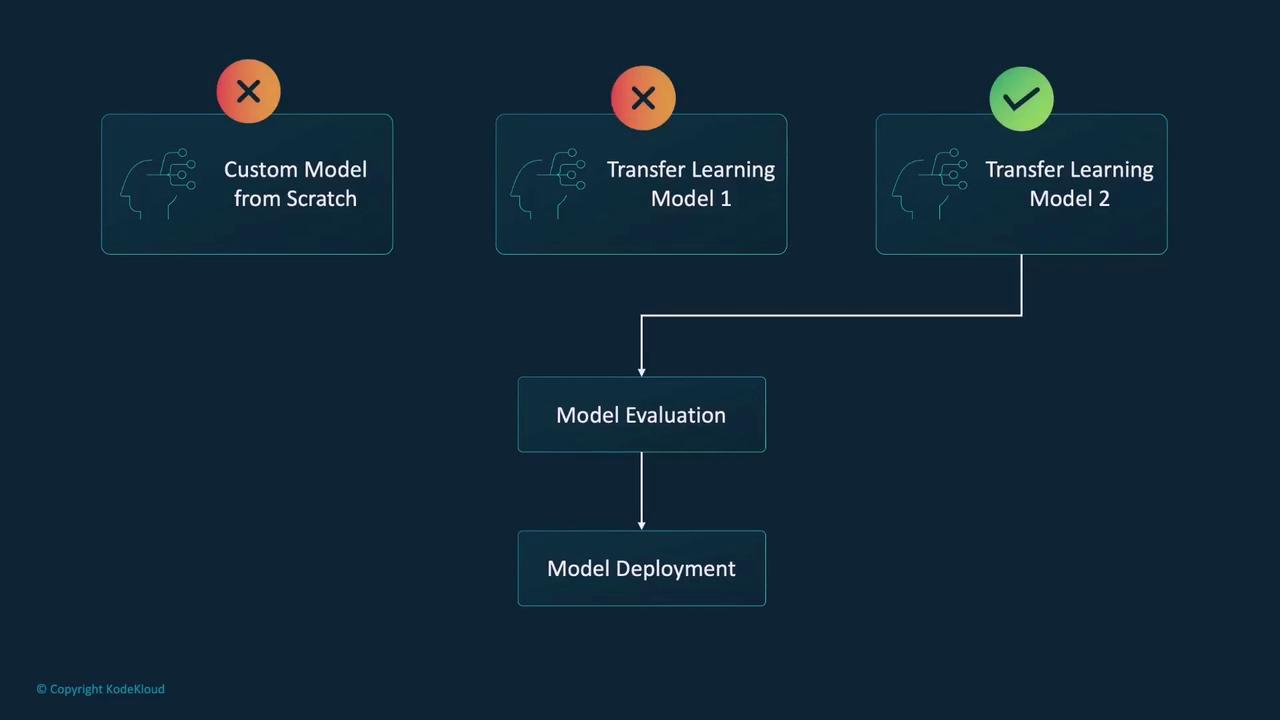
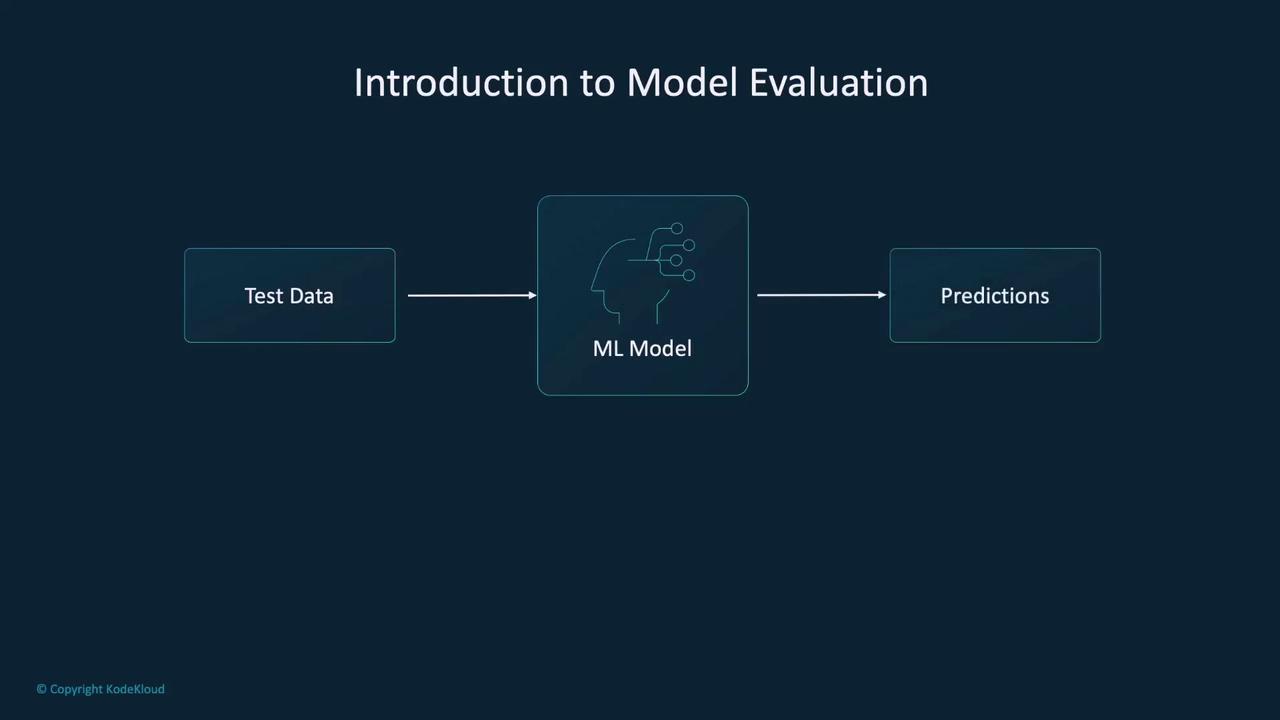
Model Evaluation in Practice
Evaluating a model often mirrors the approach used during training, but with key distinctions. In evaluation, we use a test loop where gradient computation is disabled using PyTorch’sno_grad function. This approach reduces memory usage and enhances computational speed.
Below is an example showcasing both a training loop (for context) and a test loop used for evaluation:
test_loader dataset is used to evaluate the model on unseen data. The use of torch.no_grad() is crucial as it temporarily disables gradient tracking during inference, significantly reducing memory consumption.
Inference Paradigms
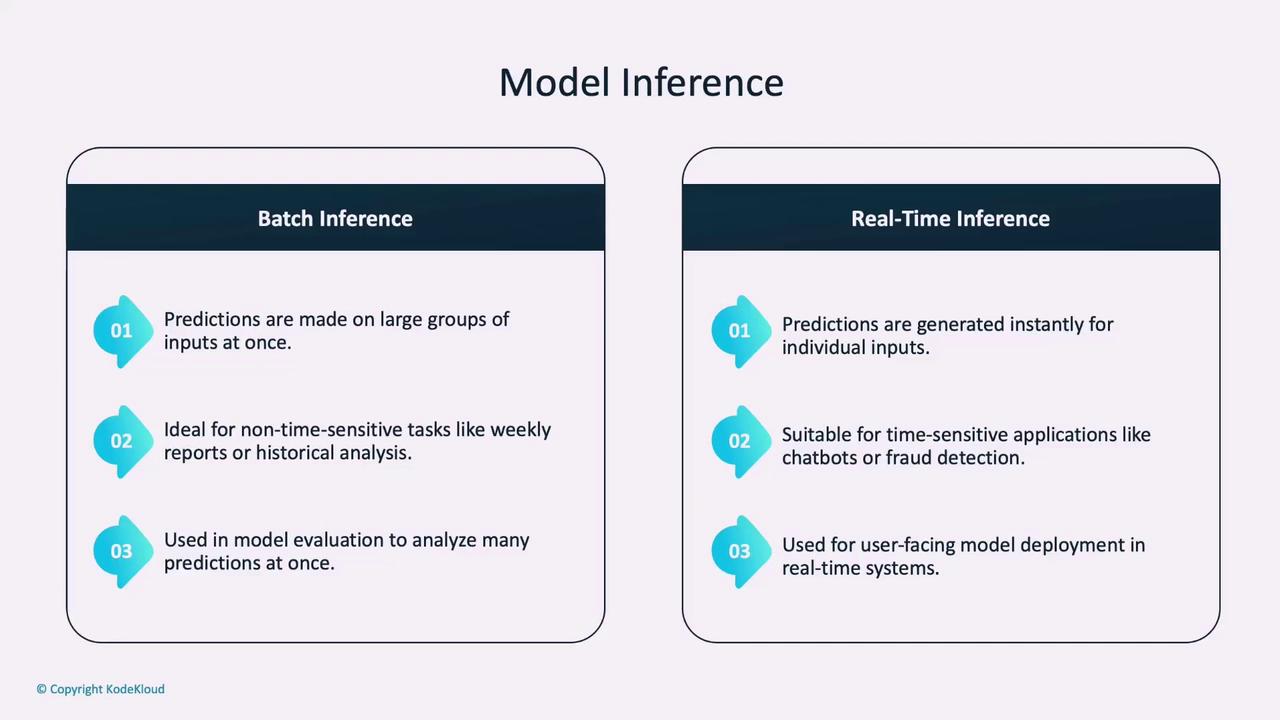
There are two primary paradigms for model inference:- Batch Inference: This approach processes predictions on a group of inputs at once, making it ideal for non-time-sensitive tasks like generating weekly reports or analyzing historical data. It allows for efficient processing of large datasets.
- Real-Time Inference: In this scenario, predictions are generated instantly as individual inputs arrive. This method is critical for time-sensitive applications such as chatbots, fraud detection systems, or self-driving cars.
Integrating TorchMetrics for Evaluation
For more efficient metric computation in our test loop, we can integrate the TorchMetrics library. TorchMetrics simplifies tracking of key performance metrics in PyTorch. It provides pre-built functions for metrics such as accuracy, precision, recall, and F1 score, and is compatible with both CPU and GPU. You can also define custom metrics if needed.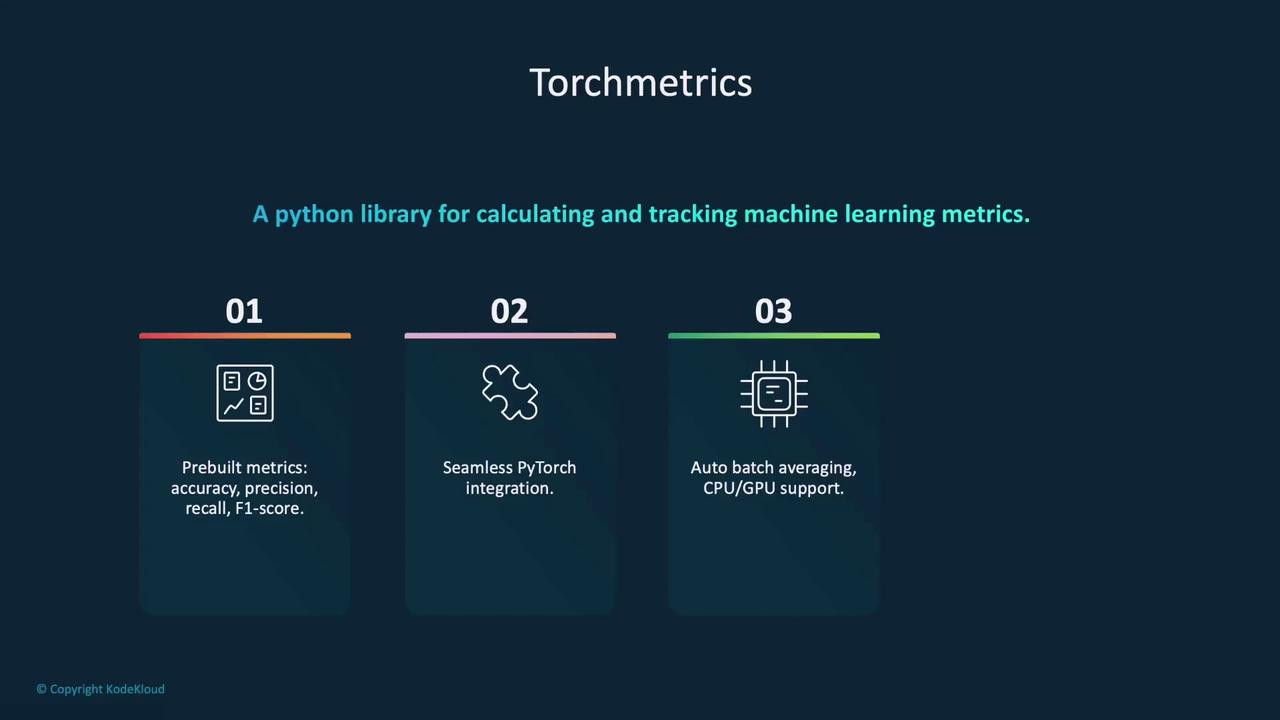
Alternative Evaluation Methods
In addition to TorchMetrics, other evaluation libraries such as Scikit-learn offer robust solutions and additional metrics:- Accuracy Score: For overall prediction accuracy.
- Classification Report: Provides a detailed report including precision, recall, and F1 score.
- Confusion Matrix: Offers a granular breakdown of true vs. predicted labels.

Summary
In summary, model evaluation is critical for ensuring that a machine learning model generalizes well to unseen data. Key takeaways include:- Monitoring both training and validation losses to detect overfitting or underfitting.
- Utilizing diverse evaluation metrics such as accuracy, precision, recall, and F1 score.
- Leveraging tools like the confusion matrix for detailed analysis of the model’s performance.
- Integrating libraries such as TorchMetrics or Scikit-learn to streamline the evaluation process.
- Understanding the distinction between batch and real-time inference based on application requirements.
- Using PyTorch’s
no_grad()function during evaluation to optimize memory usage and speed up inference.


For optimal model performance, always validate using multiple metrics and choose the evaluation strategy that aligns with your application’s requirements.