This article explores data preparation for AI and ML models, covering preprocessing, labeling, augmentation, and privacy management to ensure effective learning and fairness.
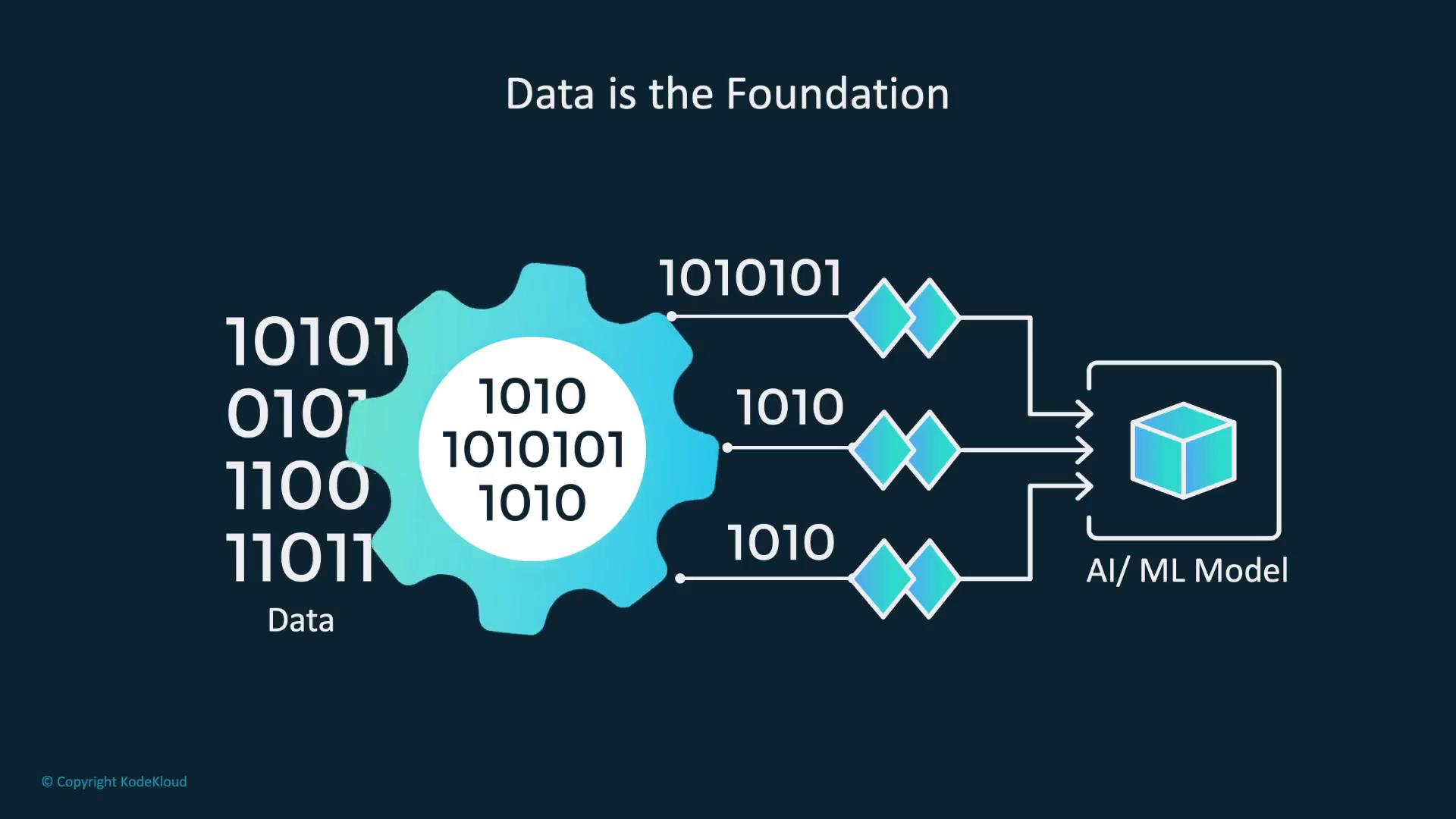
Data is the foundation of any successful AI and ML model. The quality, quantity, and ethical management of your data greatly impact the performance and fairness of your models.
In this article, we explore essential topics related to data preparation. We cover preprocessing, labeling, augmentation, and privacy management—key steps that ensure your model learns effectively while adhering to legal and ethical standards.
Data is the cornerstone for model learning. Think of it as the collection of experiences from which an AI system draws knowledge. High-quality data enables models to capture accurate patterns, while poor-quality data can lead to unreliable outcomes. In addition, having a substantial amount of diverse data empowers your model to understand complex patterns and generalize well.
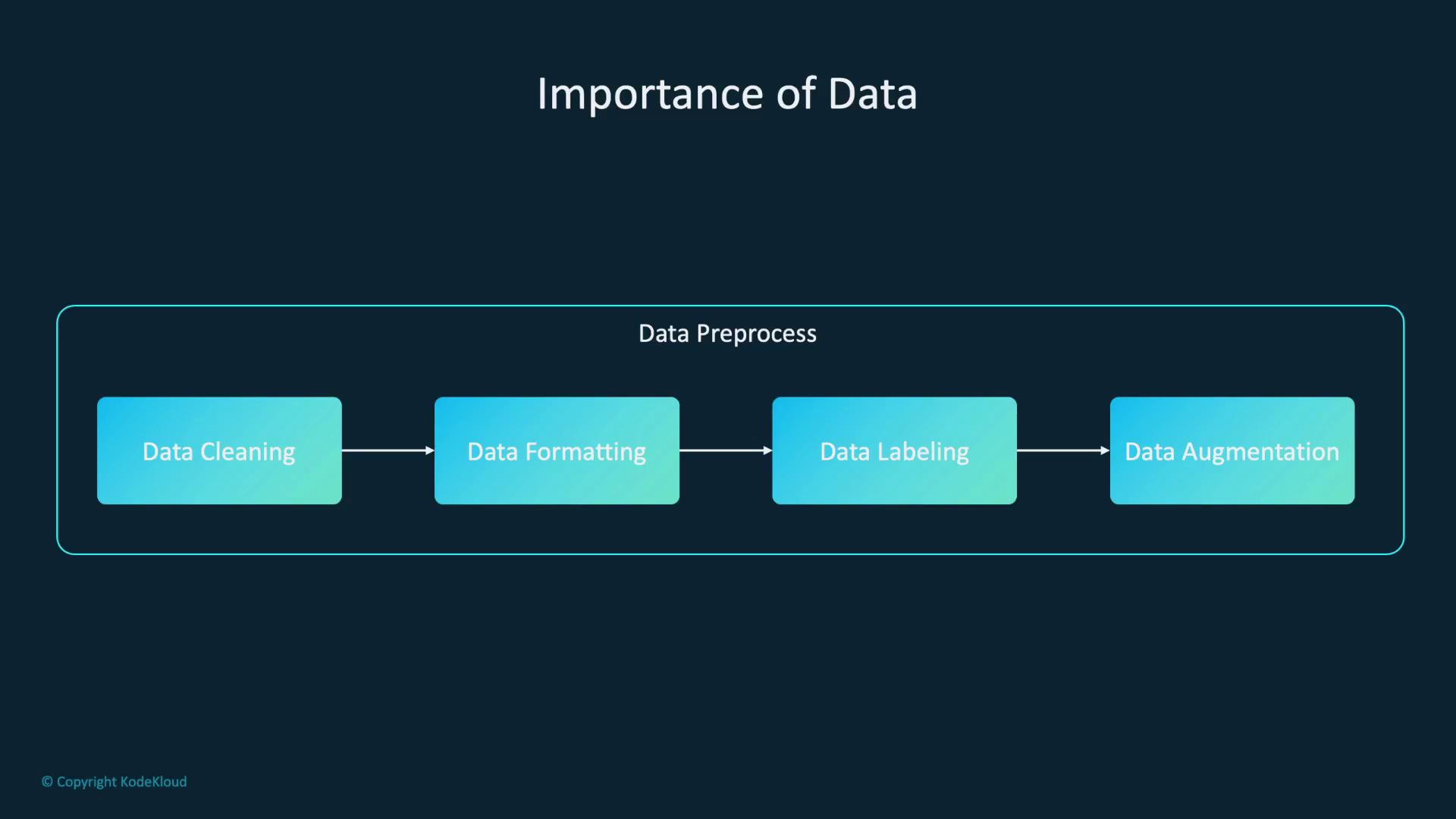
A robust dataset should undergo thorough preprocessing:
Clean the data by removing errors and duplicates.
Format the data appropriately for the model.
Label the data to provide clear guidance during training.
Augment the data to enhance its diversity and robustness.
By prioritizing data quality, quantity, and thorough preparation, you set a strong foundation for successful model building. Ensuring accurate, consistent, and complete data helps the model learn and perform better.
For instance, if the dataset overwhelmingly contains images of cats with few dog images, the model may perform well on cats but struggle with dogs. To avoid this imbalance, ensure even representation across classes. Managing large and diverse datasets is streamlined by using PyTorch’s DataLoader:
Copy
# Create a DataLoader object with a batch size of 32dataLoader = DataLoader(dataset, batch_size=32, shuffle=True)
We will cover DataLoaders in more detail in the upcoming section.
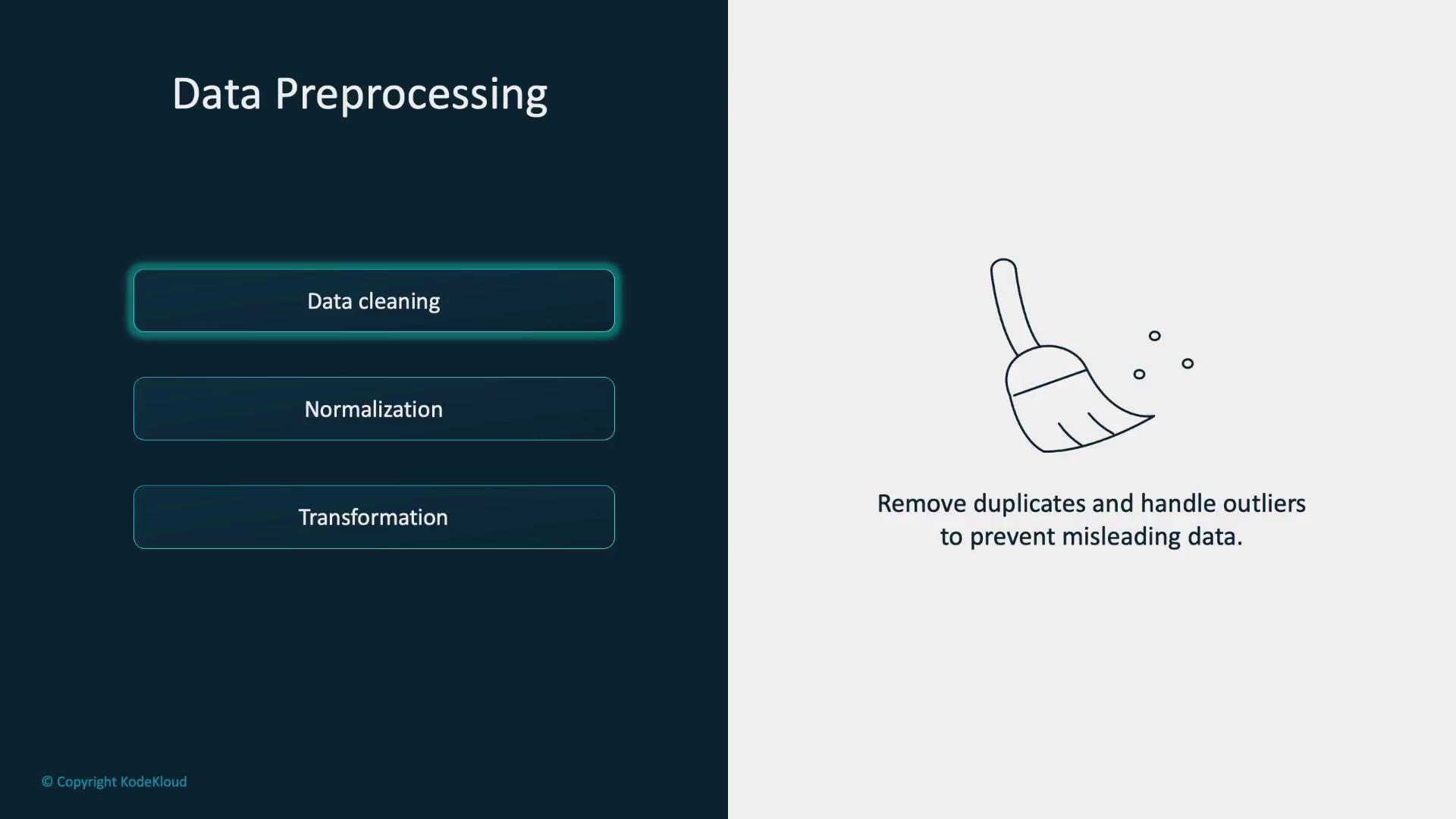
Data preprocessing is critical for model training. It begins with cleaning—removing duplicates and addressing outliers that could mislead the model.
Next, normalization scales data features to similar ranges. This improvement helps the model learn efficiently and converge faster. Transformations convert raw data into a format that models can interpret—often transforming images or text into numerical tensors using libraries like TorchVision. The code below demonstrates how to resize images, convert them to tensors, and normalize their pixel values:
Data augmentation further increases dataset diversity by applying transformations such as horizontal flips, rotations, or color adjustments. This technique is especially valuable when data is limited, as it enables the model to generalize better from an expanded set of examples.
Using TorchVision’s transforms, you can easily implement these augmentations. Consider the example below:
Copy
# Transformations for data augmentationtransform = transforms.Compose([ transforms.RandomHorizontalFlip(p=0.5), # Randomly flip images horizontally with a probability of 0.5 transforms.RandomRotation(degrees=15), # Randomly rotate images by up to 15 degrees transforms.ToTensor() # Convert images to PyTorch tensors])
Splitting your data into training, validation, and testing sets is essential for robust model performance. This approach helps prevent overfitting and ensures realistic evaluation of the model’s performance.
PyTorch’s utility, RandomSplit, allows you to partition your dataset easily:
Copy
# Split the full dataset into training, validation, and testing setstrain_data, val_data, test_data = random_split(full_data, [train_size, val_size, test_size])
Accurate data labeling is crucial in supervised learning, as correct labels guide the model’s understanding of input-output relationships. Mislabeling can lead to flawed performance; therefore, ensuring consistent annotation is key.
In PyTorch, custom dataset classes simplify the management of labeled data. The example below demonstrates how to instantiate a custom dataset from a CSV file:
Copy
# Instantiate a custom dataset from a CSV filedataset = CustomDataset(csv_file='dataset.csv')
Bias in data can lead to models that exhibit unfair or discriminatory behaviors. To build equitable models, it is important to detect and correct these biases during data preparation.
When handling data, always prioritize protecting individuals’ privacy by anonymizing personal information and securing sensitive data. Comply with regulations such as GDPR or HIPAA.
Responsible data usage involves obtaining consent, transparently communicating how data is used, and carefully assessing the societal impact of your models.
Next Steps: Custom Datasets and PyTorch Data Handling
In the upcoming section, we will dive deeper into PyTorch by building custom datasets. We’ll explore the Dataset and DataLoader classes and leverage TorchVision transforms for sophisticated preprocessing, standardization, and augmentation of image data.
Let’s begin our exploration of PyTorch by working with datasets and data loaders to facilitate efficient and scalable model training.