AWS Solutions Architect Associate Certification
Designing for Reliability
Turning up Reliability on Management Services
Welcome back, Solutions Architects. In this lesson, we explore how to enhance reliability across AWS management and governance services. We’ll cover provisioning, observability, and various management tools, providing insights into their inherent design and how they support resilience without requiring additional configuration.
Provisioning
AWS CloudFormation is the native provisioning tool of AWS, forming the backbone of resource creation and management. Even if you leverage third-party tools like Terraform or code-based solutions such as the AWS Cloud Development Kit (CDK) version 2, it ultimately generates CloudFormation templates. This means that understanding CloudFormation is essential, regardless of the provisioning method you select.
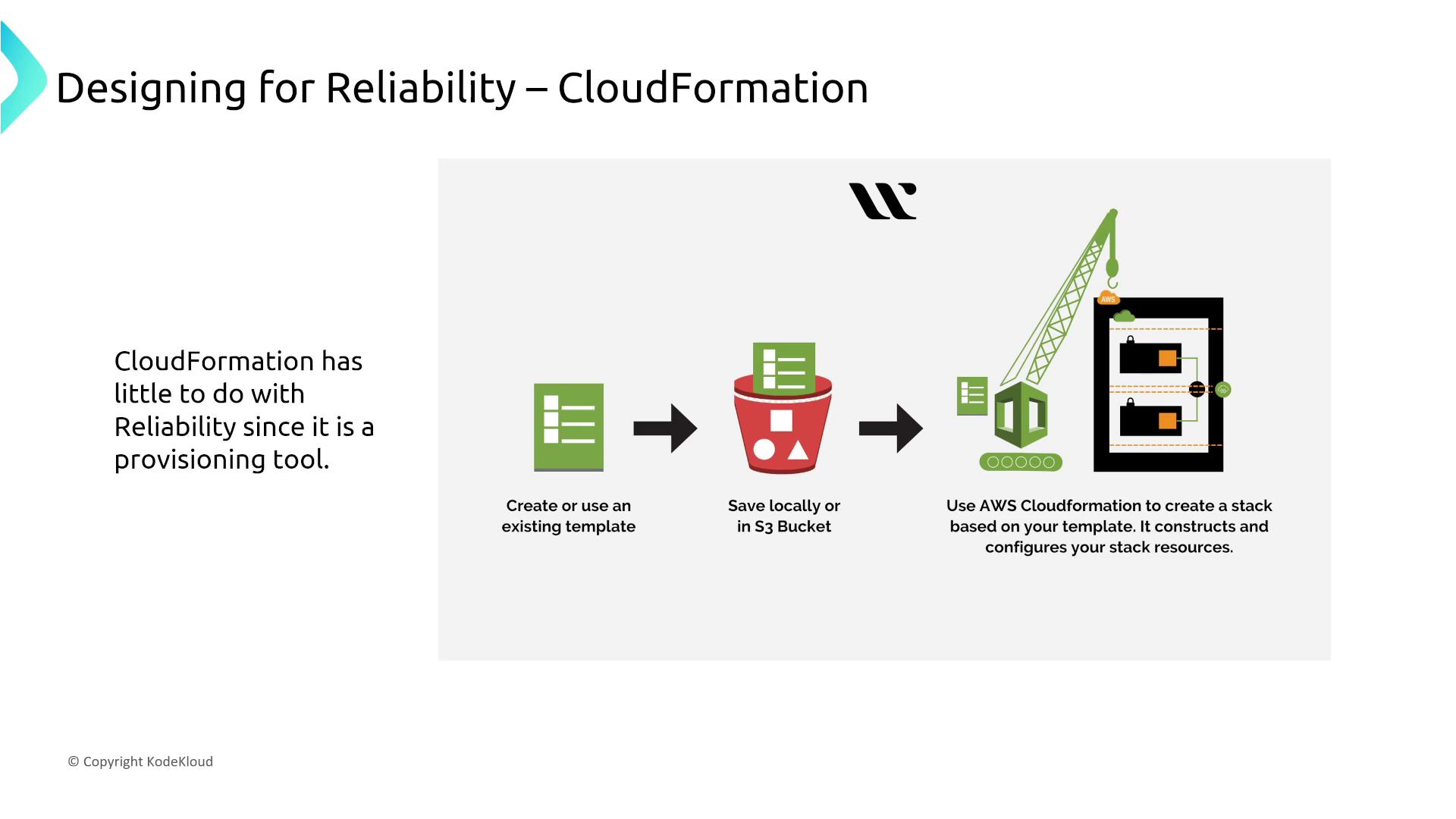
CloudFormation is built for inherent reliability—there are no additional configuration options or custom retry policies. Similarly, the AWS CDK, while providing a code-driven approach to create CloudFormation templates, does not extend reliability features beyond those already available in CloudFormation.
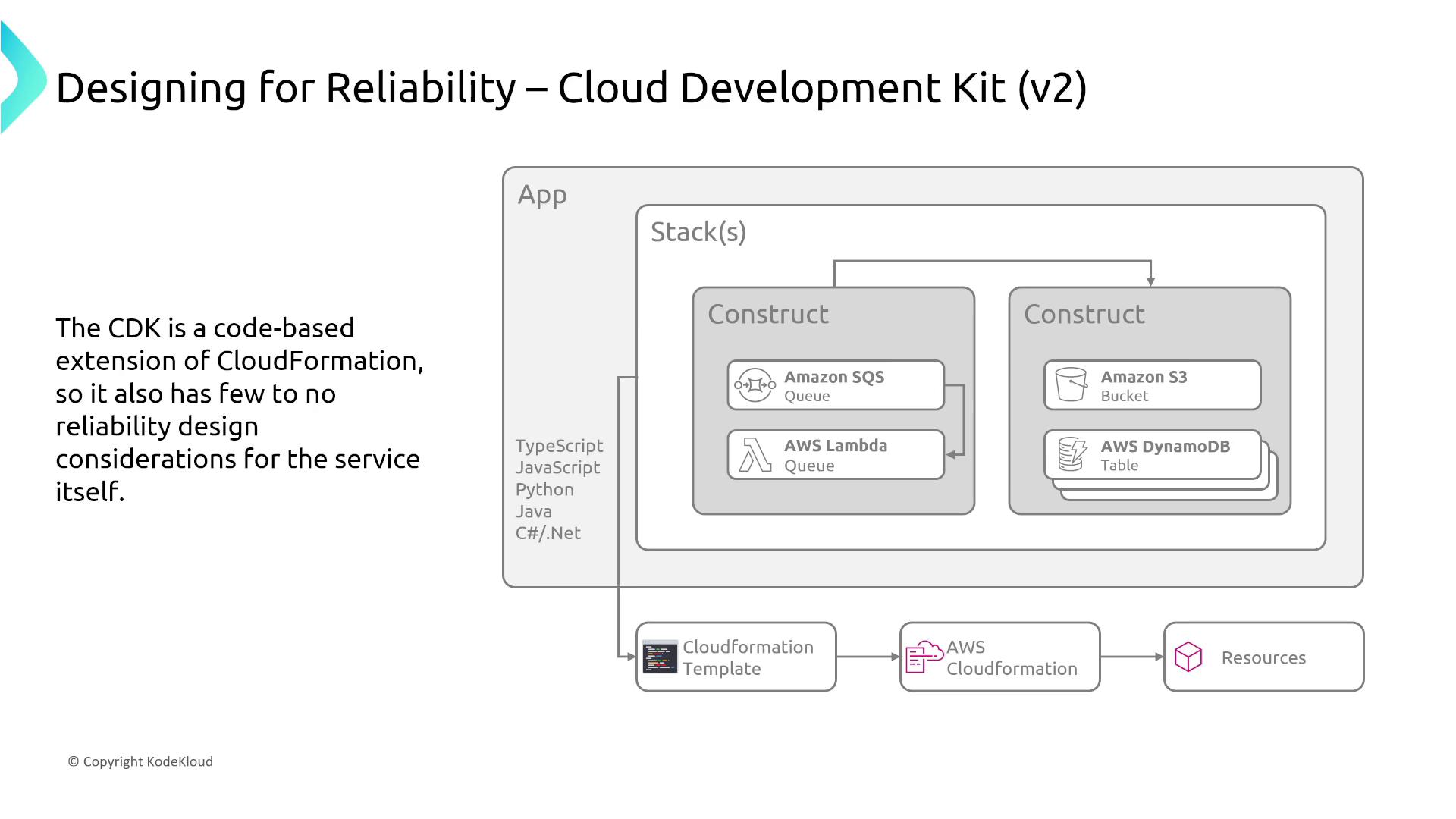
For operations teams, it is crucial to have visibility into the generated resources for troubleshooting. Generating a CloudFormation template from a CDK application is straightforward, thus enabling effective tracking and management of these resources.

Observability
Observability is key to managing application performance and ensuring operational reliability. AWS CloudWatch provides a robust suite of monitoring features including logs, alarms, events, and insights. Designed for high availability, CloudWatch serves as a central hub for tracking metrics, troubleshooting issues, and guiding performance optimizations.
In production, when performance issues arise, CloudWatch consolidates metrics through dashboards, logs, and events, allowing for in-depth analysis. Additionally, AWS Health and the Personal Health Dashboard offer operational status insights similar to Security Hub or Migration Hub—without the need for extra reliability configurations.
Other Management Services
AWS offers a broad range of management services that are inherently resilient and designed to function without manual reliability tweaks.
Managed Prometheus and Grafana
Managed Prometheus automatically scales and recovers, offering a plug-and-play experience without server-level configuration changes. When integrated with Amazon Managed Grafana, a unified dashboard view is achieved with the same managed-reliability design.
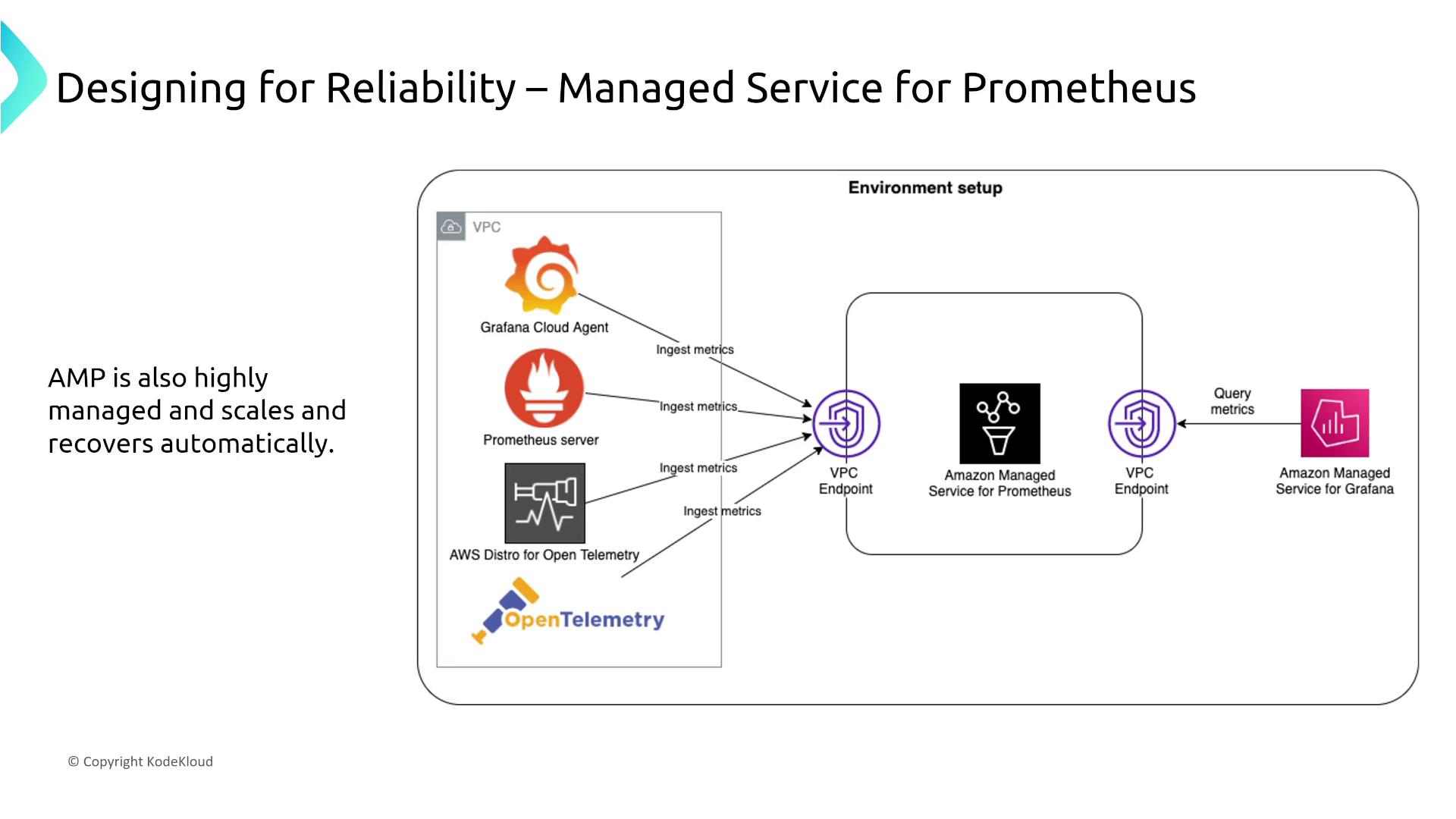
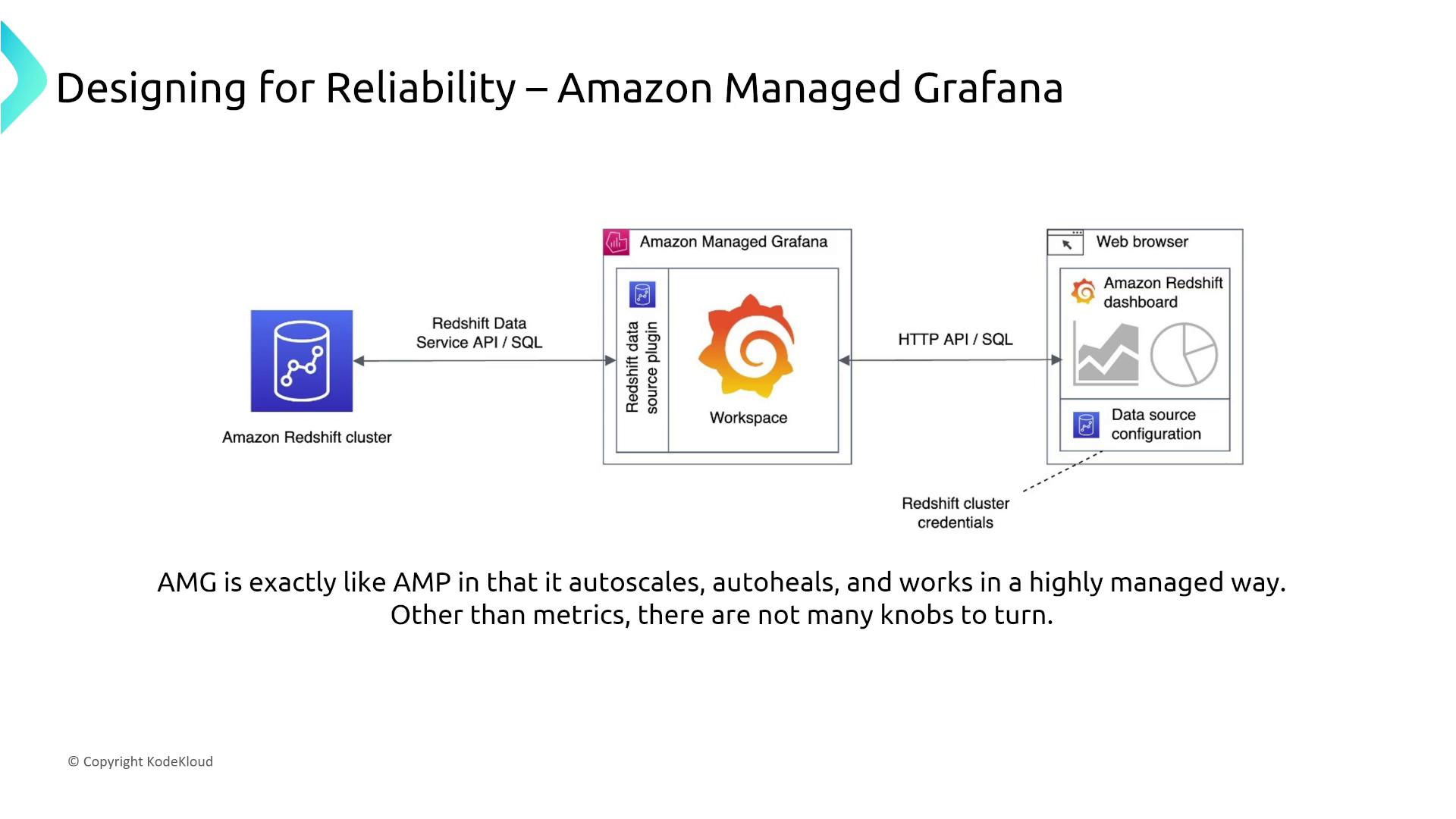
For organizations seeking a single pane of glass for application metrics, Amazon Managed Grafana provides a highly dependable dashboard without requiring manual reliability adjustments.

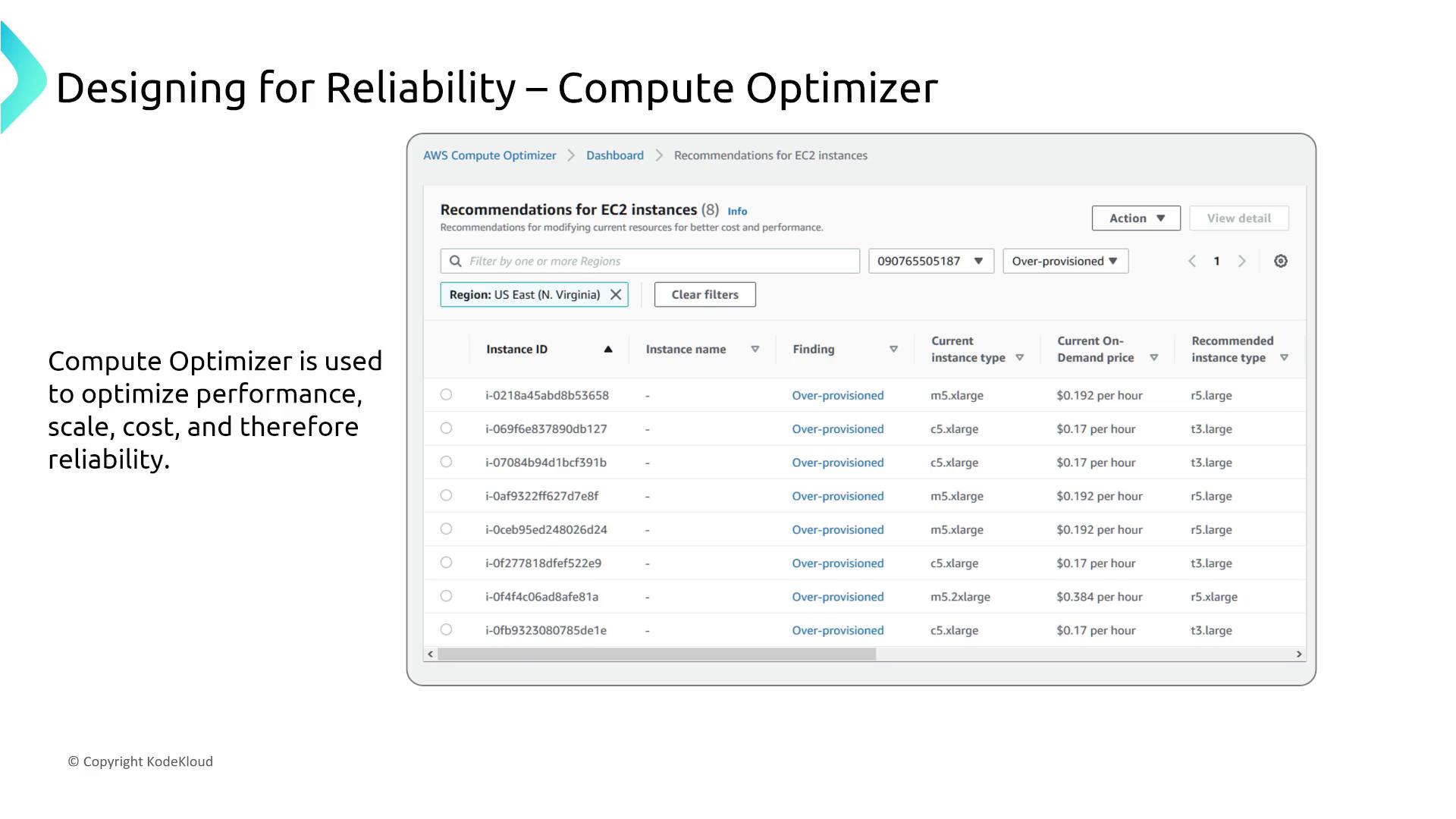
Trusted Advisor and Compute Optimizer
AWS Trusted Advisor and Compute Optimizer help optimize fault tolerance and cost efficiency. Trusted Advisor, with fault tolerance checks available under specific support plans, and Compute Optimizer, offering resource optimization recommendations, both operate with inherent reliability without requiring any configuration adjustments.


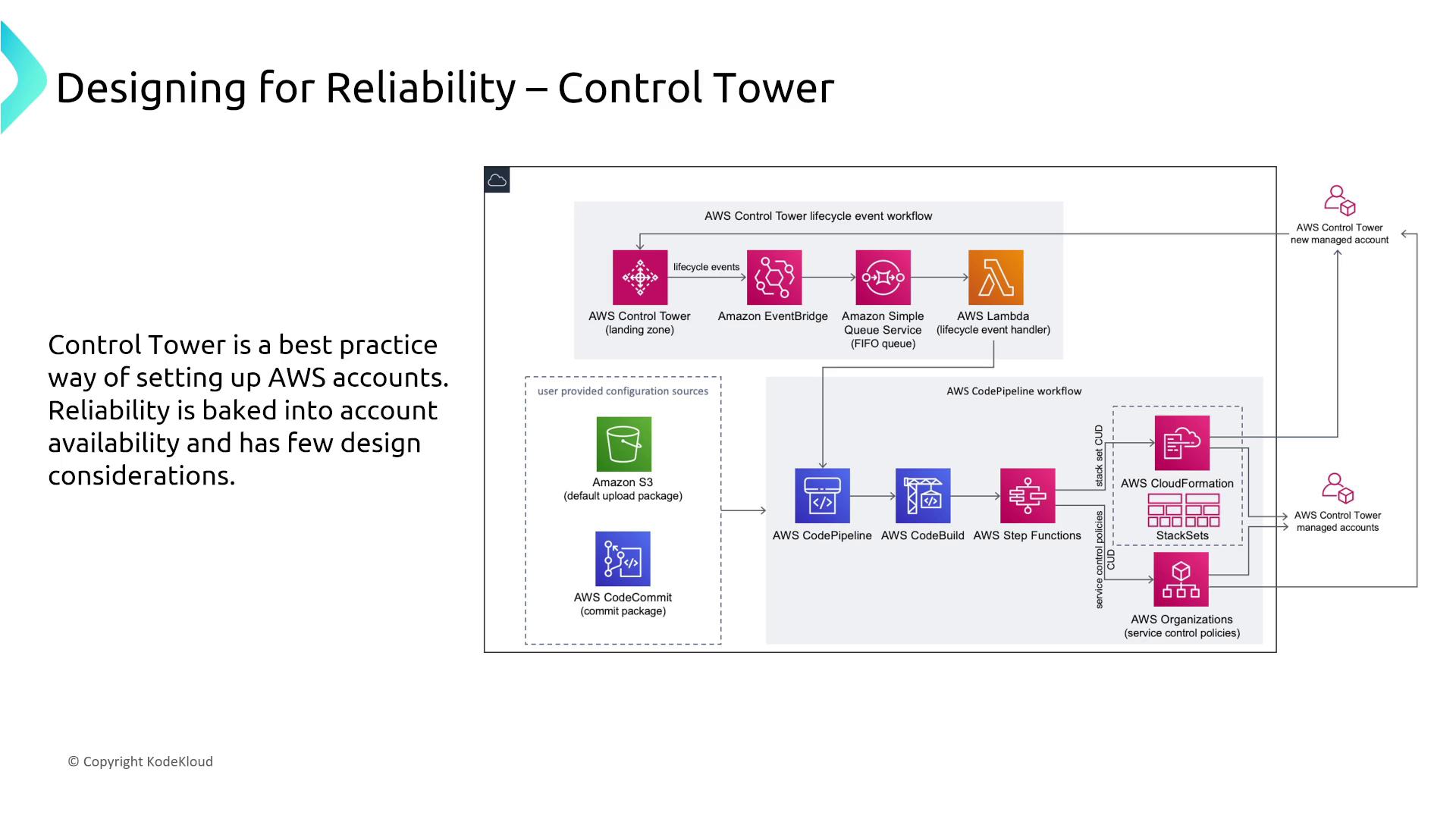
Organizations and Control Tower
While AWS Organizations is focused on account management rather than service reliability, AWS Control Tower automates account setup with best practices, such as service control policies and auditing. This automation inherently promotes resiliency across multiple accounts.

Systems Manager
AWS Systems Manager provides extensive operational capabilities to manage both cloud and on-premises resources efficiently. It is engineered to support critical tasks such as OS patching and compliance checks reliably without additional configuration.
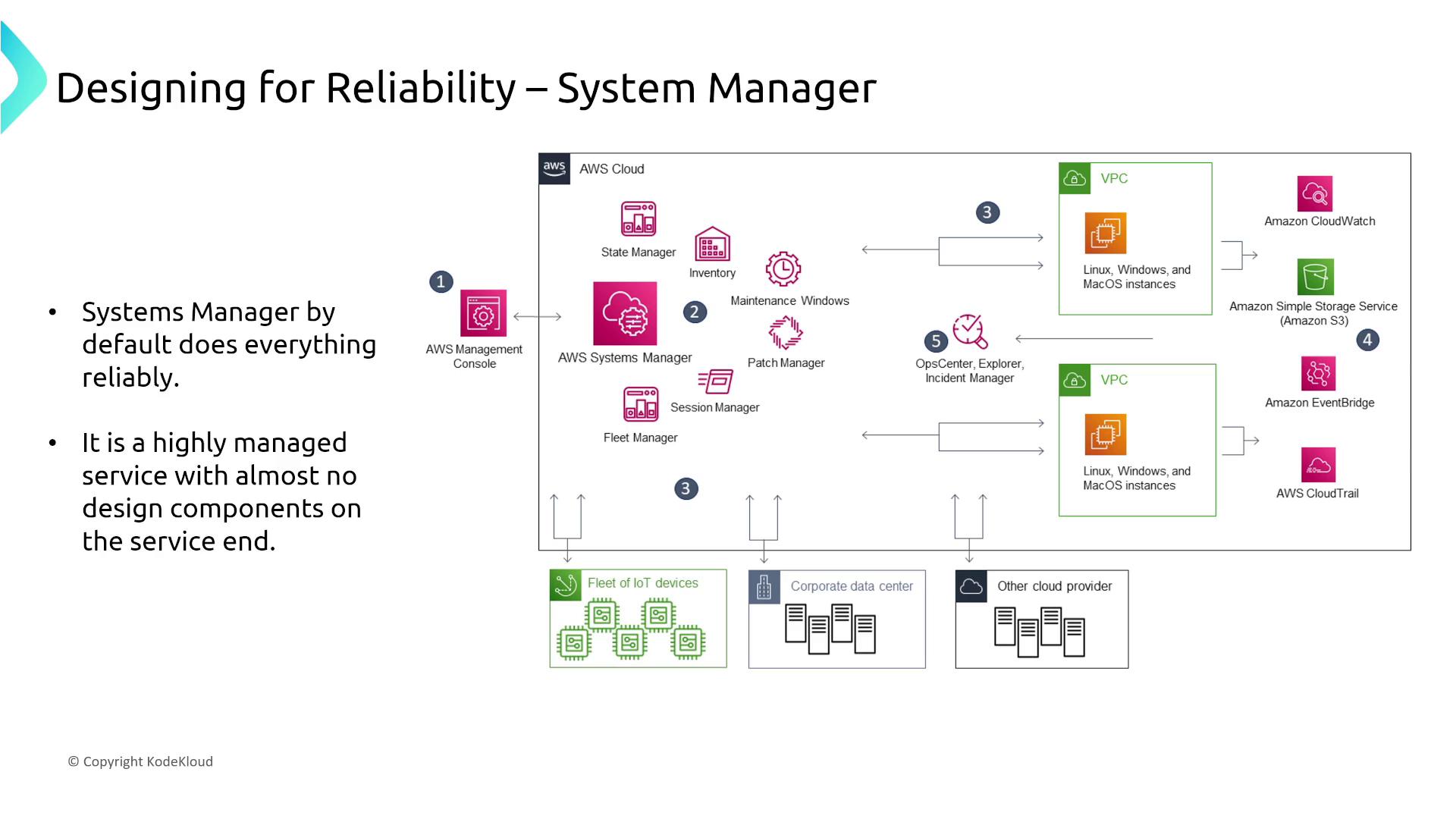
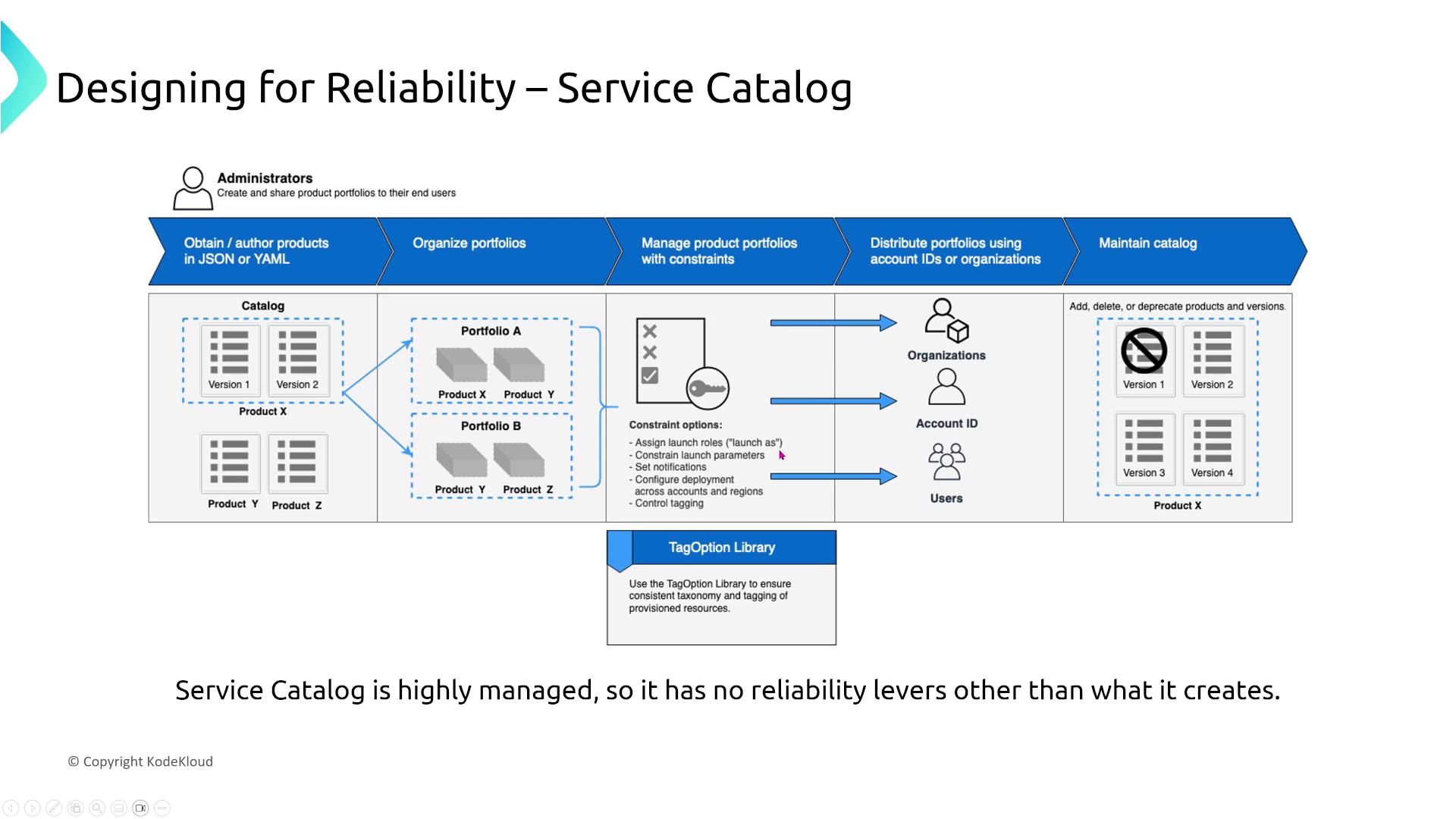
Service Catalog and License Manager
Service Catalog allows you to create and manage portfolios of AWS services while enforcing company policies. This standardization streamlines deployments, though it does not independently adjust reliability beyond that provided by the underlying services.
Similarly, AWS License Manager centralizes software license compliance, ensuring that license management is as reliable as its design intends to be.

Proton
AWS Proton is designed for container and microservices deployments, incorporating built-in reliability measures like automatic multi-AZ deployments and data backup/restore functionalities. Although Proton offers a few extra reliability "knobs" for specific configurations (such as scheduled backups), its overall design prioritizes high resiliency out-of-the-box.

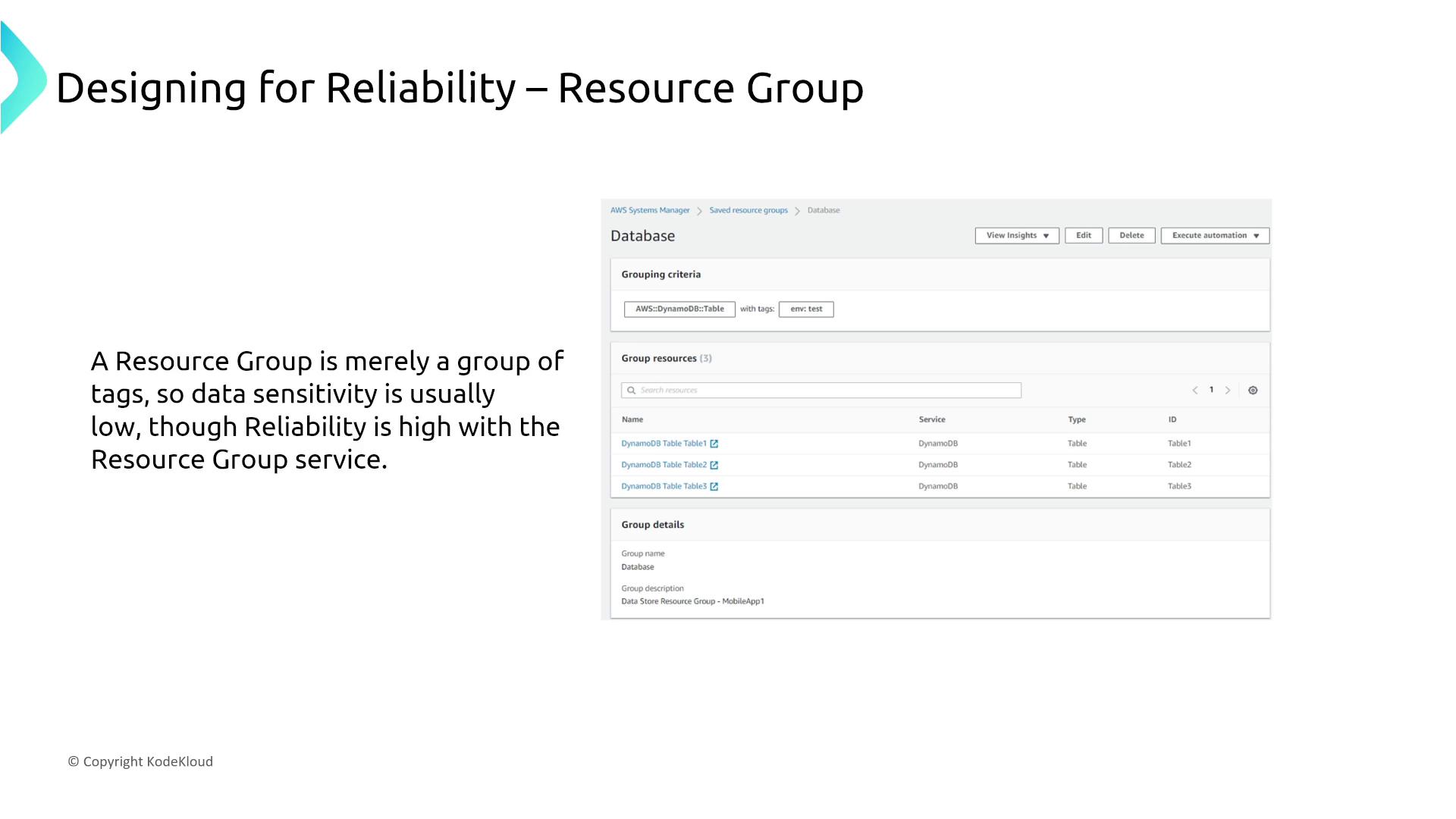
Tag Editor, Resource Explorer, Resource Groups, and Resource Access Manager
AWS provides several tools to organize and manage your resources effectively:
- Tag Editor: Enables efficient tagging across services.
- Resource Explorer and Resource Groups: Help in grouping and identifying related resources.
- Resource Access Manager: Facilitates secure resource sharing.
Each tool is designed to operate reliably by default, without configurable reliability options.

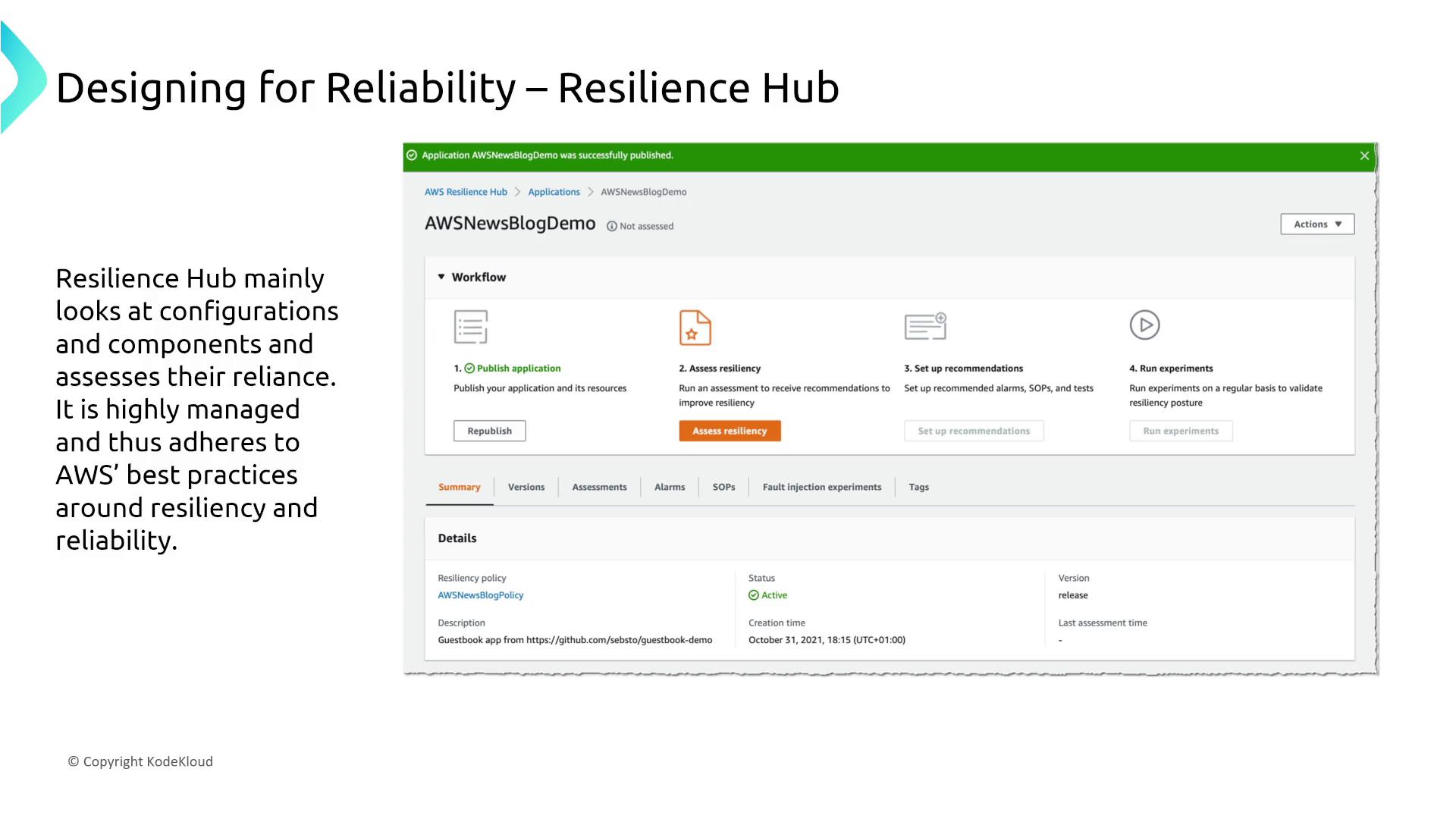
Resilience Hub
AWS Resilience Hub assists in assessing and improving the resiliency of your applications by analyzing configurations and suggesting best practices. Although the process involves manual inputs for analysis, the tool does not offer direct modifications to enhance service reliability.
Key Takeaway
Most AWS management and governance services are engineered to be inherently reliable. They come with built-in resilience, auto-healing, and seamless integration with observability tools—thus eliminating the need for manual adjustments.
Conclusion
In summary, AWS management and governance services are built on robust, resilient foundations. Whether provisioning through CloudFormation/CDK, monitoring with CloudWatch, or leveraging tools like Trusted Advisor, Control Tower, and Systems Manager, these services are designed to function reliably without additional configuration. Embrace AWS best practices and utilize these tools as intended to ensure optimal performance and resiliency in your environment.
Michael Forrester thanks you for following along in this lesson. If you have any questions, please join the forums or reach out directly at [email protected]. Catch you in the next lesson.
Watch Video
Watch video content
Practice Lab
Practice lab