Overview
Managed Service for Apache Kafka (MSK) simplifies running Kafka on AWS. Built on the popular open-source streaming data platform Apache Kafka (originally developed by LinkedIn), MSK streamlines deployment, scaling, and integration in a cloud-based environment. Whether you choose a server-based or serverless option, MSK allows you to build robust applications that ingest, process, and interact with high-volume real-time data.MSK is ideal for real-time behavioral analytics, clickstream data, website interactions, event sourcing, log aggregation, IoT data, and e-commerce transactions.
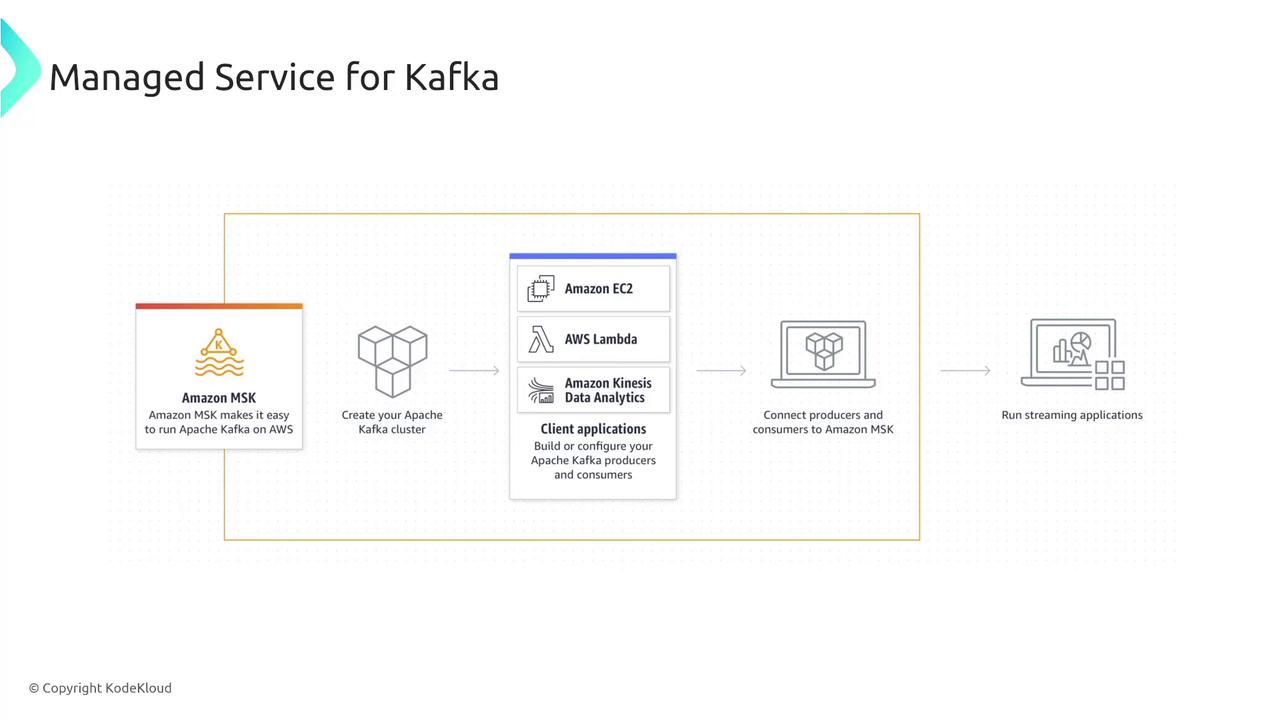
How It Works
Imagine MSK as your personal data radio station—broadcasting real-time data by creating topics, sending data streams to these topics, and allowing consumers to process the data downstream. MSK essentially serves as a “programming guide” for orchestrating data streams, enabling applications to handle massive volumes of real-time data with ease.
Architecture Insight
The managed service architecture for Kafka leverages AWS-managed brokers, ensuring that the underlying infrastructure remains largely invisible to end users. This architecture comprises Kafka brokers, ZooKeeper nodes that route requests, and multiple subnets across different availability zones. For users opting for a serverless configuration, simply setting your capacity is enough—producers and consumers directly interact with the managed brokers.
When configuring MSK in non-serverless mode, ensure you specify the appropriate broker sizes and configurations to meet your workload requirements.
Key Features of MSK
MSK is designed to handle data ingestion at scale, delivering high performance and reliability. Here are some of its standout features:- Automated Cluster Management: Reduces manual overhead by automating routine cluster tasks.
- Scalability and Performance: Provides excellent scalability to manage high volumes of data.
- Security and Compliance: Ensures network isolation, encryption at rest and in transit, integration with AWS IAM, and compliance with GDPR, HIPAA, and other standards.
- Reliability and High Availability: Offers automated backups, multi-zone replication, and automatic recovery.
- Monitoring and Alerts: Seamlessly integrates with AWS monitoring and alerting services like CloudTrail and CloudWatch.