Generative Pre-trained Transformer (GPT)
At its core, GPT predicts the next token (word or subword) in a sequence based on prior context. Pre-trained on massive corpora, it learns grammar, facts, and reasoning patterns. Using prompts, you can steer GPT to generate code, equations, creative writing, or structured data.
Tokenization and Token Counts
GPT breaks text into tokens—units that include words, subwords, spaces, or punctuation. Token count influences both the model’s context window and your billing.
Each additional token adds to compute time and cost. Keep prompts concise to optimize performance and expenses.
Model Selection
Selecting the right GPT variant balances cost, speed, and capability:| Model Type | Use Case | Advantages | Considerations |
|---|---|---|---|
| GPT-4 (Large) | Complex reasoning & analysis | Highest accuracy | Higher per-token cost |
| GPT-4 mini (Small) | Quick prototyping & low latency | Faster, lower cost | Limited output quality |
| Reasoning Model | Multi-step planning & coding | Advanced reasoning | Slower, more tokens |

Key Components of Text Generation
- Tokenization
Divide input and output into discrete tokens. - Contextual Learning
Use all prior tokens to inform the next prediction. - Sampling
Apply methods like greedy or temperature sampling for creativity.

How GPT Generates Text
The autoregressive pipeline consists of:- Input Prompt: Your instruction or question.
- Text Completion: Model predicts the next token.
- Autoregressive Loop: Each new token feeds back until a stop condition or max tokens is reached.

Example: Generating a Haiku
Setup: Python, VS Code, and OpenAI
Install the Python package and set your API key securely:
Never hard-code your
openai.api_key in public repositories. Use environment variables or a secret manager.Core Parameters
| Parameter | Description |
|---|---|
| model | GPT version (e.g., "gpt-4") |
| messages | List of chat messages or prompt strings |
| max_tokens | Maximum number of tokens in the response |
| temperature | Sampling randomness (0.0 = deterministic, 1.0 = creative) |
| n | Number of completions to generate |
| stop | Optional sequences where generation halts |
| top_p | Cumulative probability threshold for nucleus sampling |

Example: Short Story Generator
Auto-regressive Generation and Sampling
GPT’s output is built one token at a time, each influenced by the full sequence so far.Sampling Methods
- Greedy Sampling: Picks the highest-probability token each step (deterministic).
- Temperature Sampling: Scales logits to adjust randomness (
0.0–1.0).

Advanced Techniques: Temperature, Top-P, and Fine-Tuning
Customize model creativity and focus via parameters or fine-tuning.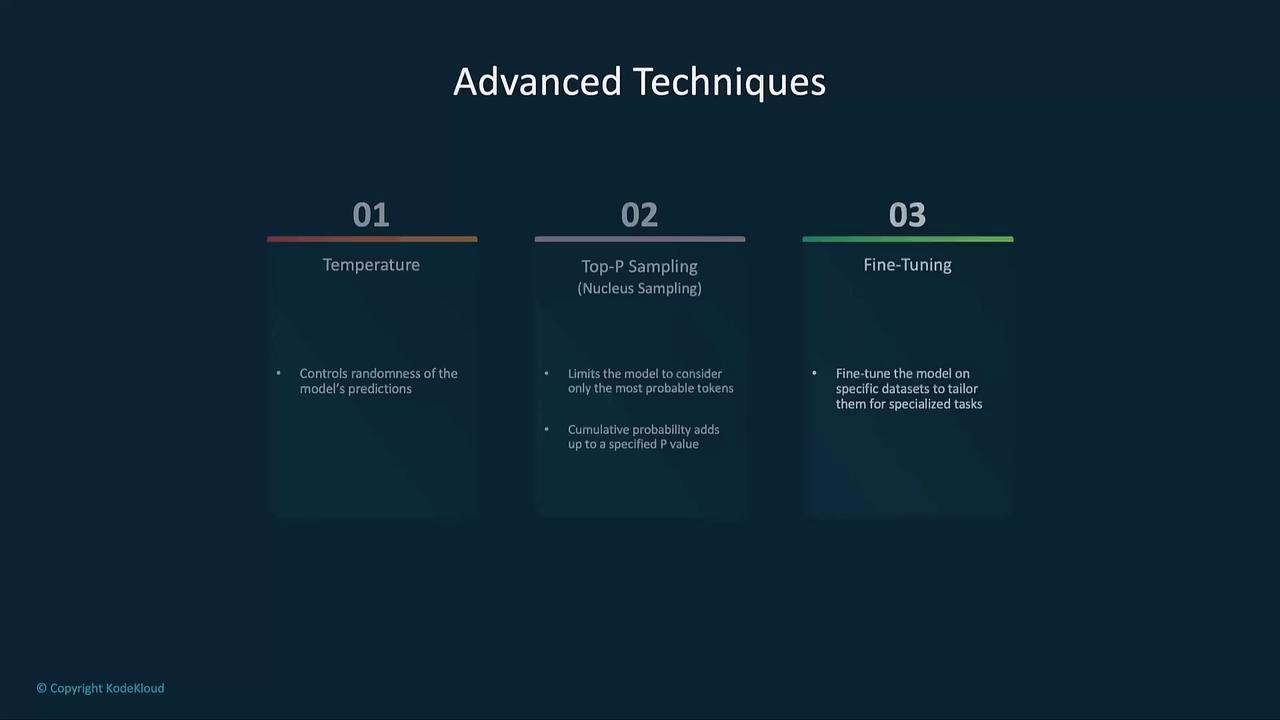
Temperature Effects

Top-P Sampling
Restricts choices to tokens whose cumulative probability ≤ p.
Fine-Tuning Custom Models
Fine-tuning adapts a GPT model to domain-specific tasks:- Prepare a JSONL dataset with input-output pairs.
- Upload via the OpenAI API.
- Initiate the fine-tuning job.
- Call your specialized model just like any other.

Tokenization Details
GPT uses byte-pair encoding (BPE) to efficiently split text into subword tokens.Transformer and Decoder Stack
After tokenization, text passes through:- Embedding Layer
- Positional Encoding
- Self-Attention Mechanism
- Feedforward & Decoder Blocks

Best Practices
- Prompt Engineering: Craft clear, specific instructions.
- Review Outputs: Check for bias, factual accuracy, and coherence.
- Iterate Parameters: Experiment with
temperature,max_tokens, andtop_p. - Responsible Usage: Always combine AI-generated content with human oversight, especially in sensitive domains.
Links and References
- OpenAI API Documentation: https://platform.openai.com/docs
- OpenAI Python SDK on PyPI: https://pypi.org/project/openai
- Nucleus Sampling (Top-P) Paper: https://arxiv.org/abs/1904.09751