This article explores AWS OpenSearch, its components, use cases, and how it compares to traditional databases for managing diverse data types.
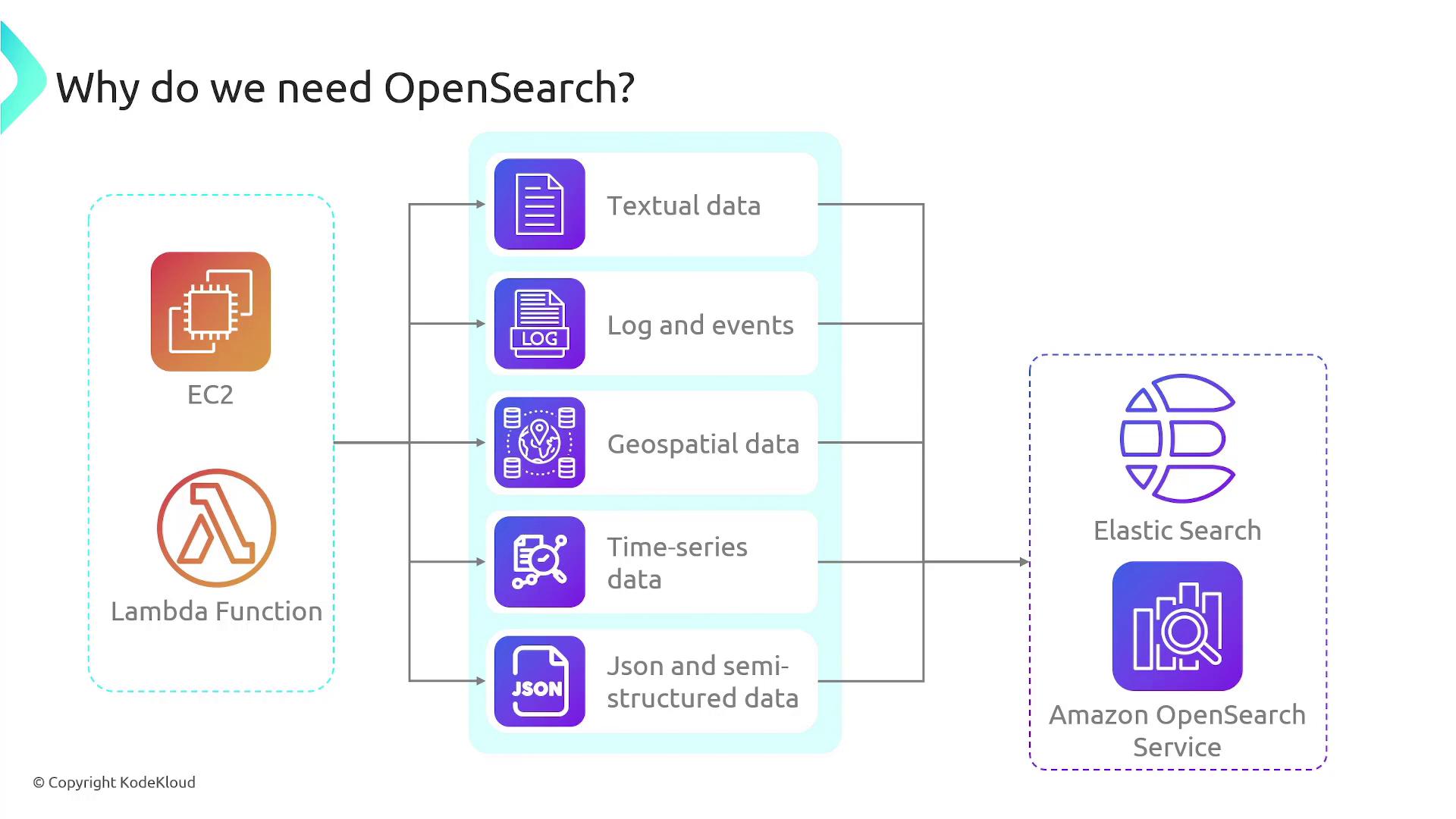
In this lesson, we explore AWS OpenSearch, a powerful search and analytics suite designed to handle a wide range of data types. You’ll learn about its purpose, key components, and common use cases, as well as how it compares to traditional relational databases.Modern applications often generate diverse data—including textual content, login events, geospatial information, time series data, JSON, and other semi-structured formats. While traditional relational databases excel at handling structured data with predefined schemas, they may struggle with the flexibility and scalability required for these varied data types. OpenSearch, built on the robust capabilities of Elasticsearch, efficiently manages this data in real time, making it an ideal solution for search engines, log management, and analytics.
Before diving deeper, it is important to understand the relationship between Elasticsearch and OpenSearch. Originally, both Elasticsearch and Kibana were free and open source. However, when the managing company transitioned Elasticsearch to a proprietary license, Amazon forked the latest available open source version to maintain a truly open environment. While Elasticsearch now operates under a proprietary model, OpenSearch continues to be offered as a free and open source alternative under proper licensing.
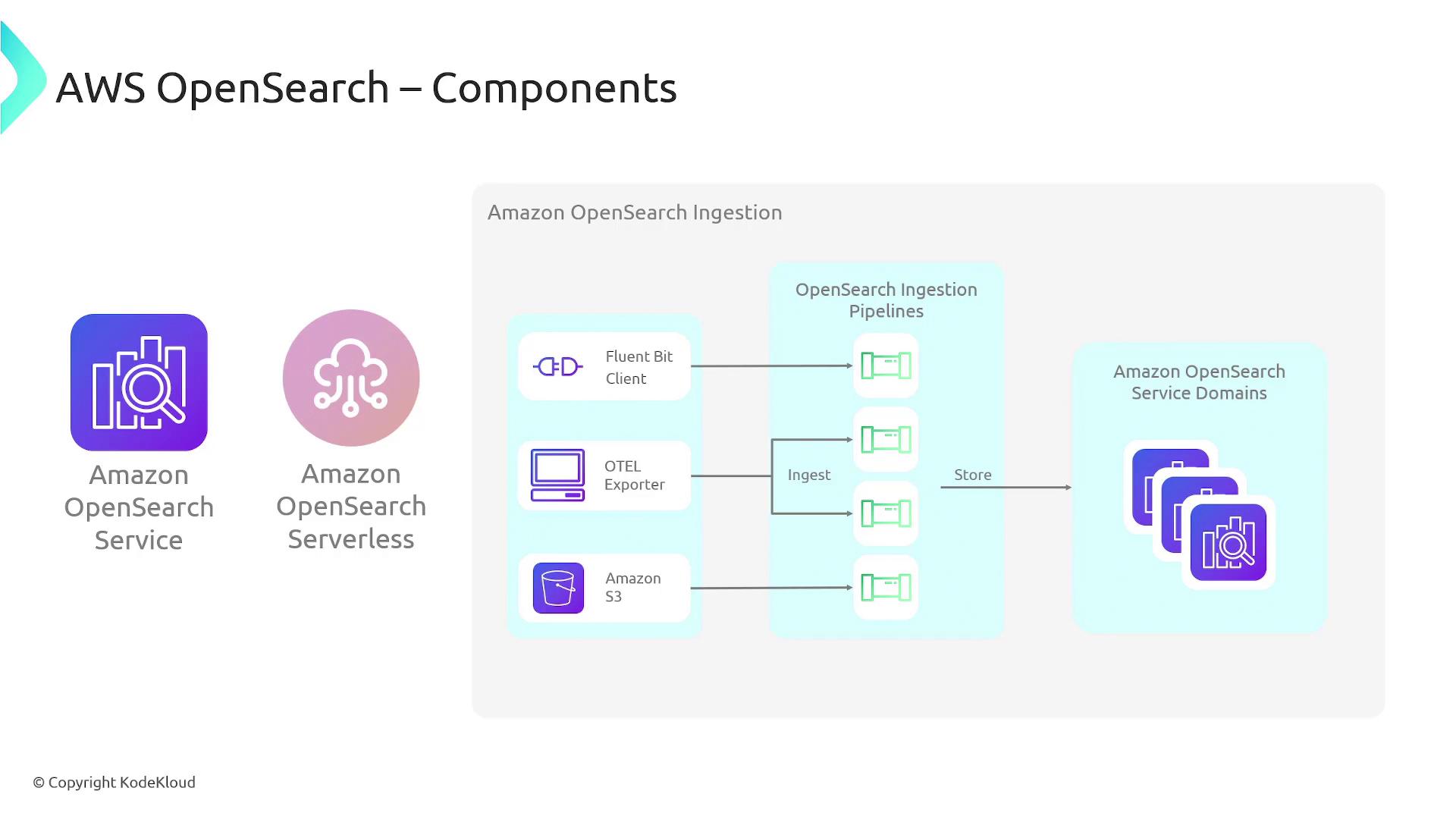
OpenSearch can be deployed as a managed cluster on Amazon or used via a serverless configuration. OpenSearch Serverless is an on-demand, auto-scaling offering that removes the operational burden of provisioning, configuring, and tuning an OpenSearch cluster—Amazon manages these tasks for you.Additionally, OpenSearch Ingestion serves as a fully managed, serverless data collector that delivers real-time logs, metrics, and trace data to both OpenSearch Service domains and OpenSearch Serverless collections. For each OpenSearch cluster, this service creates a dedicated domain to simplify data delivery and management.
With OpenSearch Ingestion, there is no longer a need for third-party tools like Logstash or Jaeger. You can configure your data producers to send information directly into OpenSearch Ingestion, which can also handle data transformation and cleaning before the data is delivered to your clusters.One notable feature of OpenSearch is its ability to aggregate logs, traces, and metrics into a unified view, enabling comprehensive application analytics. Its machine learning integration further supports anomaly detection and alerting. OpenSearch also allows replicating indexes, mappings, and metadata between clusters, ensuring cross-cluster redundancy or offloading reporting queries. The service offers a variety of CPU, memory, and storage configurations—supporting up to three petabytes of attached storage. Moreover, OpenSearch provides a familiar SQL query syntax, enabling users to perform aggregations with WHERE clauses and to read data as JSON documents or CSV tables. For those with a background in SQL, this makes transitioning to OpenSearch straightforward. The platform also supports trace analytics, allowing the ingestion and visualization of open telemetry data.
For users transitioning from Elasticsearch, OpenSearch provides a familiar environment with additional serverless and ingestion features, allowing for streamlined operations and enhanced scalability.
OpenSearch service domains automatically send operational metrics to CloudWatch, which helps monitor domain health and performance. AWS CloudShell maintains a history of OpenSearch configuration API calls and related events for auditing purposes. Other integrations include:
Amazon Kinesis: Load and stream data into OpenSearch.
Amazon S3: Use S3 for index storage.
IAM: Securely manage cluster access.
Lambda: Preprocess data before ingestion.
DynamoDB: Automatically transfer table data to an OpenSearch cluster.
Amazon QuickSight: Create interactive dashboards for visualizing OpenSearch data.
OpenSearch is a community-driven search and analytics suite that originated as a fork of Elasticsearch to preserve its open source nature. With both traditional and serverless deployment options, OpenSearch simplifies the management and scaling of search clusters while integrating diverse data sources for comprehensive analytics.
For more detailed information and best practices, consider visiting the following links:
Ensure that you understand the licensing differences between OpenSearch and Elasticsearch to avoid unexpected limitations or costs when deploying in production environments.