This article explores designing for reliability on AWS compute services, focusing on EC2 and the shared responsibility model for resiliency.
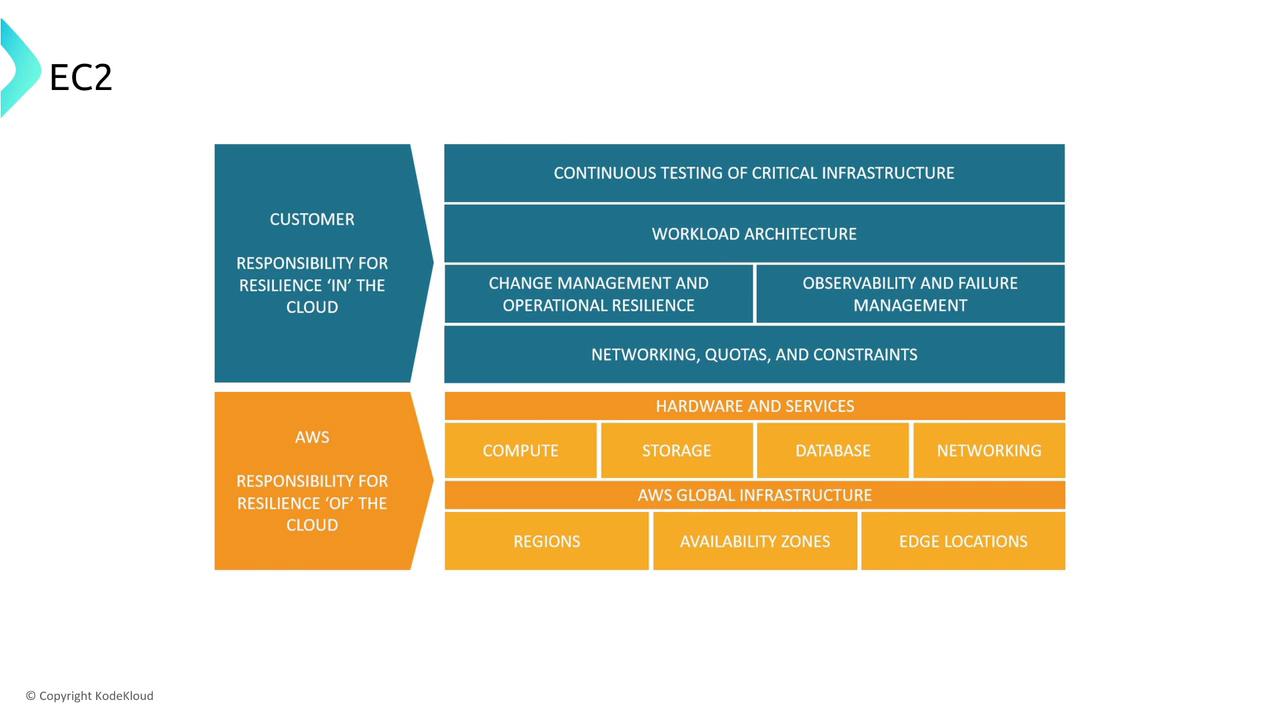
Future AWS Solutions Architects, in this lesson we explore designing for reliability on compute services with a focus on EC2. As you know, Amazon EC2 (Elastic Compute Cloud) requires you to assume more resiliency responsibilities compared to fully managed services like AWS Lambda. This lesson emphasizes the shared responsibility model, where AWS manages the underlying infrastructure and you manage elements such as workload architecture and failure management.
When designing for resiliency on compute services, you often face questions about the division of responsibilities. For instance, consider a scenario where a company uses AWS for its application infrastructure and the CTO requires clarity on who handles tasks such as data replication. In a multi-region setup, AWS is responsible for data replication between Availability Zones and for managing the physical hardware and data centers. On the other hand, tasks like database backups, scaling compute resources, and securing virtual machine operating systems become the customer’s responsibility.
A key point to remember is the distinction between the host operating system (managed by AWS) and the instance operating system (managed by you). For example, in Amazon RDS (except for RDS Custom), you cannot log in to the underlying virtual machines, so AWS handles patching and security. In contrast, with EC2, EMR, or RDS Custom where you have operating system-level access, it becomes your responsibility to ensure that the OS remains secure and up to date.
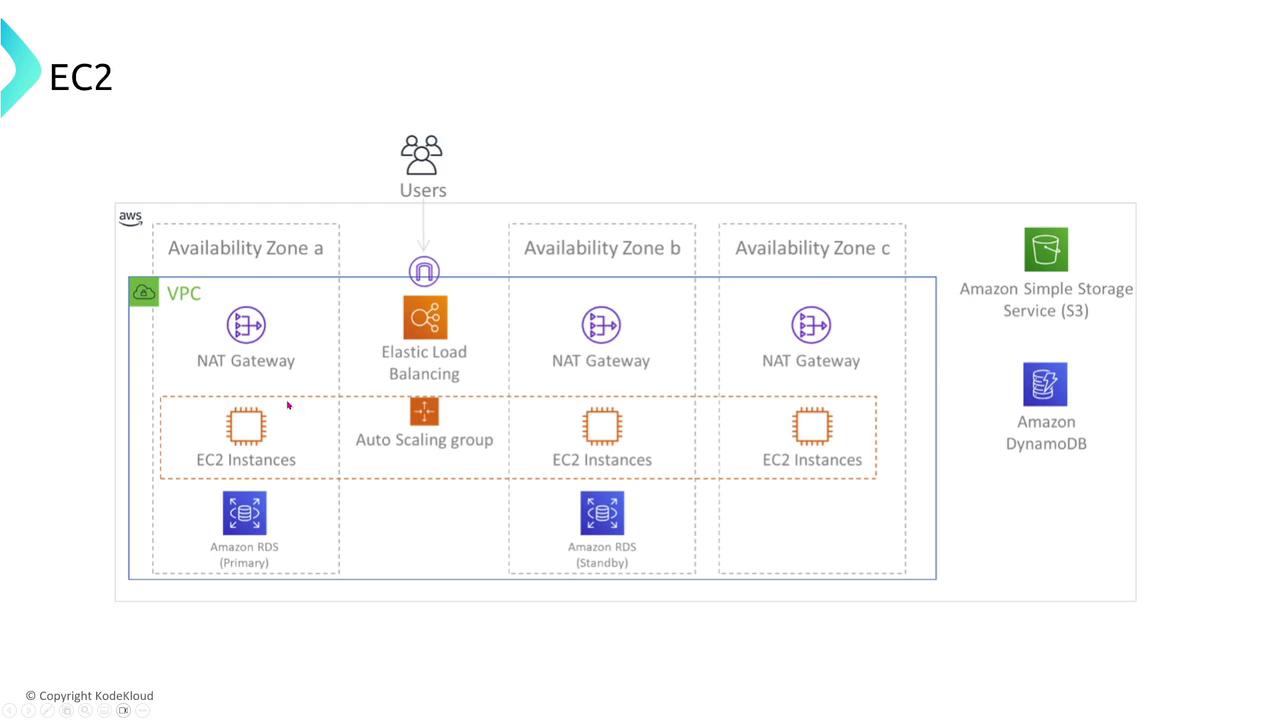
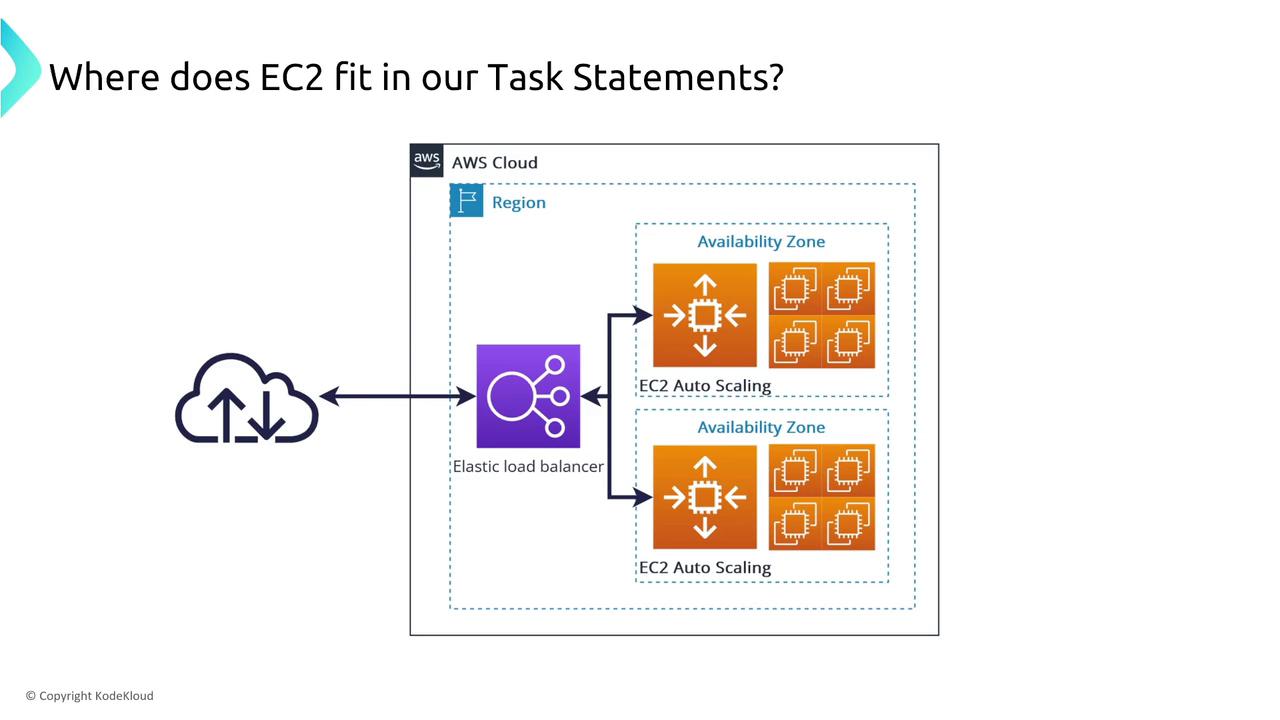
To enhance EC2 resilience, the most common strategy is to use load balancing and Auto Scaling groups. These tools automatically add additional EC2 instances to ensure minimal downtime if an instance fails.
For example, if your critical EC2 application instances need to be restored rapidly within a 10-minute Recovery Time Objective (RTO), consider using an Auto Scaling group combined with EC2 Fast Snapshot Restore. Since “cold” instance start-up may take too long, using immutable infrastructure with pre-configured AMIs accelerates recovery. Additionally, enabling EC2 auto-recovery ensures that an instance can be automatically replaced while preserving its IP address so that recovery occurs within the desired window.
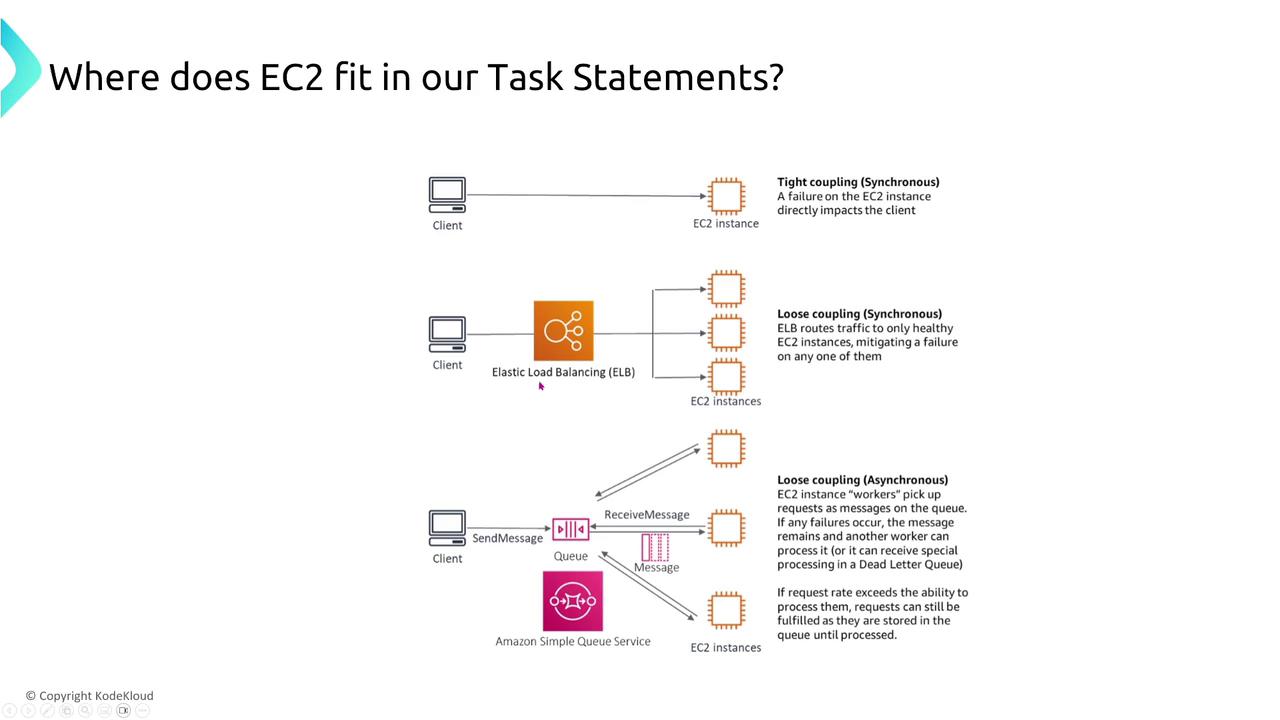
Beyond recovery measures, rigorous security management is essential. Monitoring access and ensuring proper authentication remain high-priority tasks. To further enhance resiliency, consider integrating intermediary AWS services—such as load balancers, queues, or notification systems—to decouple client interactions from direct connections with EC2 instances. This decoupling, whether implemented synchronously or asynchronously, improves the overall resilience of your application architecture.
For instance, imagine EC2 instances processing messages from an SQS queue after S3 triggers notifications for new video uploads. By including a unique message identifier, processing becomes idempotent, ensuring that messages are not reprocessed unnecessarily if retries occur.
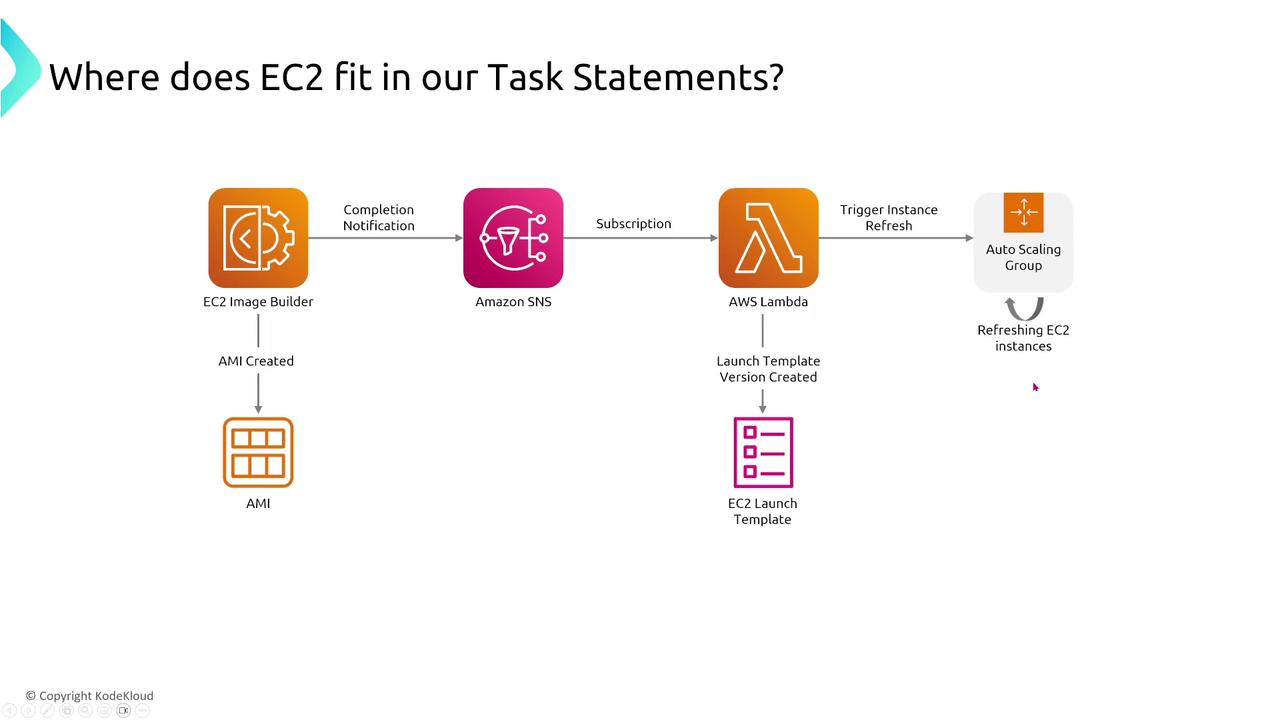
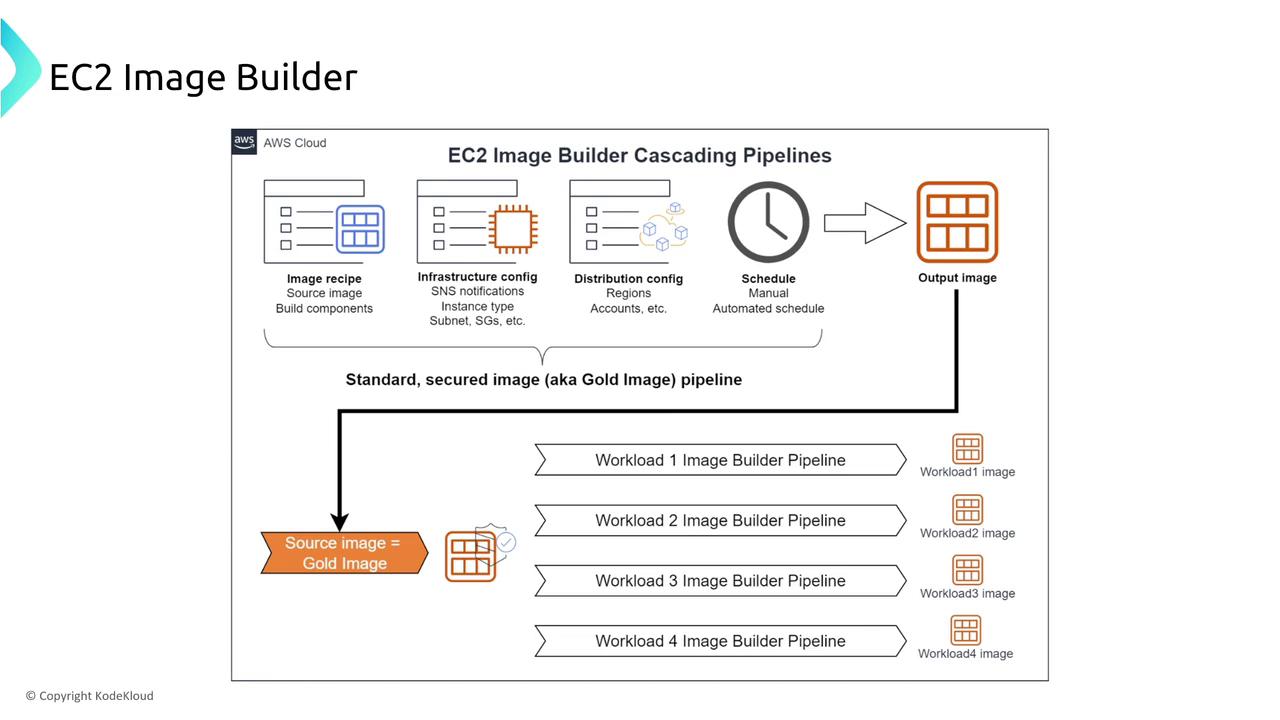
Another effective pattern is using EC2 Image Builder to create consistent AMIs, which are then deployed via launch templates. These AMIs can be refreshed automatically within your Auto Scaling group to maintain consistency across various environments such as development, testing, and production.
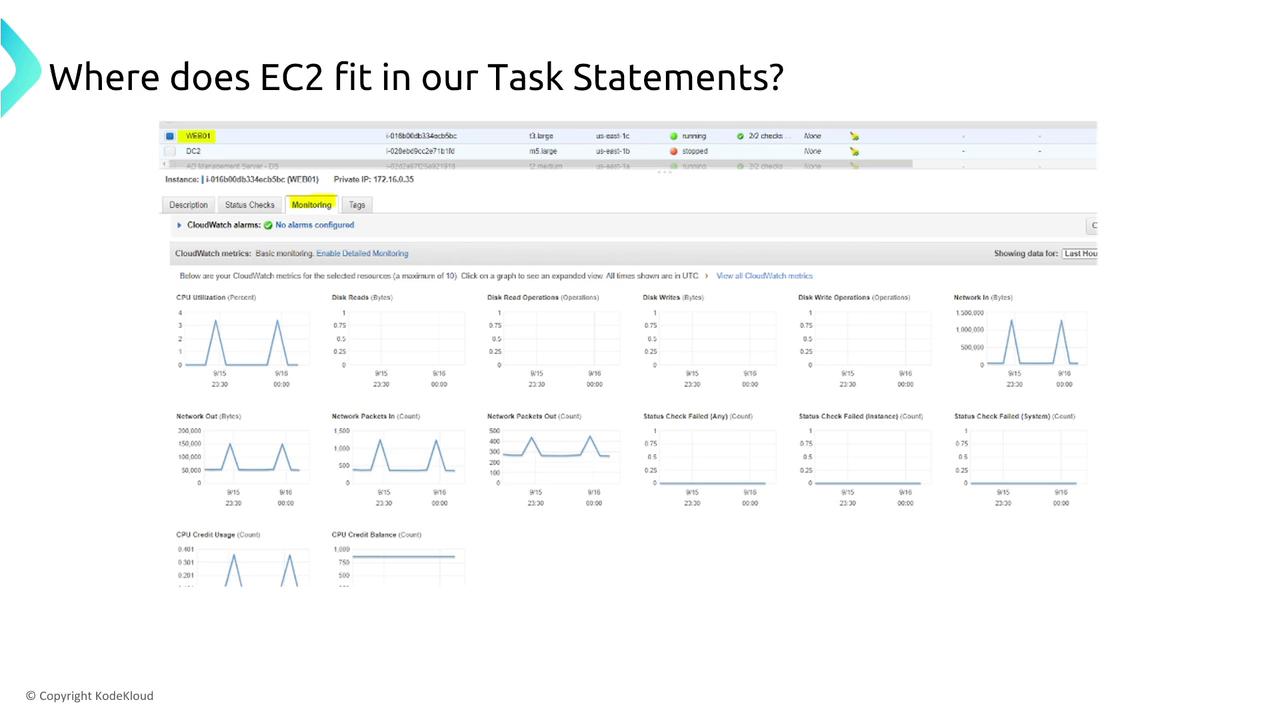
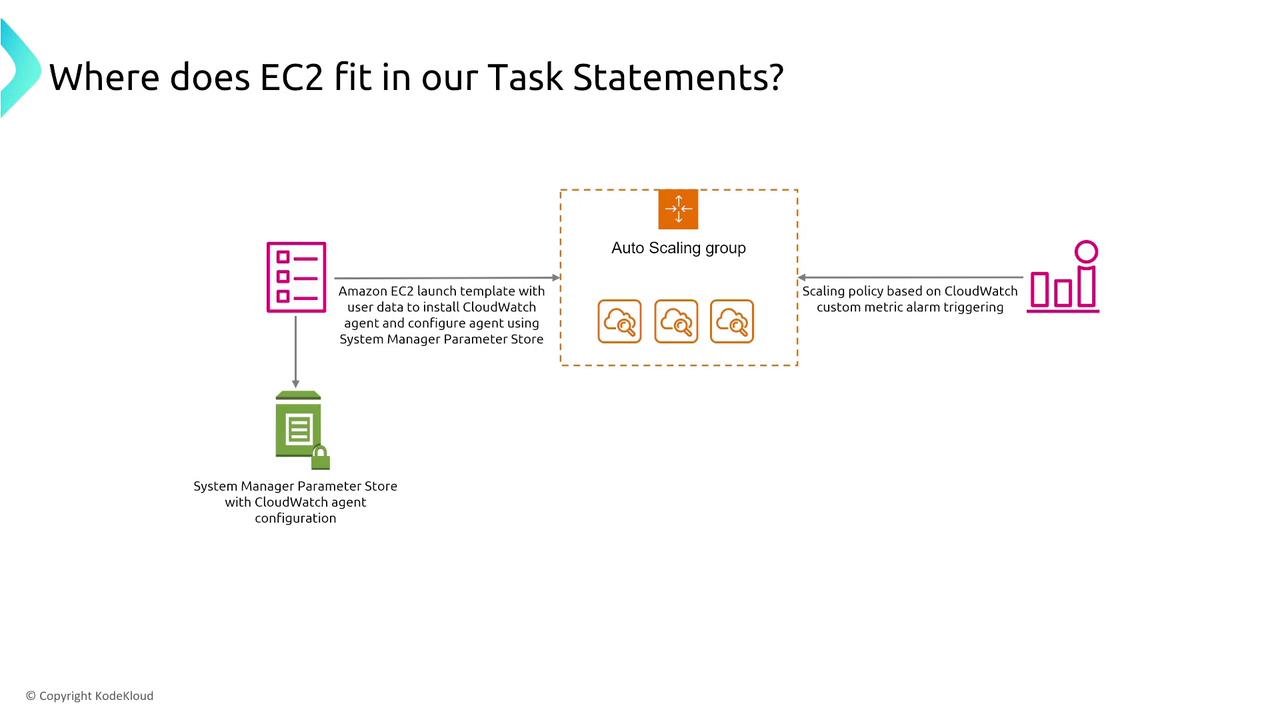
Monitoring is the cornerstone of any resilient system. Installing CloudWatch agents on your instances helps capture vital performance metrics, including CPU utilization, disk operations, and network performance. These metrics provide deep insights into your system’s health and help guide Auto Scaling actions based on dynamic loads.
Predictive scaling policies can further improve resiliency by proactively scaling EC2 capacity in anticipation of traffic spikes when historical usage data is available.
Remember to follow best practices when implementing Auto Scaling. For example, avoid using Instance Store volumes for critical data and ensure that auto-recovery features are enabled where applicable. A typical resilient EC2 deployment might use a launch template that installs a CloudWatch agent, configures parameters in Parameter Store, and creates an Auto Scaling group with target tracking scaling policies—maintaining CPU utilization at a defined target (e.g., 40% or 80%).
Reliability also means tracking changes and monitoring system behavior so issues can be addressed early. AWS Config audits EC2 configuration changes, CloudTrail logs all API calls, and CloudWatch monitors system metrics. Together, these services help ensure that operational changes do not compromise your environment’s stability.
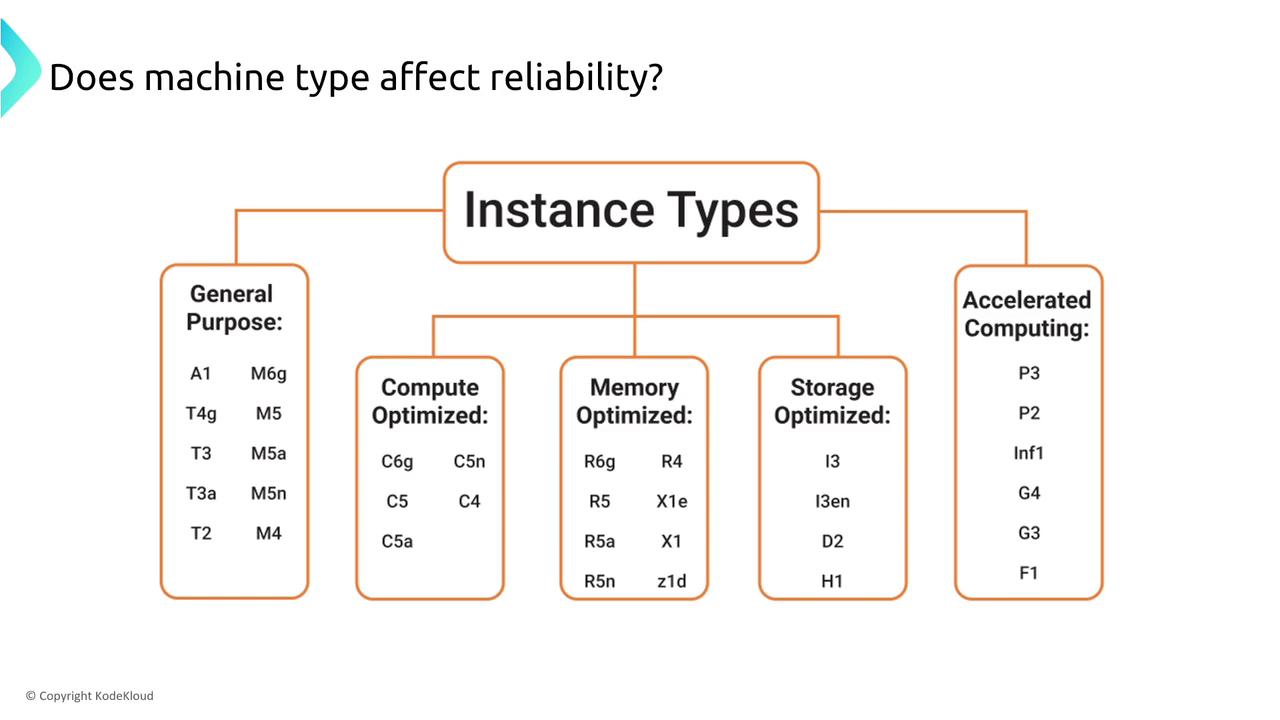
One common area of concern is whether the machine type affects reliability. Generally, for instance types with dedicated resources (such as the M, C, or R series), AWS guarantees that you receive the resources requested. However, the T-Series instances use burstable CPU credits. These provide baseline performance with the ability to burst. Once the credits are spent, performance throttling occurs. For workloads requiring consistent CPU performance, it is best to avoid burstable instance types.
For additional security or regulatory compliance, consider dedicated hosts or dedicated instances. These options ensure that the physical hardware is not shared with other AWS customers.
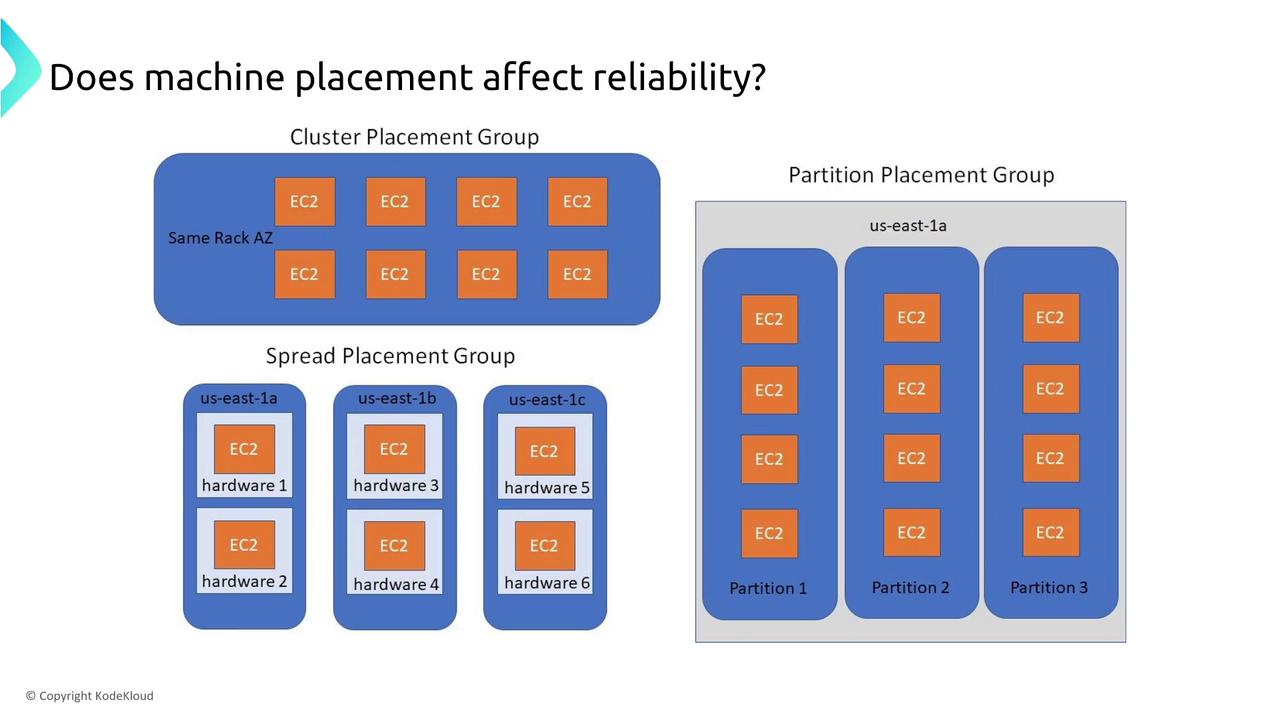
Also, consider the impact of machine placement strategies on reliability. AWS offers placement groups to control instance placement:
Cluster Placement Group: Maximizes performance by grouping instances in a single rack. However, if that rack fails, all instances may be affected.
Partition Placement Group: Distributes instances on different hosts within a single Availability Zone to reduce risk.
Spread Placement Group: Distributes instances across multiple hardware units, and even Availability Zones, for maximum availability.
Leveraging EC2 Image Builder and Elastic Beanstalk
When standardizing deployments, EC2 Image Builder is a managed service that creates secure and consistent AMIs automatically. It is ideal for automating the AMI patching process and integrates smoothly with your CI/CD pipelines.
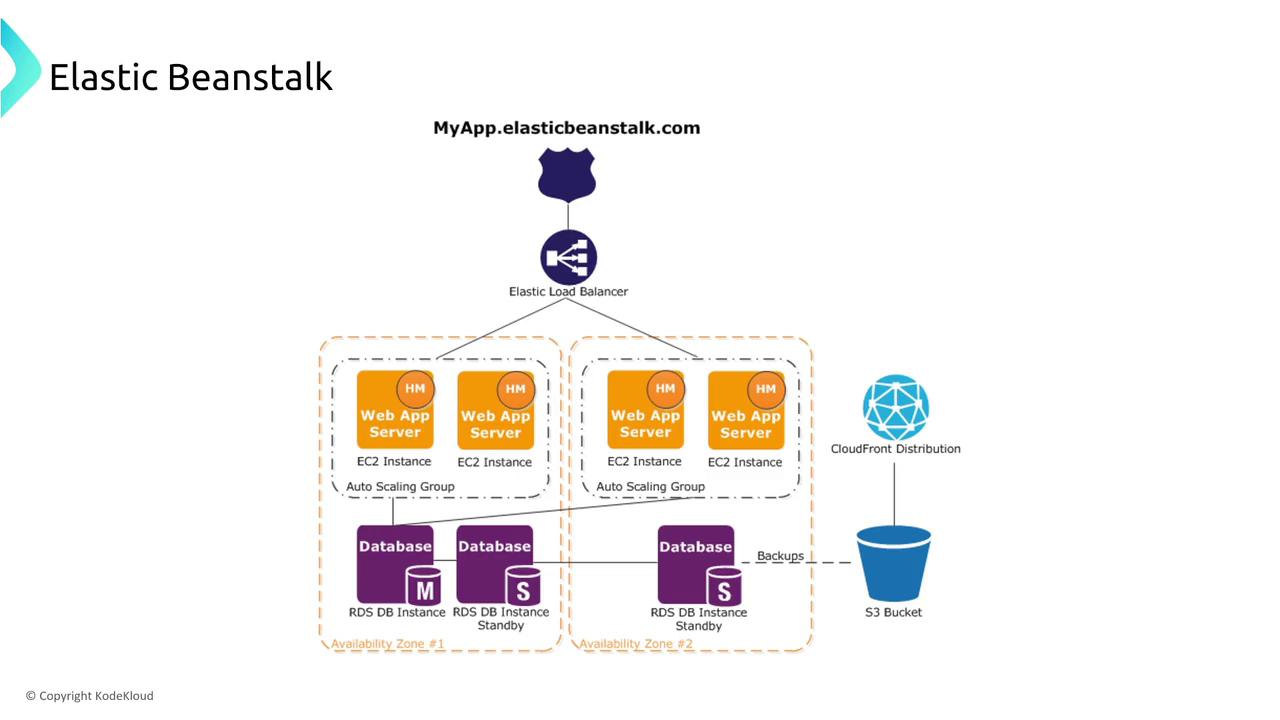
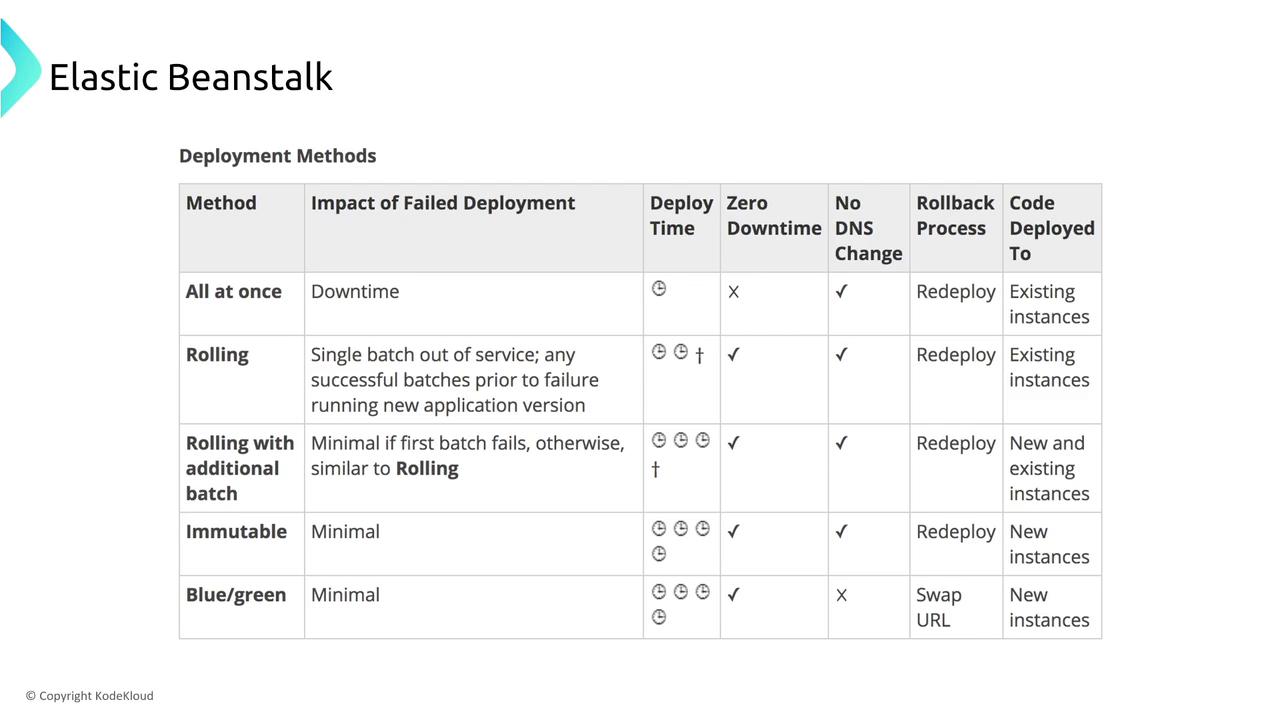
Elastic Beanstalk serves as a configuration wizard that ties together several AWS services. Although you cannot directly adjust the resiliency settings of Elastic Beanstalk itself, you can design highly redundant architectures by choosing options such as multi-AZ deployments. For example, a blue-green deployment strategy can significantly reduce downtime during updates.
Understanding the differences between deployment types is key. For instance, blue-green deployments minimize downtime by running new and old environments concurrently and then switching traffic through a DNS change. In contrast, all-at-once deployments might result in noticeable service interruptions.
When deeper application insights are needed, enabling AWS X-Ray on your EC2 instances within an Elastic Beanstalk environment can provide a comprehensive service map and help identify performance bottlenecks.
AWS Lightsail is a low-cost VPS solution that offers simplified management. However, it lacks many of the robust reliability and scalability features provided by EC2. Although Lightsail is not a focal point for the AWS Solutions Architect exam, it is useful to know for basic use cases.
The discussion now transitions to designing for reliability in container-based environments, where similar principles such as scaling, monitoring, and decoupling are applied to containerized workloads.
This concludes our deep dive into designing for reliability on compute services with a focus on EC2, Elastic Beanstalk, and an overview of Lightsail. Up next, we will explore container-based architectures and detail strategies for achieving resiliency with AWS container services.