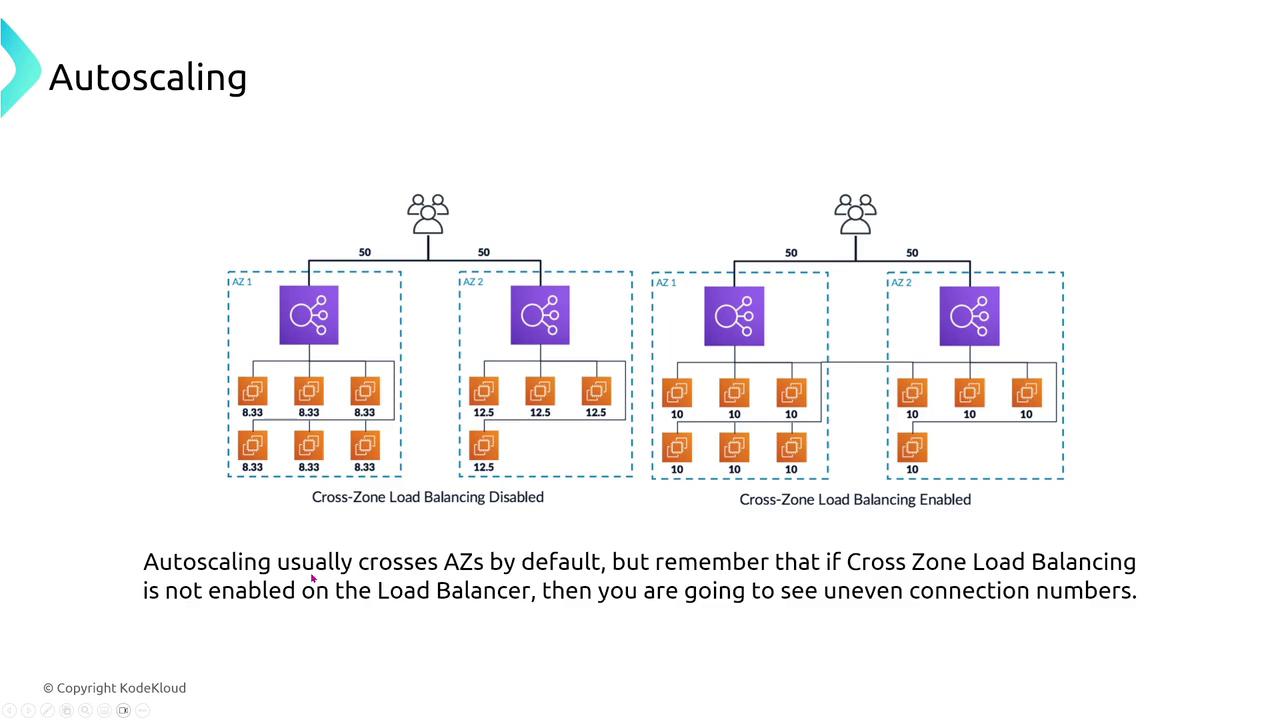
Auto Scaling and Application Load Balancers
Auto Scaling automatically launches new instances when failures occur, ensuring that your system remains resilient during disruptions. Although an auto scaling group might appear to have a single endpoint (the load balancer), the Application Load Balancer (ALB) is actually a virtual service comprised of multiple devices. It efficiently distributes traffic across instances, ensuring continuous availability even if one or more instances fail.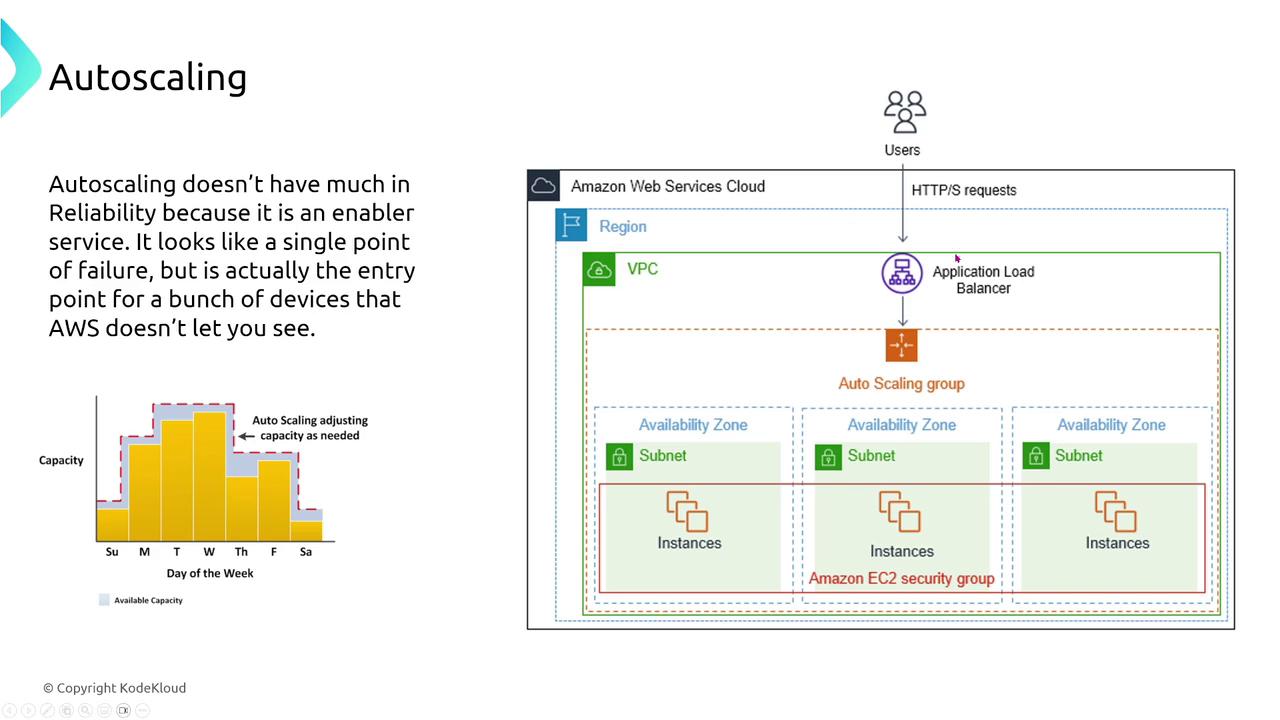

Load Balancers: Application, Network, and Gateway
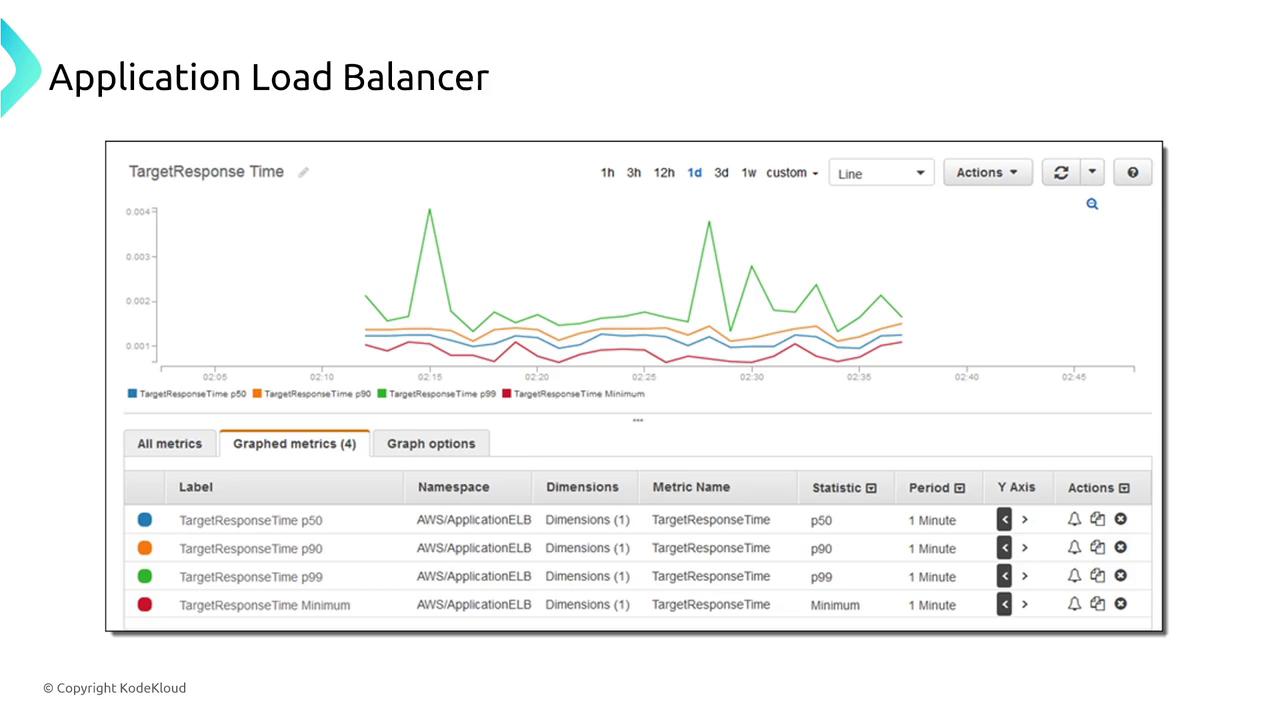
Application Load Balancer (ALB)
Operating at layer 7, ALBs can abstract HTTP/HTTPS traffic and perform target group health checks to detect and replace unhealthy instances. They support multiple listeners and rules, which allows you to distribute traffic based on geography or URL path patterns.



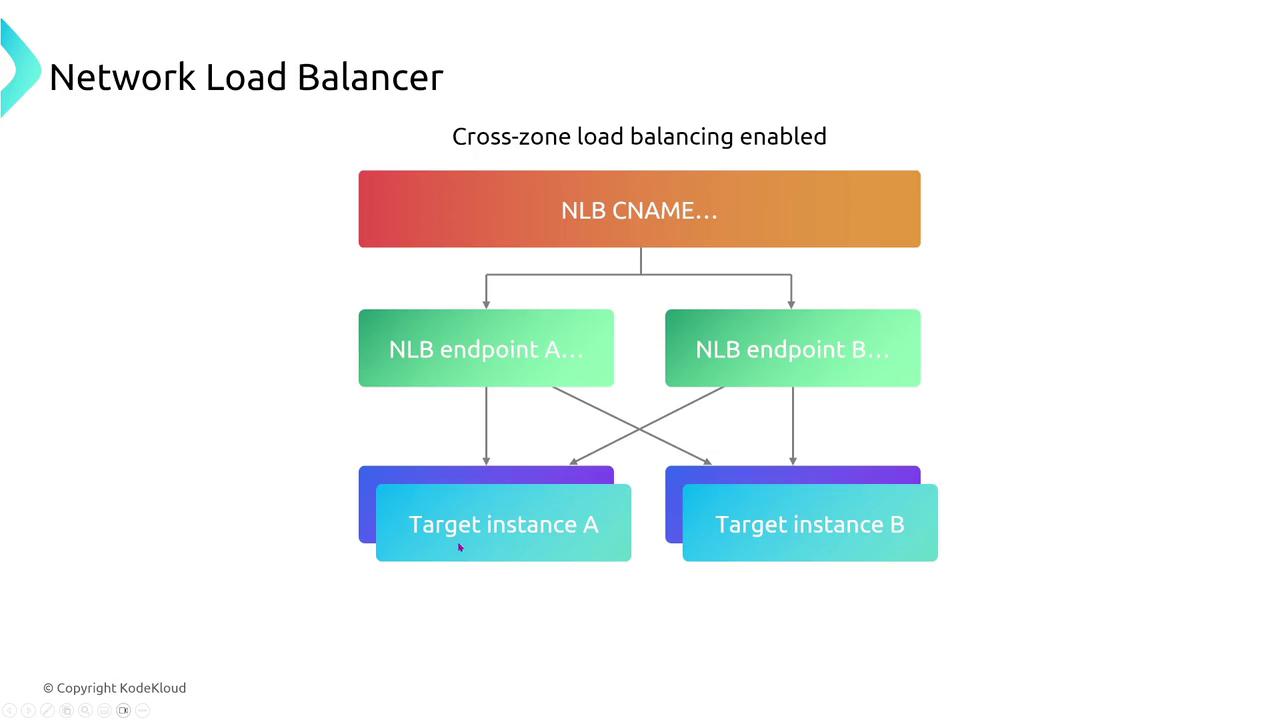
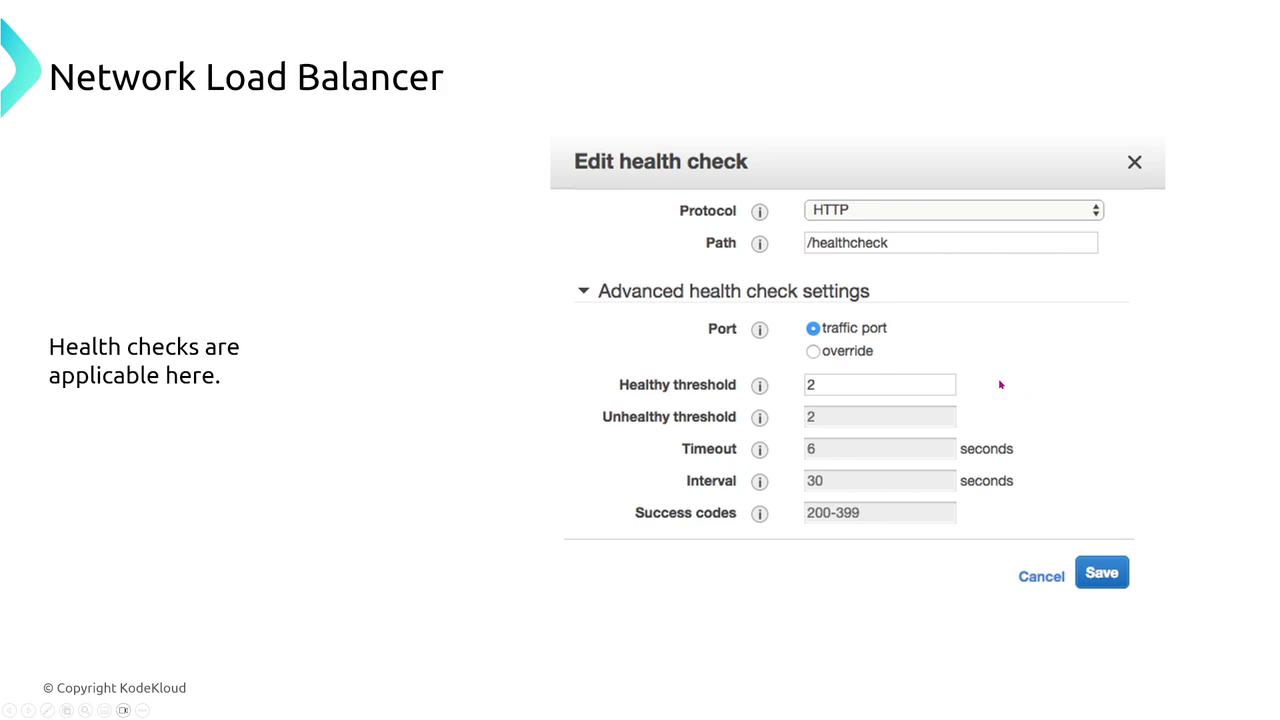
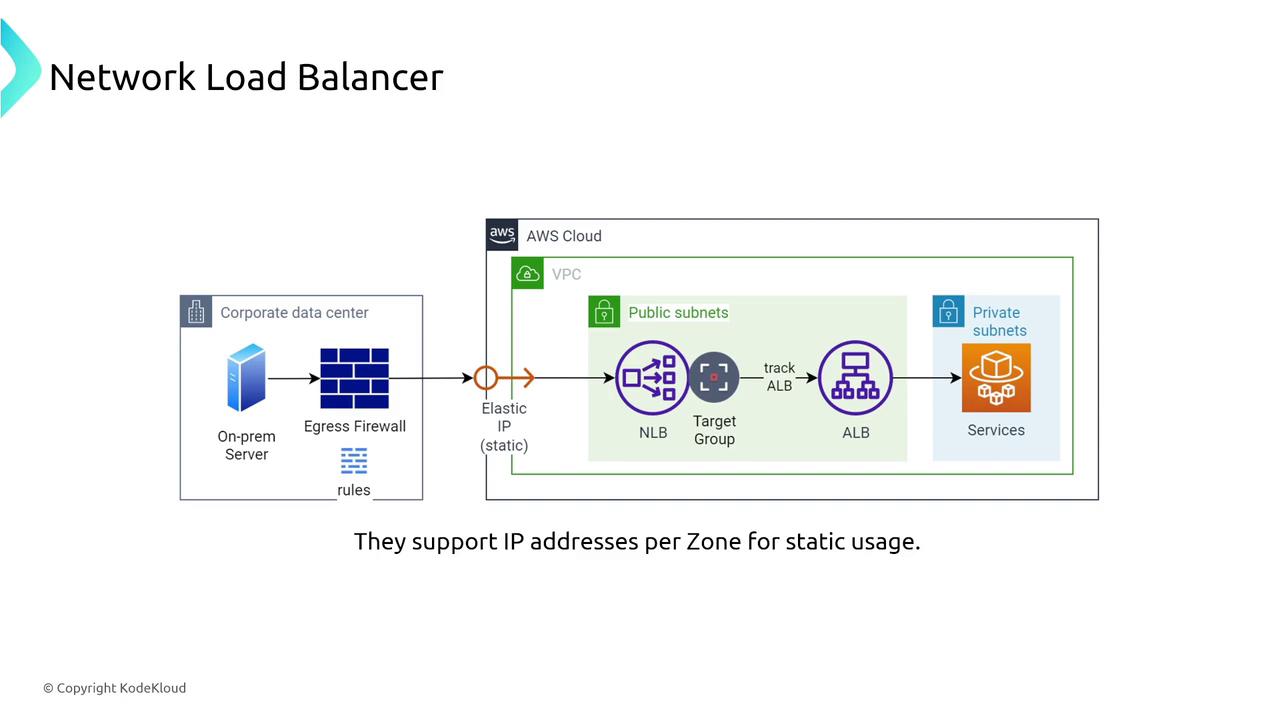
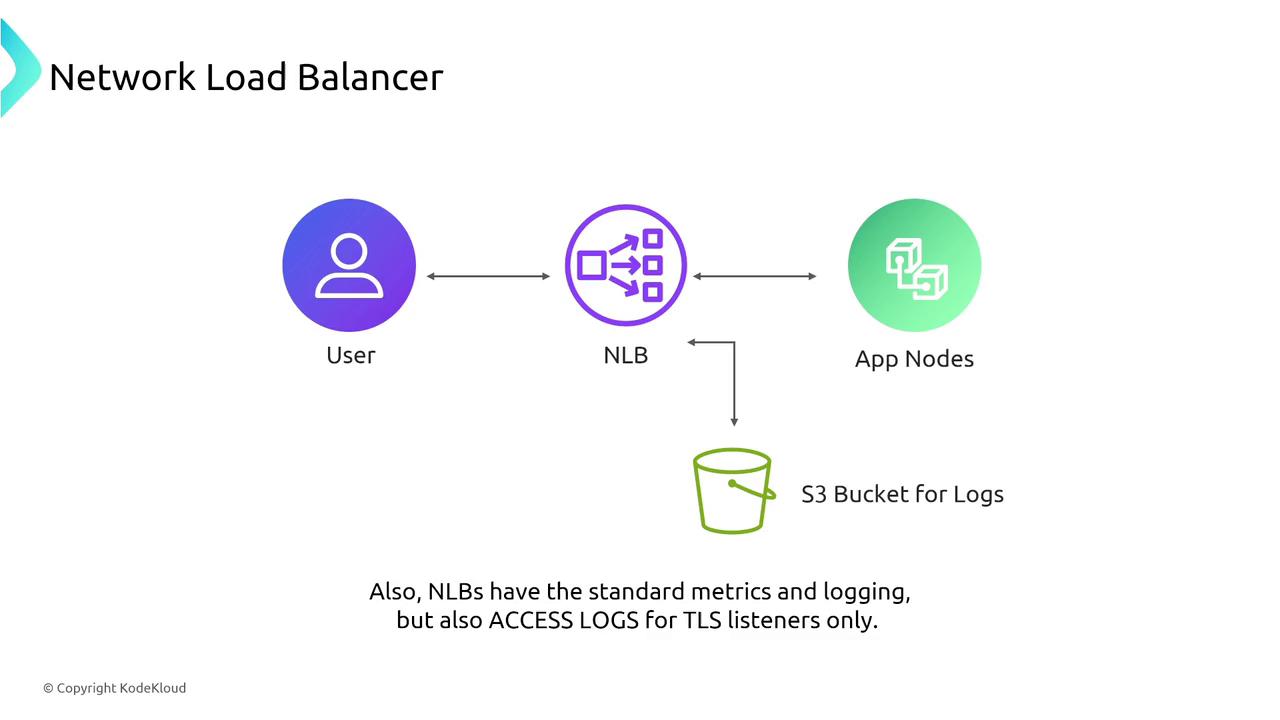
Network Load Balancer (NLB)
Operating at the transport layer, Network Load Balancers are engineered for high performance and handle TCP, UDP, and TLS traffic efficiently. Their straightforward configurations include target group health checks on specified ports. While NLBs do not support path-based routing, they integrate seamlessly with Auto Scaling as reliable targets.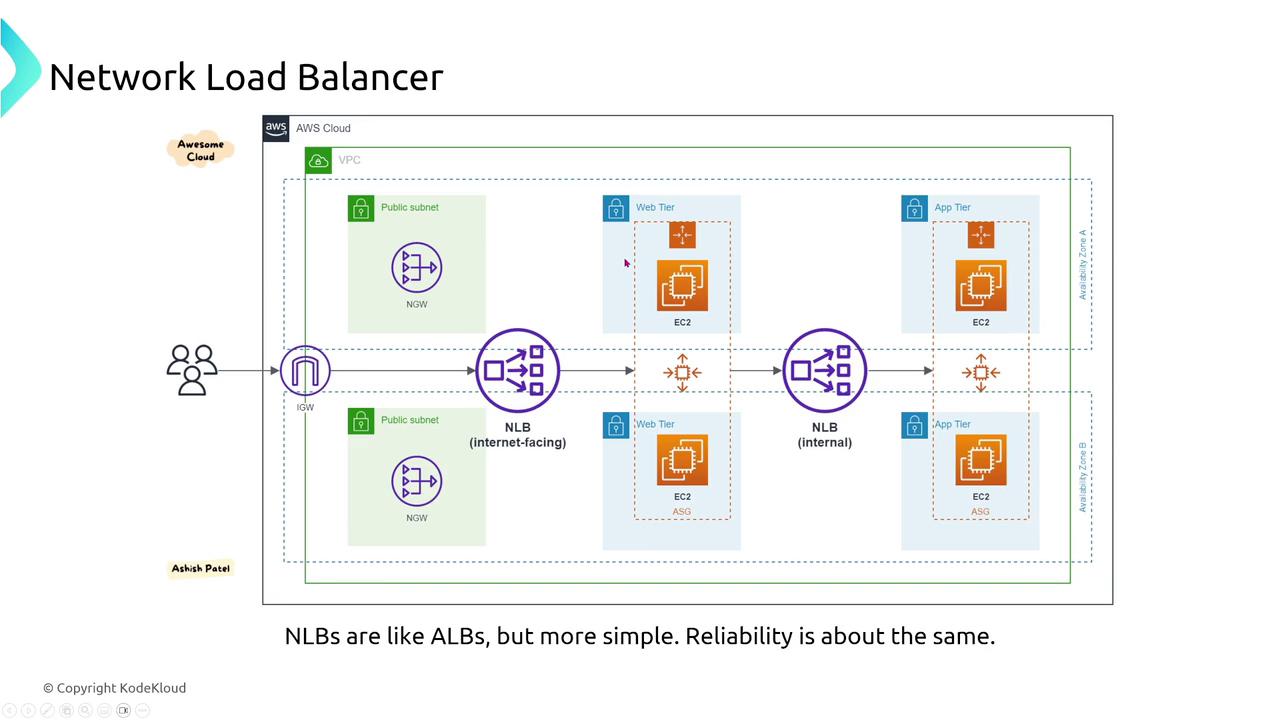
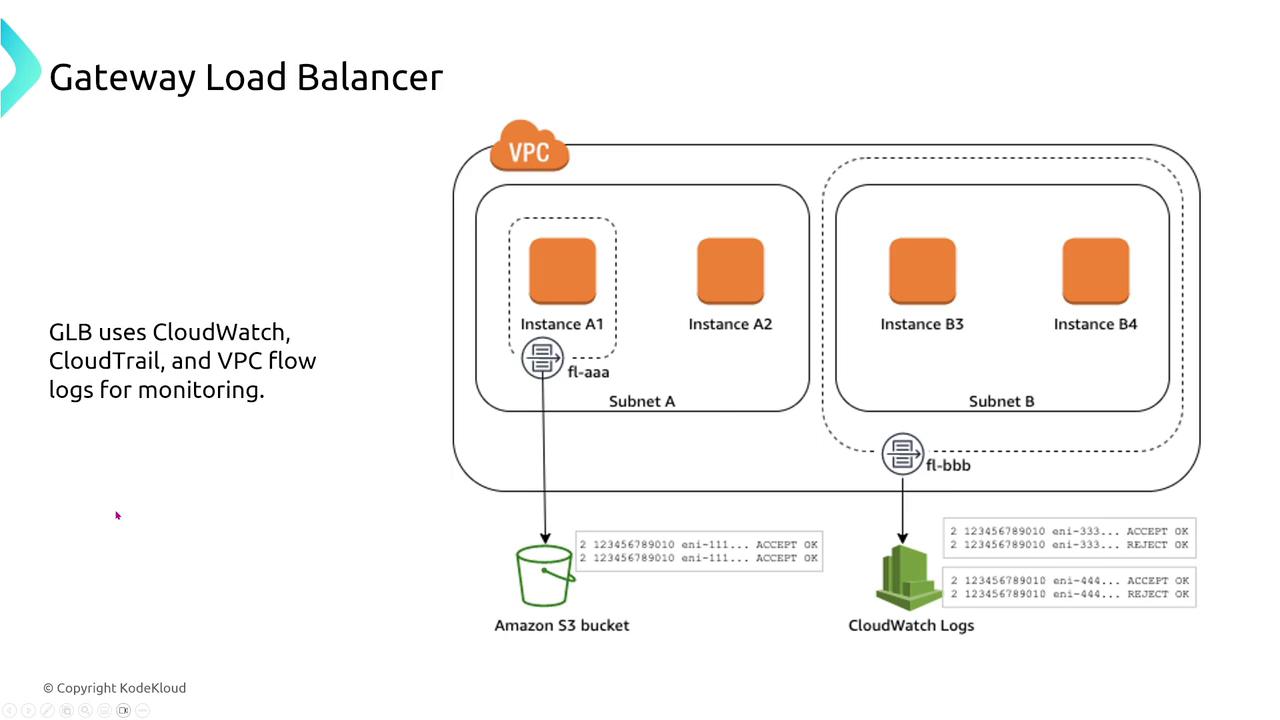
Gateway Load Balancer (GLB)
Gateway Load Balancers are built for traffic inspection appliances such as firewalls and packet inspectors. They receive traffic from endpoints defined in routing tables, forward it to inspection devices, and then deliver approved traffic to application servers. GLBs work closely with Auto Scaling groups to adjust capacity on demand.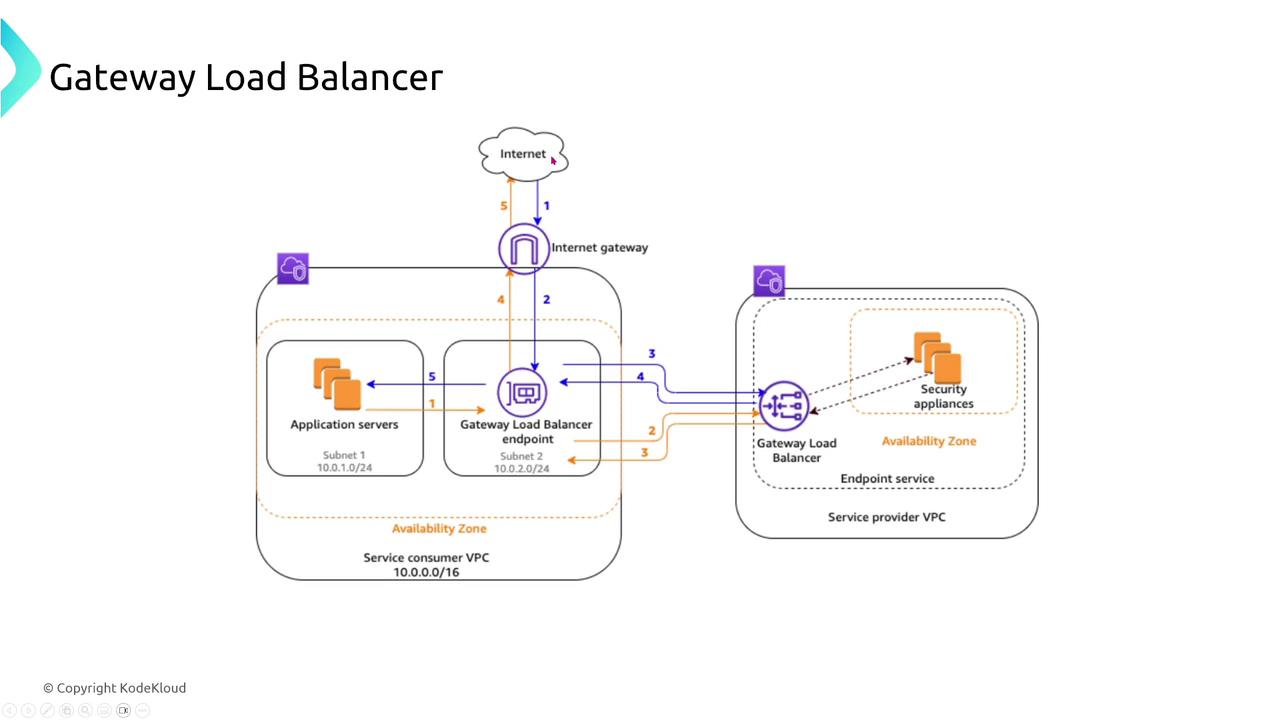
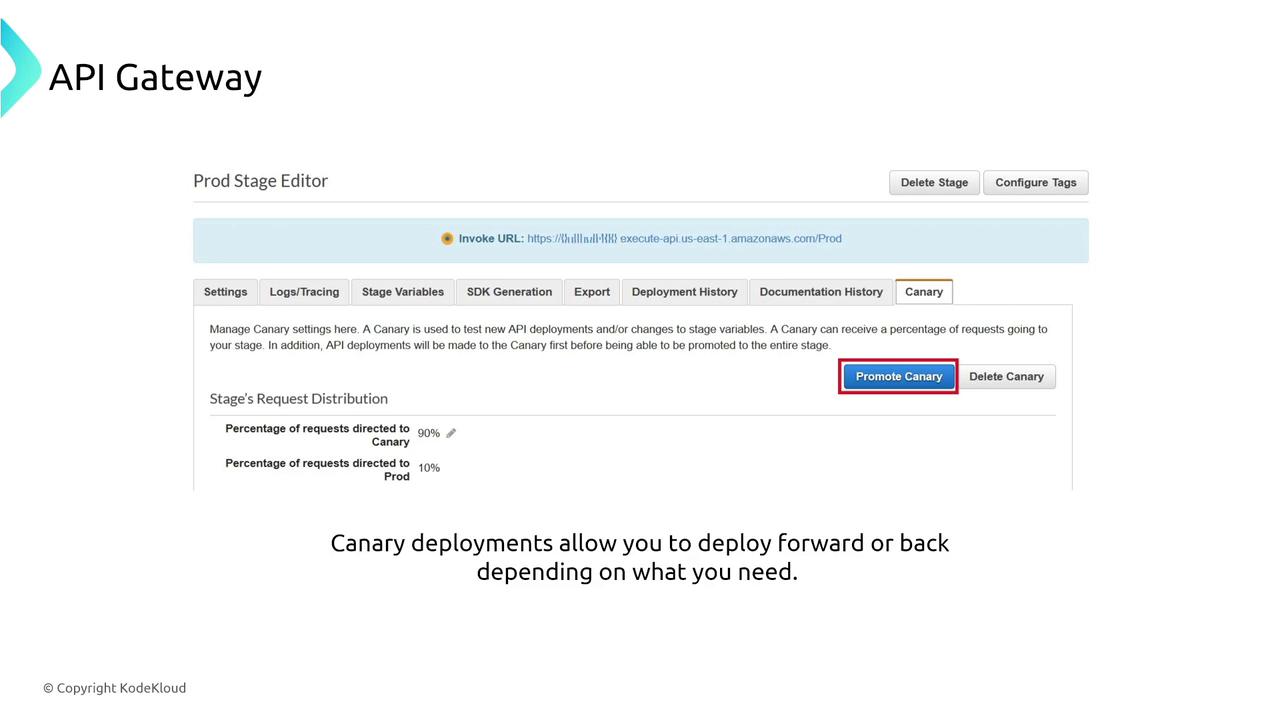
API Gateway
Amazon API Gateway enables you to create, deploy, and monitor both REST and WebSocket APIs. It offers additional features beyond what ALBs provide, such as caching, throttling, and rate limiting.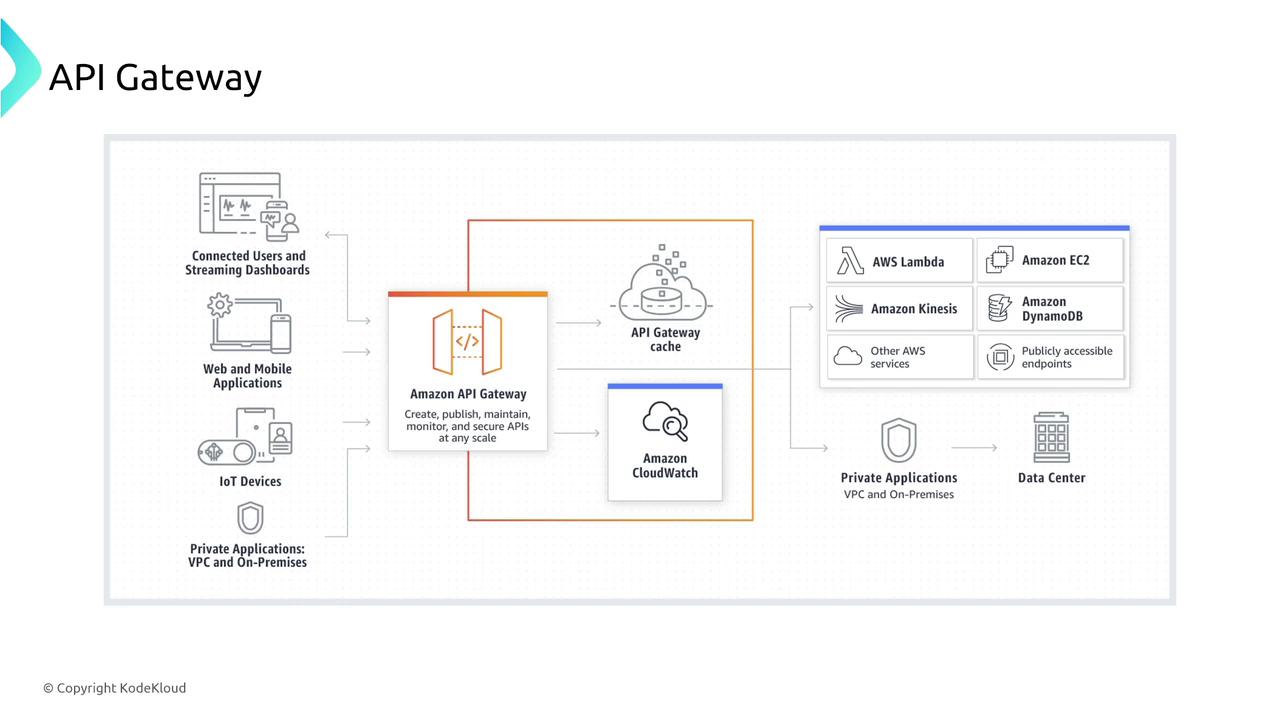

AppFlow
AWS AppFlow is a fully managed integration service that securely transfers data between AWS services and third-party applications. With built-in redundancy across multiple AZs, AppFlow ensures continuous data transfers even during an AZ failure.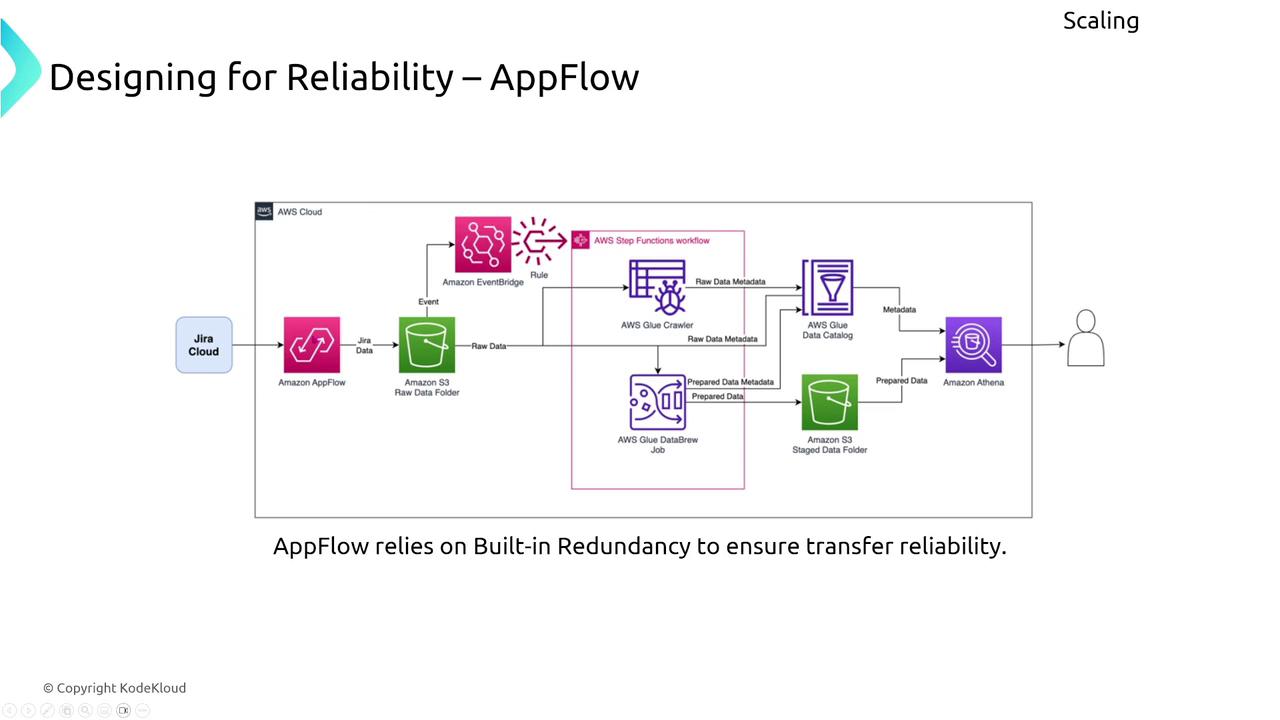

Messaging and Queueing Services
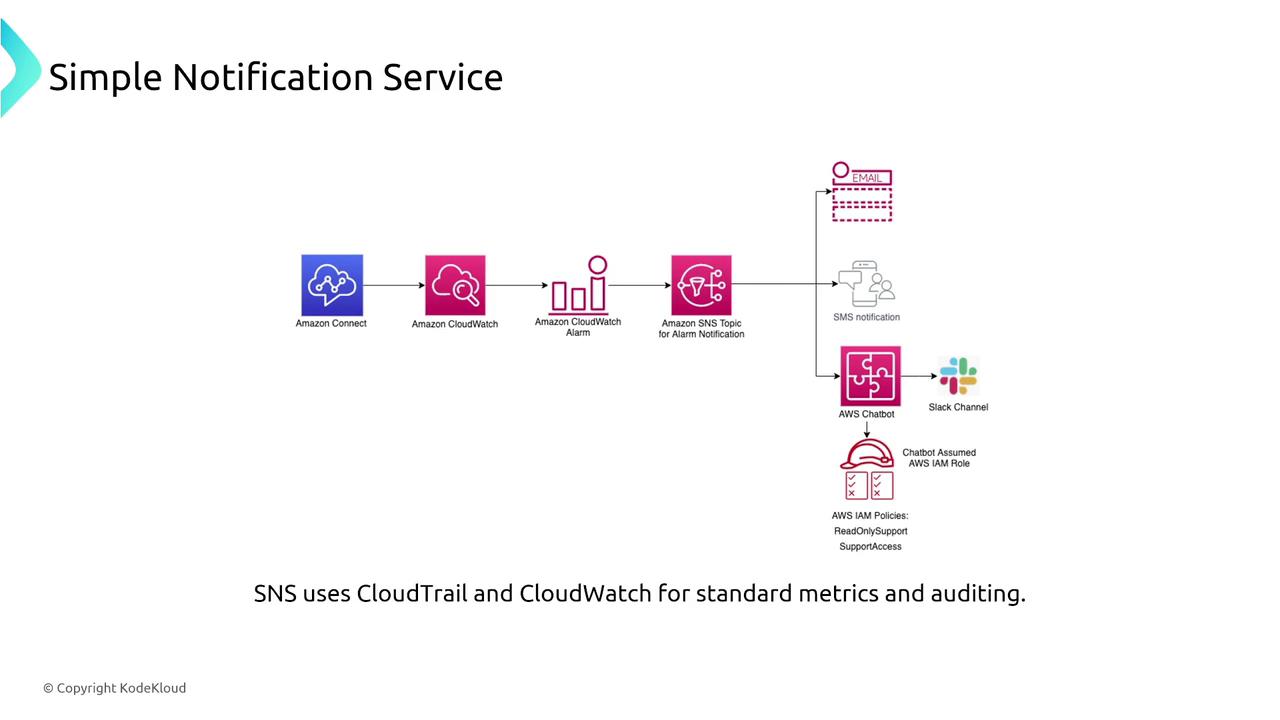
Simple Notification Service (SNS)
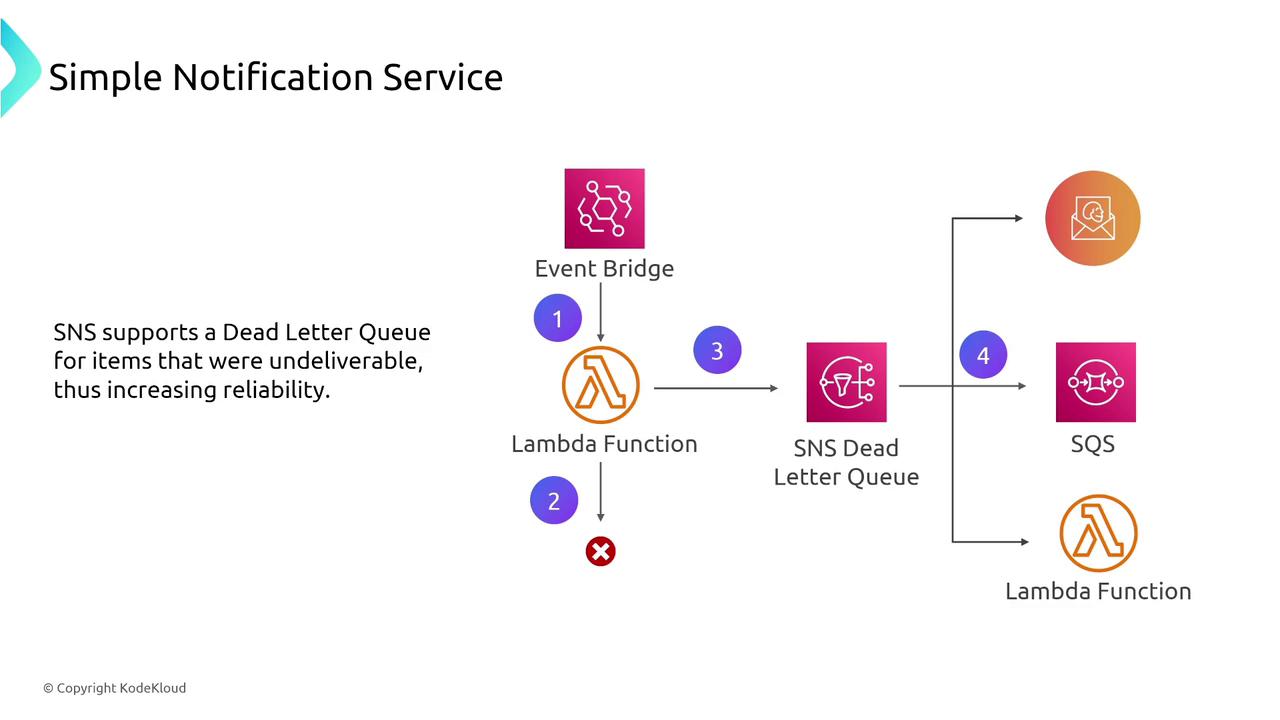
SNS is a fully managed publish/subscribe messaging service designed for high availability and fault tolerance. It automatically handles message retries and supports dead-letter queues for undeliverable messages, ensuring that no critical message is lost.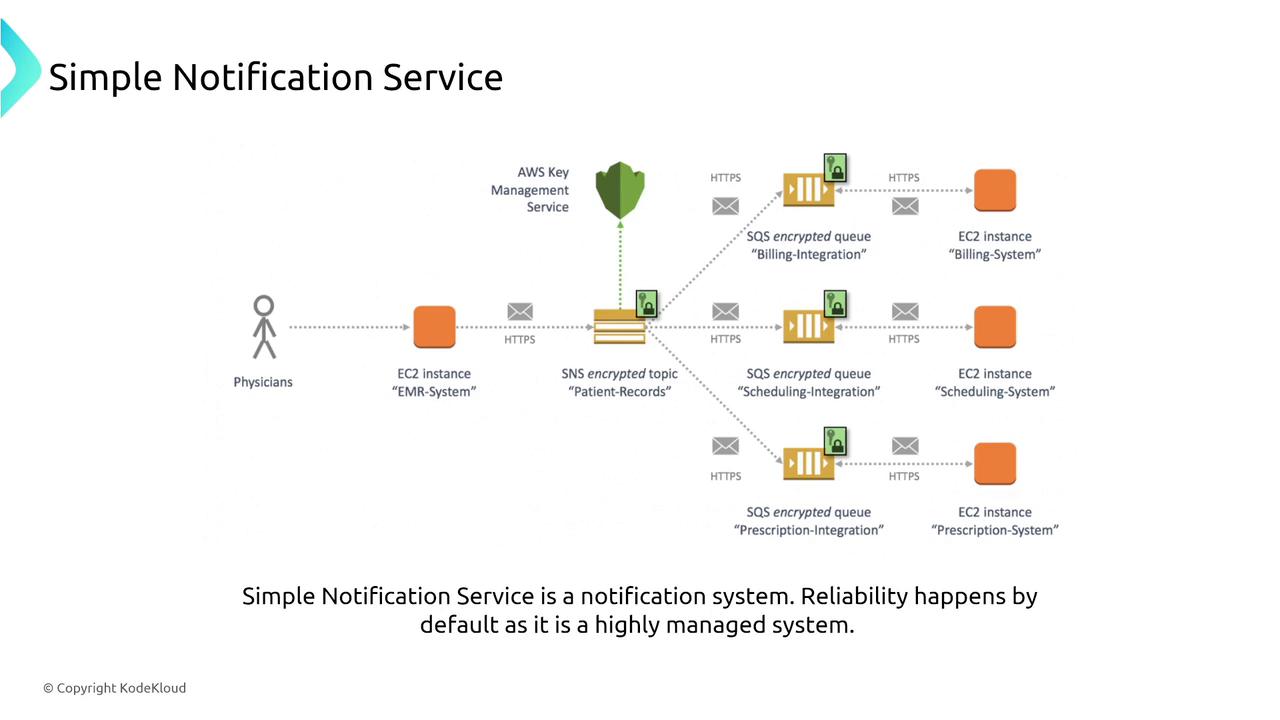
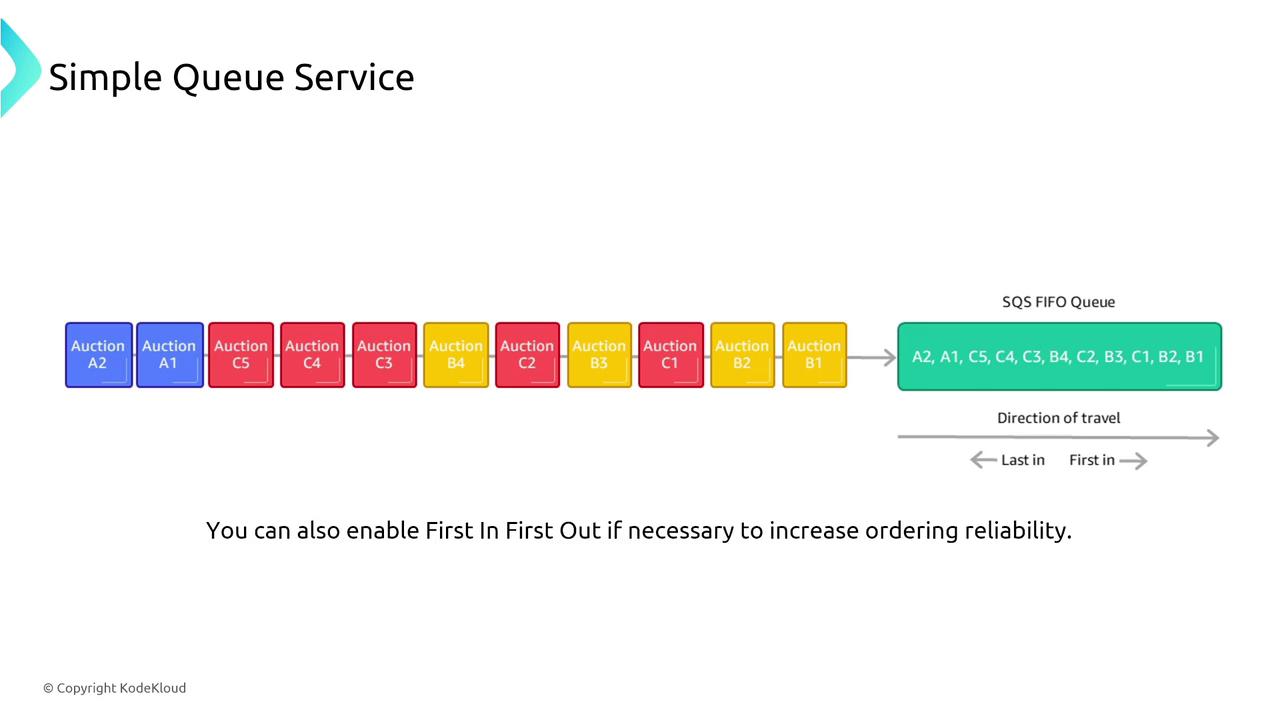
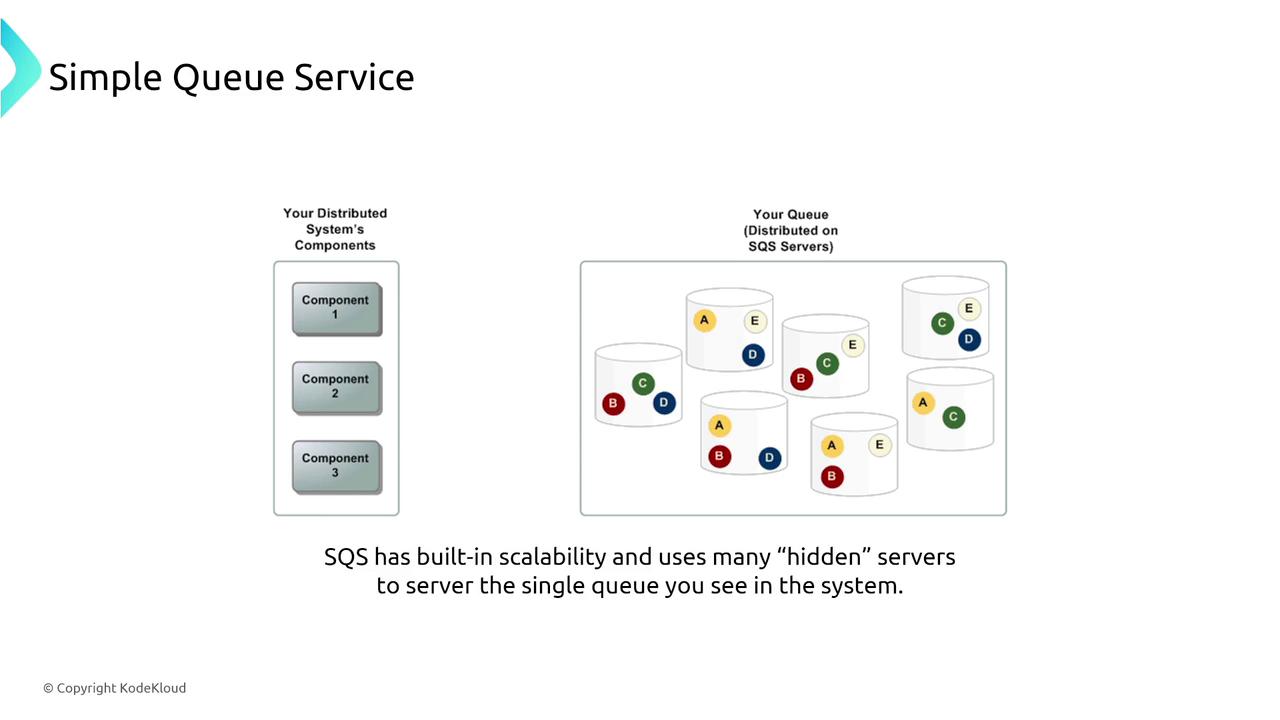
Simple Queue Service (SQS)
SQS is a robust, fully managed queueing service designed to ensure that messages are processed at least once. Features like long polling reduce unnecessary responses, and the visibility timeout mechanism prevents duplicate processing.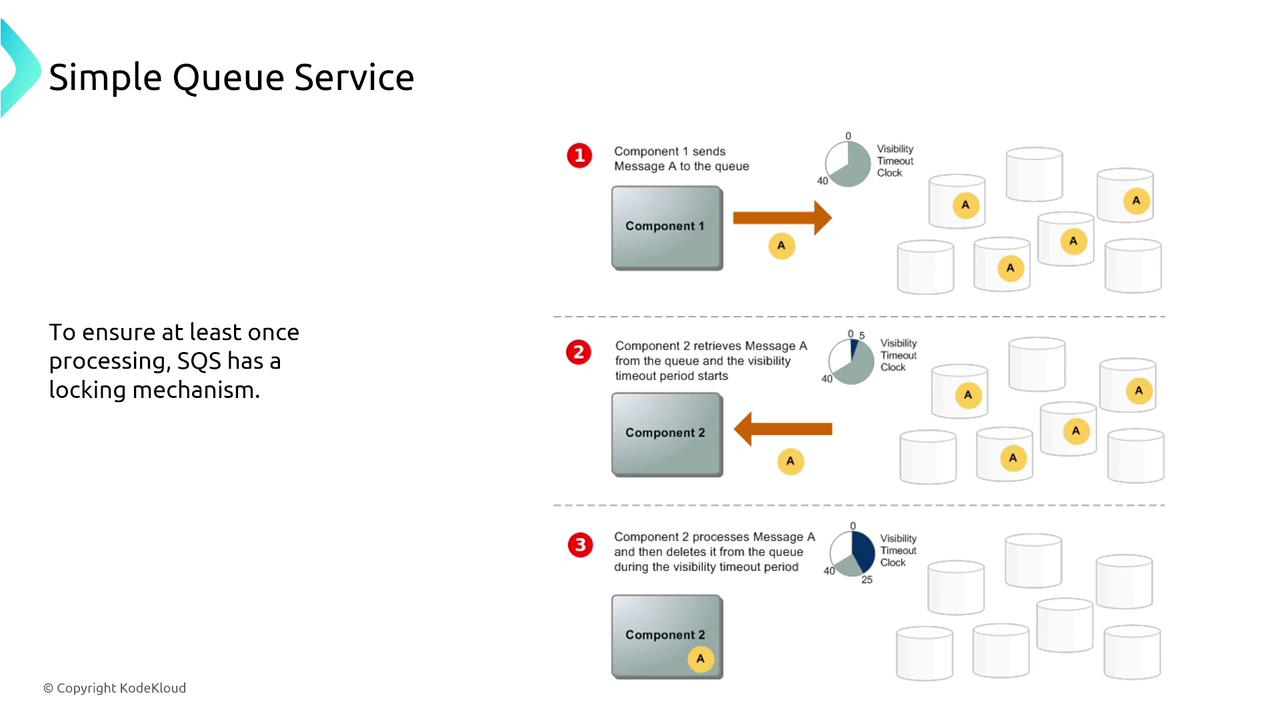
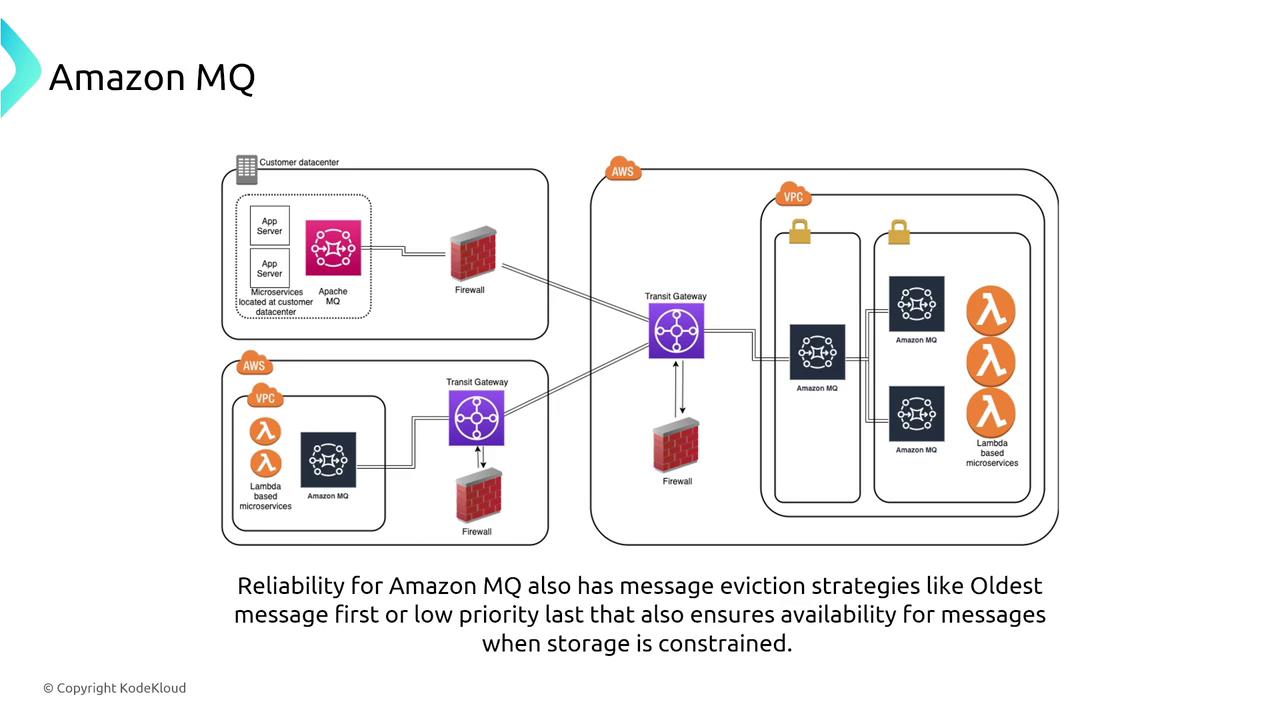
Amazon MQ
Amazon MQ offers managed messaging brokers that support industry-standard protocols such as MQTT, AMQP, and more. With capabilities like message mirroring, redelivery policies, and priority dispatch, Amazon MQ ensures reliable message delivery even during broker failures.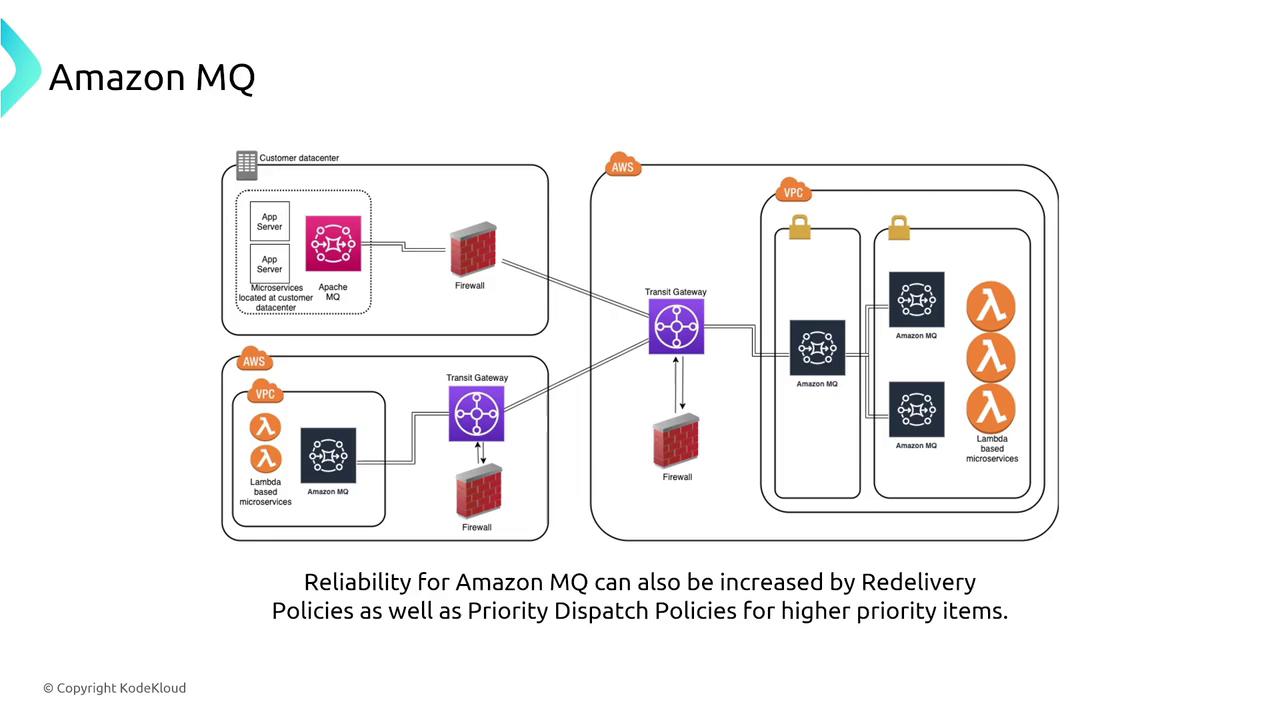

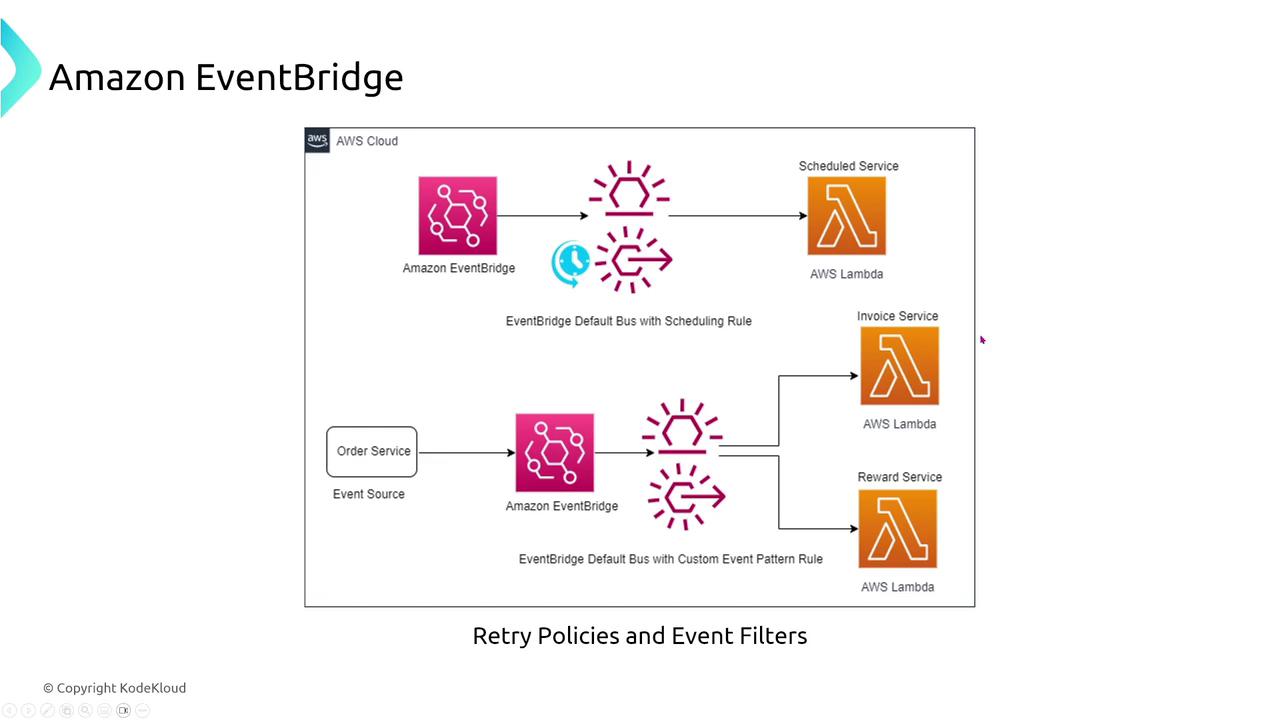
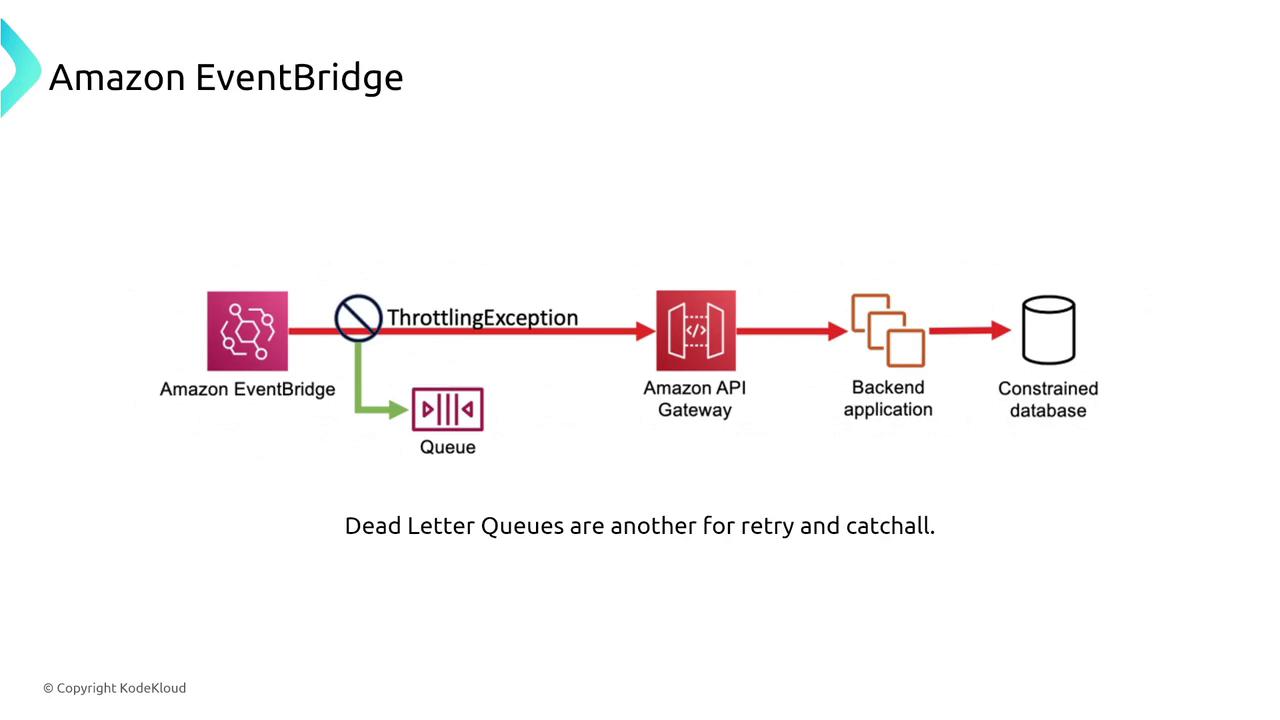
EventBridge
Amazon EventBridge, the evolution of CloudWatch Events, is a serverless event bus that enables event-driven architectures by connecting AWS services with SaaS applications. It supports features like event replay, retry policies, and filtering to manage events appropriately.
Simple Email Service (SES)
Amazon Simple Email Service (SES) is a managed email service engineered for high deliverability. With built-in redundancy and virus scanning, SES integrates with CloudWatch for performance metrics while the Virtual Deliverability Manager helps optimize email campaigns.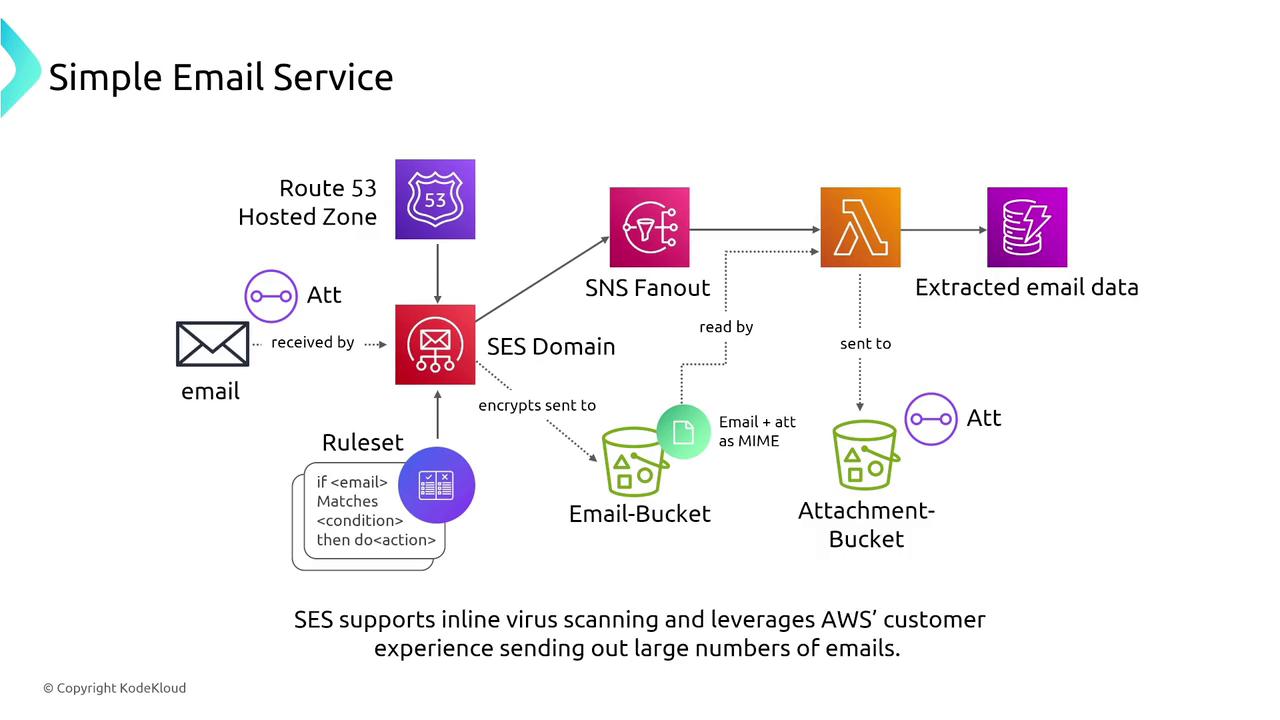

Workflows and Orchestration
AWS Step Functions
AWS Step Functions offer serverless workflow orchestration with built-in error handling through retry and catch configurations. This visual state machine enables you to monitor workflow executions via both the console and CloudWatch.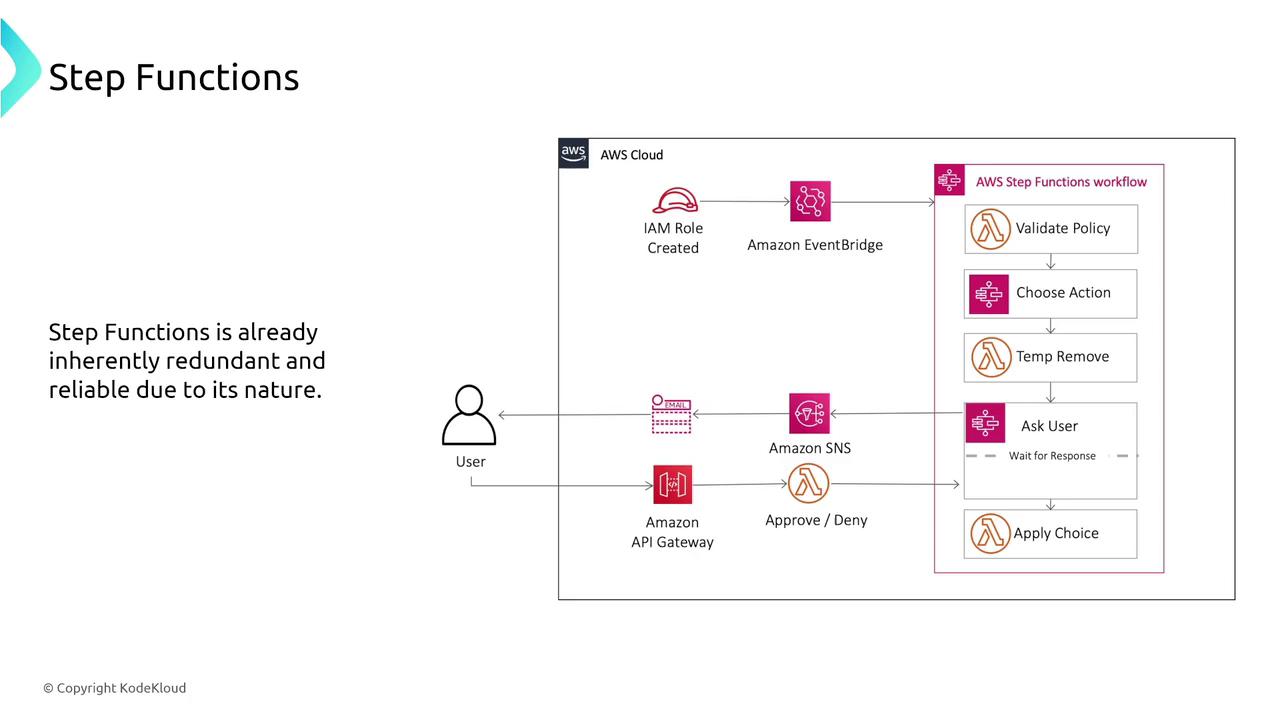

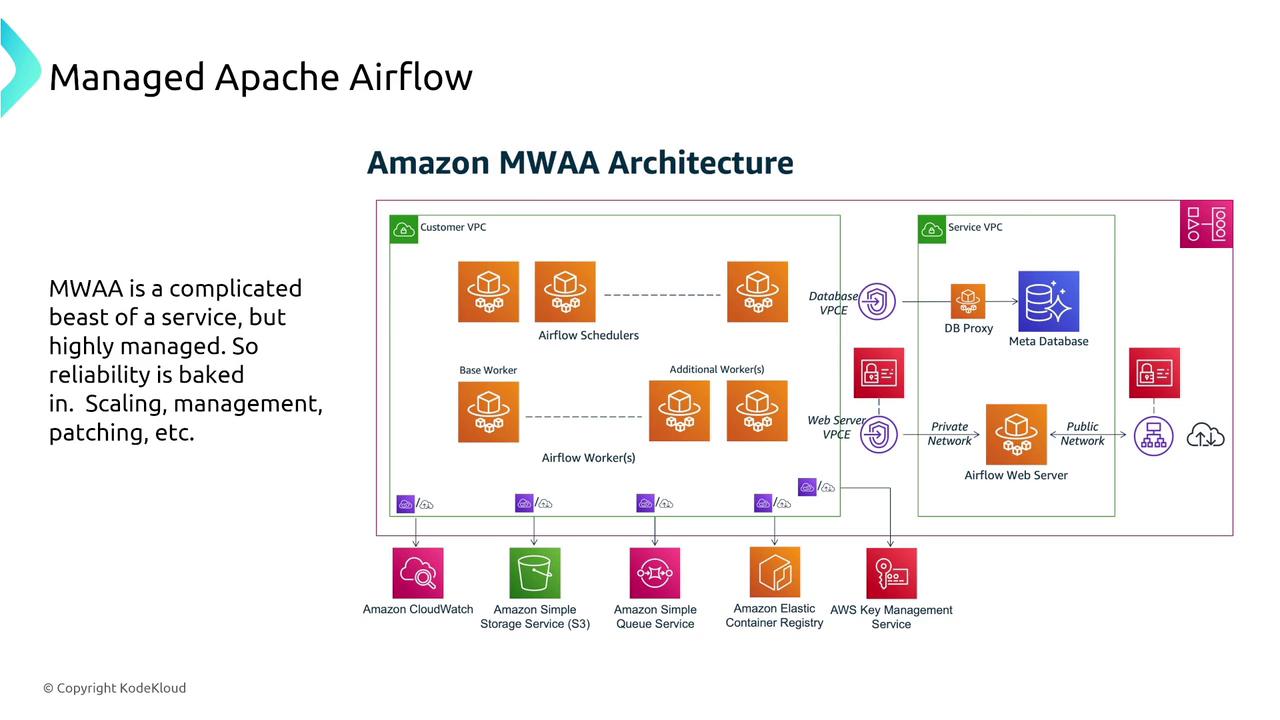
Simple Workflow Service (SWF) and Managed Apache Airflow
While the Simple Workflow Service (SWF) is an older orchestration solution requiring manual setup and consideration of AZ distribution, it offers reliability for long-running workflows. For modern orchestration demands, Managed Workflows for Apache Airflow (MWAA) provides a scalable, managed solution for complex data orchestration tasks. Airflow automatically retries failed tasks and supports multi-AZ deployments to ensure high availability.