Designing for reliability is about striking a balance between uptime and cost. For instance, achieving 100% uptime for a complex e-commerce environment may be prohibitively expensive compared to accepting minor, infrequent downtime.
1. Ability to Recover from Disruption
Resiliency is measured by how quickly and smoothly a workload can recover from disruptions, which may include hardware failures, resource exhaustion, misconfigurations, or transient network issues. A reliable system either recovers rapidly or fails gracefully. For example, AWS services such as EBS automatically maintain multiple data copies so that an unnoticed disk failure does not adversely affect the overall operation.2. Plan for Failure
Expect that components—whether they are computers, networks, data centers, disks, or VPNs—will eventually fail. Designing your systems with failure in mind means anticipating potential weak points and establishing effective recovery and mitigation strategies. This proactive planning ensures that your architecture remains robust even when individual components falter.
3. Automate Recovery
Minimize downtime and reduce human intervention by automating recovery processes. For example, if a server’s primary database fails, having automated failover to a secondary instance ensures business continuity. AWS RDS and Aurora provide built-in automated recovery mechanisms, and integrating tools like RDS Proxy further improve resilience by masking database failures from end users.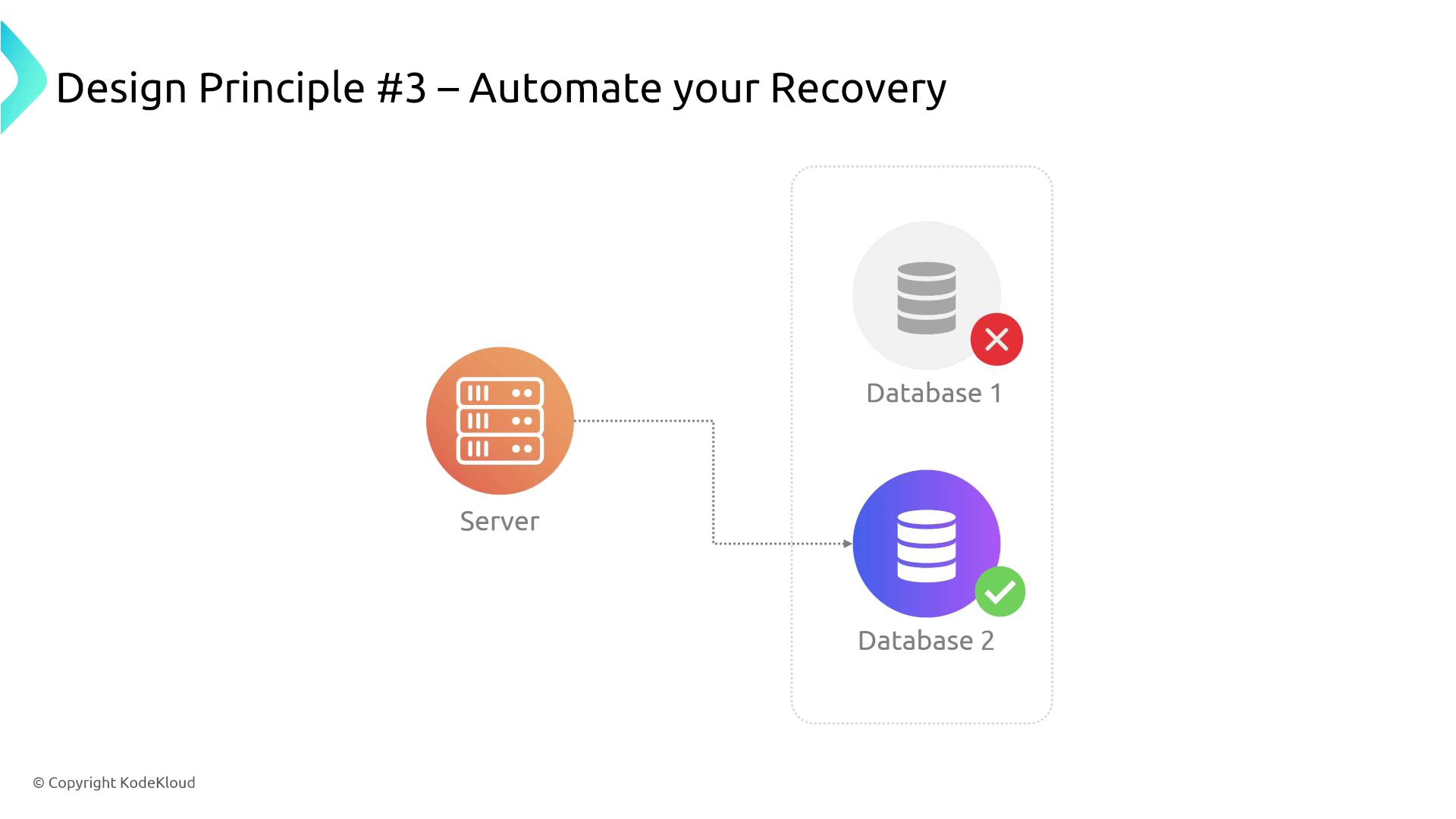
4. Prevent Capacity Outages Through Scaling
Scale your systems horizontally to match escalating customer demand. As workload increases, ensure that server capacity scales accordingly or even ahead of demand to prevent capacity outages. This proactive scaling strategy maintains consistent performance even during peak usage.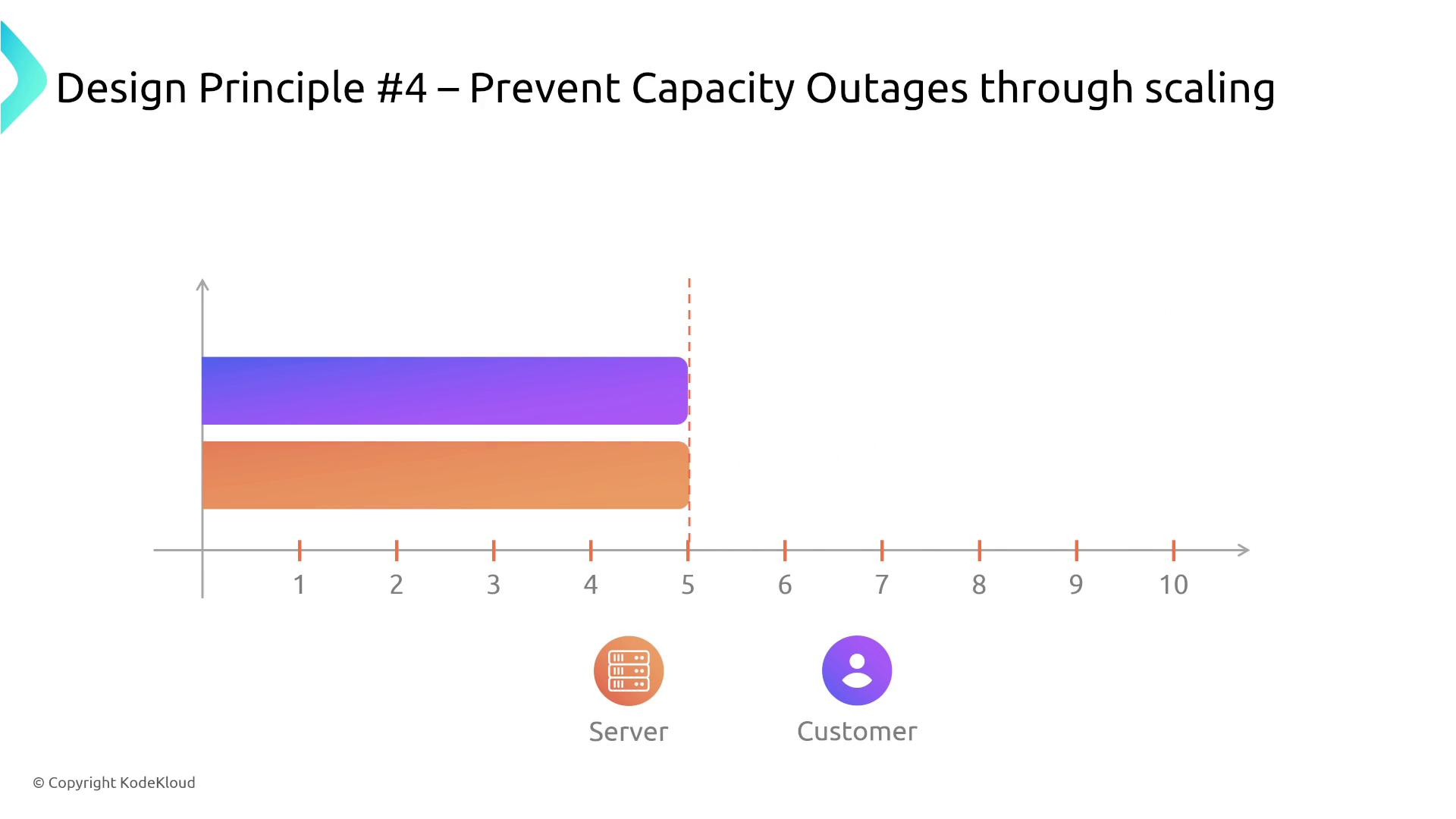
5. Test Everything
Testing is a critical component of resilient design. Validate how your system responds to failure scenarios by intentionally turning off components and observing the results. This method, reminiscent of chaos engineering, ensures that load tests, backups, and failure protocols operate as intended. Always verify that backups can be restored reliably through regular restore testing.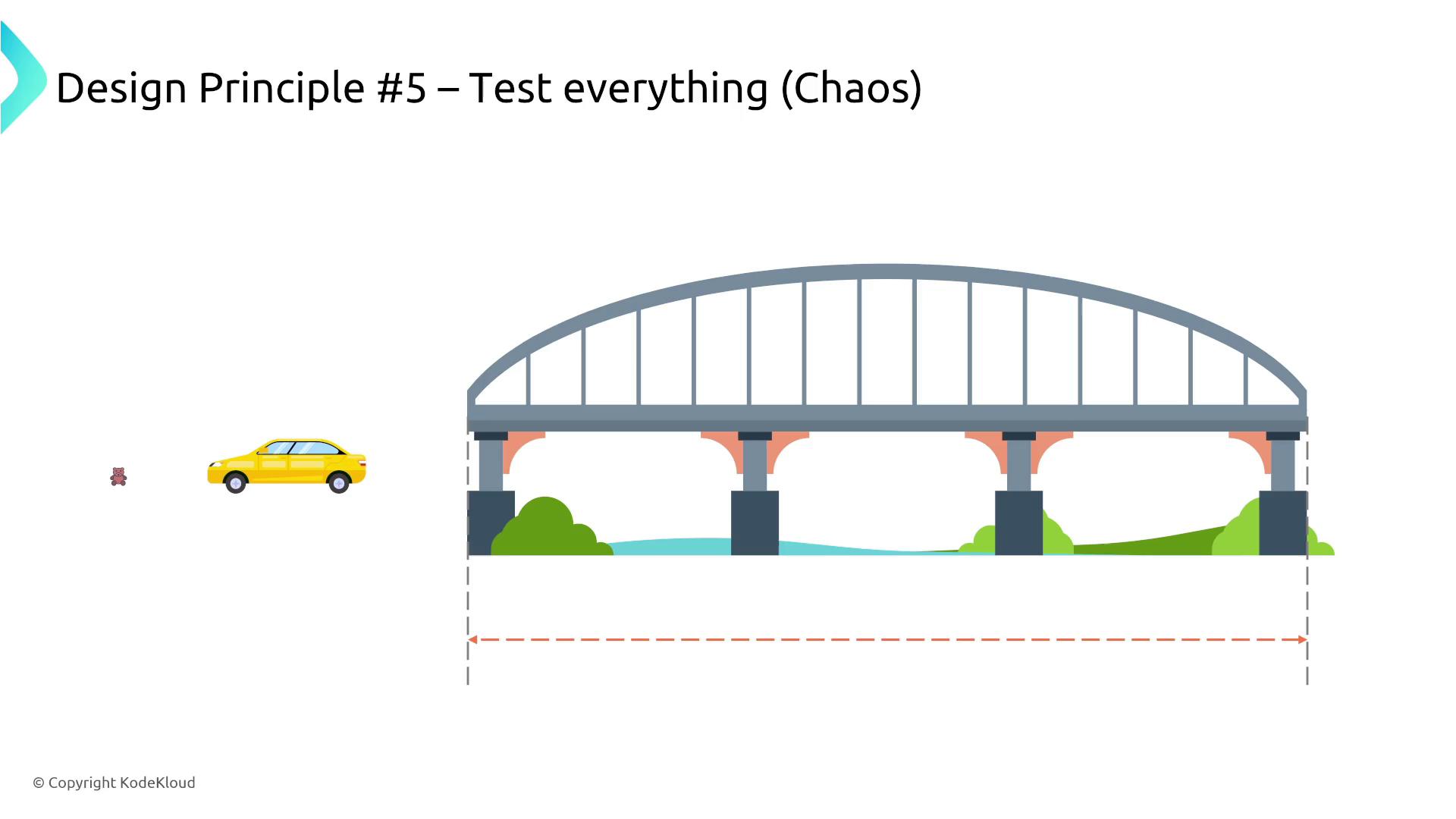
6. Use Only the Availability You Need
Avoid over-engineering availability. High-availability architectures come at a significant cost, so align your design choices with the actual needs of the business. Not every application requires maximum availability; tailor your system’s availability to balance performance needs with cost efficiency.
7. Measure Everything and Document It
Consistent monitoring and documentation are keys to understanding system behavior. Track performance data using dashboards, SLAs, and internal documentation to establish baselines for “normal” operation. This rigorous measurement process enables you to validate whether reliability improvements are effective and informs future decision-making.
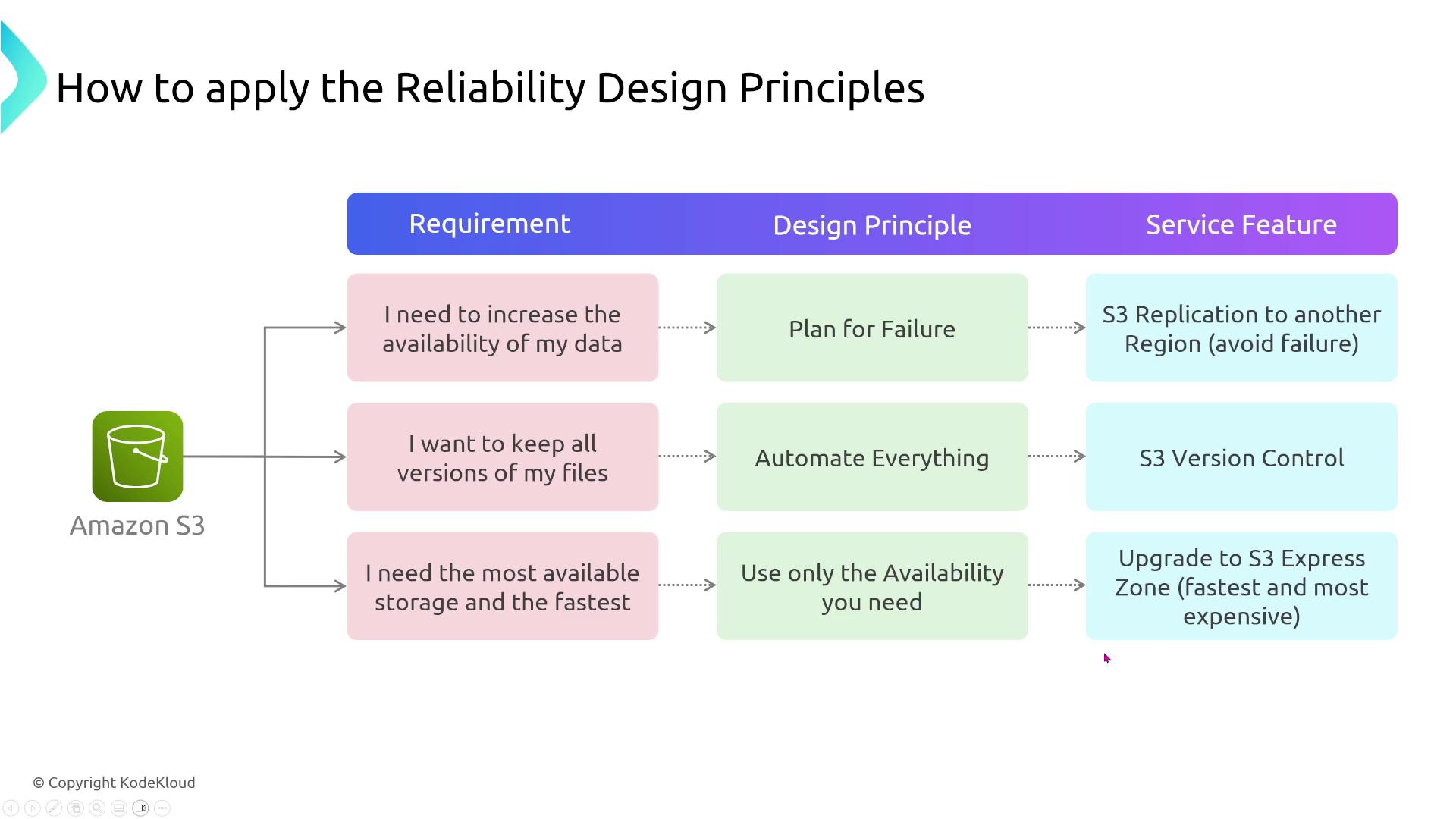
In practice, these principles are interrelated. For instance, maximizing data availability may involve planning for failure, automating recovery, and distributing data across regions. When preserving every version of a file is critical, enabling S3 versioning provides an automated layer of data protection. For performance-sensitive applications demanding millisecond response times, consider advanced storage classes like S3 Express, introduced in November 2023, to meet stringent performance benchmarks.
Summary
Design principles for resilience provide a structured framework for enhancing system reliability. By planning for failure, automating recovery processes, scaling capacity proactively, and continuously testing and measuring performance, you can develop systems that withstand disruptions and deliver consistent service levels.