Shared Responsibility in Managed Services
As you transition from managing infrastructure to using managed services, your role in ensuring reliability evolves. With traditional compute services like EC2, you assume a larger share of the reliability burden, whereas serverless options handle many resiliency aspects automatically.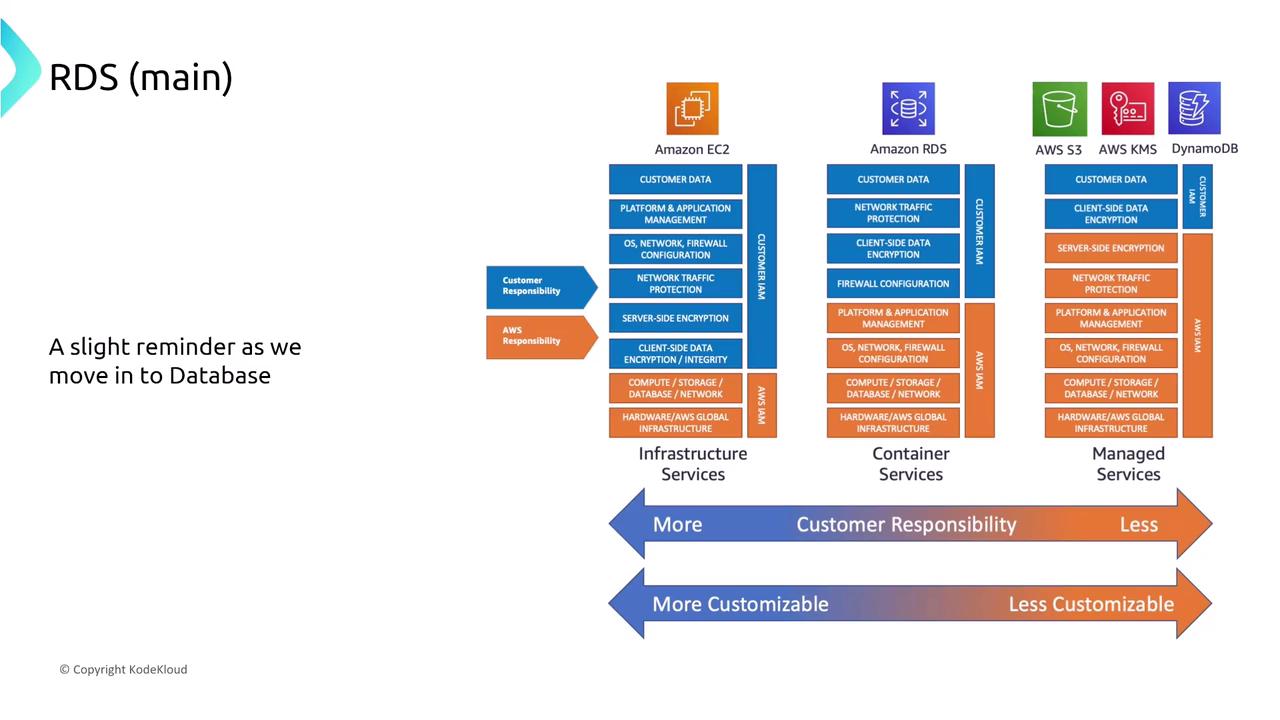
Amazon RDS and Relational Databases
Amazon RDS simplifies managing relational databases by handling tasks like patching, backup, and replication. When designing for high availability and performance, take advantage of features such as read replicas and Multi-AZ deployments.Read Replicas and High Availability
Utilize read replicas to offload read traffic from the primary (writer) instance. For example, you can configure DNS endpoints as follows:• read.myapplication.companyname.com (reader endpoint)
• rewrite.myapplication.companyname.com (writer endpoint) Keep in mind that replication for read replicas is asynchronous. In one production scenario, offloading 80% of the traffic from the primary server improved overall performance. In situations like IBM DB2 on RDS, a production setup might require both high availability (HA) and resiliency. The recommended approach is a Multi-AZ configuration with synchronous replication. Using a cluster instance with two backup copies further boosts resiliency.

Upgrading Using Read Replicas
A best practice for database upgrades is to first upgrade the read replica and then promote it to primary. This minimizes downtime and helps ensure consistency during the upgrade process.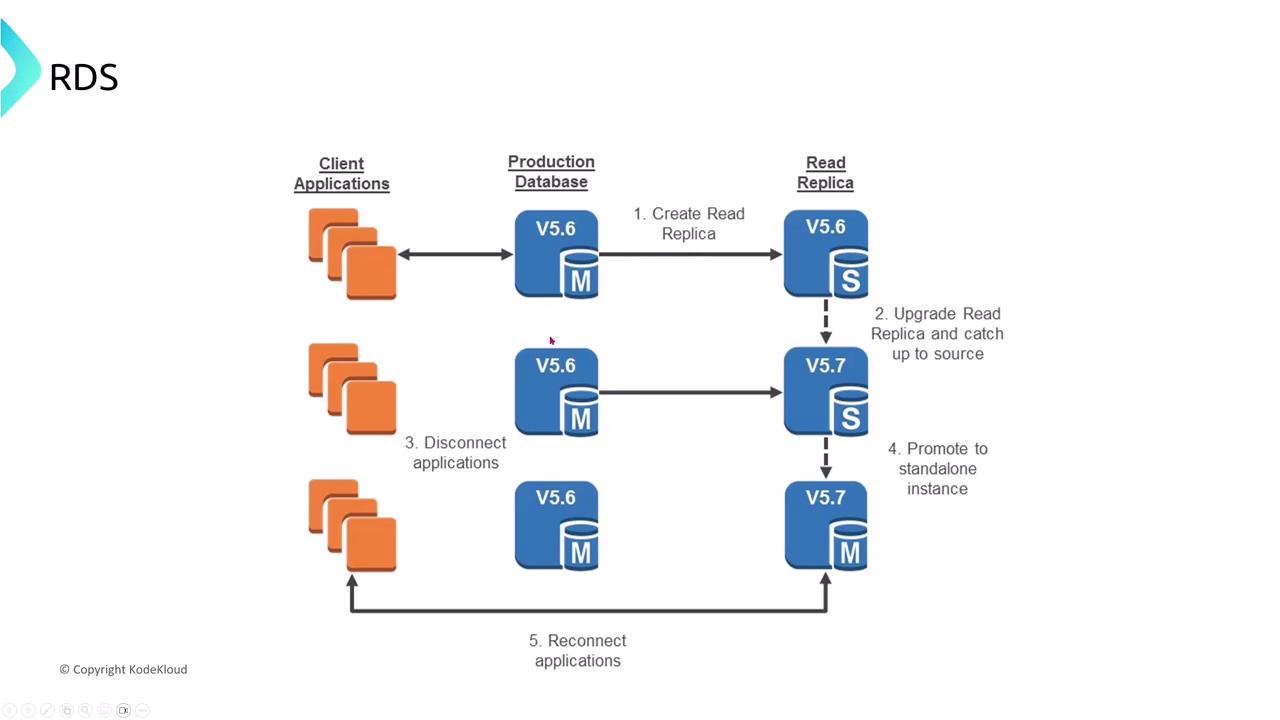

Multi-AZ Deployments
A Multi-AZ configuration keeps a synchronous secondary (or multiple readable standbys) alongside the primary instance. In case of a failure, a standby instance is automatically promoted to primary, minimizing downtime without manual DNS updates.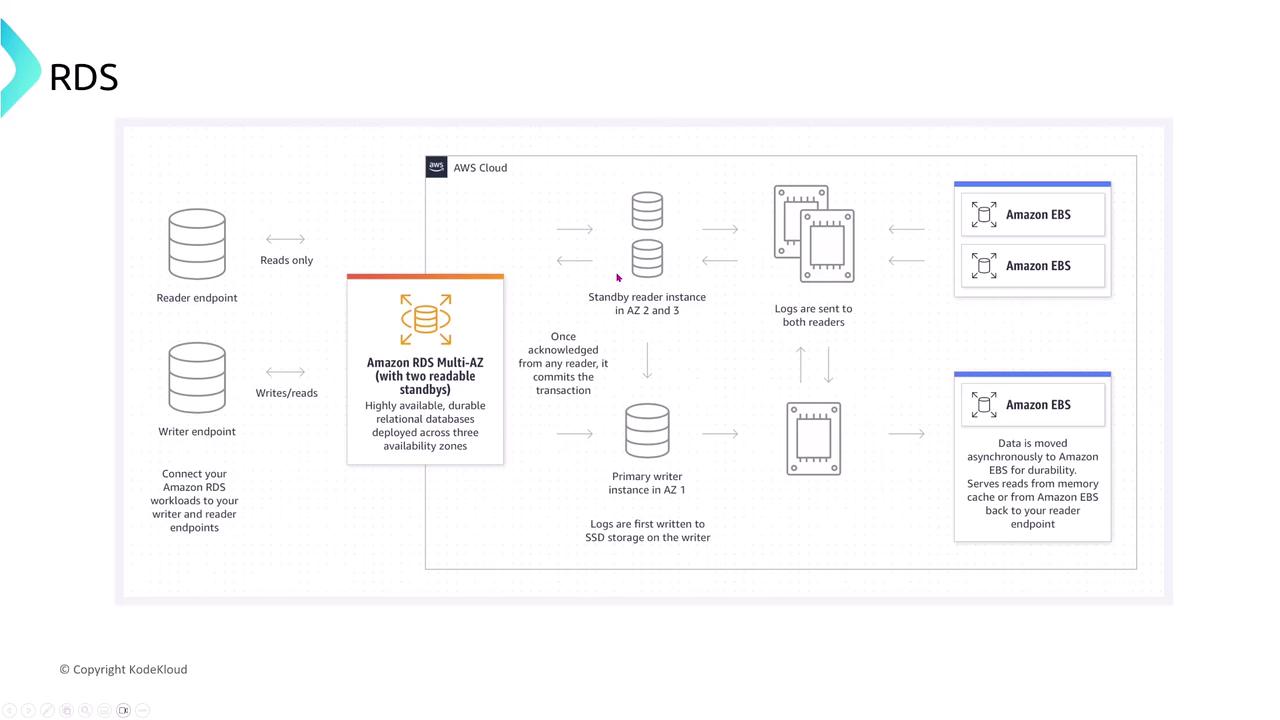

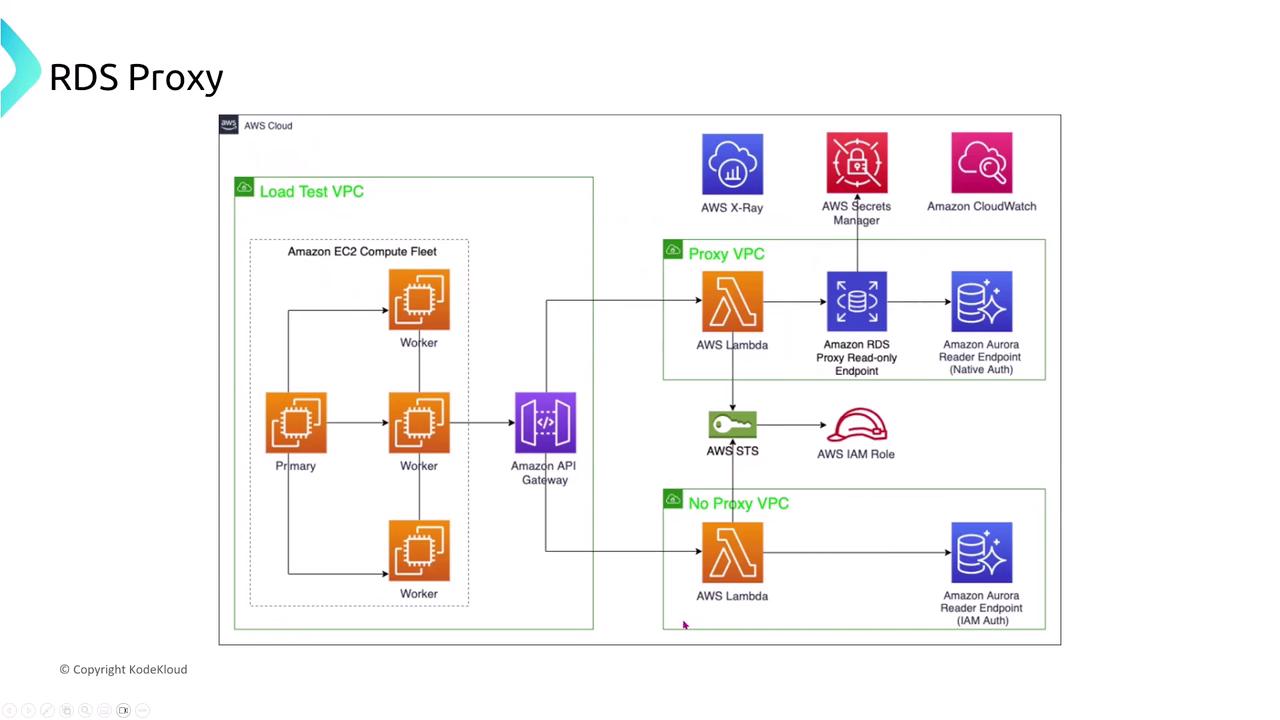
RDS Proxy
RDS Proxy serves as a connection pool between your application and RDS instances. It maintains persistent connections and routes read-only and read-write requests, improving failover times and decoupling your application from direct database dependencies.

Amazon Aurora
Aurora is an enhanced, cloud-native relational database offering compatibility with PostgreSQL and MySQL. It replicates data across multiple Availability Zones (with up to six copies) and supports automatic failover. For disaster recovery, Aurora Global Database replication is available.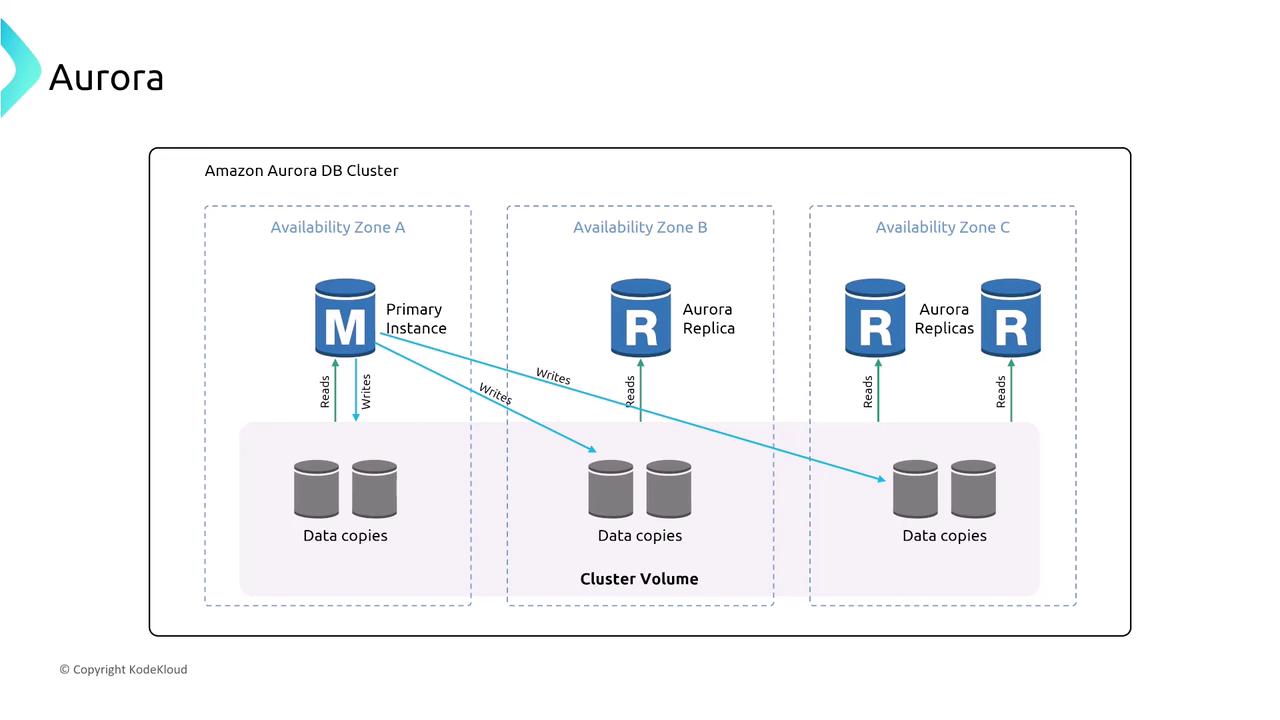



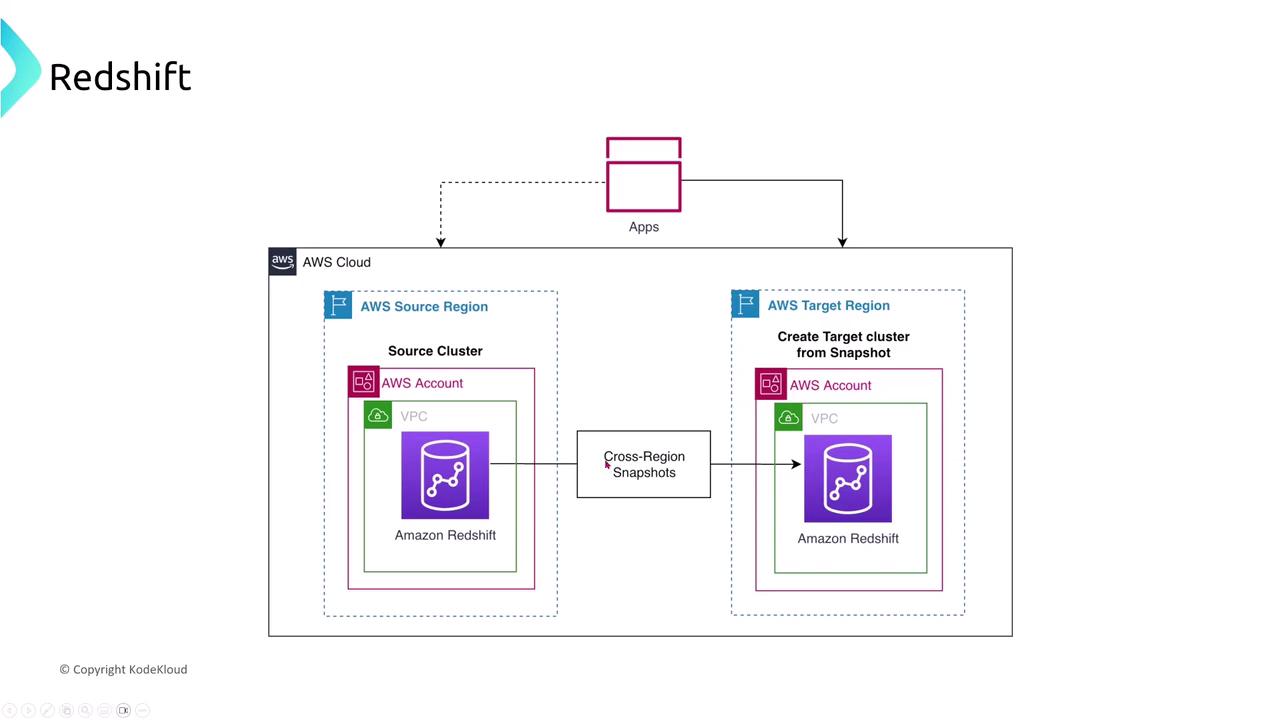
Amazon Redshift and Redshift Serverless
Amazon Redshift is AWS’s data warehousing solution, enabling multi-node clusters with a dedicated leader node for high availability and durability. The new Redshift Serverless automatically adjusts capacity based on query workload.

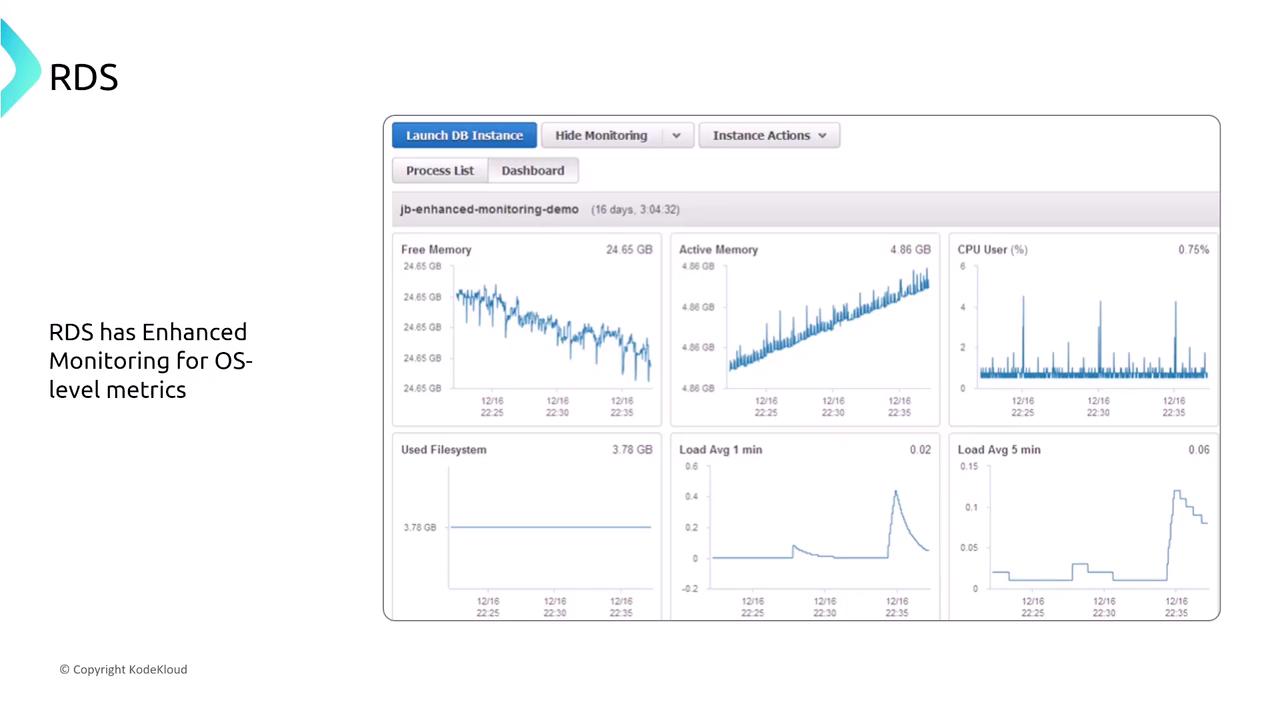
Monitoring and Logging for RDS
Amazon RDS integrates with CloudWatch for performance metrics and CloudTrail for audit logs. Enhanced monitoring provides OS-level metrics (CPU, memory, filesystem stats), while RDS Performance Insights focuses on SQL query performance. Consider these SQL queries used for troubleshooting and optimization:
NoSQL Options
Amazon DynamoDB
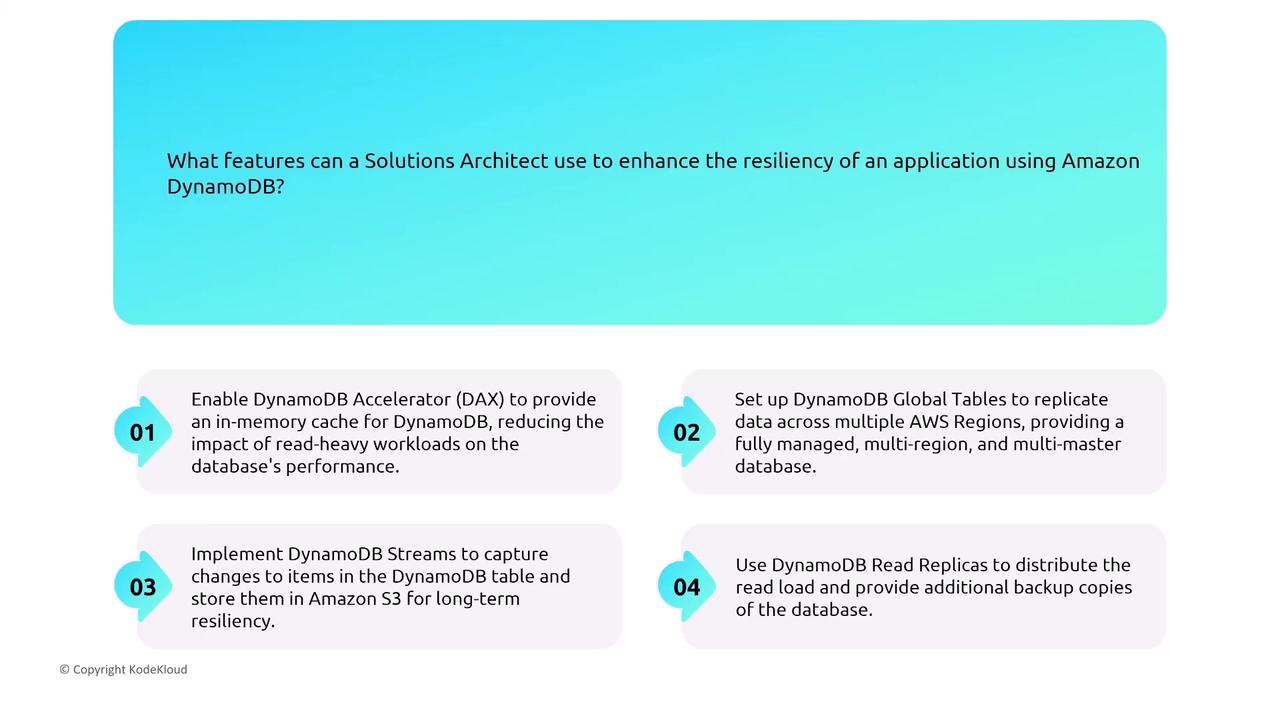
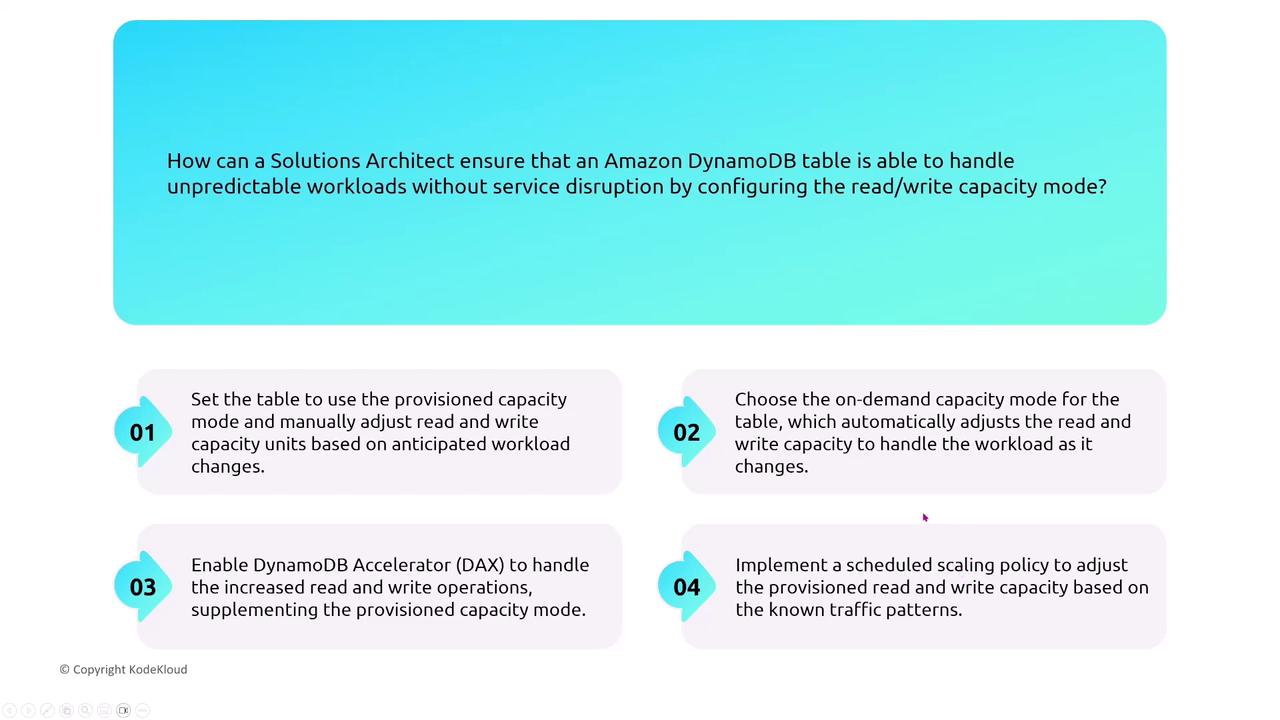
DynamoDB is AWS’s flagship NoSQL database, offering fully managed services with built-in replication (six copies) across multiple Availability Zones. It supports both on-demand and provisioned capacity modes. For multi-region resiliency, leverage Global Tables, which provide a multi-master solution using asynchronous replication.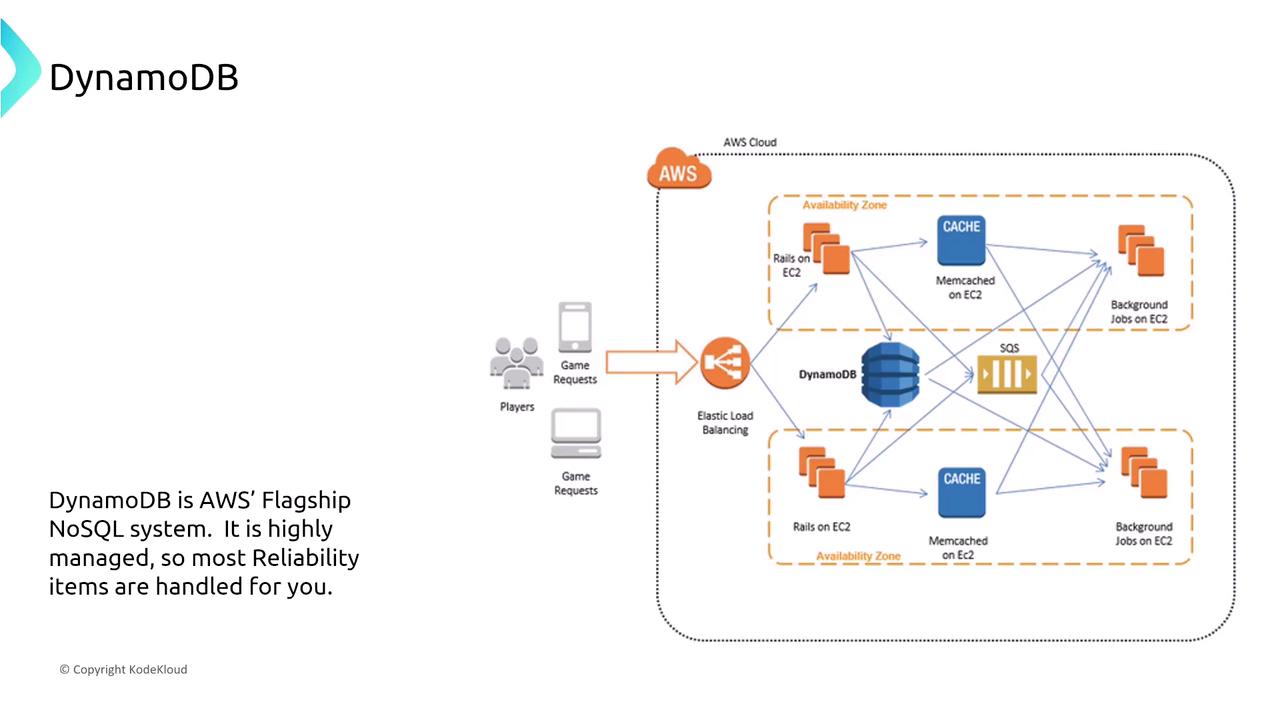

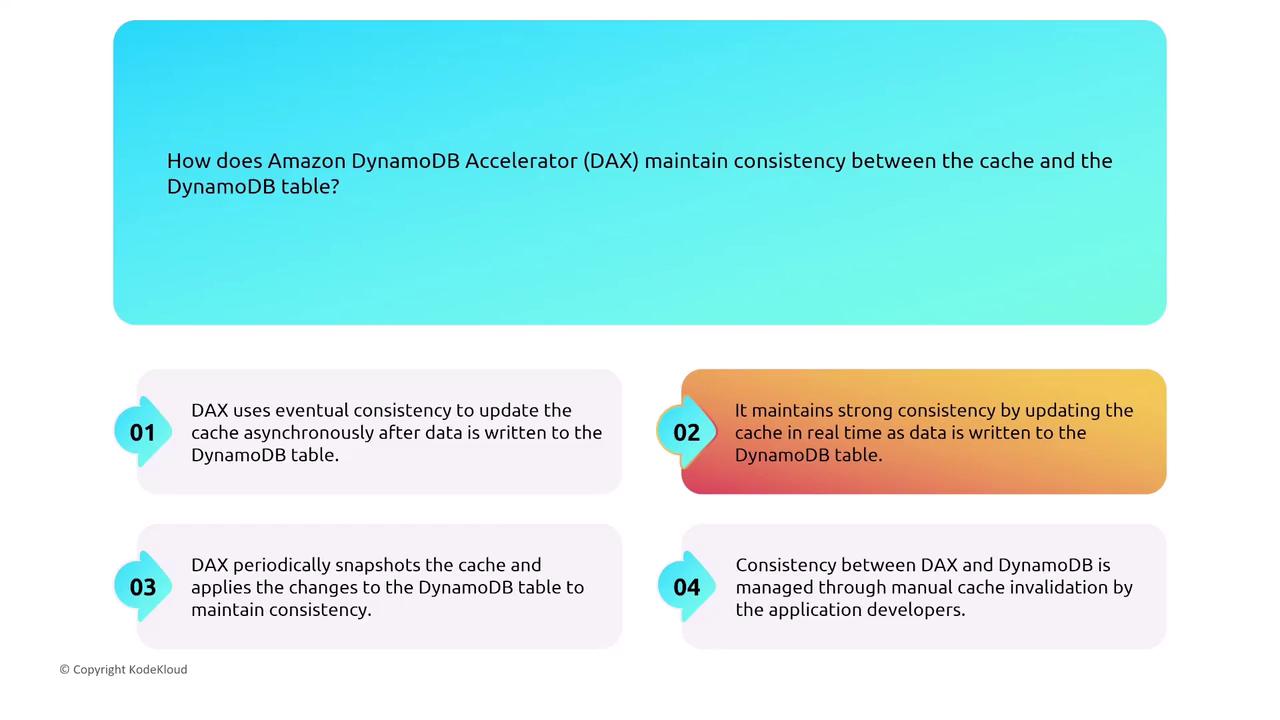
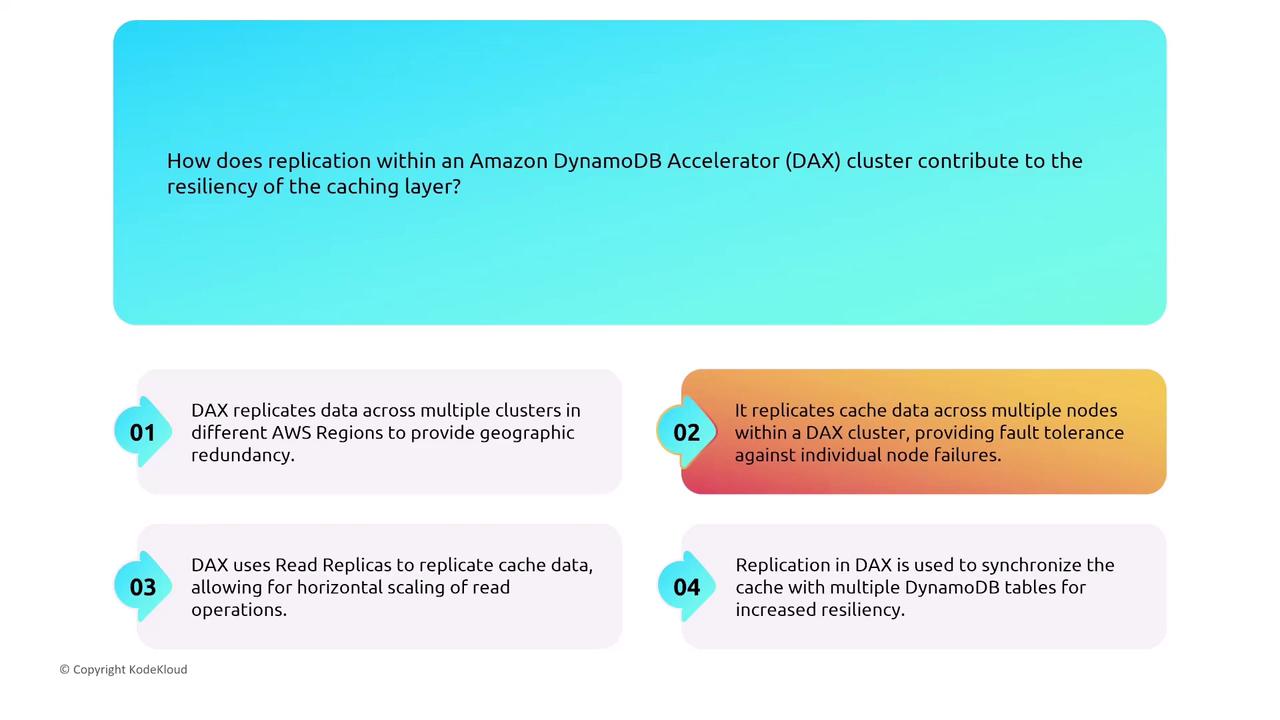
DynamoDB Accelerator (DAX)
DAX serves as an in-memory cache extension for DynamoDB. In the event of a node failure, DAX reroutes read requests quickly and replicates cached data across nodes, ensuring availability and consistency.
OpenSearch and OpenSearch Serverless
OpenSearch, derived from Elasticsearch, is optimized for search and analytics with built-in resiliency features. If a primary node for a shard fails, requests are automatically redistributed to replica shards—with a replica potentially being promoted if necessary.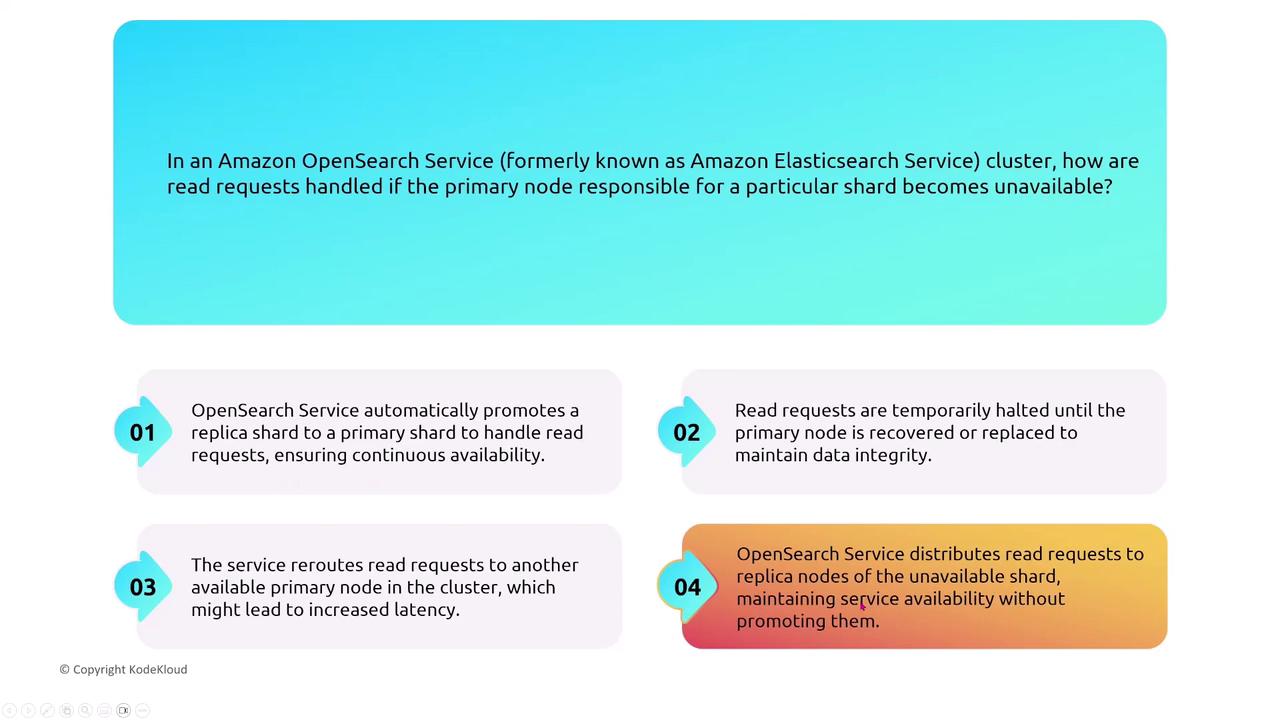
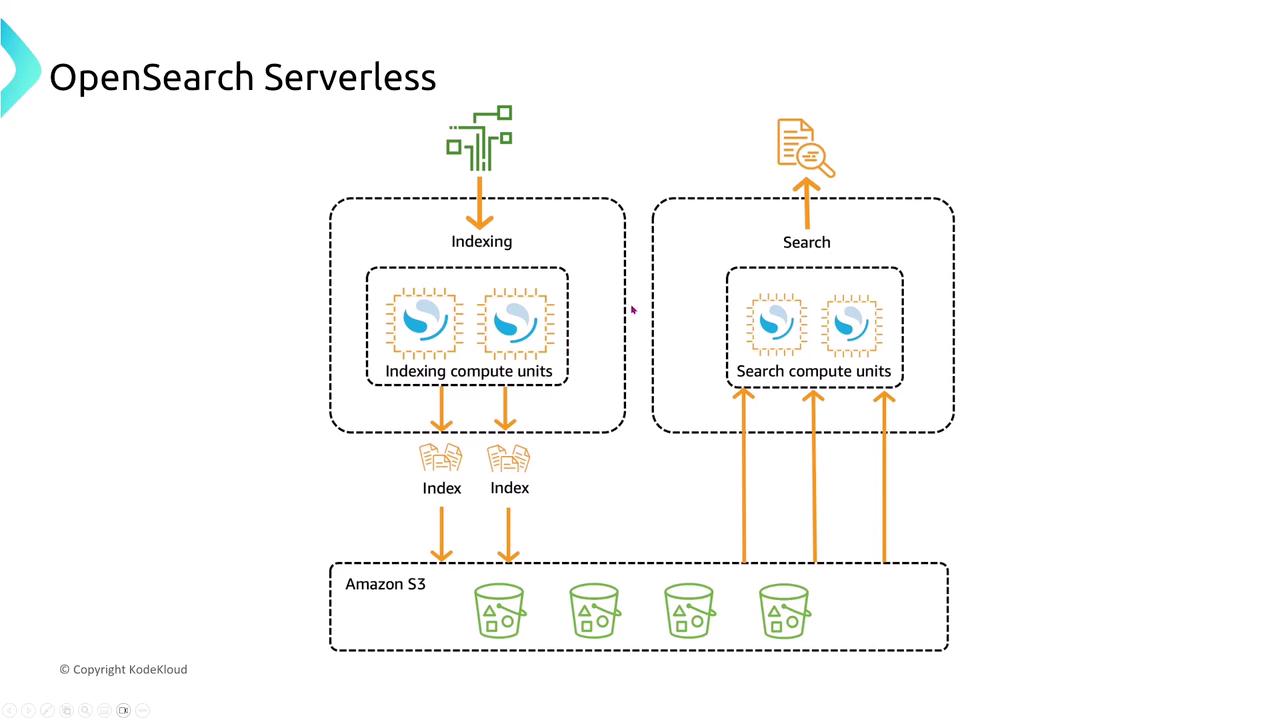
Open Source Database Alternatives
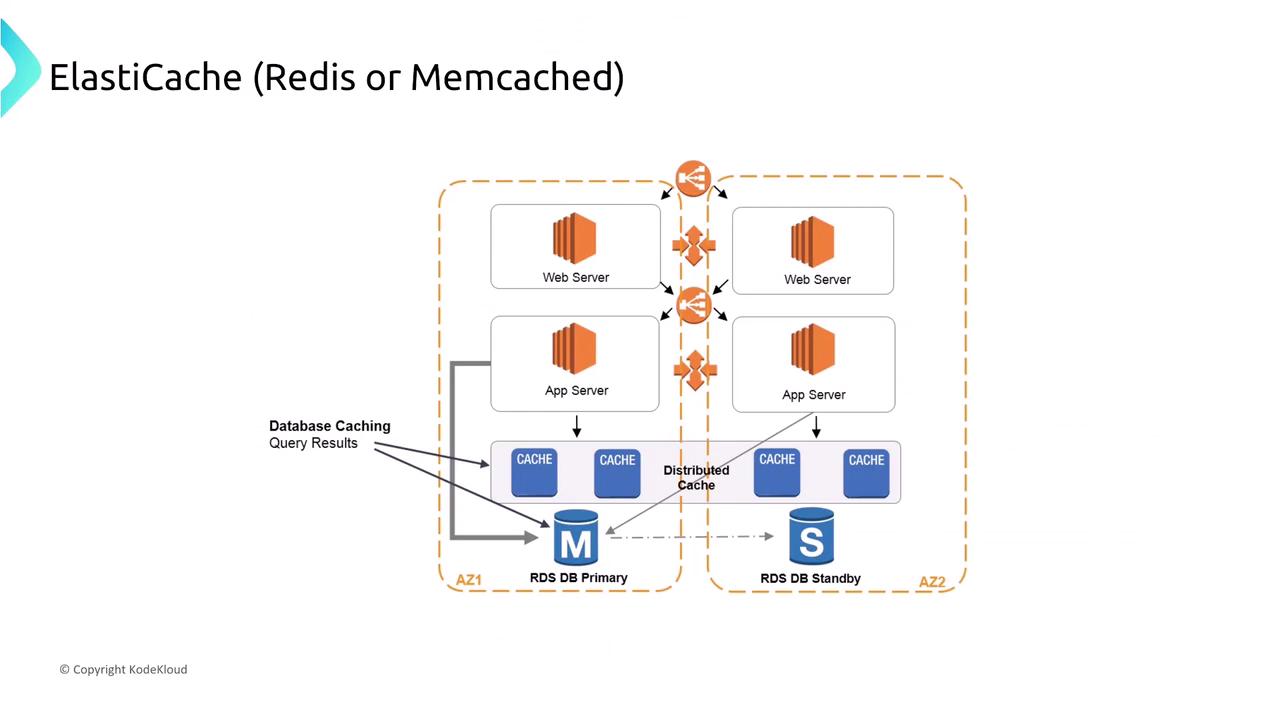
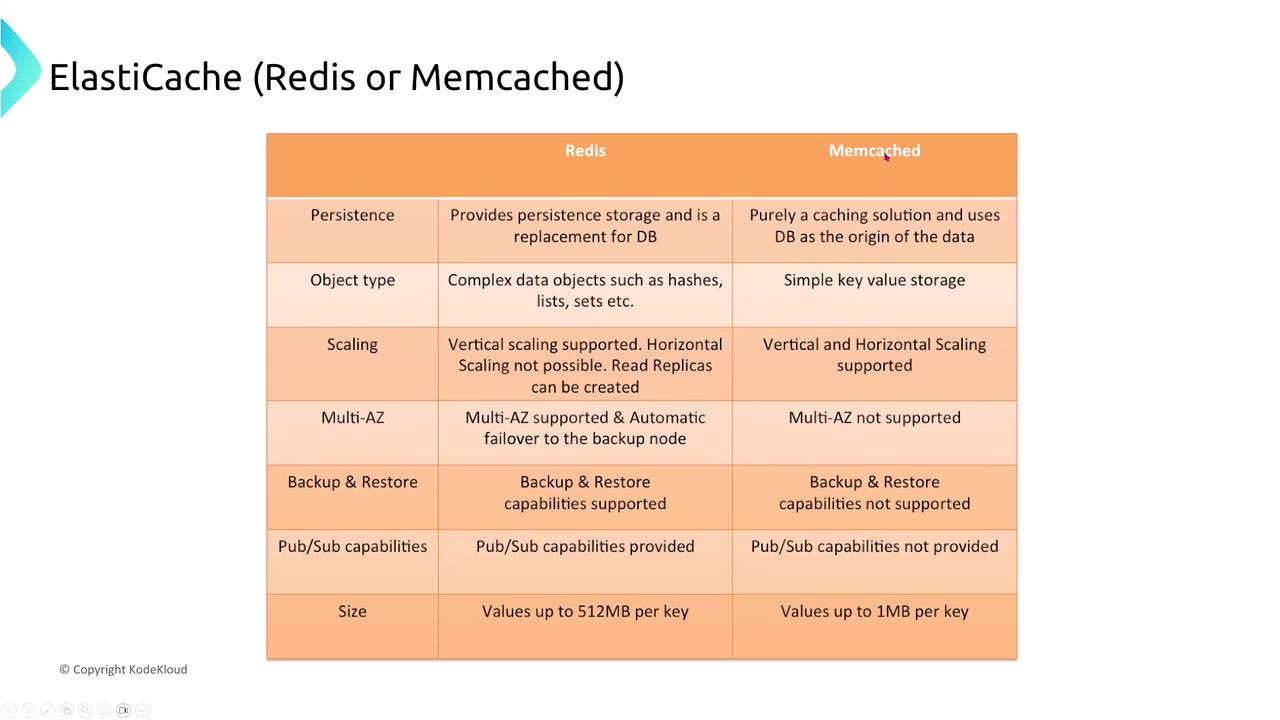
Amazon ElastiCache (Redis/Memcached)
ElastiCache supports both Redis and Memcached. Redis offers replication and persistence, while Memcached does not support node-to-node replication. Implementing a caching layer with ElastiCache can offload database traffic, reduce latency, and add resiliency through auto-recovery and scaling.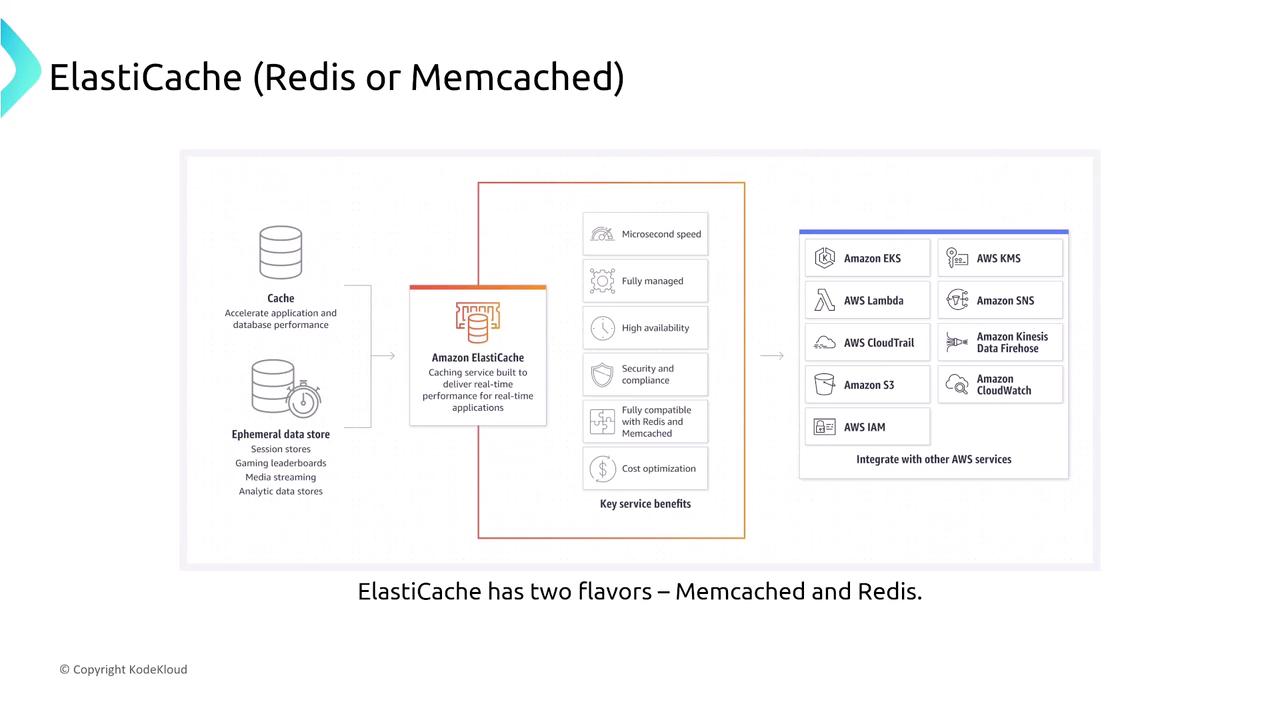

Amazon MemoryDB for Redis
MemoryDB for Redis is engineered as an in-memory persistent data store, ideal for microservices architectures. It employs a multi-AZ deployment with synchronous replication, ensuring that if a primary node fails, a replica in another AZ is immediately promoted without data loss.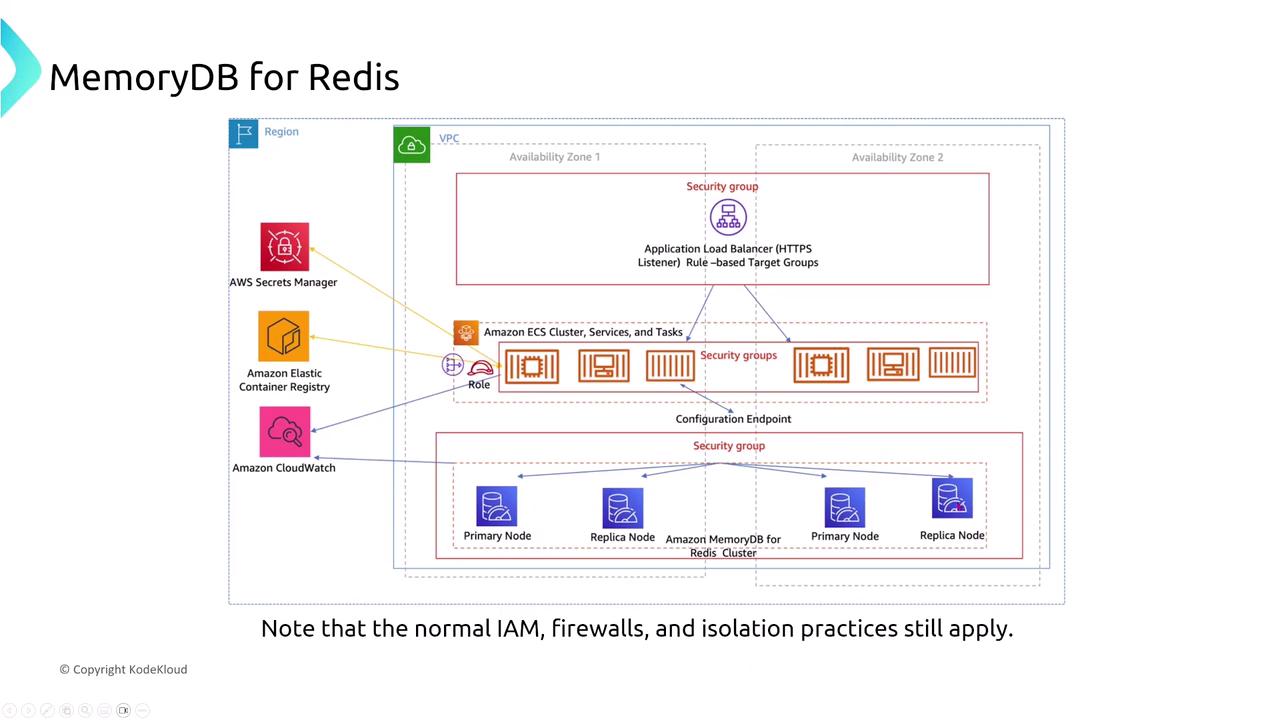

Amazon DocumentDB
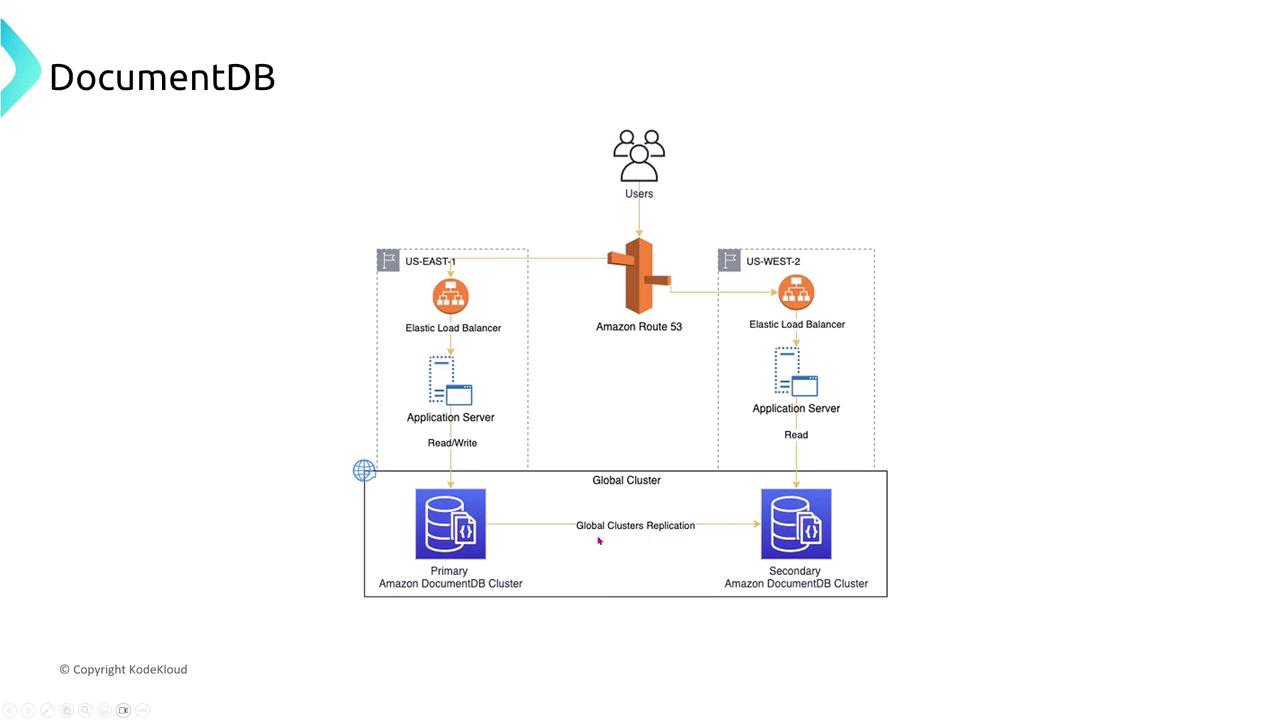
Amazon DocumentDB (with MongoDB compatibility) uses a distributed storage layer that replicates data six times across three AZs while continuously backing up to Amazon S3. It separates read and write endpoints (reader endpoint vs. cluster endpoint) to balance performance with resiliency.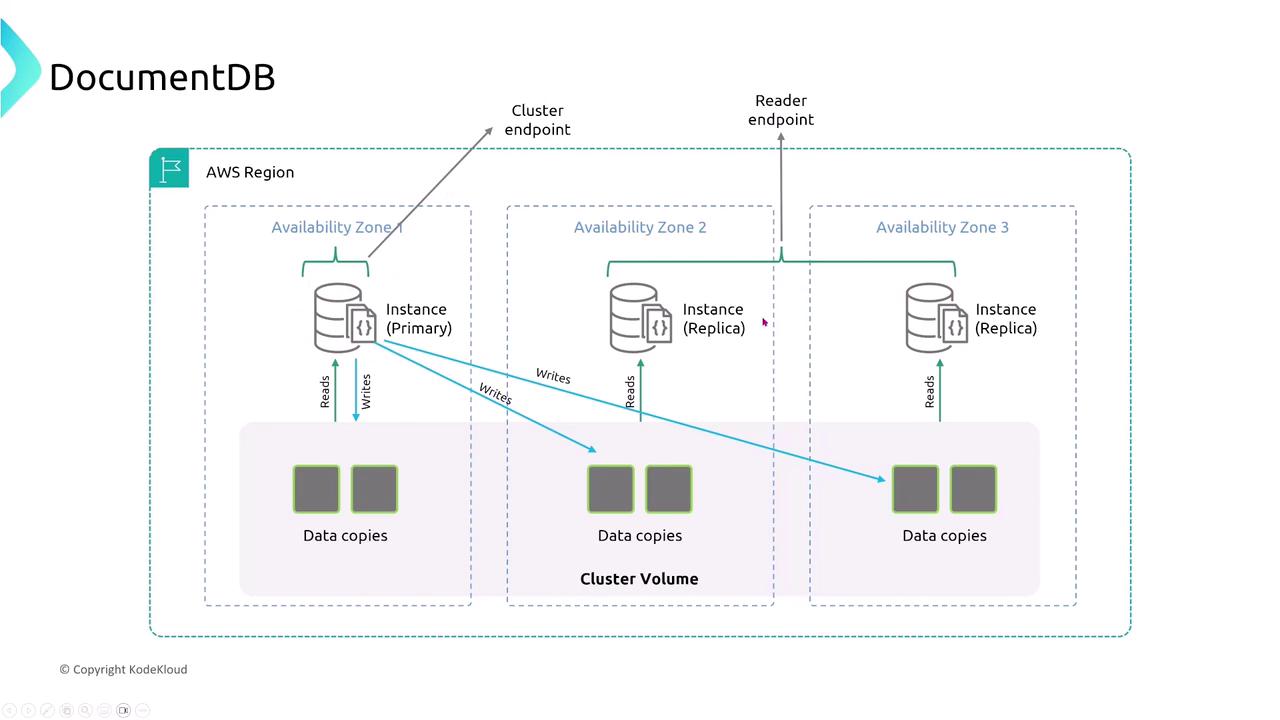

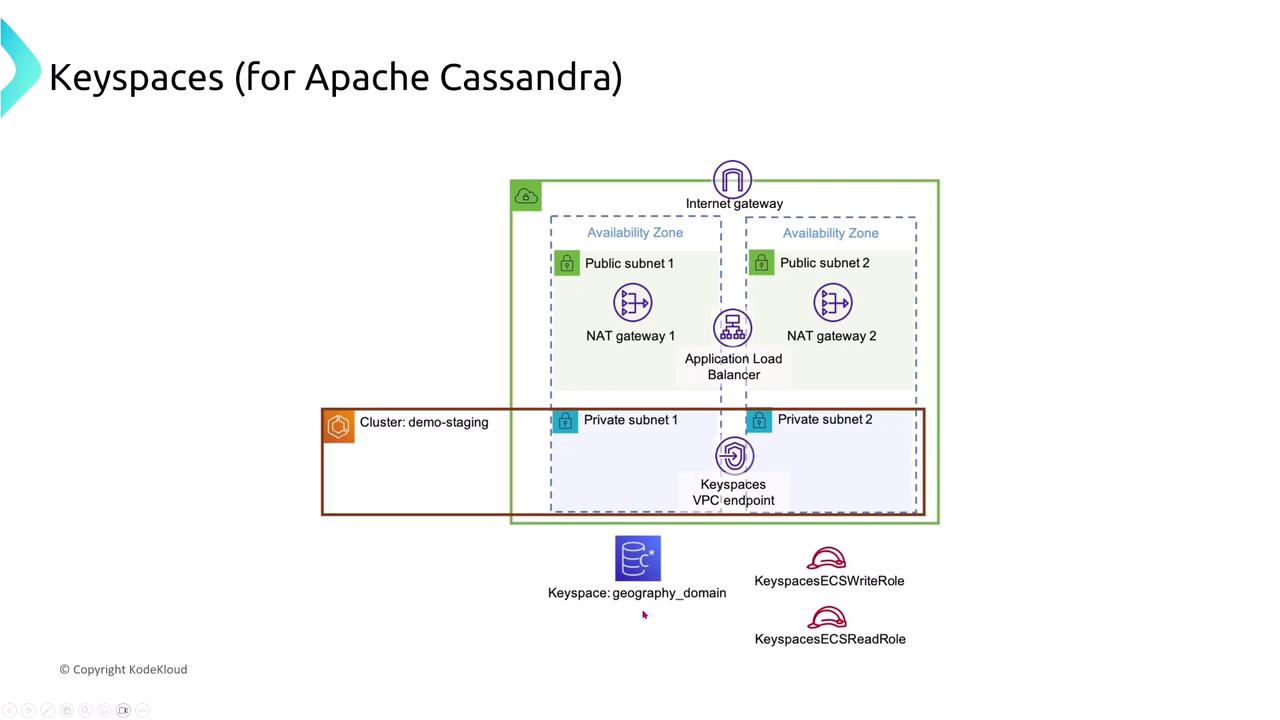
Amazon Keyspaces (for Apache Cassandra)
Amazon Keyspaces offers a serverless, Cassandra-compatible service. Data is automatically partitioned and replicated across multiple Availability Zones, and the replication factor (typically three) ensures that your queries remain reliable even if one node fails.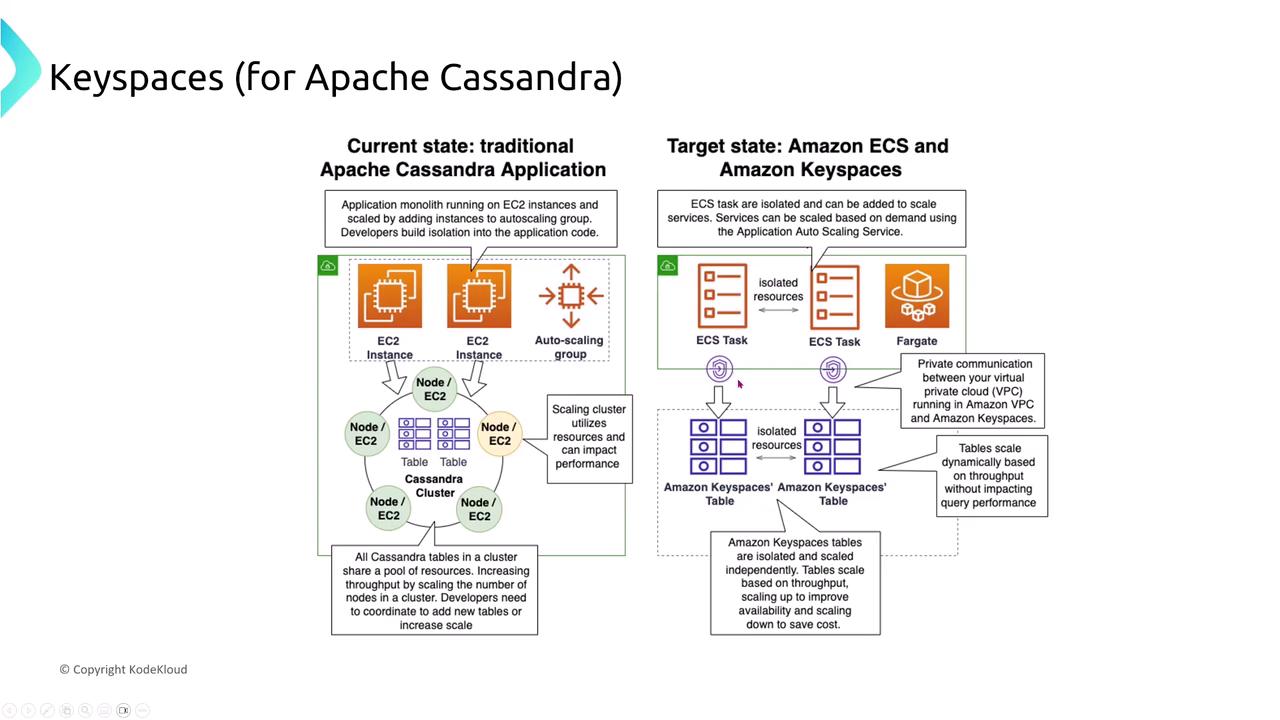
Graph Databases
Amazon Neptune
Amazon Neptune is a managed graph database supporting both property graph and RDF models. It replicates data synchronously across multiple Availability Zones so that if one node fails, others seamlessly take over without manual intervention.

Immutable and Time Series Databases
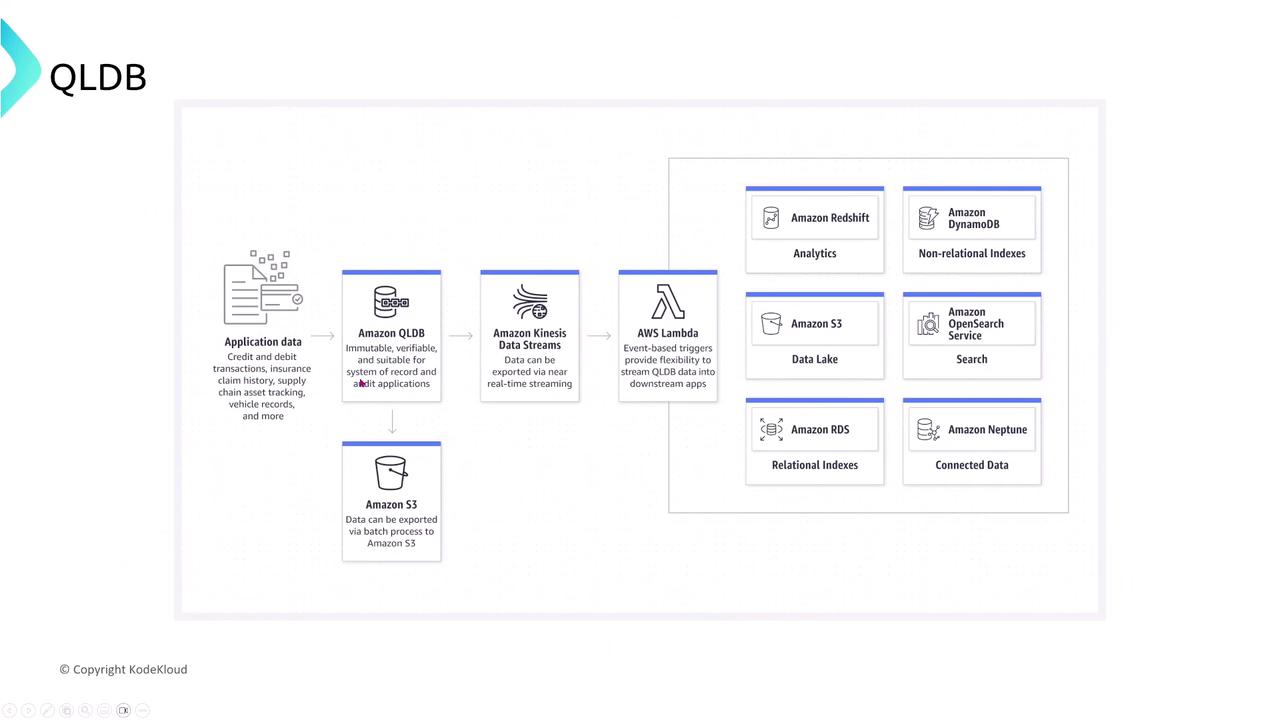
Amazon QLDB
Amazon Quantum Ledger Database (QLDB) is an immutable, append-only ledger database ideal for tracking transactions transparently. It replicates data across three Availability Zones and continuously backs up to Amazon S3, ensuring that once data is written, it remains unaltered.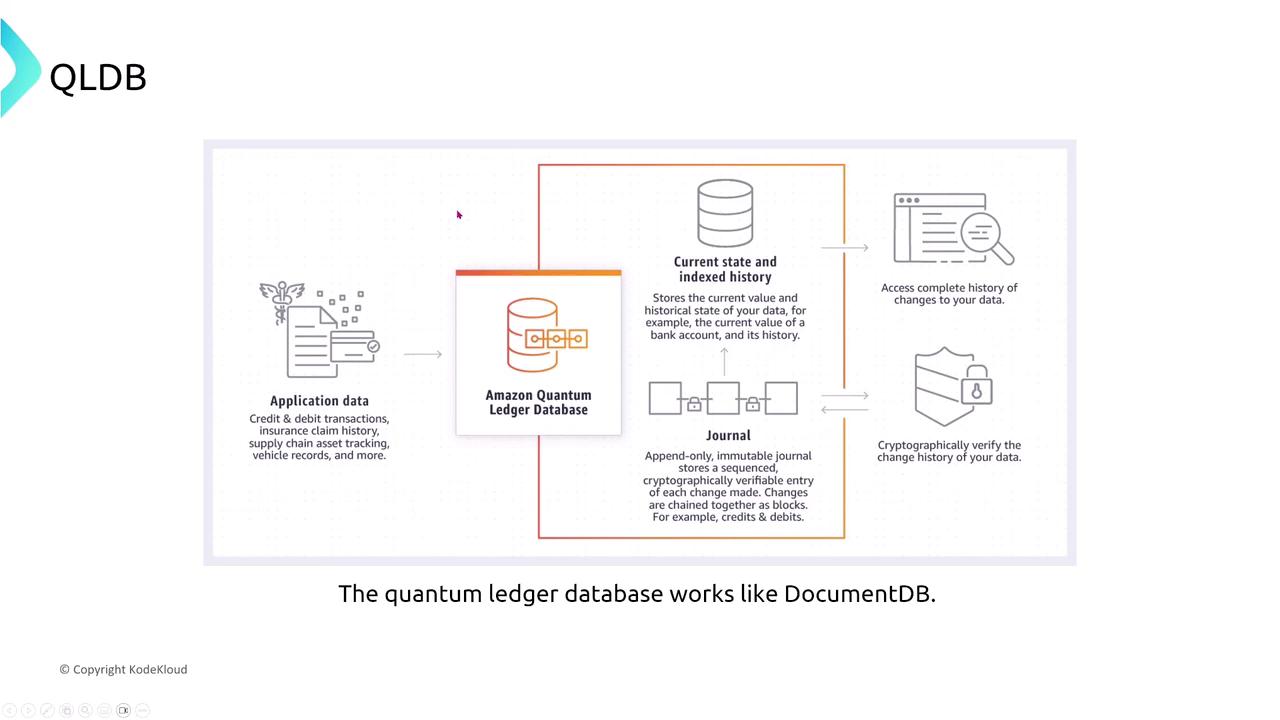


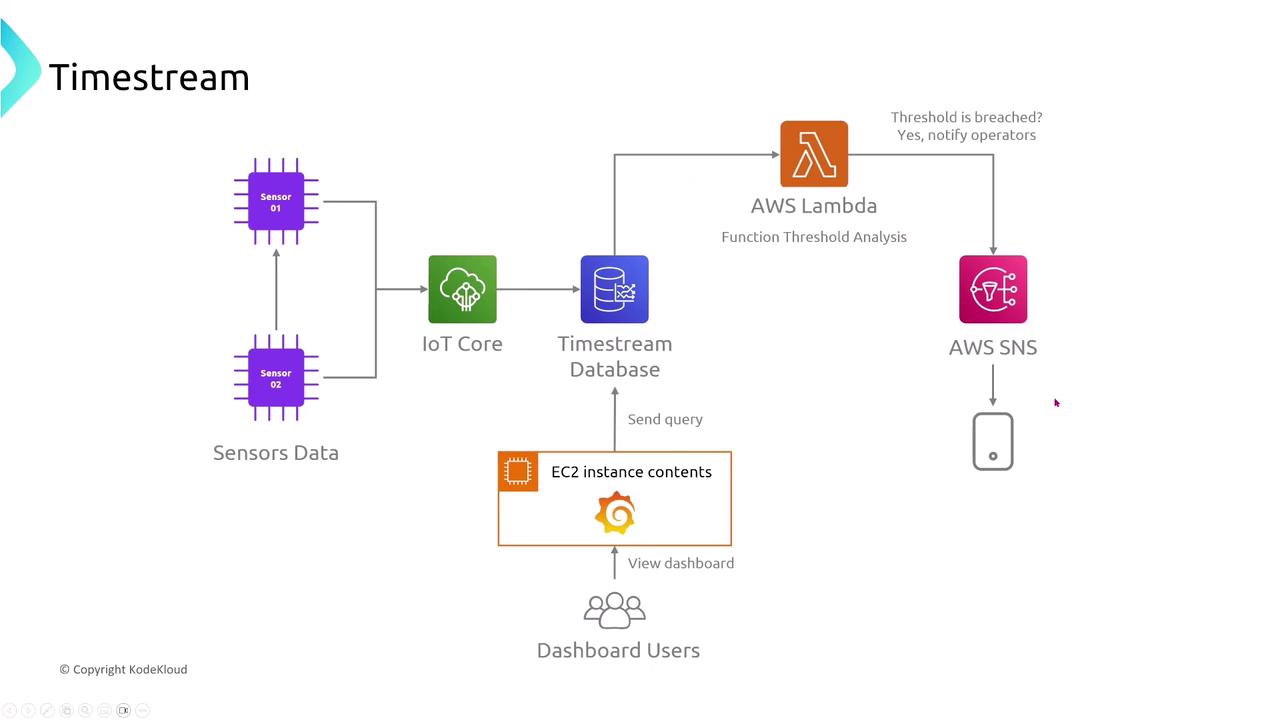
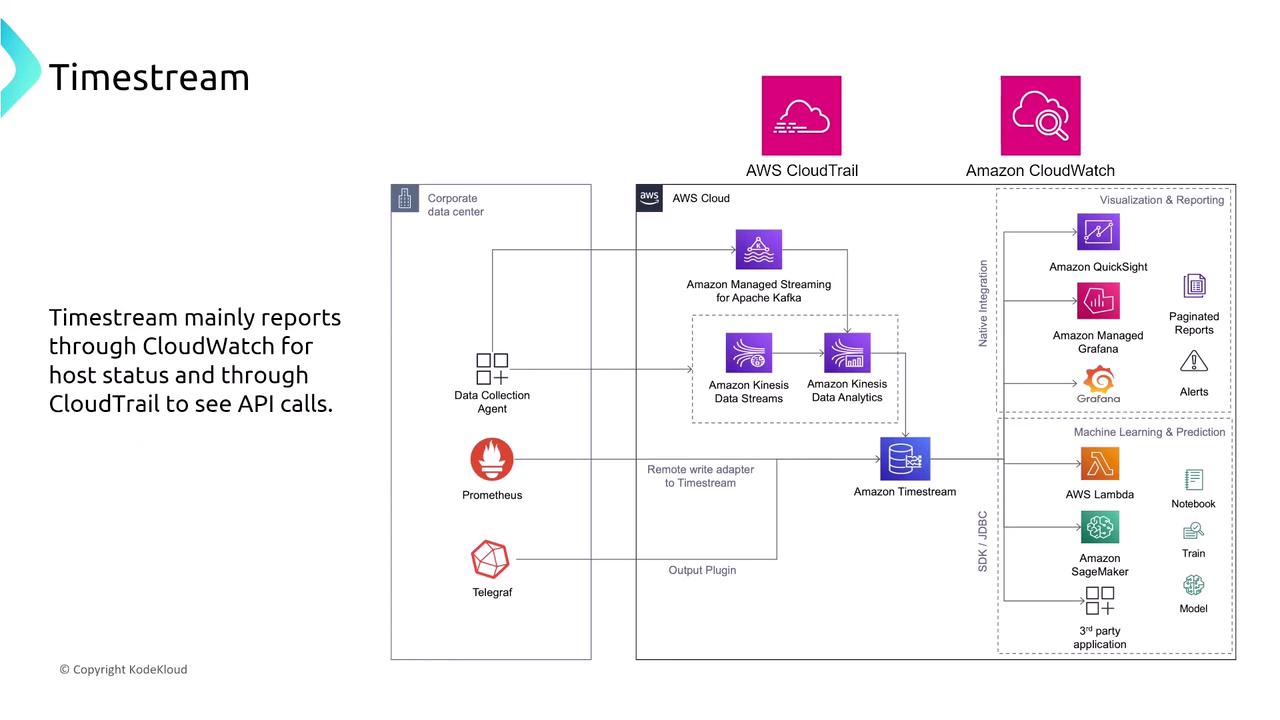
Amazon Timestream
Amazon Timestream is a purpose-built time series database optimized for high ingest rates and fast query performance over time-series data. It automatically replicates data across multiple Availability Zones. To ensure fault tolerance, it is essential to incorporate retry logic with exponential backoff in your applications.
Summary
This article has surveyed a broad range of AWS database services and open-source alternatives, outlining practical strategies for enhancing availability, resiliency, and overall reliability. Traditional, node-based systems such as RDS, Aurora, and Redshift require careful configuration (e.g., using Multi-AZ deployments and read replicas), whereas serverless and fully managed solutions like DynamoDB, QLDB, and Timestream inherently incorporate many reliability features. By leveraging automatic replication, failover, scaling, and robust monitoring through services like CloudWatch and CloudTrail, you can build architectures that meet your resiliency requirements while also supporting security best practices. If you have any questions or need further guidance, please join the forums for discussion. Thank you for joining me on this deep dive into database reliability. I look forward to our next exploration into application integration. —Michael Forrester, KodeKloud.com