Data Ingestion with Kinesis
Kinesis is a powerful streaming bus service that can handle data in transit with built-in redundancy and automatic scaling. The service achieves scalability by splitting data across multiple shards, each with its own throughput capacity. This allows you to distribute records for independent processing across shards. When your workloads experience fluctuations, enabling auto scaling on your Kinesis shards (based on utilization) ensures that your data stream scales to meet demand.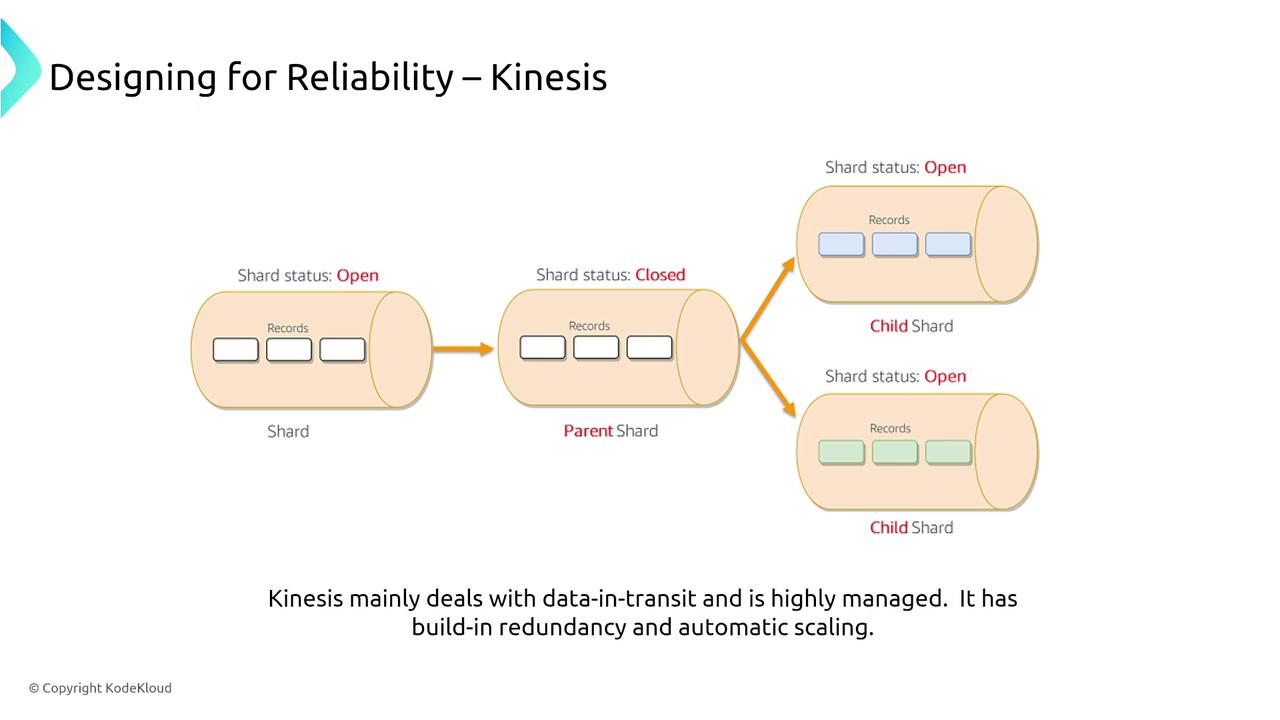


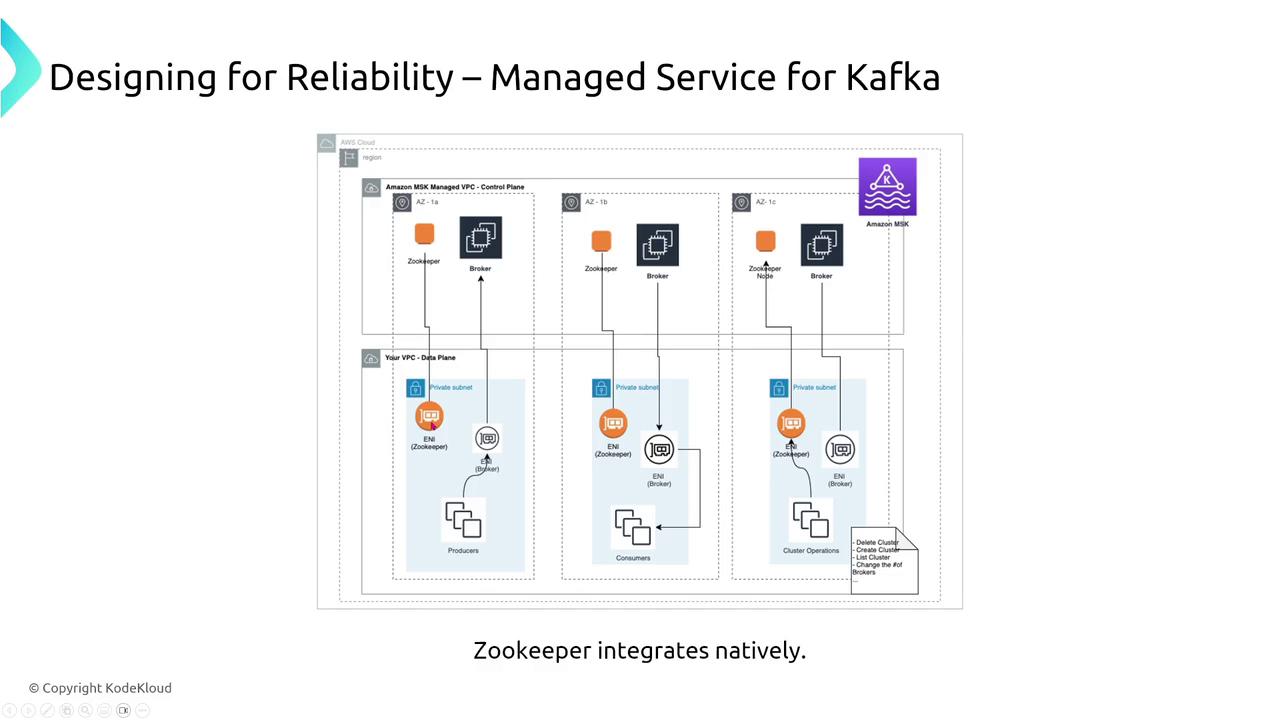
Managed Service for Kafka (MSK)
Amazon MSK provides a managed Kafka experience with added insights that simplify cluster management. The typical data flow in MSK involves:- Incoming data connecting to ZooKeeper.
- Distribution from ZooKeeper to dedicated broker nodes in a cluster.
- Brokers, each defined by its machine size, handling portions of the data load.
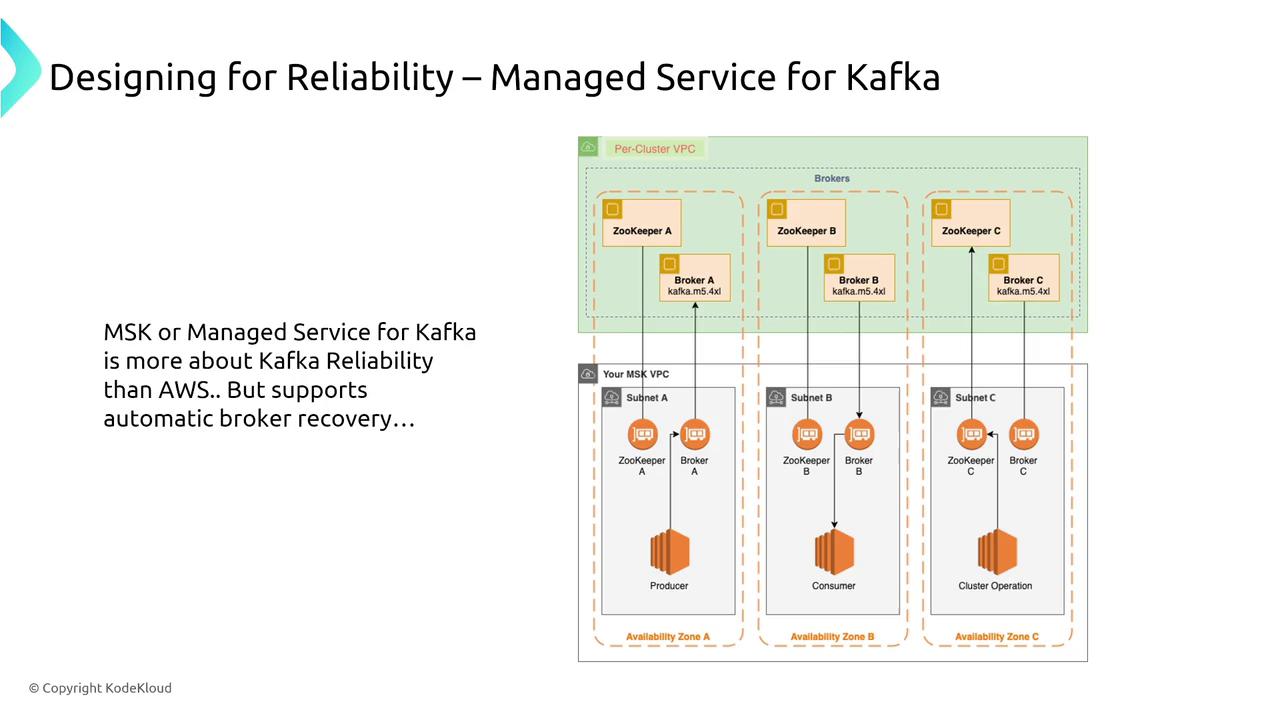
- Auto-detection and replacement of failed brokers (auto-healing).
- Cluster-to-cluster asynchronous replication for cross-region data synchronization.
Data Transformation with Glue and EMR
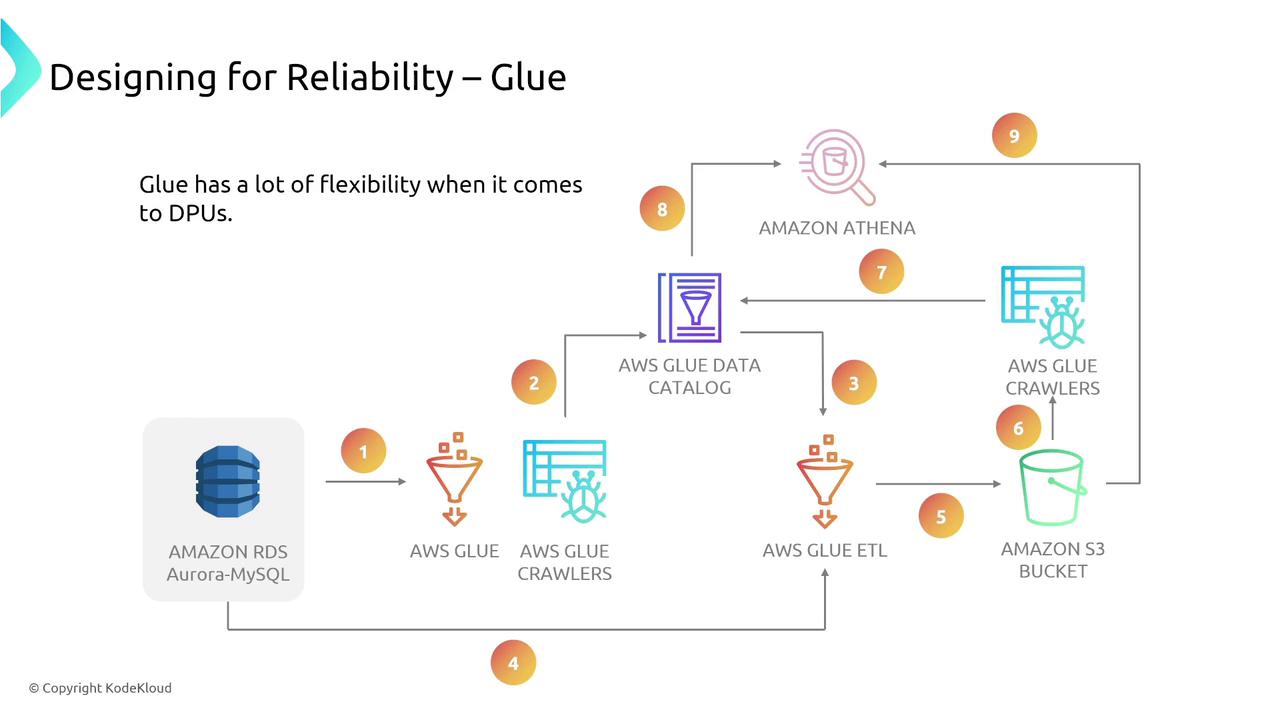
AWS Glue
AWS Glue is a managed ETL (Extract, Transform, Load) service based on open-source PySpark. It automatically crawls your data sources, creates a catalog, and launches ETL jobs. Glue integrates seamlessly with S3, Athena, and QuickSight for processing and visualization. In terms of reliability, AWS Glue:- Supports automated retries on failed jobs.
- Scales compute with Data Processing Units (DPUs) according to job requirements.

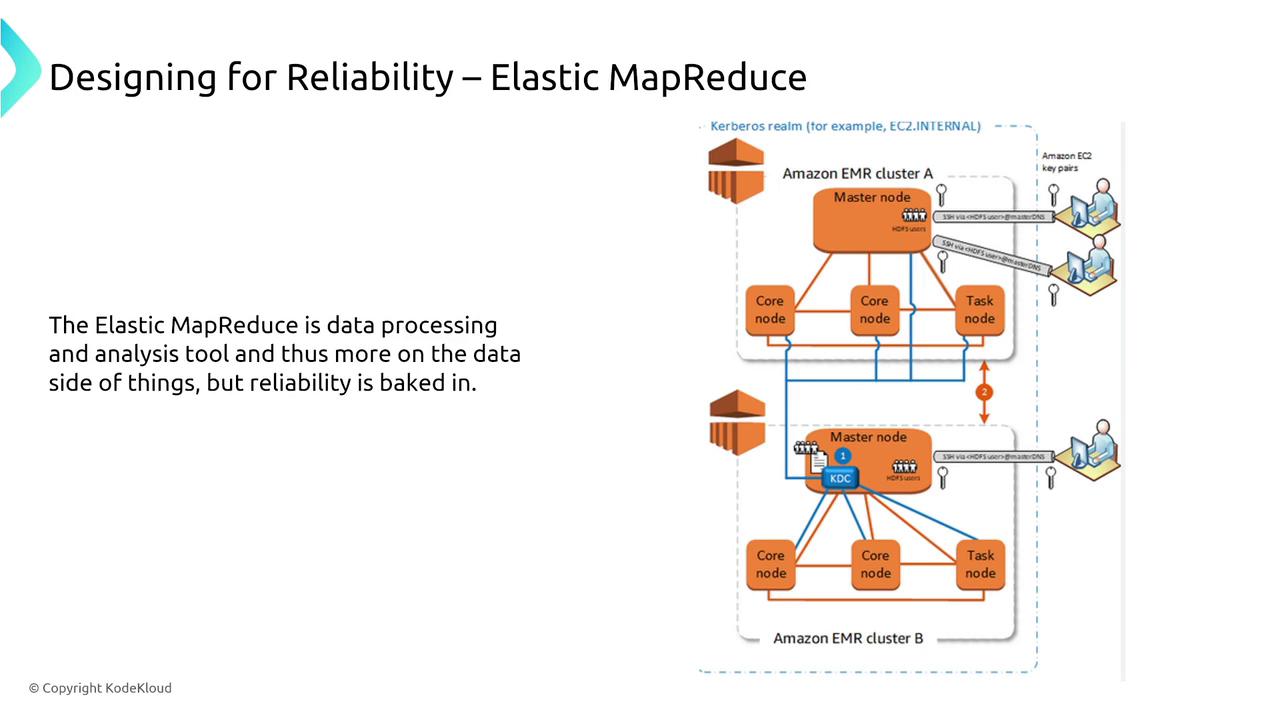
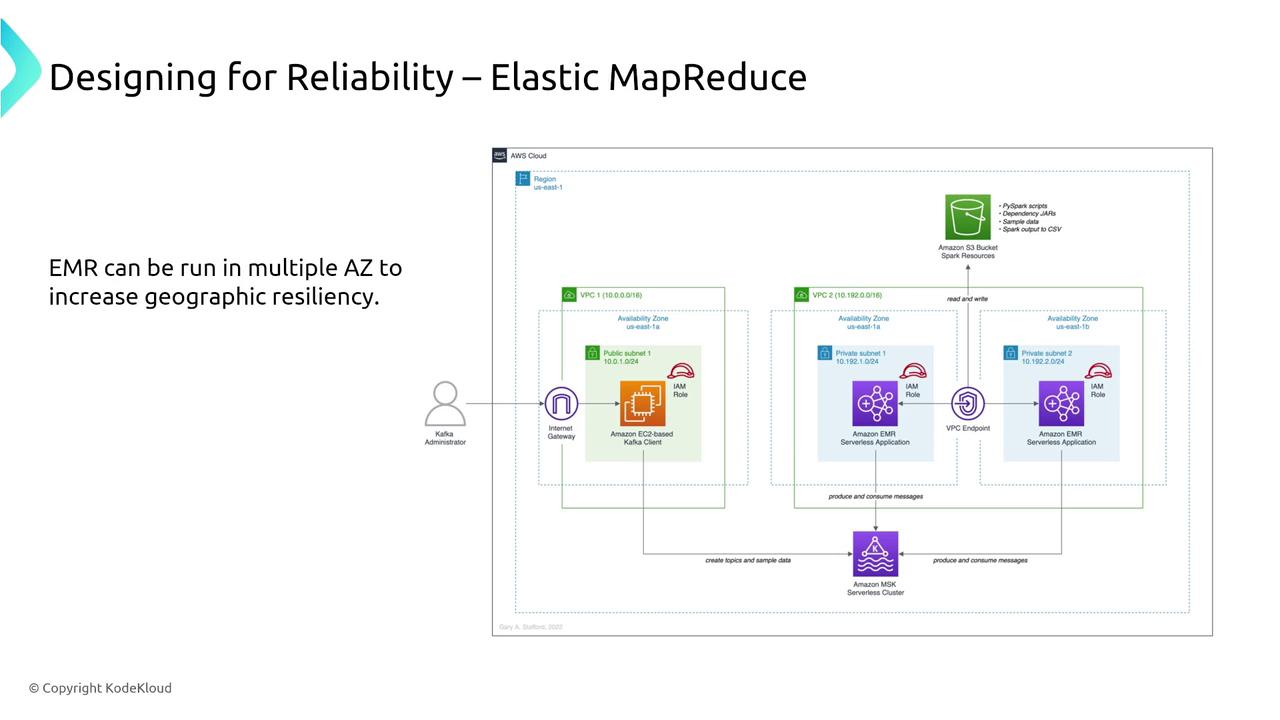
Amazon EMR
Amazon EMR is a managed cluster service that supports frameworks such as Hadoop, MapReduce, and Spark. Reliability is enhanced through:- Node redundancy by deploying multiple primary nodes.
- Resource management using Yarn.
- Multi-AZ deployments to provide geographic resiliency.
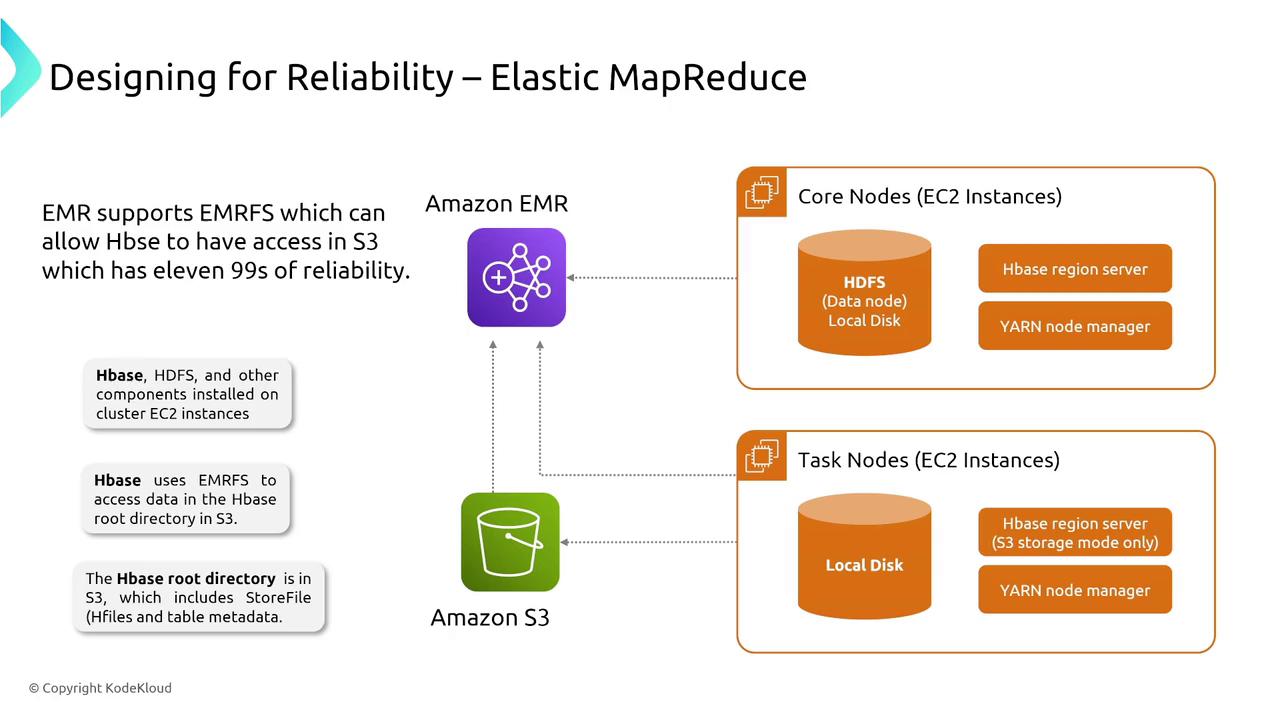
Data Preparation with Glue DataBrew
AWS Glue DataBrew is a fully managed service for data preprocessing, enrichment, and transformation. It streamlines tasks such as filling missing values and computing averages. While DataBrew supports automatic job retries, it is designed with minimal configuration options to simplify your workflow.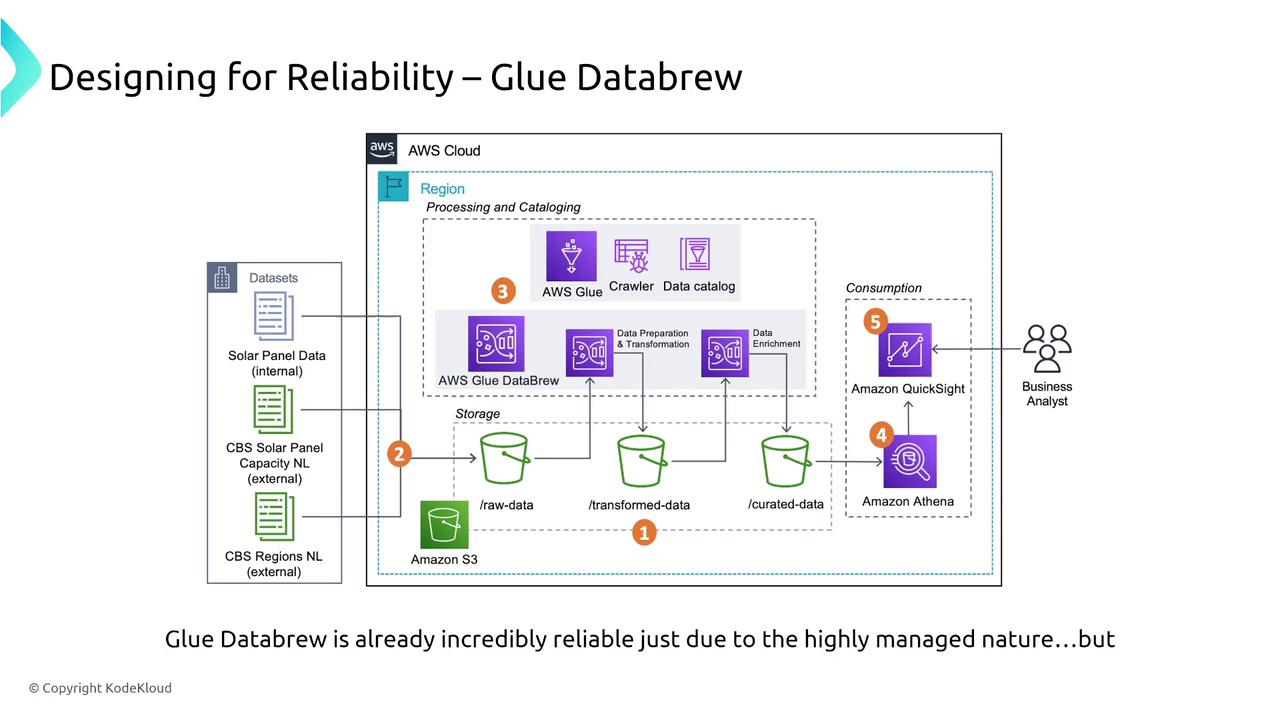

Data Storage and Presentation
Lake Formation
AWS Lake Formation simplifies setting up a secure data lake using S3, Glue, EMR, and other services under one management pane. However, its reliability largely depends on the underlying services like S3.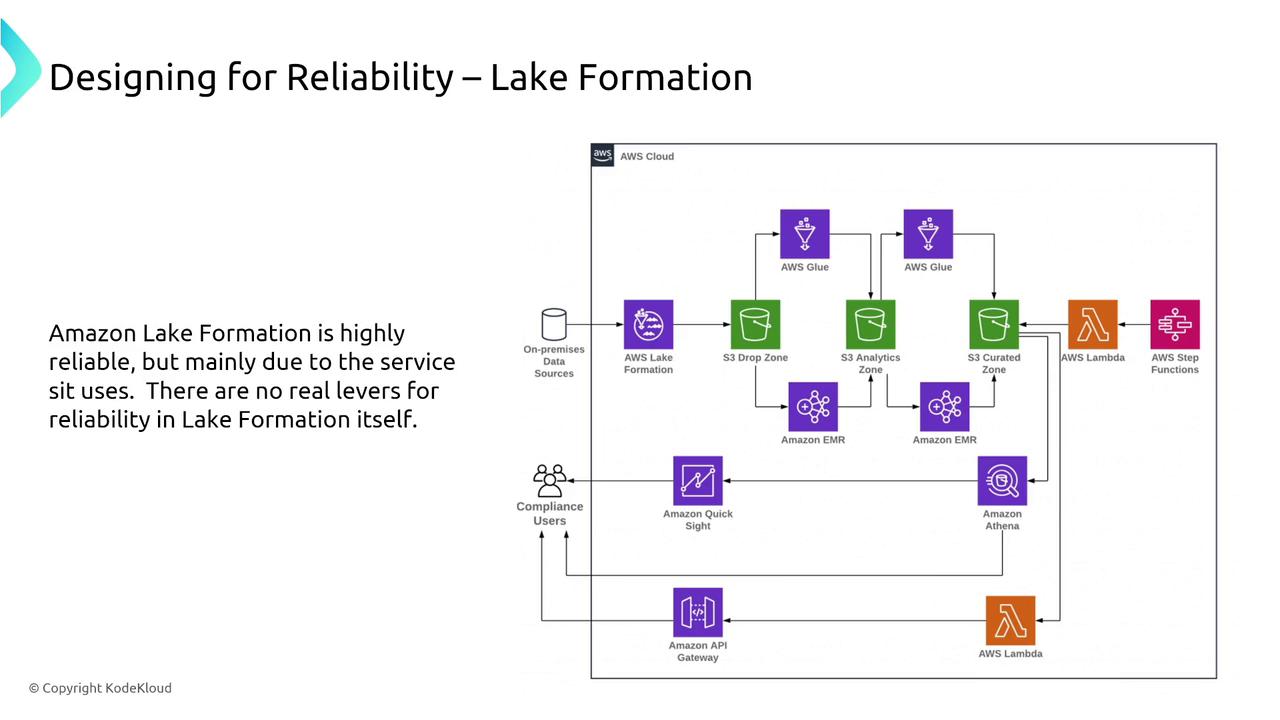
Amazon Athena
Amazon Athena is a serverless query service that operates on data stored in S3 and other sources. It provides resilient and scalable query capabilities with minimal configuration—making it ideal for querying large datasets reliably.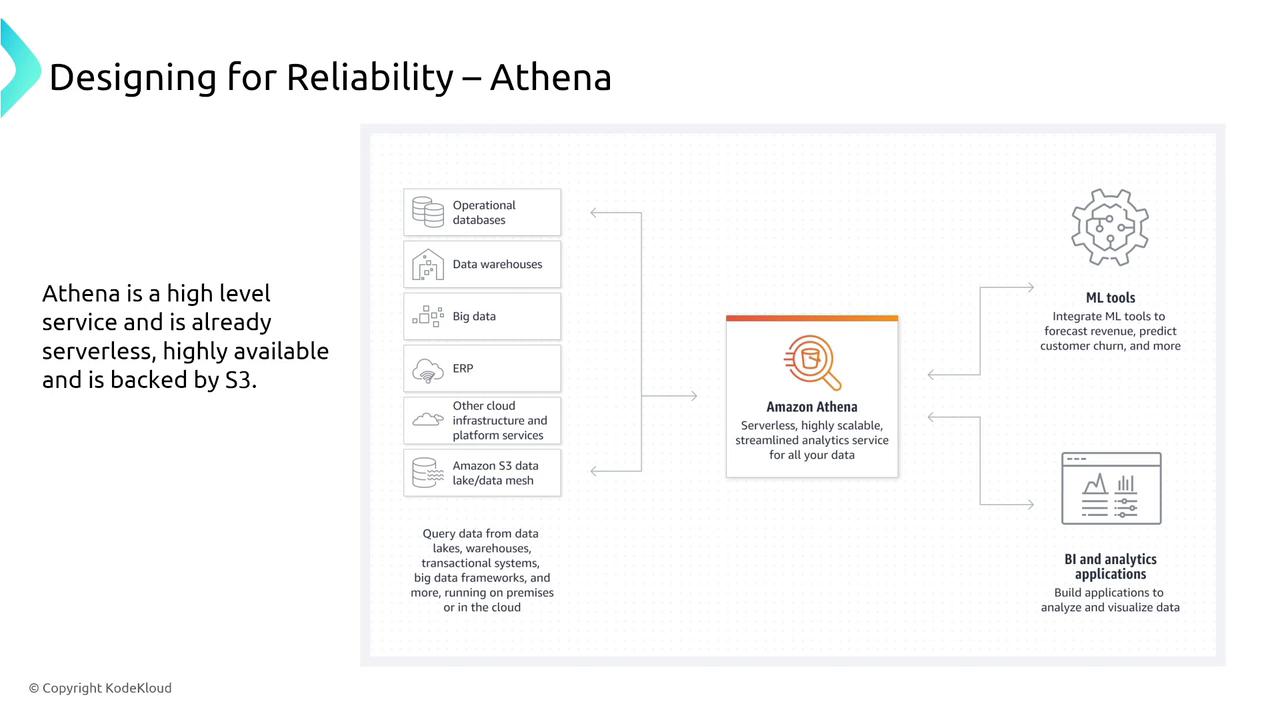
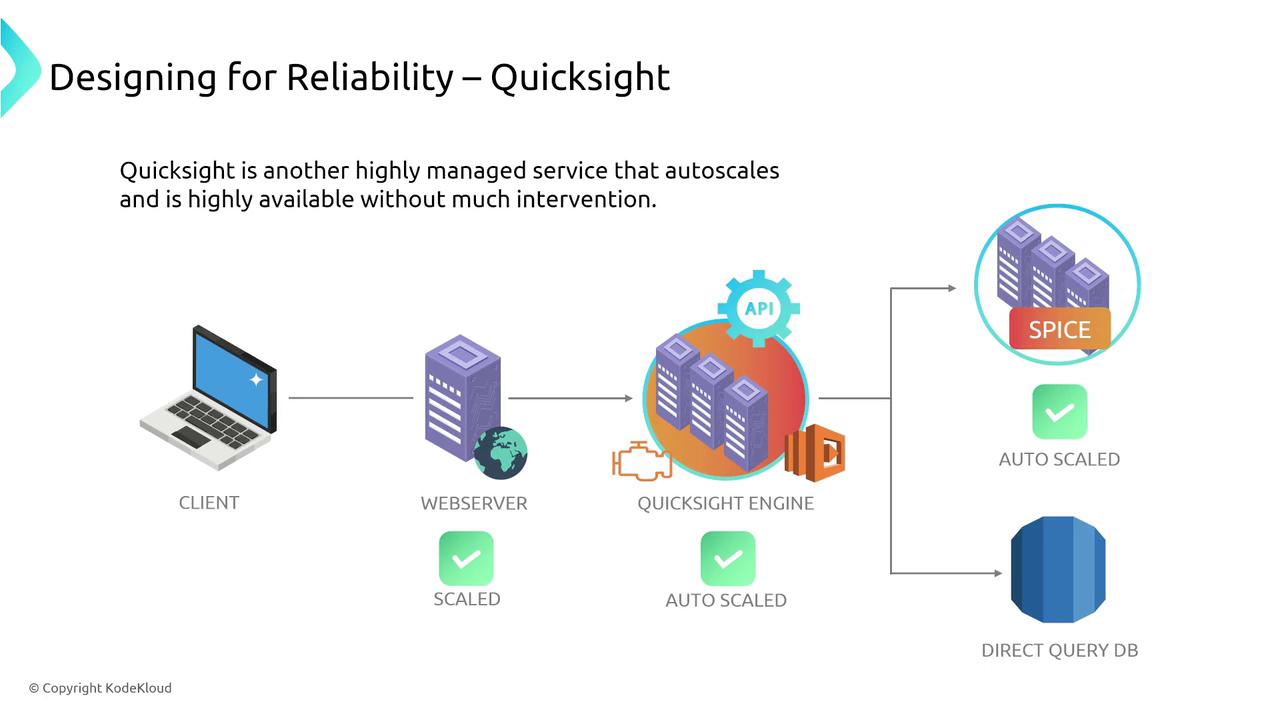
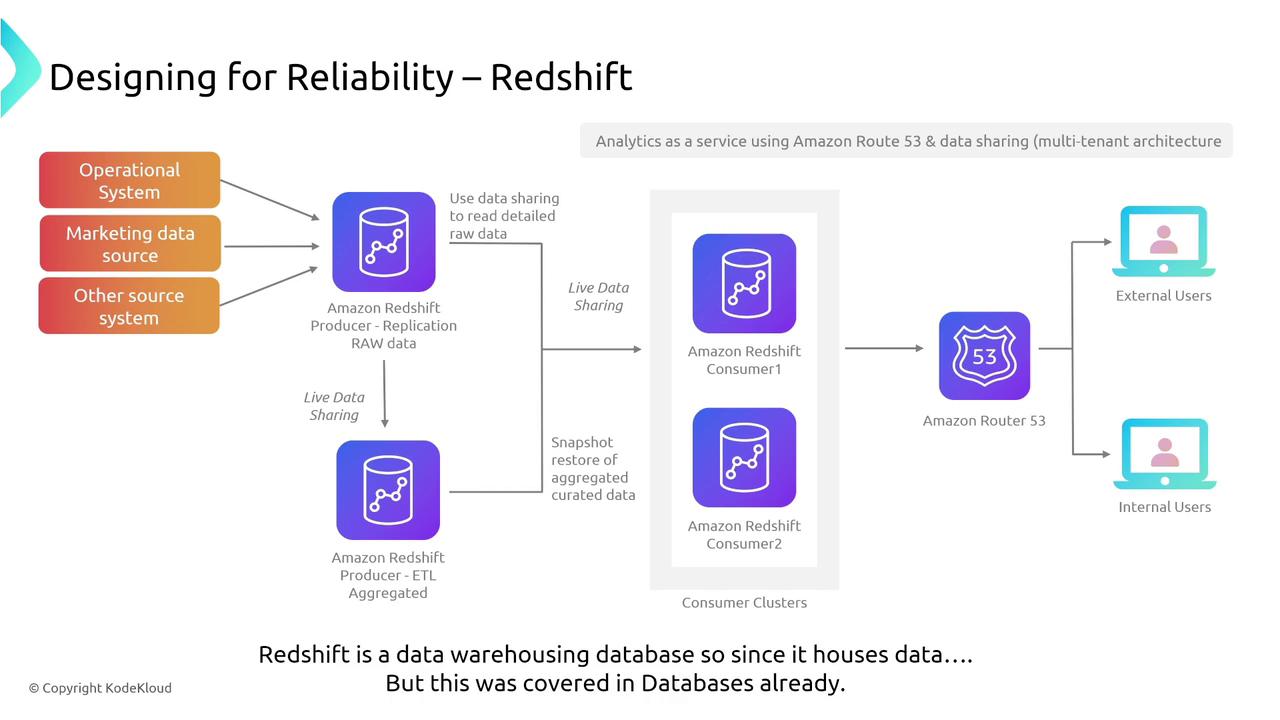
Machine Learning and AI Services
SageMaker
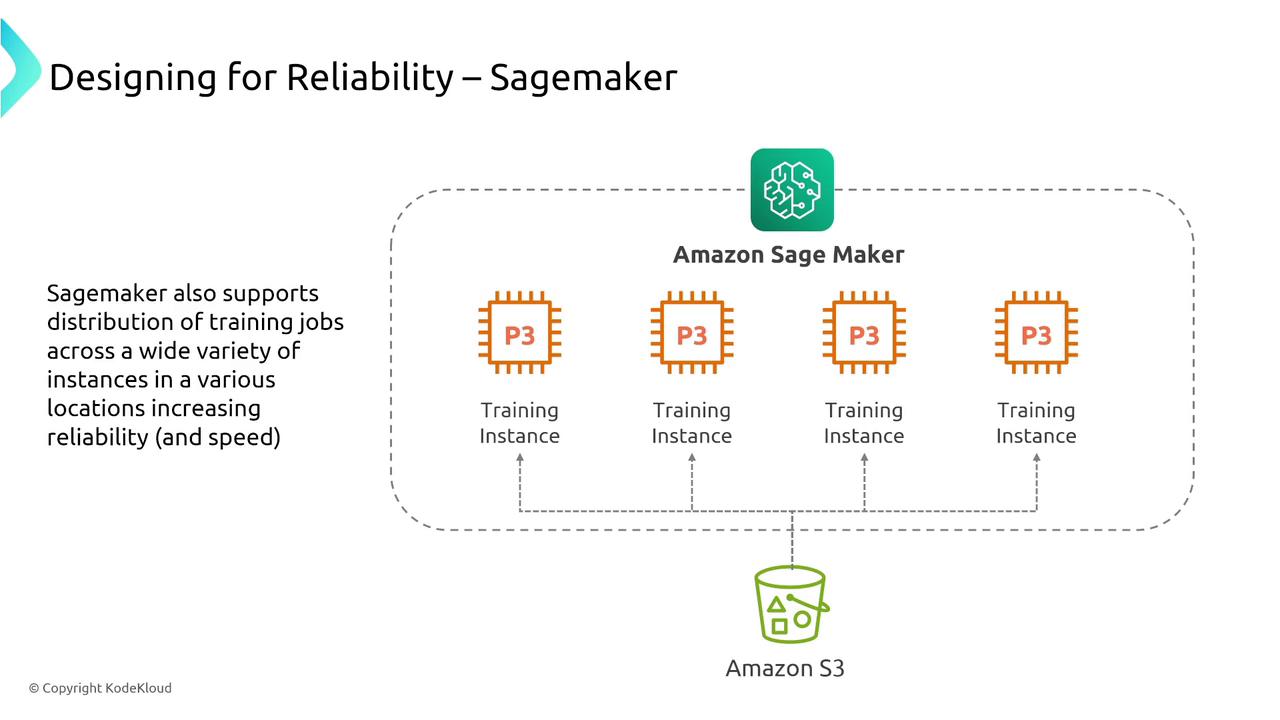
Amazon SageMaker supports model training, hosting, and testing with instance-based infrastructure. To enhance reliability, it implements strategies such as canary testing, load balancing, and multi-instance deployment. SageMaker also supports A/B testing for model evaluation and distributed training across multiple instances.

Highly Managed Services: Rekognition, Polly, Lex, and Comprehend
Highly managed AWS services like Amazon Rekognition (image and video analysis), Polly (text-to-speech), Lex (chatbots), and Comprehend (NLP) are designed to be inherently reliable. They handle auto scaling, retries, and failover internally. For monitoring:- Use CloudWatch metrics and logs to track performance and errors.
- Enable AWS X-Ray tracing for deeper insight where needed.
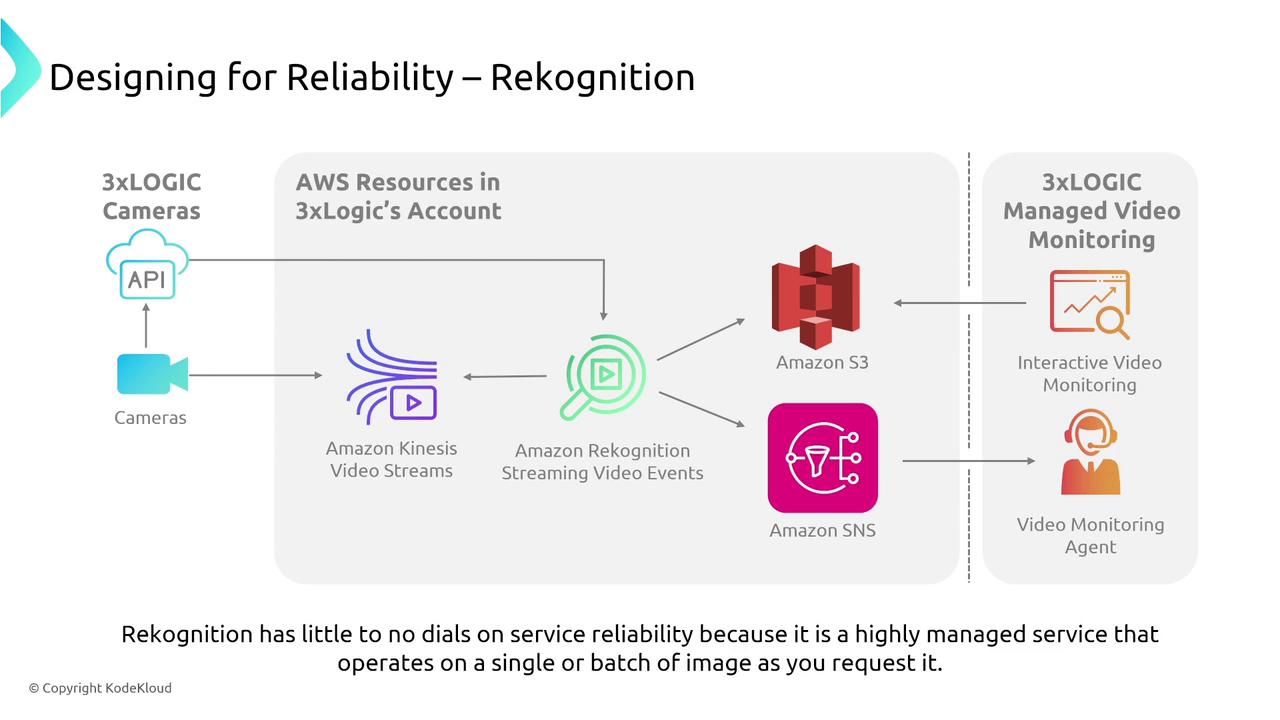
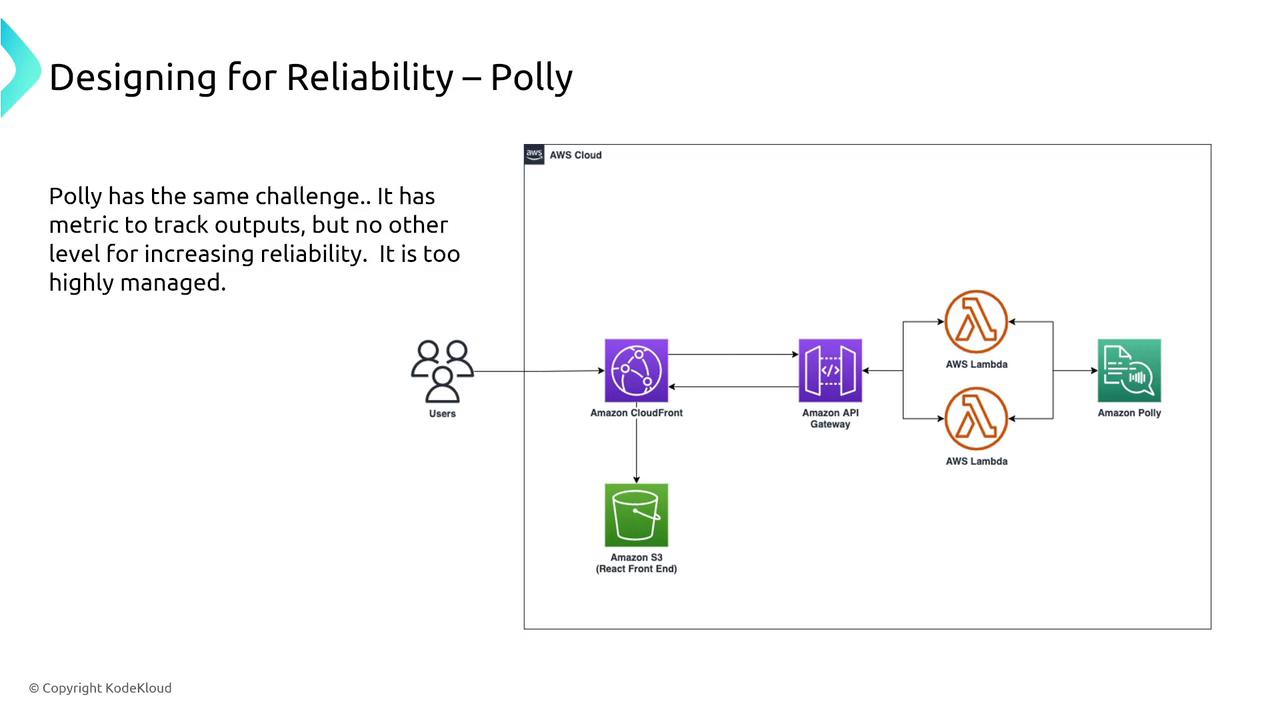
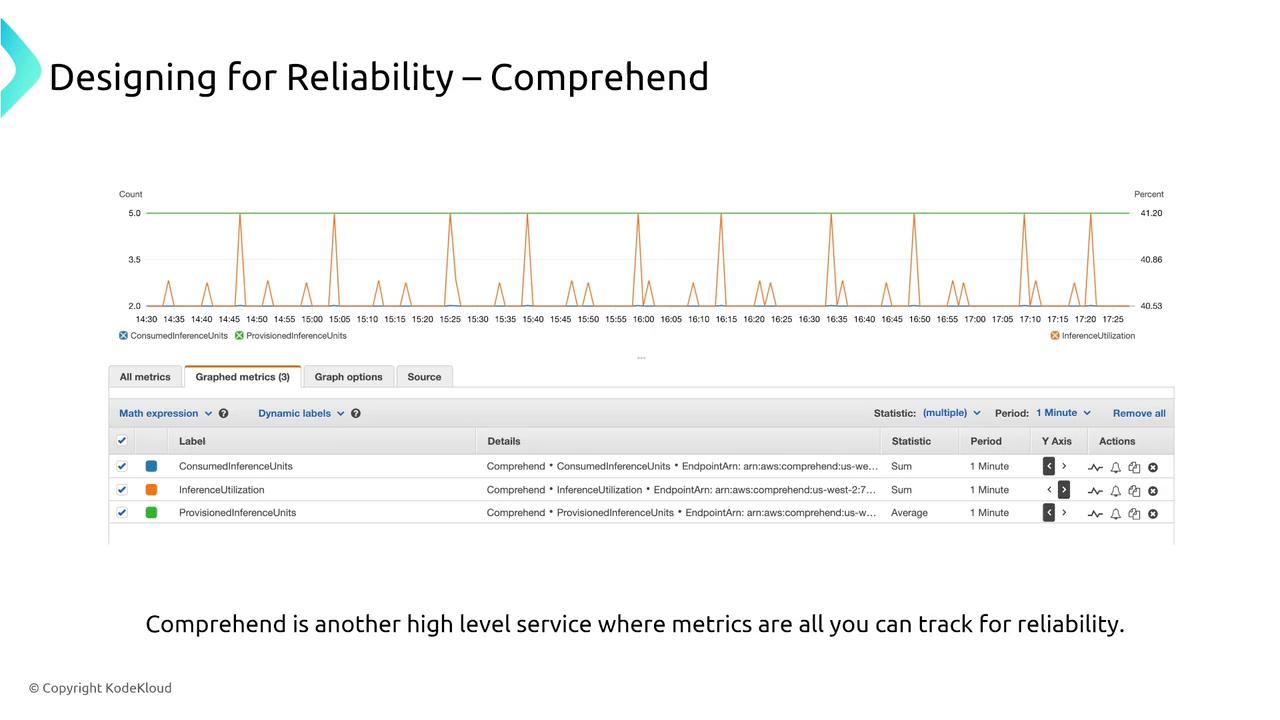
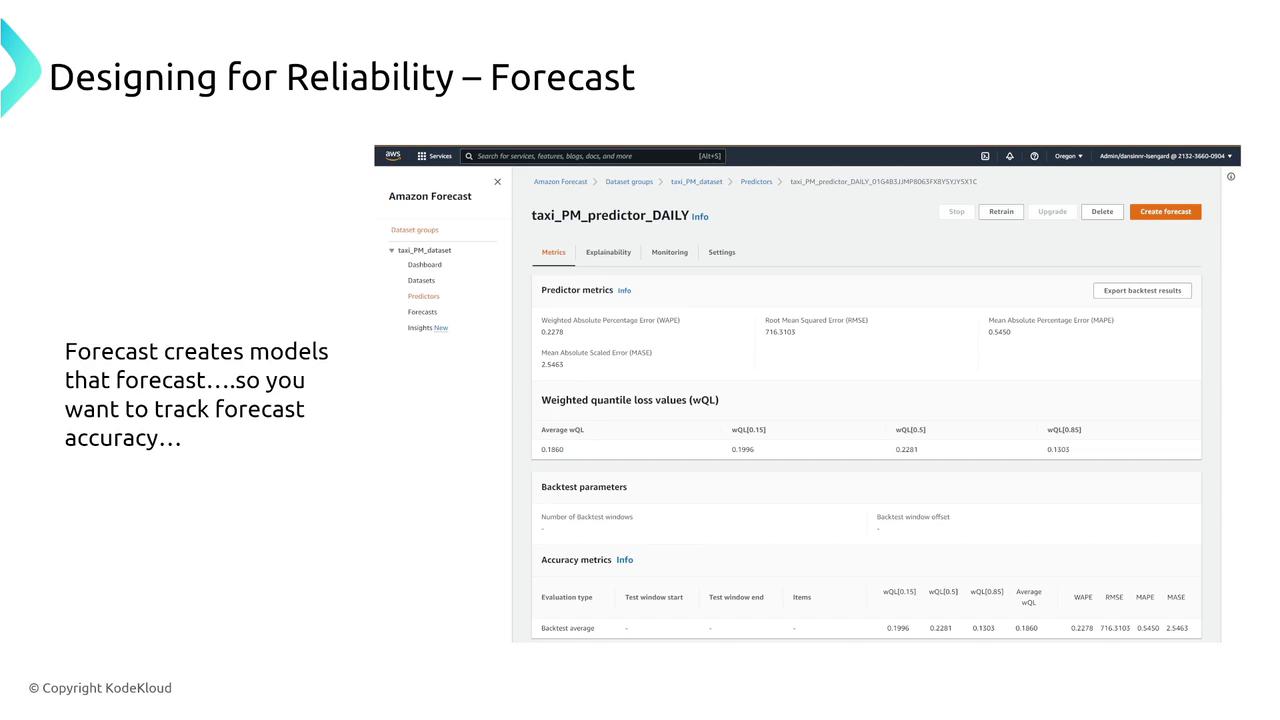
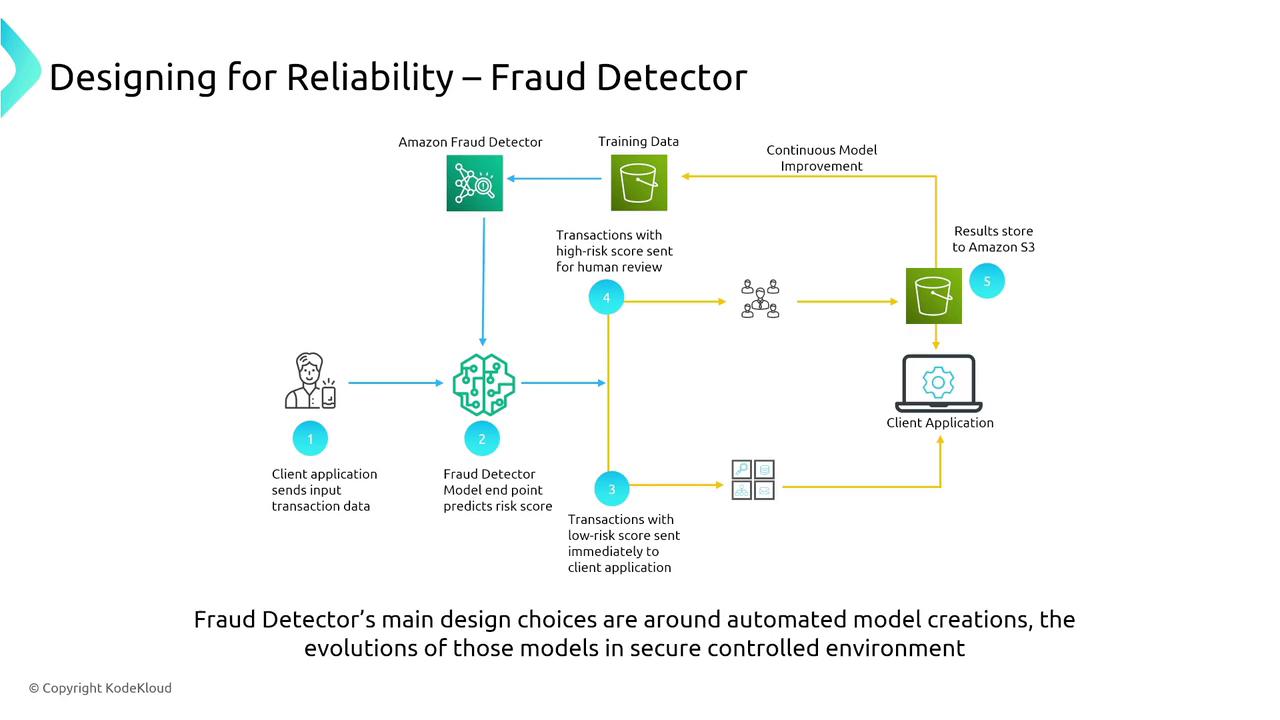
Augmented AI and Fraud Detection
Augmented AI (A2I) introduces a human review stage into machine learning outputs, adding an extra layer of reliability. This service integrates human insights with automated predictions for improved outcomes.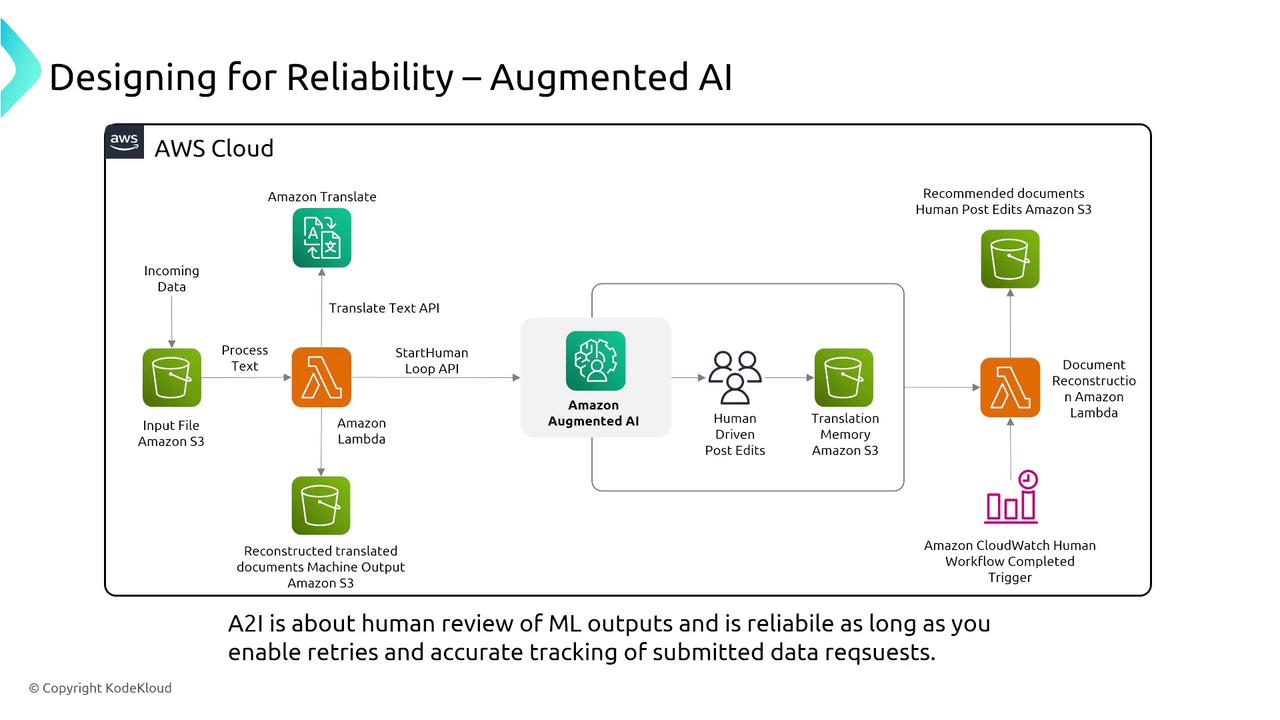
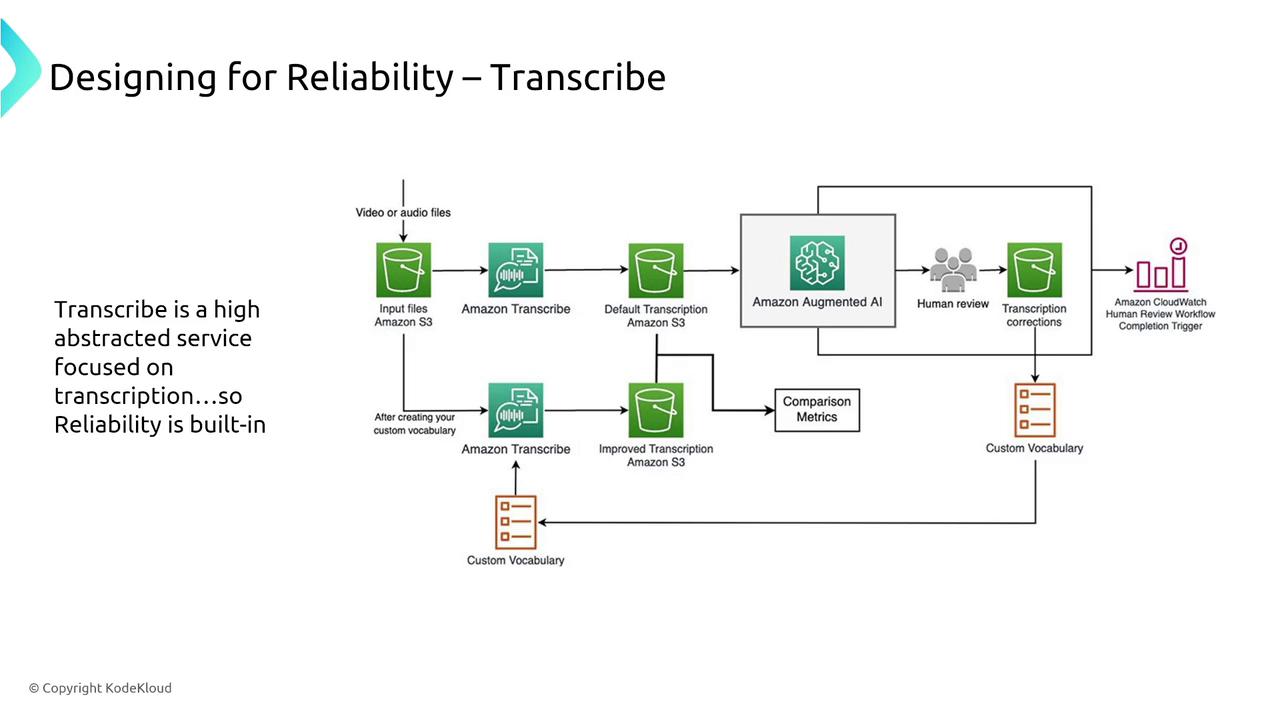
Language Services: Transcribe, Translate, and Textract
- Amazon Transcribe converts audio to text at scale with built-in reliability features. Using Transcribe for tasks like video captioning leverages its API-driven, resilient design.

- Amazon Translate provides robust language translation with automatic recovery, retries, and failover capabilities.
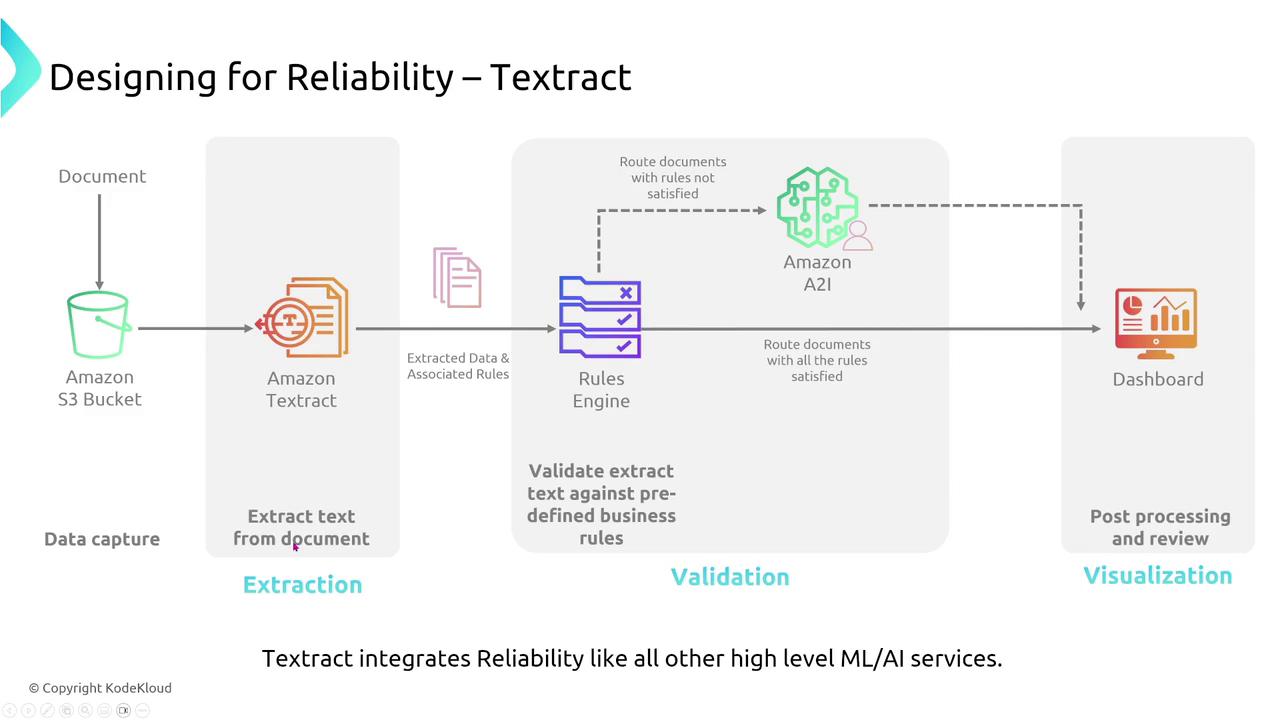
- Amazon Textract extracts text from documents and images with high accuracy and reliability. Integrated monitoring with CloudWatch and AWS X-Ray (if needed) provides further operational visibility.
Summary
This article covered a broad range of AWS services—from data ingestion with Kinesis and MSK, through transformation with Glue and EMR, to advanced machine learning and AI services like SageMaker, Rekognition, Polly, Lex, Comprehend, Transcribe, Translate, and Textract. Key reliability features include:- Auto scaling and automatic recovery.
- Cross-AZ and multi-region deployments.
- Integrated monitoring using CloudWatch and CloudTrail.
