
What We’ll Cover
-
Design Principles and Foundational Concepts
Understand the key principles that enable automatic scaling, recovery from failures, and comprehensive automation while planning for potential issues. -
Application of Reliability to AWS Services
Explore how various AWS services, including networking, storage, compute, and databases, integrate reliability best practices. -
Demos and Labs
Participate in practical labs and demos that provide hands-on experience. -
Final Design Challenge
Reinforce your learning with a quiz that simulates real-world AWS design choices.

Reliability Design Principles
We begin by reviewing essential design principles for reliability. This section covers how systems can scale automatically, recover from failure, automate processes, and plan ahead for potential disruptions. These principles are integral to understanding disaster recovery models, which are a key exam topic. You will learn about strategies such as:- Backup and Restore
- Multi-site Active-Active Configurations
- Warm Standby
- Pilot Light Setups
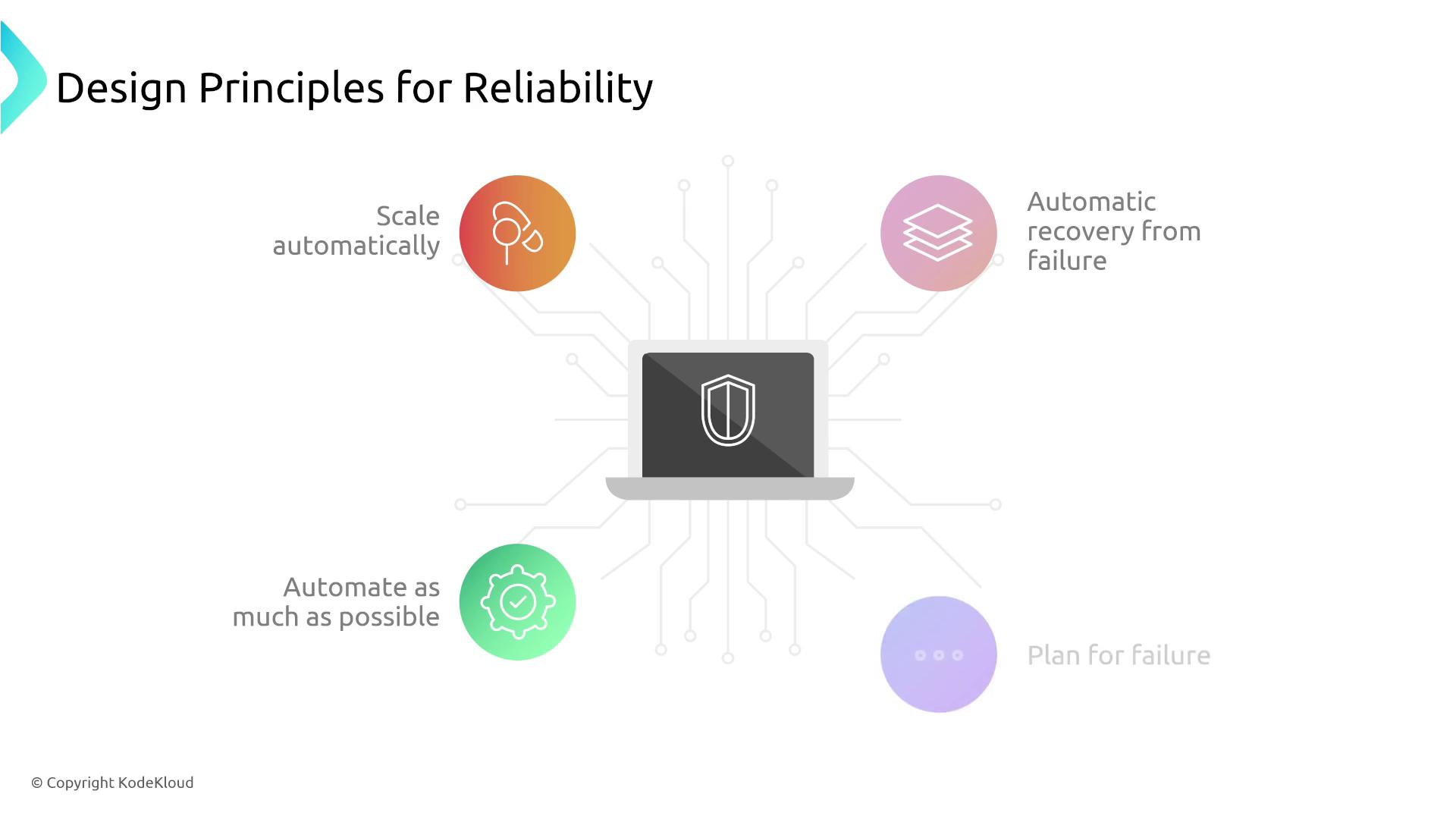
Focusing on these principles early will help simplify the complex topics later in the course.
Understanding Disaster Recovery Models
Next, we discuss various disaster recovery models. In this section, you’ll explore models ranging from simple backup and restore to multi-site active-active configurations. Each model has its trade-offs between cost, control, and recovery speed.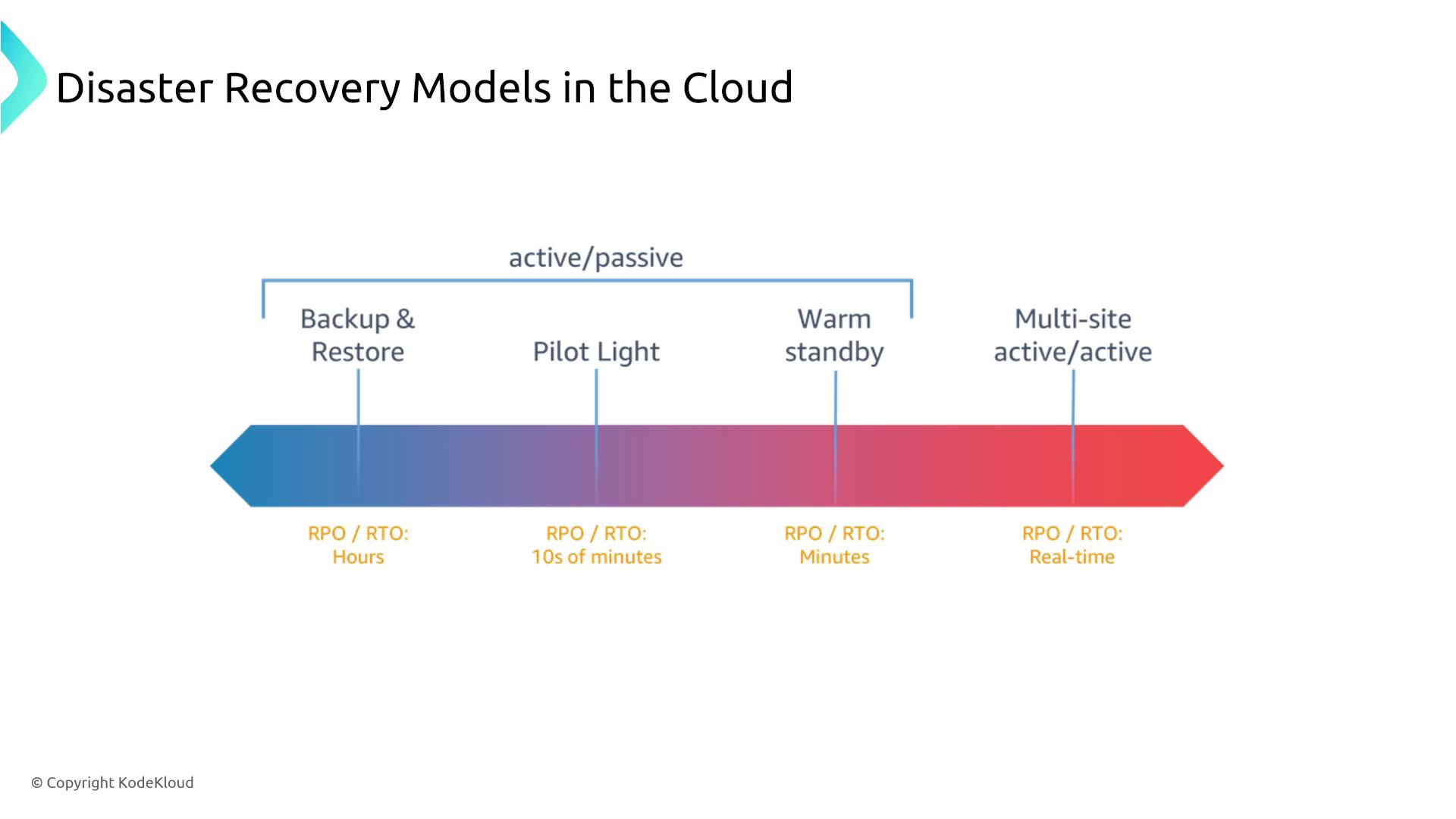
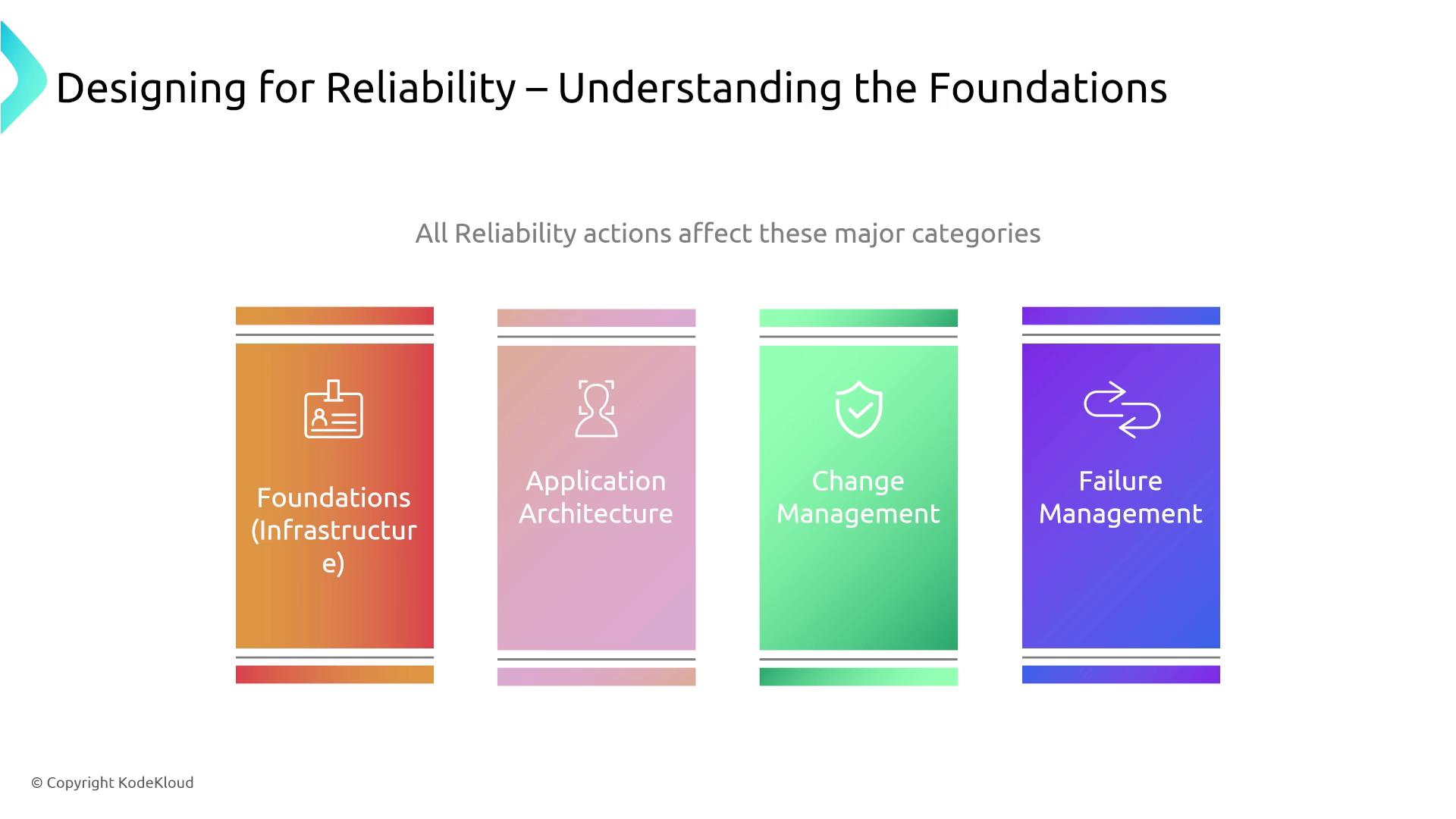
Key Categories Influencing Reliability
We now introduce major categories that shape reliability and design:| Category | Description |
|---|---|
| Foundations | Actions that enhance basic infrastructure reliability. |
| Application Architecture | Architectural patterns that bolster application resilience. |
| Process and Change Management | Strategies to manage system modifications and updates. |
| Failure Management | Approaches to detect, respond, and recover from failures. |
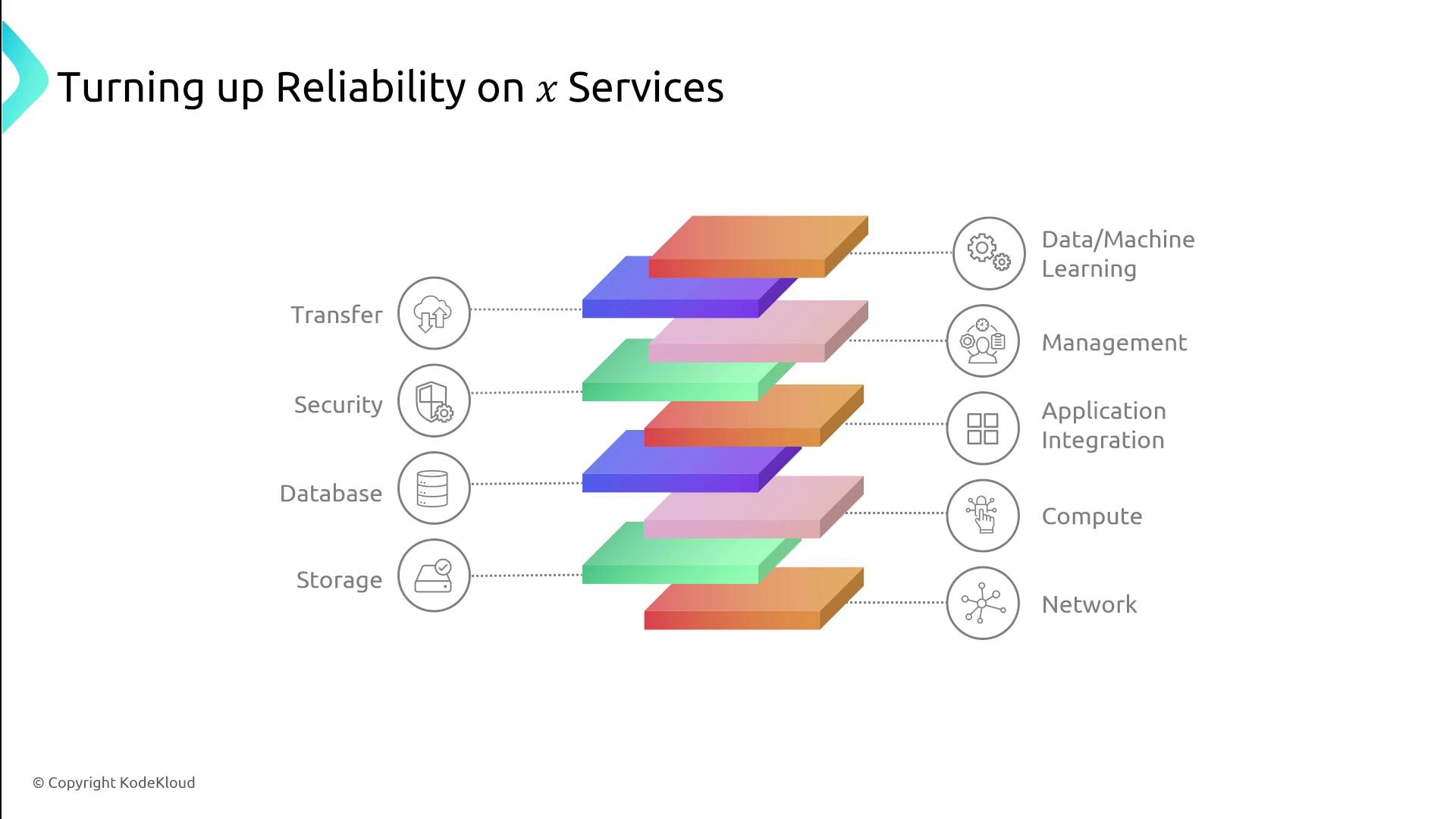
AWS Service Groups and Reliability
We will now explore various AWS service groups through the lens of reliability. The topics typically follow the sequence below:- Networking
- Storage
- Compute
- Database
- Application Integration
(Including services like Auto Scaling and Simple Notification Service) - Security, Management, and Governance
- Transfer and Migration Services
- Data, Machine Learning, and Specialized Services
Design Challenge Overview
Towards the end of this section series, you’ll engage in a design challenge. This exercise simulates real-world scenarios by asking you to choose appropriate AWS services based on specific requirements. For example:- For compute at the edge, AWS Lambda@Edge or CloudFront functions may be appropriate.
- For content delivery, CloudFront is typically the best option.
- For internet name resolution, Route 53 is essential.
- For scalable key-value data storage, DynamoDB often fits the need.
- For serverless compute, AWS Lambda is a popular choice.
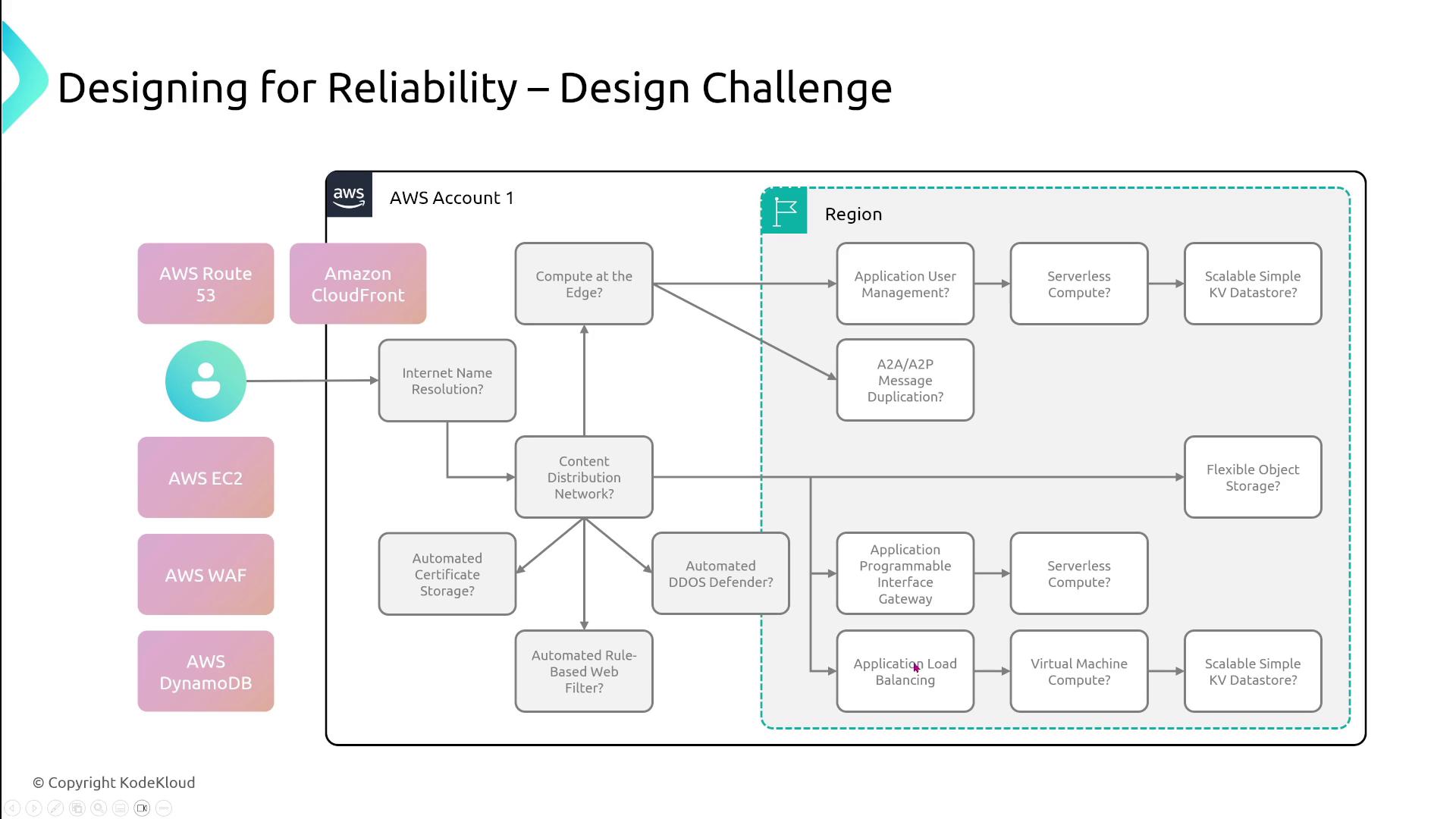
Pay special attention to the design challenge—this part of the lesson is designed to mirror real-world scenarios and exam-style questions. Practice and internalize these concepts to build a strong foundation for the exam.