What Is a Model?
A model can be thought of as a blueprint or recipe that makes predictions based on input data. A popular type of model is a neural network, inspired by the human brain’s structure and function.
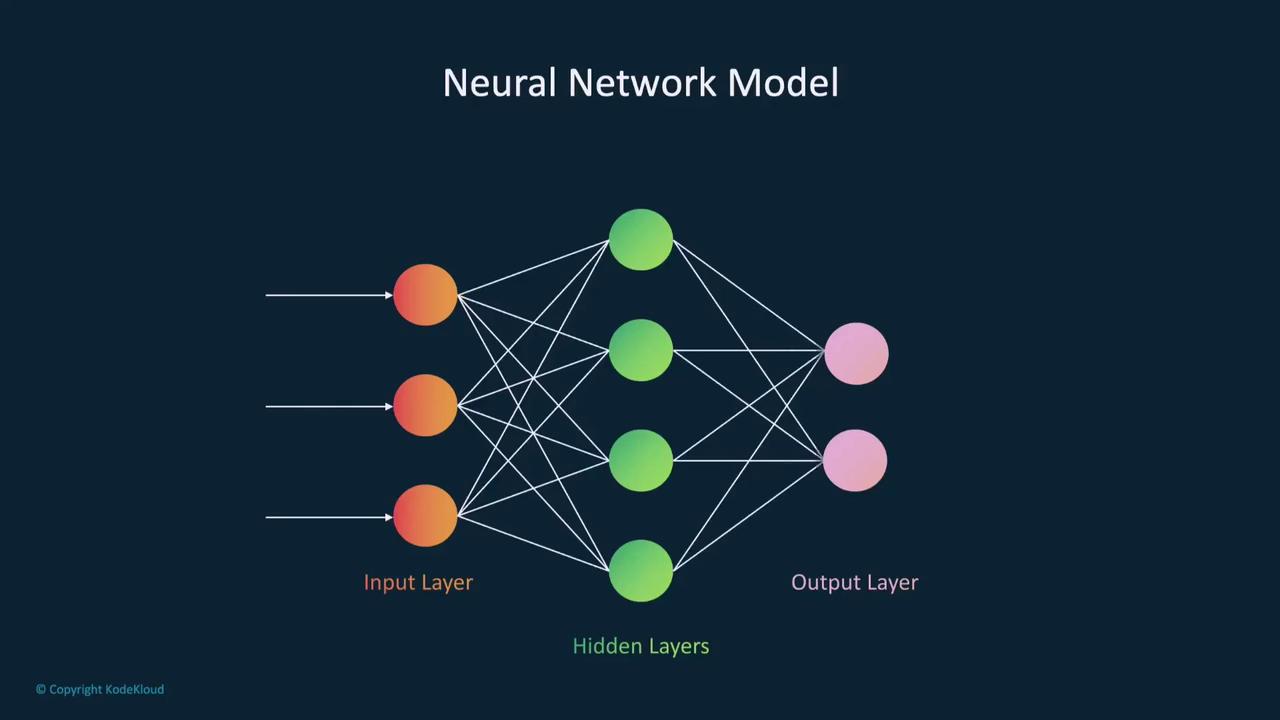
Defining a Neural Network Model in PyTorch
To build a neural network in PyTorch, you create a class that inherits fromtorch.nn.Module. This class serves as a blueprint that defines the layers and the flow of data through them.
Below is an example of a simple neural network class:
- The
__init__method sets up the input, hidden, and output layers, along with the ReLU activation function. - The
forwardmethod dictates how data flows through the network, from the input layer to the final output.
Understanding torch.nn.Module
Thetorch.nn.Module class offers a structured approach for defining layers and operations in your model. By inheriting from this module, you benefit from features such as automatic management of weights, gradients, and parameter updates. This design also simplifies saving, loading, and reusing your model.

__init__ function, by defining the layers, you ensure that they are primed to process data seamlessly.
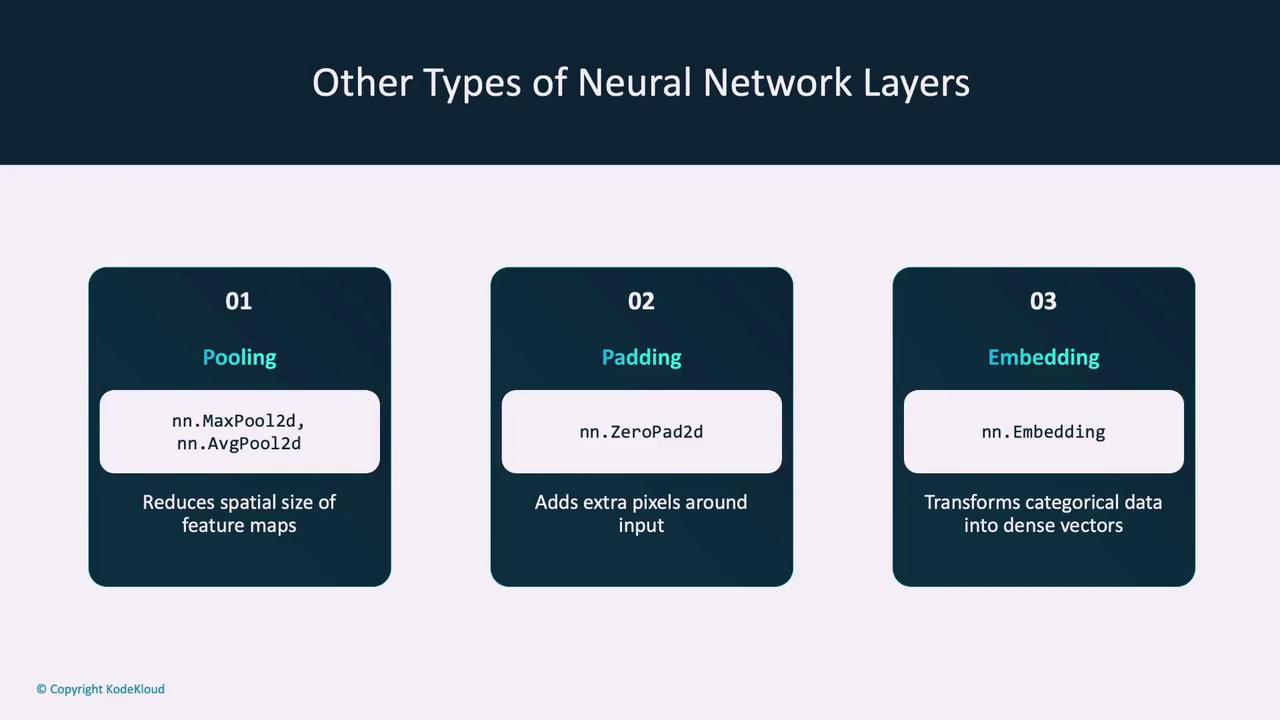
A Quick Overview of Neural Network Layers
When designing a neural network, you have various types of layers at your disposal. Here are some common layer types used in PyTorch:-
Fully Connected Layer (Dense Layer)
- Every neuron in one layer is connected to every neuron in the next.
- Implemented as
nn.Linear.
-
Convolutional Layer
- Ideal for image processing.
- Uses convolutional filters to extract features such as edges and textures.
- Implemented as
nn.Conv2d.
-
Recurrent Layer
- Suitable for sequential data like time-series or text.
- Examples include
nn.RNN,nn.LSTM, andnn.GRU.
-
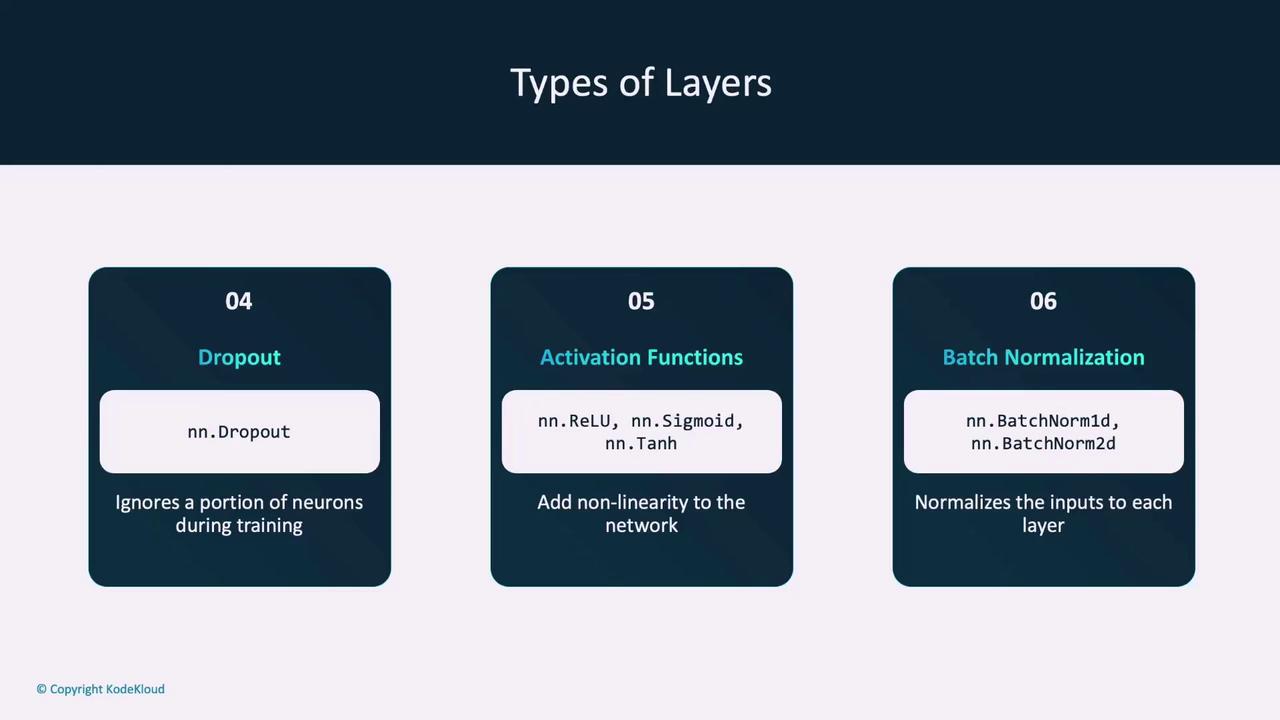
Dropout Layer
- Randomly ignores a portion of neurons during training, helping to prevent overfitting.
-
Activation Functions
- Introduce non-linearity into the network (e.g., ReLU for hidden layers, sigmoid or softmax for output layers).
-
Batch Normalization
- Normalizes the outputs of each layer to improve training stability and speed.

The Forward Function
In a PyTorch model, theforward function defines the sequence of operations and transformations that generate a prediction from input data. Essentially, it processes data through each layer and produces an output.
Consider the simplified example below that demonstrates the forward pass:
Designing Your Network
When designing your neural network, consider the following factors:- Output Size: Analyze the dimensions of your input data and determine the desired output (e.g., classification labels versus regression values). This affects the configuration of the first and last layers.
- Network Architecture: Choose the appropriate architecture based on the task. For instance, CNNs are optimal for image data, while RNNs suit sequential data. Experimentation with existing architectures is useful.
- Layers and Connections: Decide the number of neurons and the connectivity between layers. Too few neurons may cause underfitting, whereas too many may lead to overfitting.
- Activation Functions: Select the right activation functions (e.g., ReLU, sigmoid, or tanh) to capture non-linear patterns within your data.

Loss Functions and Optimizers
After designing the model, the next step is training. Training involves optimizing the model’s parameters (weights and biases) by reducing the error using loss functions and optimizers.- Loss Function: This function measures how well the model’s predictions match the target values. Common examples include cross-entropy loss for classification tasks and mean squared error (MSE) for regression tasks.
- Optimizer: The optimizer adjusts the model’s parameters to minimize the loss using gradients computed via backpropagation. Popular optimizers include Stochastic Gradient Descent (SGD) and Adam.

criterion is set to cross-entropy loss for classification tasks, and optimizer is configured as SGD with a learning rate of 0.001 and momentum of 0.9. Other loss functions such as Mean Squared Error (MSELoss) and Binary Cross-Entropy (BCELoss) cater to regression and binary classification tasks, respectively.

- Stochastic Gradient Descent (SGD): Updates weights based on gradients, often enhanced with momentum.
- Adam: Combines SGD with adaptive learning rates for improved optimization.

Automatic Differentiation with Autograd
One of PyTorch’s standout features is automatic differentiation with Autograd. This mechanism tracks operations performed on Tensors to build a computational graph, which is later used to compute gradients during backpropagation. When you invokeloss.backward(), Autograd calculates the gradients for each parameter, guiding the optimizer in updating the model’s weights.

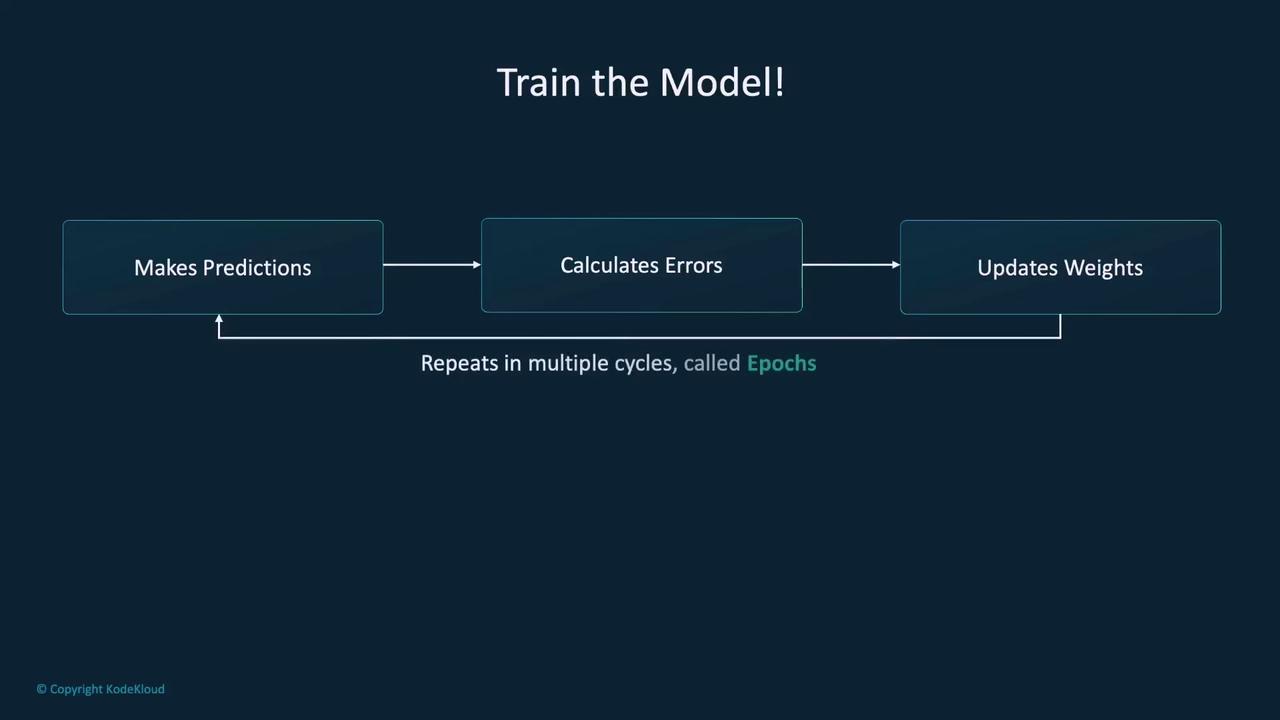
Training the Model
With the neural network, loss function, and optimizer defined, the next step is training the model. Training involves iterating through the dataset over multiple epochs. In each epoch, the model:- Makes predictions.
- Calculates the loss.
- Computes gradients using backpropagation.
- Updates its weights via the optimizer.
Example Training Loop
Below is an example demonstrating a training loop that runs over three epochs:- Data is fetched in batches from
trainloader. - Gradients are reset using
optimizer.zero_grad(). - A forward pass calculates predictions.
- The loss is then backpropagated, and the optimizer updates the model parameters.
- The average loss for each epoch is printed to monitor training progress.
Incorporating Validation Data
Validating your model during training is essential for ensuring that it generalizes well and does not overfit the training data. Overfitting occurs when the model learns the details and noise in the training dataset too well, resulting in poor performance on unseen data.Updated Training Loop with Validation
The example below demonstrates a training loop that includes a validation phase:Remember to switch between training and evaluation modes using
model.train() and model.eval(). This ensures that layers like dropout behave correctly during training and inference.
Recap of the Steps
-
Define the Model:
- Create a class that inherits from
torch.nn.Module. - Define the network layers in the
__init__method. - Specify the data flow in the
forwardmethod.
- Create a class that inherits from
-
Set Up the Training Environment:
- Initialize the model.
- Define a loss function to quantify errors.
- Set up an optimizer to adjust model parameters.
-
Implement the Training Loop:
- Iterate through batches for several epochs.
- Perform forward passes, compute the loss, backpropagate, and update weights.
- Optionally incorporate validation to monitor generalization.

Conclusion
In this article, we have covered:- How to build a neural network in PyTorch by defining a class that inherits from
torch.nn.Module. - How to design the network structure, including layer definitions and the forward pass.
- The importance of loss functions and optimizers in training.
- How to implement a training loop that incorporates validation to combat overfitting.