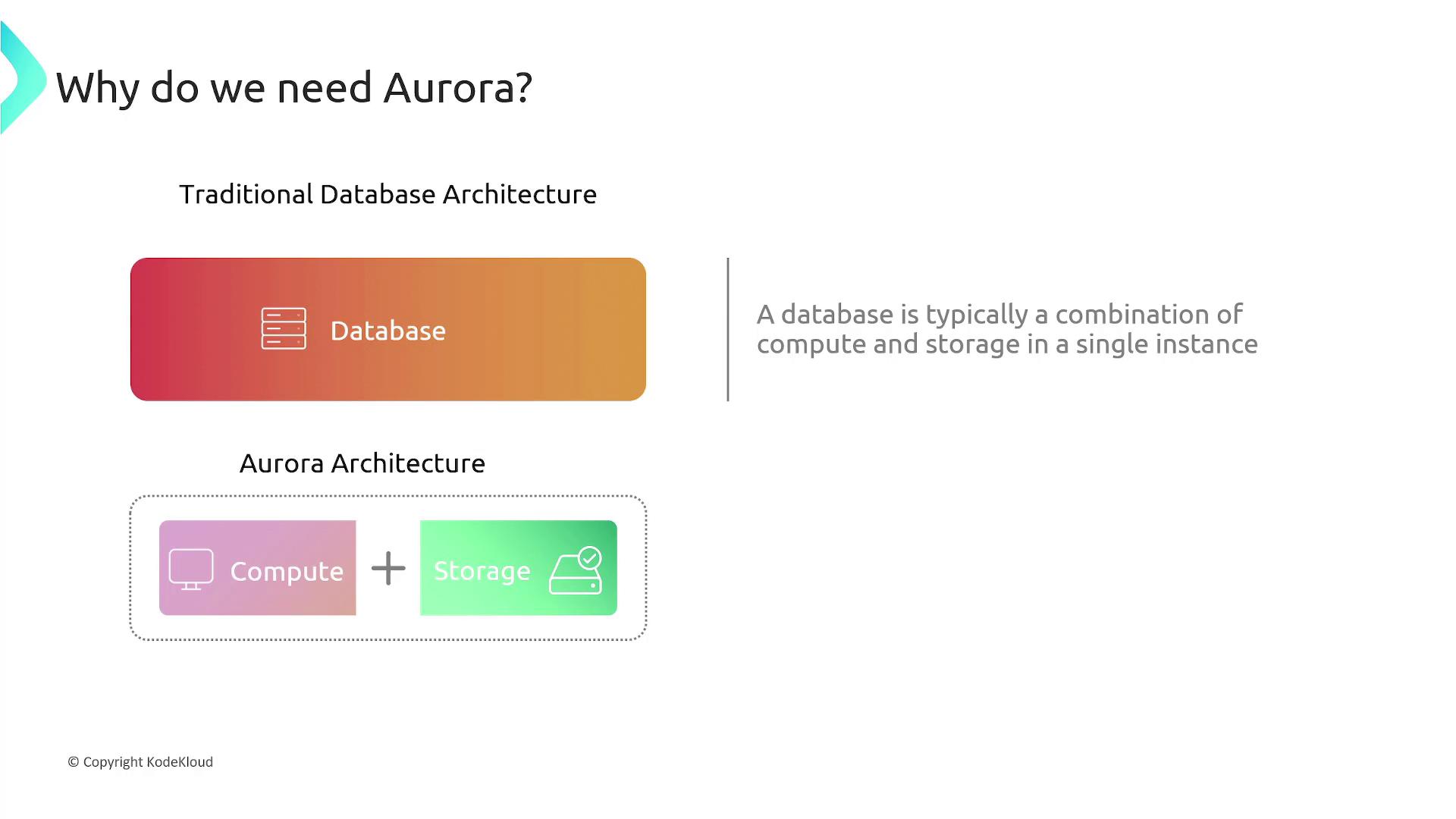
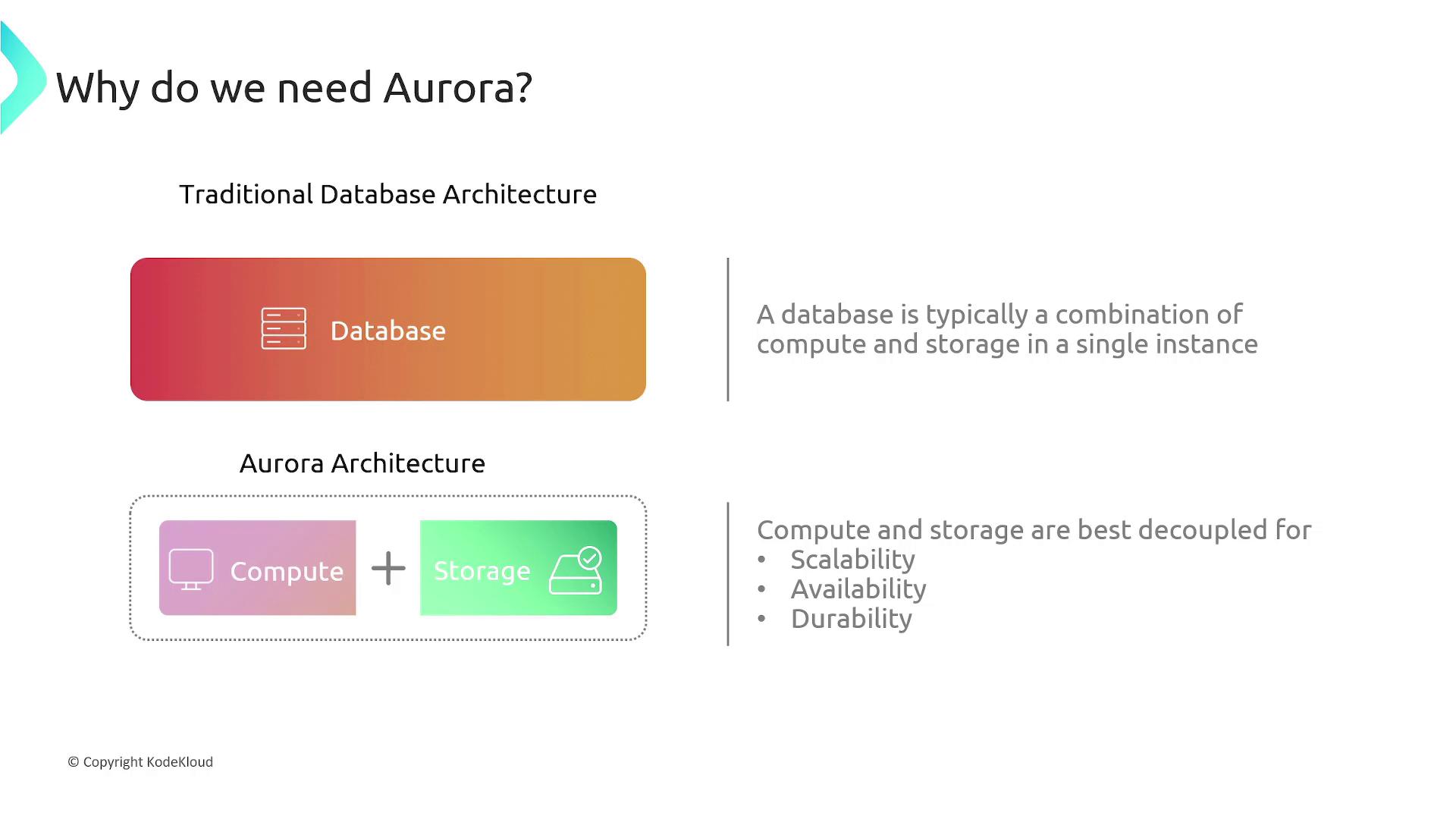
The Challenge with Traditional Database Architectures
Traditional databases typically combine compute and storage within a single instance, which introduces several challenges:- Longer snapshot durations since the entire dataset must be copied.
- Difficulty scaling storage independently of compute resources, potentially leading to downtime or complex migrations.
- Extended backup and restore times, especially when dealing with large storage volumes.
- The necessity to overprovision storage for peak capacity, resulting in unnecessary expenses.
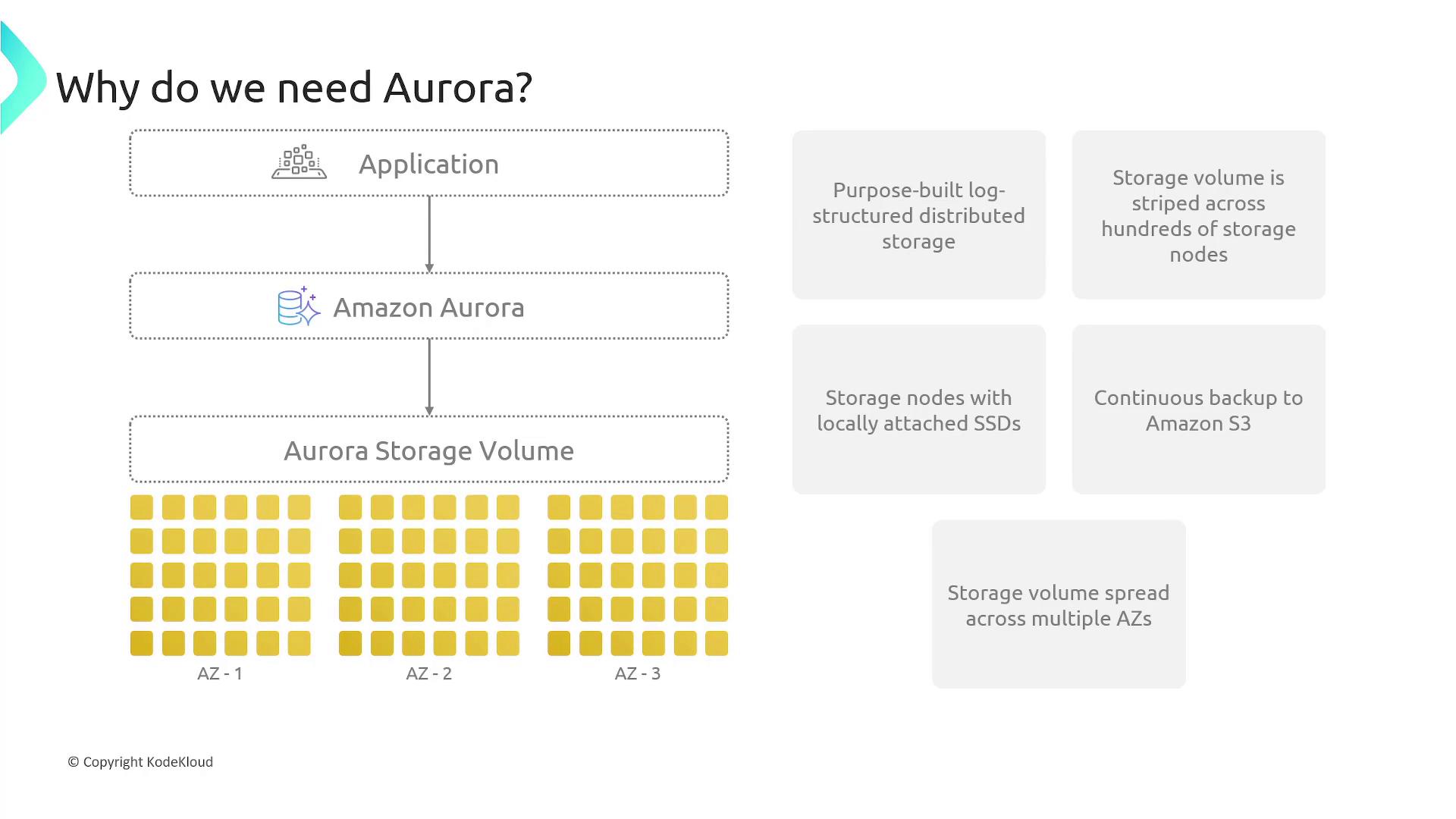
Aurora Storage Architecture
Aurora overcomes these challenges with a unique, log-structured distributed storage system designed for modern cloud environments. Key characteristics include:- The storage volume is striped across hundreds of nodes with locally attached SSDs, ensuring high performance and durability.
- Continuous backup capability to Amazon S3 for seamless data protection and recovery.
- Data distribution across multiple Availability Zones (AZs), providing built-in high availability and resilience to data center failures.
- Automatic scaling of storage capacity, eliminating the need for manual intervention or downtime.
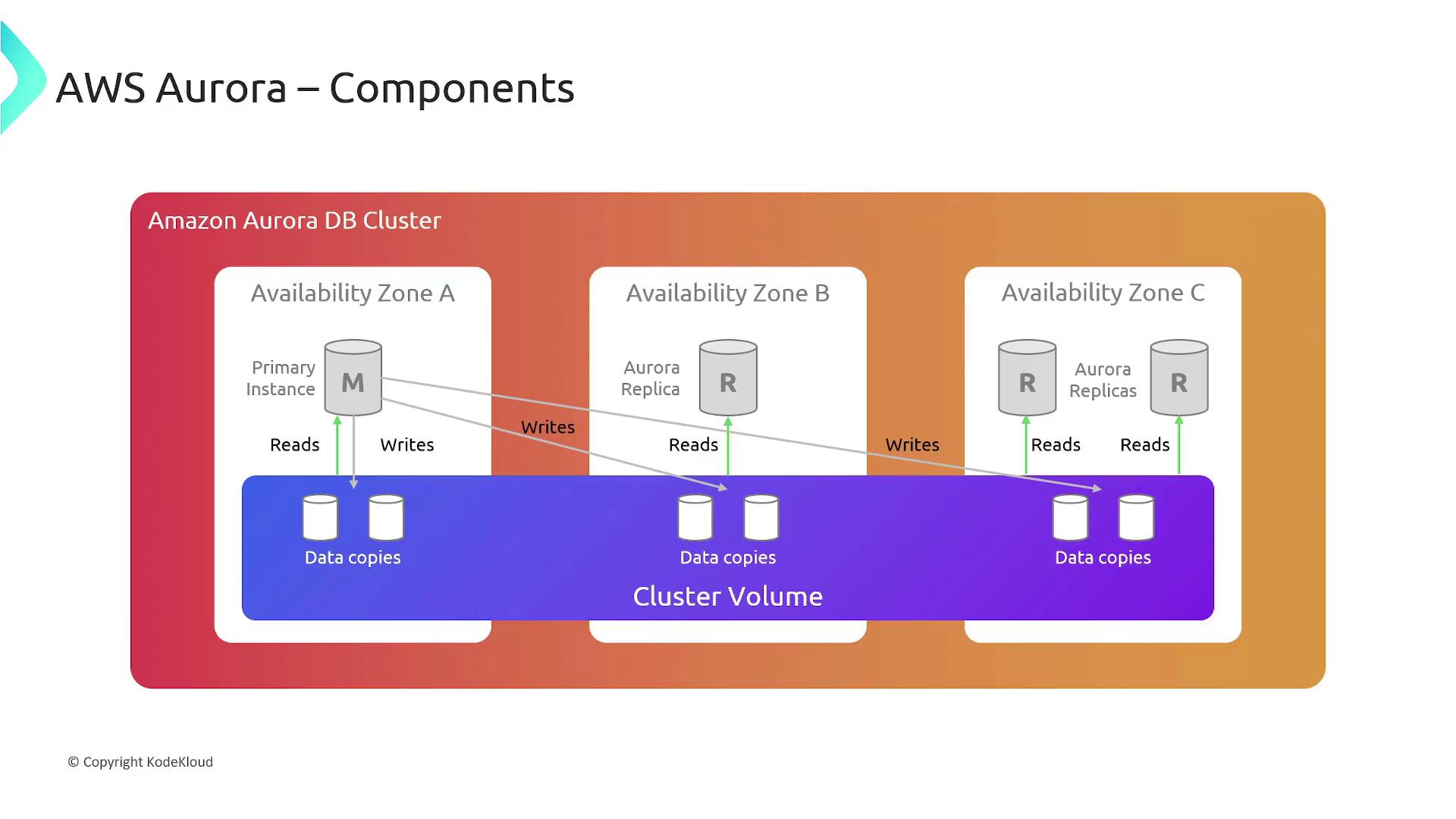
Components of an Aurora Database Cluster
An Aurora database cluster is comprised of several key components:-
Database Instances:
- Primary Instance:
Supports both read and write operations while updating the cluster volume. Each Aurora cluster has exactly one primary instance. - Replicas:
Support read-only operations and share the same storage volume as the primary. Up to 15 replicas can be deployed across different AZs, providing enhanced availability. If the primary fails, one of these replicas can be promoted to become the new primary.
- Primary Instance:
-
Cluster Volume:
Acts as a virtualized storage layer that spans multiple AZs, with each zone maintaining a copy of the entire database cluster’s data.
Deployment Options: Provisioned vs. Serverless
When deploying an Aurora database cluster, you have two configuration options:Provisioned
- Allocate a database instance with pre-configured CPU, memory, storage, and IOPS.
- Scale resources manually as needed.
- Benefit from Aurora Global Databases, which provide low latency global reads and regional failover capabilities.
Serverless
- Ideal for workloads with unpredictable capacity requirements.
- Automatically scales capacity on demand based on application load.
- Payment is based solely on the actual resources consumed.
- Aurora Serverless v2 offers enhanced scalability and integration with Aurora Global features.

Consider serverless for applications with variable load and provisioned for stable, predictable workloads.
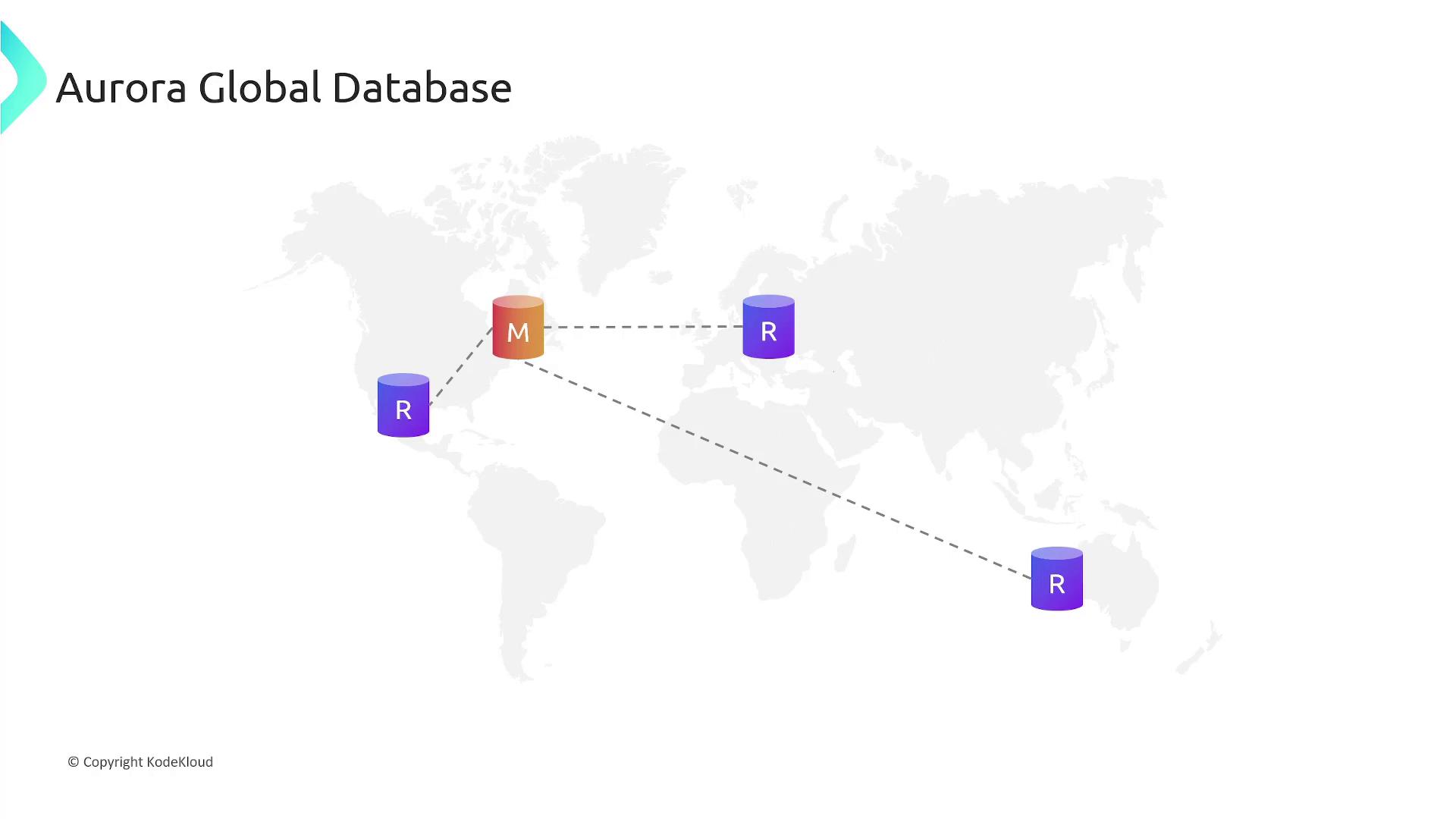
Aurora Global Database
Aurora Global Database clusters enable deployment of a consistent database system across multiple AWS regions:- A primary database cluster in one region accepts write operations.
- Up to five secondary clusters in different regions serve as read-only replicas.
- Data is asynchronously replicated from the primary to each secondary cluster via a low latency, high throughput system.


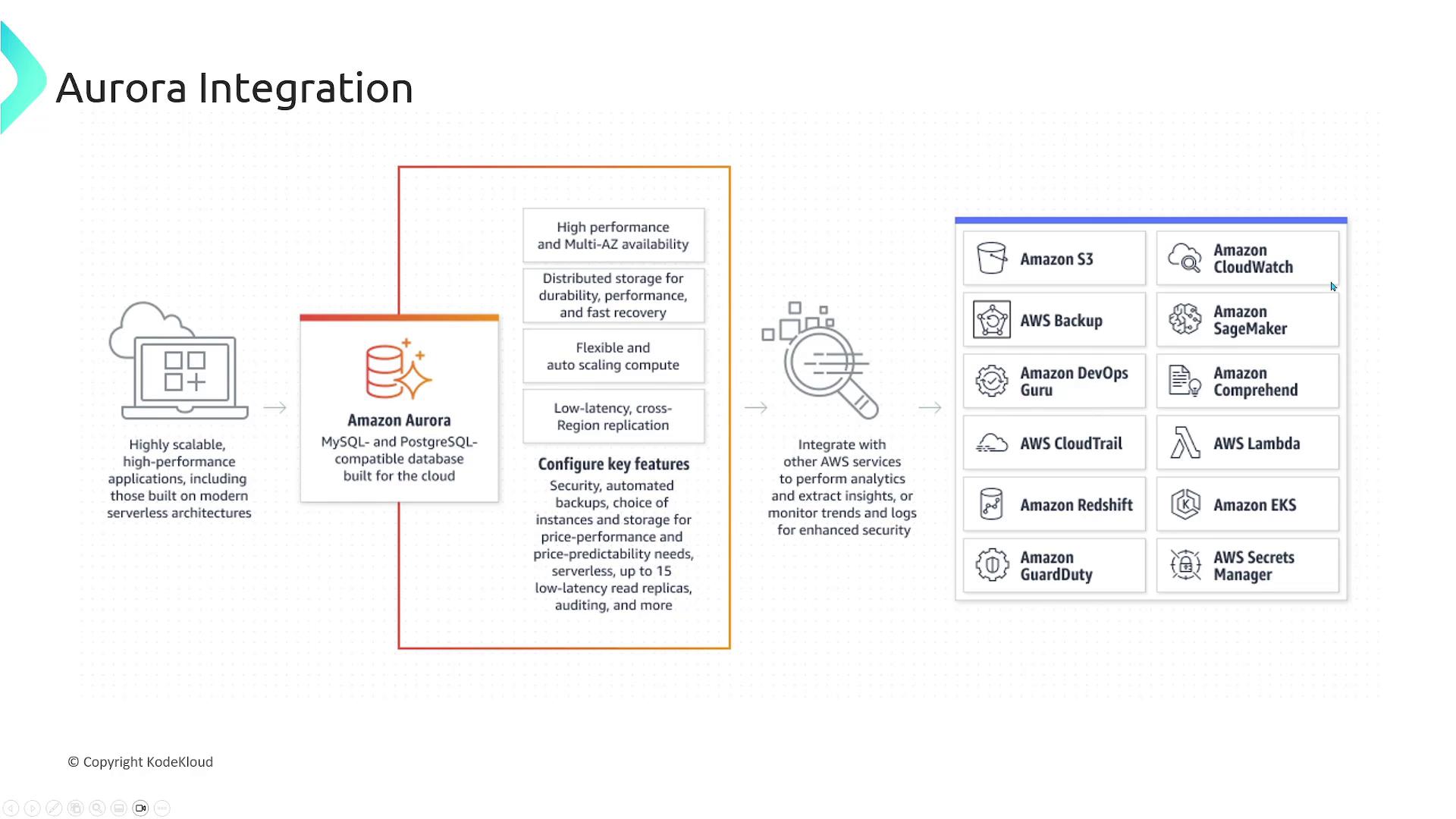
Integrations with Other AWS Services
Aurora integrates seamlessly with various AWS services to enhance its functionality:- Amazon S3: Used for scheduled backups and data recovery.
- CloudWatch: Provides robust monitoring of performance metrics.
- AWS Lambda, EKS, ECS, etc.: Facilitates connectivity between your applications and the database.
- Secrets Manager: Securely stores database credentials.
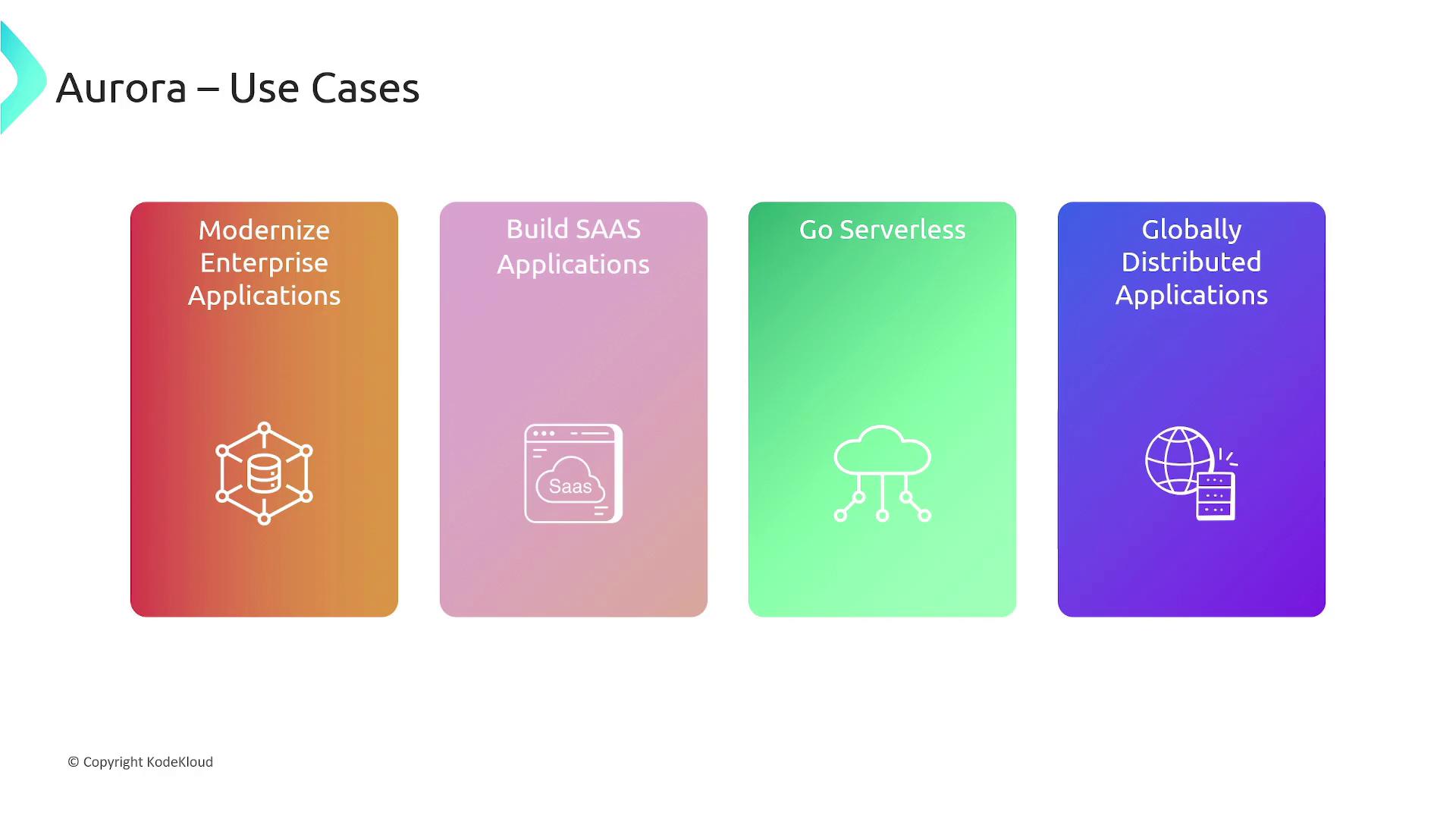
- Modernizing enterprise applications (CRMs, ERPs, and supply chain or billing systems).
- Building SaaS applications that require flexible compute and storage scaling.
- Implementing efficient serverless architectures where you pay only for actual usage.
- Developing globally distributed applications, including mobile games and social media platforms.
Summary
Aurora is a fully managed relational database service that automates hardware provisioning, database setup, patching, and backups. Its advanced, fault-tolerant, and self-healing storage system can scale up to 128 terabytes per instance, ensuring both high performance and reliability. Key features include:- Up to five times the throughput of MySQL and three times that of PostgreSQL.
- Support for up to 15 replicas across three Availability Zones, enhancing read scalability and availability.
- Fast cloning capabilities for rapid database replication in development and testing environments.
- Seamless integration with multi-AZ and global deployments for improved local read-write performance and disaster recovery.
- Aurora Serverless, which automatically adjusts capacity based on demand, offering significant cost savings.

Explore additional details on AWS Aurora Documentation to further enhance your understanding and deployment strategies.