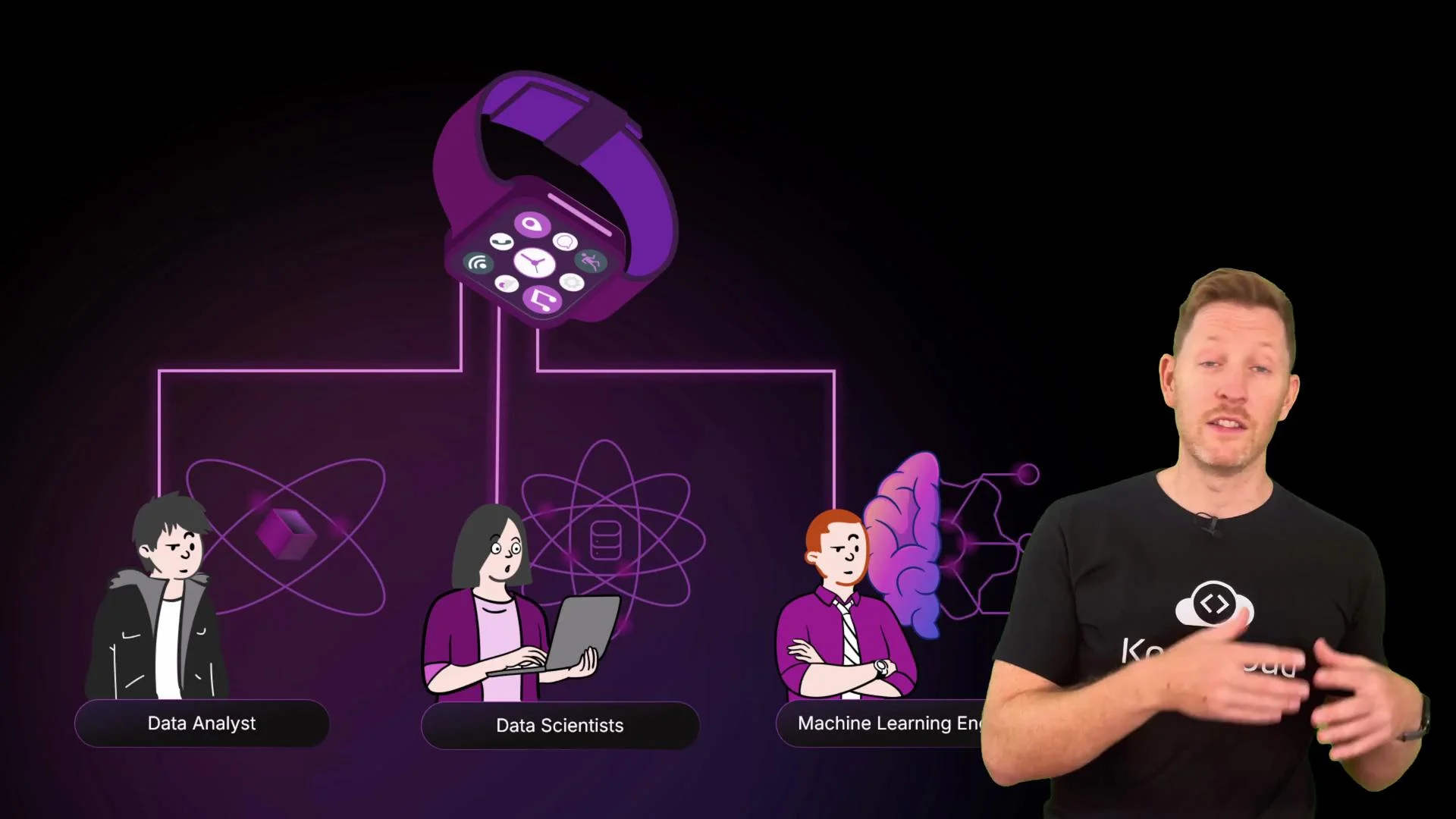
- Differentiate data engineering from related roles (data scientist, analyst, ML engineer).
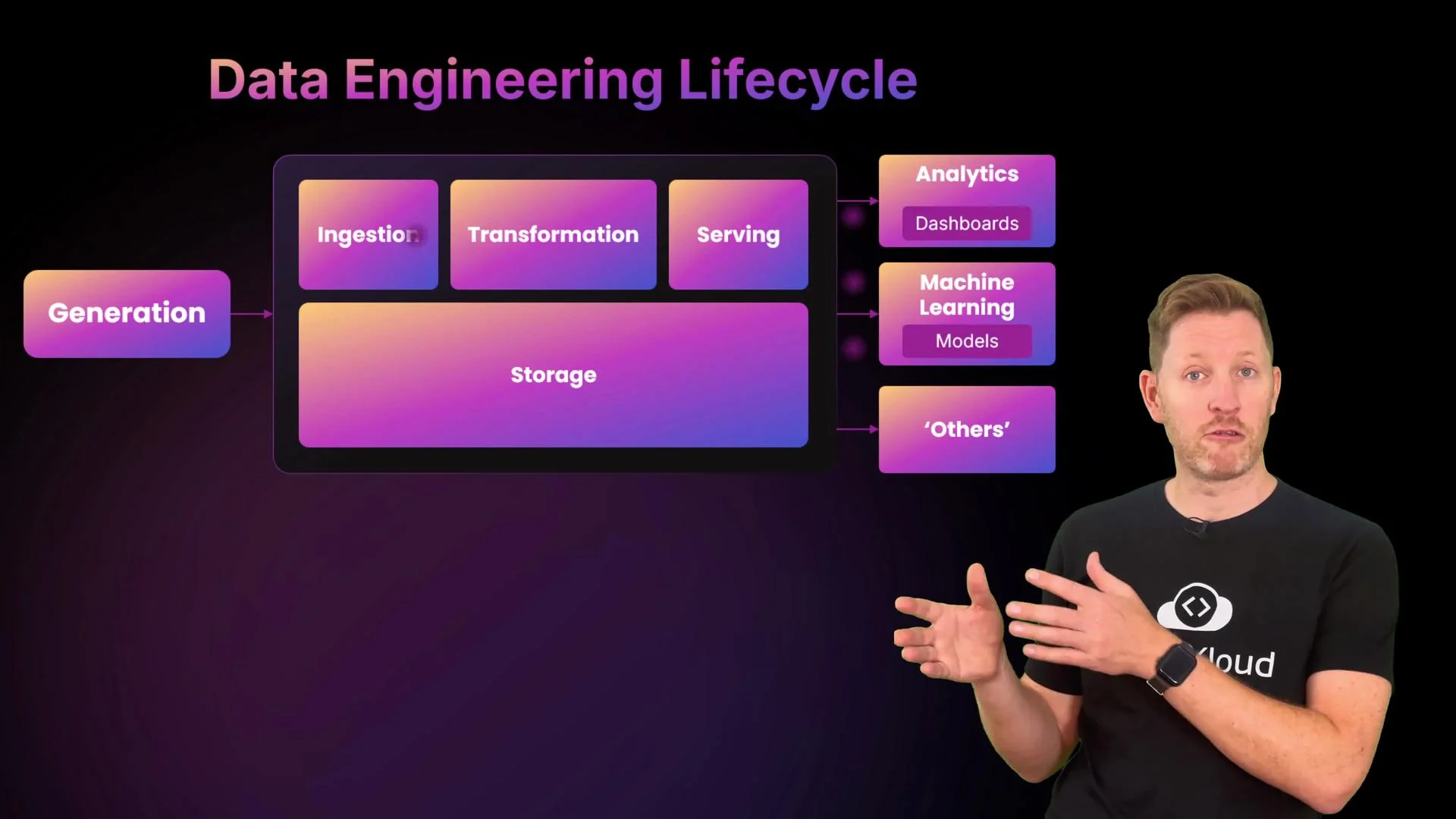
- Describe the core stages of the data engineering lifecycle.
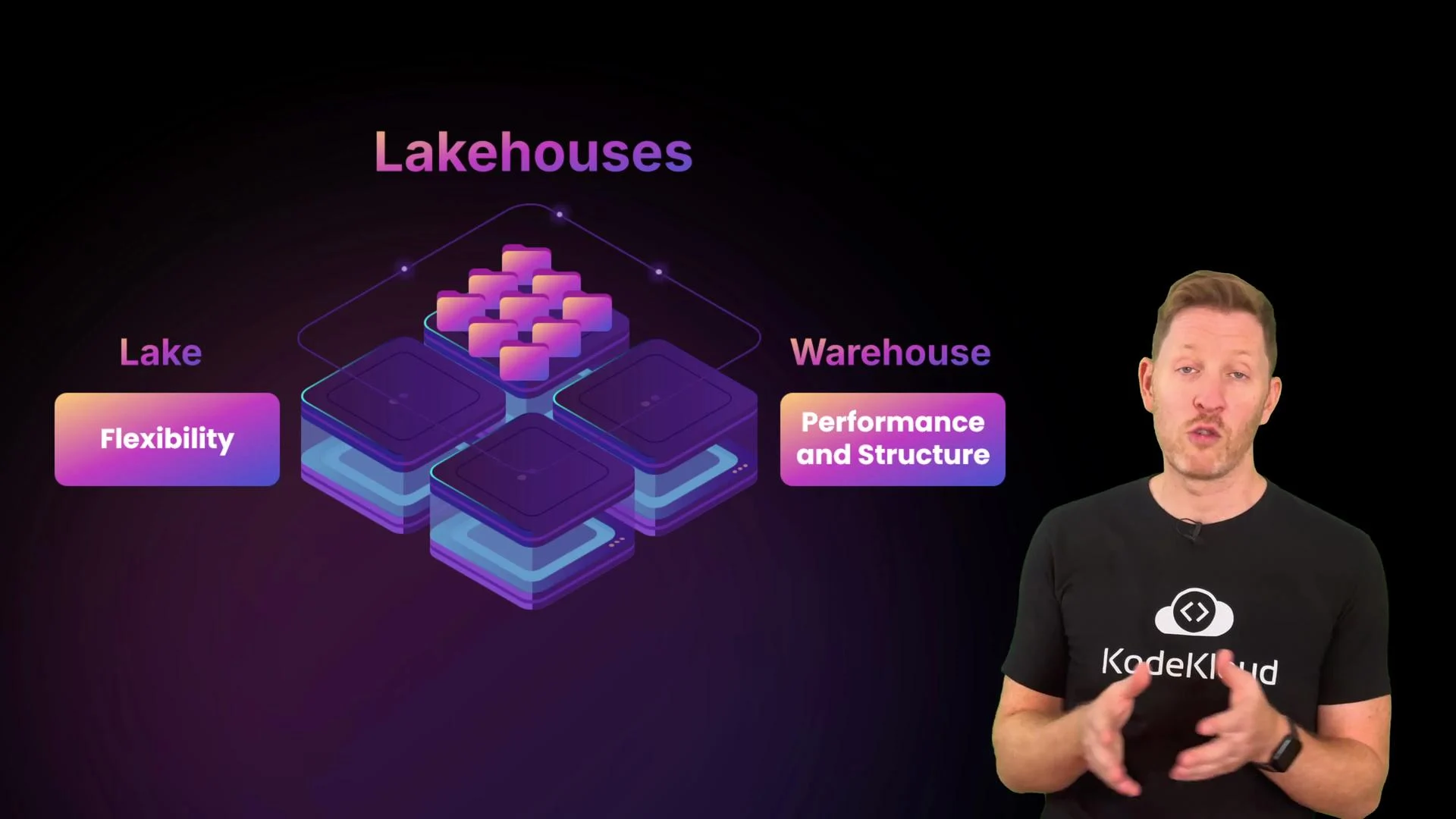
- Compare common storage patterns and identify key security and compliance considerations.

- Upstream: systems and teams that generate raw data — mobile apps, IoT devices, logs, and operational databases. These are typically owned by software engineers, DevOps teams, or product teams.
- Downstream: consumers of processed data — analysts, data scientists, ML engineers, and BI teams that derive insights, build models, or power apps.

- This stage is where events and records originate: mobile apps, IoT sensors, web traffic, and transactional databases create raw, noisy data that must be captured and cataloged.

- Ingestion covers collecting raw data from sources. Common patterns include batch file syncs, CDC (change data capture) from databases, streaming telemetry (e.g., Kafka), and webhooks or API pulls.
- After ingestion the raw data must be stored reliably. Storage decisions affect cost, performance, governance, and who can access data. Data can land in cloud object stores, data lakes, warehouses, or hybrid lakehouse systems. Connectors and ETL/ELT processes move data into these storage targets.


- Encrypt data in transit and at rest.
- Apply the principle of least privilege for access controls.
- Enable audit logging and retention policies.
- Choose cloud regions and data handling strategies to meet regulations such as GDPR or local privacy laws.
- Manage secrets (API keys, DB credentials) with a secrets manager or environment variables rather than hard-coding them.
Never store secrets in plain text or in repository history. Use a secrets manager (e.g., AWS Secrets Manager, HashiCorp Vault) and restrict access with fine-grained IAM policies.

- Transformation is where raw data is cleaned, joined, and enriched: removing duplicates, normalizing timestamps, computing derived metrics, and applying business logic.
- Serve is delivering curated datasets to dashboards, APIs, or ML training pipelines — the final step that makes data actionable.
- ETL (Extract, Transform, Load): Transformations happen before loading into the target. Useful when upstream transforms are required or target platform cannot scale transformations.
- ELT (Extract, Load, Transform): Raw data is loaded first; transformations occur later inside the target platform (often leveraging scalable compute).
ETL vs ELT: prefer ETL when targets cannot handle heavy transformations or when you must enforce transformation before sharing. Prefer ELT when you need to retain raw data for reproducibility and want to leverage the target platform’s scalability.

- Use version control (Git) for pipeline code, SQL, and infrastructure-as-code.
- Implement automated tests, CI/CD, and code reviews.
- Orchestrate workflows with scheduling tools (Airflow, Prefect, Dagster) and monitor pipelines with observability tools and alerting.

B. Storage happens after data has been transformed and just before it’s been served.
C. A data lake only accepts cleaned, structured data with a fixed schema.
D. Data engineers use the principle of least privilege to control access to sensitive data.

- A is true: data engineers build systems that ingest, clean, and deliver data from upstream sources.
- D is true: the principle of least privilege is a foundational security practice.
- B is false because storage can exist before, during, or after transformation — stages often overlap and run in parallel.
- C is false because that describes a data warehouse. A data lake accepts raw, unstructured data and typically applies schema-on-read.
- Data engineers design and maintain pipelines that move, clean, and serve data to downstream users and systems. They focus on reliability, observability, and data quality rather than only analysis or modeling.
- The data engineering lifecycle is: generate → ingest → store → transform → serve. These stages may repeat or run concurrently depending on use cases.
- Storage patterns (lake, warehouse, lakehouse) trade off flexibility, governance, and query performance; choose based on workload and organizational needs.
- Security and compliance — encryption, audit logs, least privilege, and secret management — are mandatory across the lifecycle.
- AWS S3 Documentation
- Snowflake Documentation
- Google BigQuery Documentation
- General Data Protection Regulation (GDPR) overview