Amazon Elastic Container Service (ECS)
ECS is one of the pioneering container management services on AWS. When building a resilient ECS architecture, consider the following best practices:- Multi-AZ Deployment:
For EC2-based clusters, deploy multiple EC2 instances across different AZs. For example, an auto scaling group might allocate one instance in a public subnet in AZ-1, another in AZ-2, and so on. Distributing tasks across these instances ensures high availability if an instance or AZ fails.
- Task Definitions and Service Scaling:
Multiple containers that run together are defined within a single ECS task definition. You can specify the number of task instances and distribute them across multiple AZs. This practice increases resiliency by ensuring that application components remain available even if some tasks fail.

- Container Scaling:
For applications using the EC2 launch type, ensure that your task definitions run on multiple instances. Implement auto scaling policies (such as target tracking) to automatically restart unhealthy tasks.

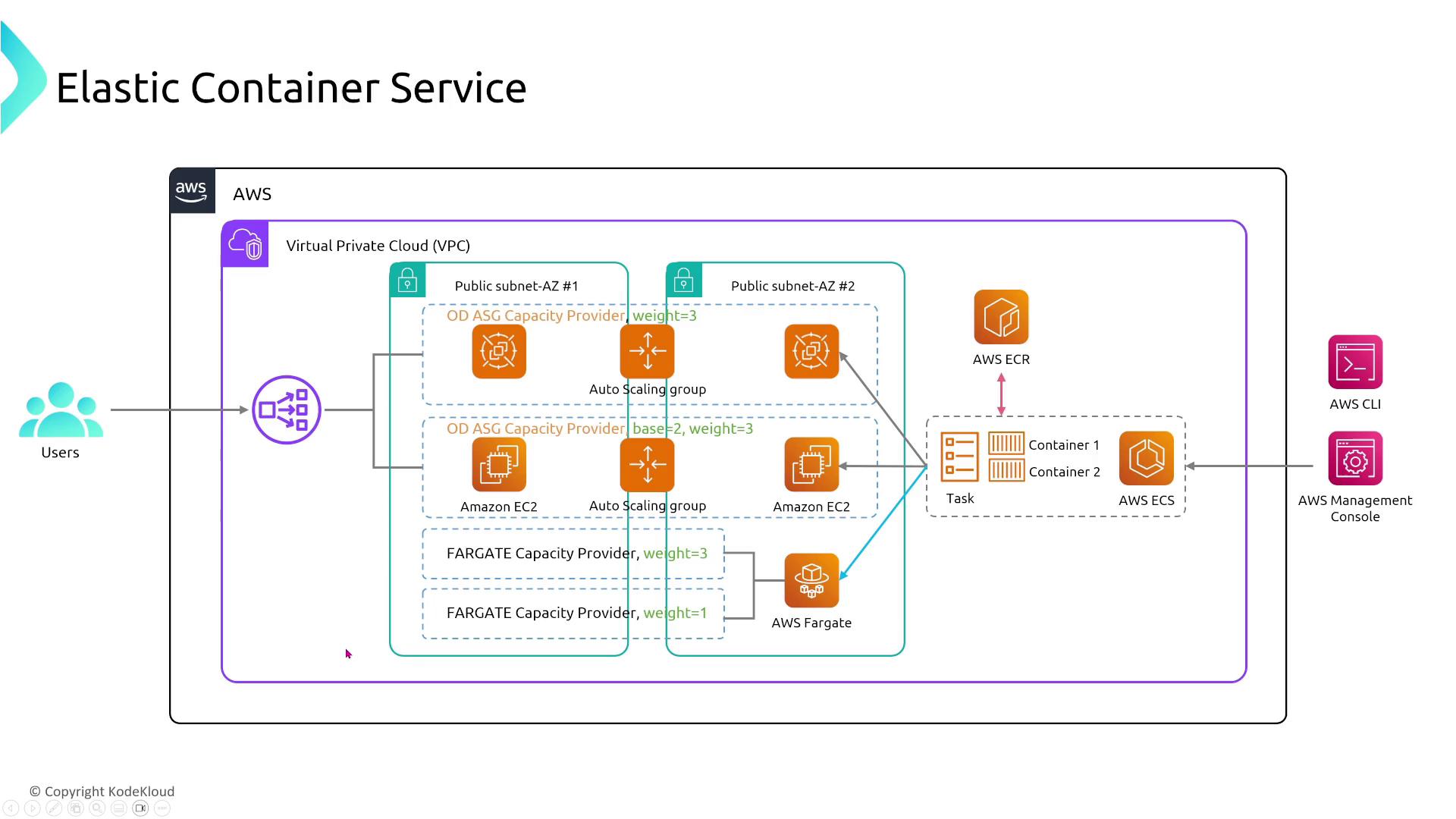
- Capacity Providers:
Utilize ECS capacity providers to support various infrastructure types (e.g., Windows, Amazon Linux 2, or Graviton processors with Bottlerocket). Each capacity provider has built-in auto scaling capabilities to allocate the necessary EC2 capacity based on demand.

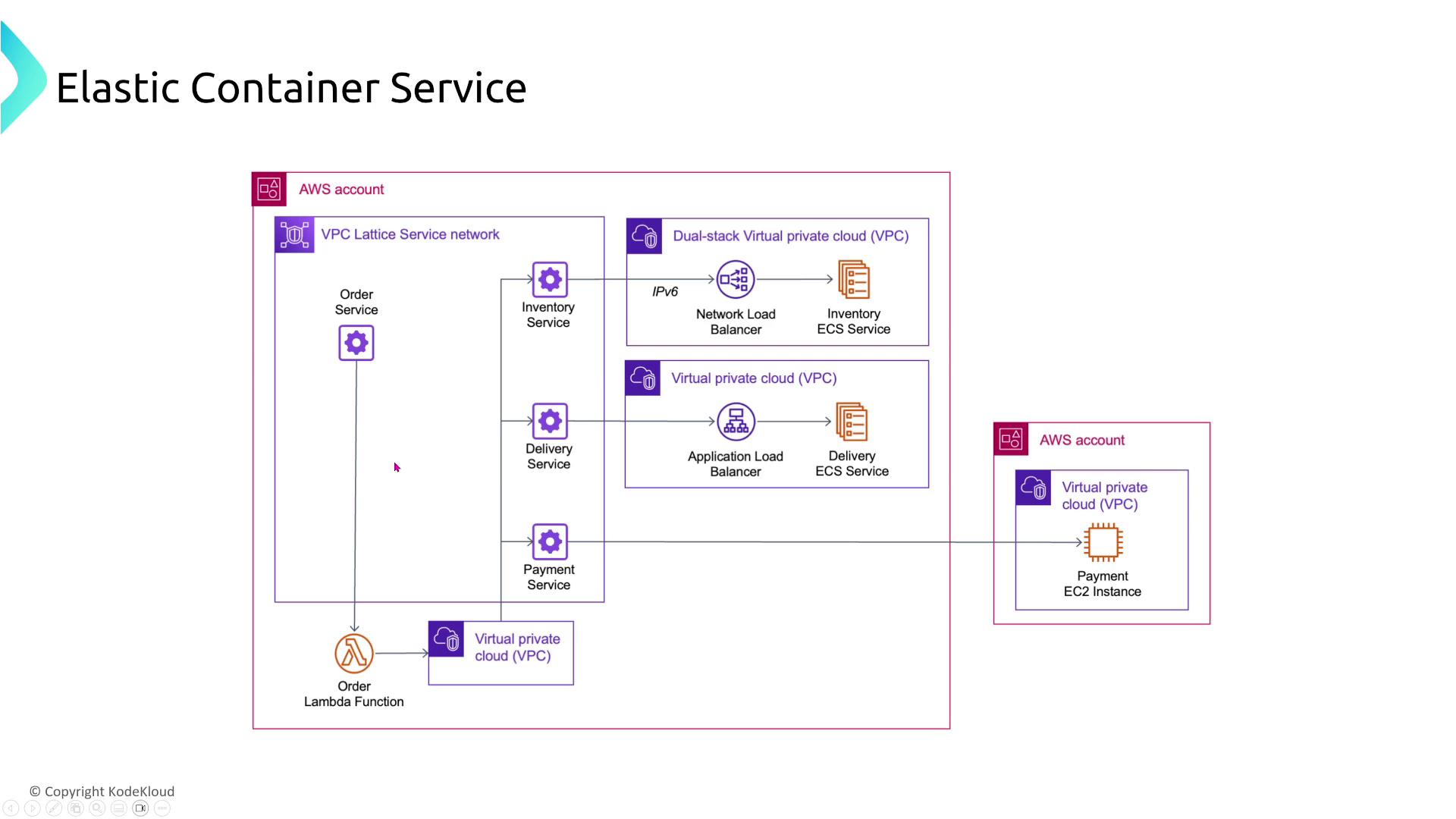
- Extended Resiliency with VPC Lattice:
Enhance service communication resiliency by integrating AWS VPC Lattice. This service network allows resilient communications between services in separate VPCs without the need for direct peering.
- Fargate Option:
When you choose Fargate, AWS manages the underlying EC2 instances for you. However, note that Fargate currently does not support GPU workloads. For GPU-intensive applications, use the EC2 launch type.

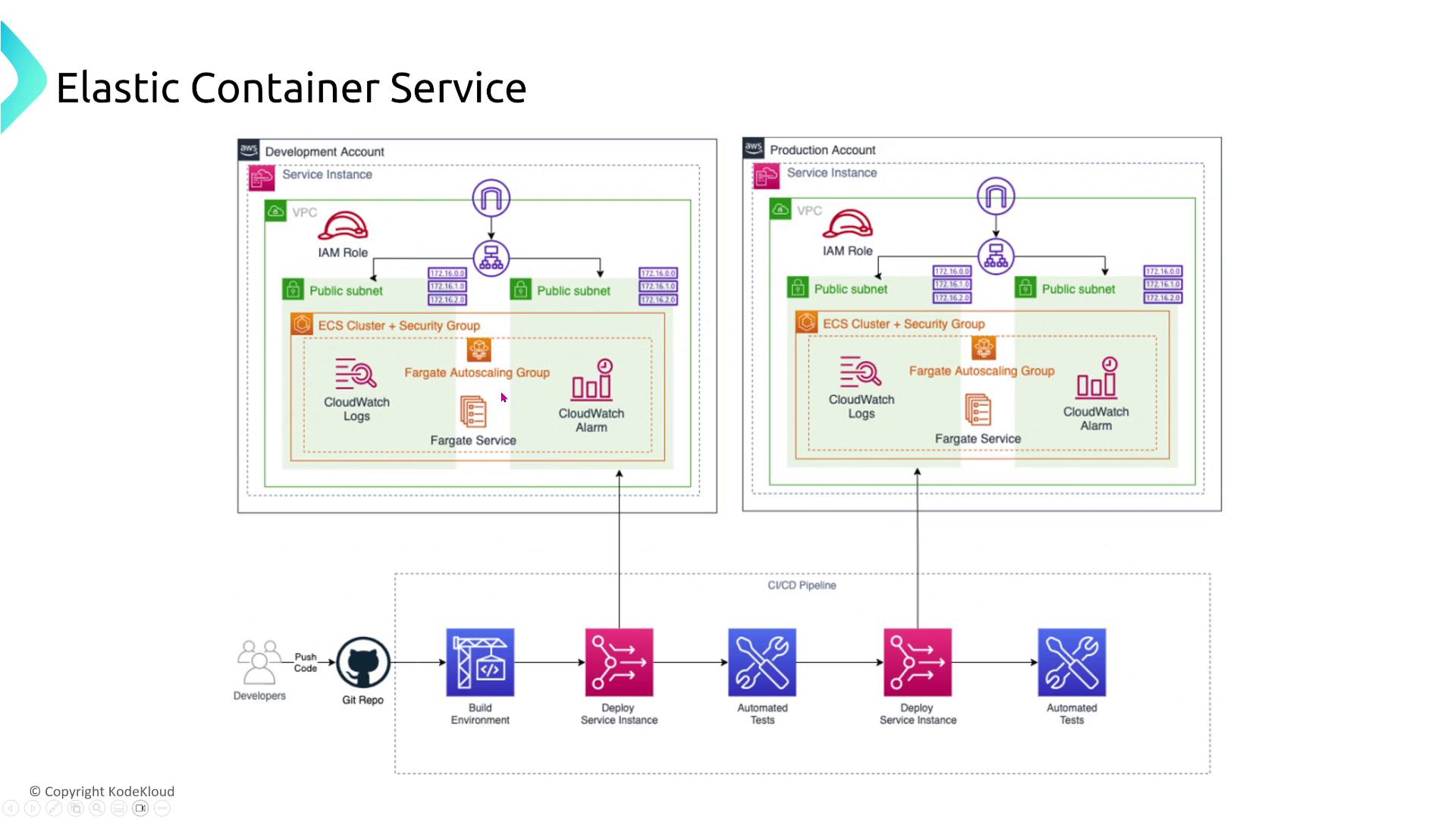
- CI/CD Integration:
Integrate CI/CD pipelines to deploy Fargate services across multiple environments, such as development and production. Auto scaling across these environments maximizes task availability.
- Health Checks and Task Auto Healing:
Enable health checks and auto recovery mechanisms to ensure that failed tasks are automatically restarted. Group related tasks into ECS services to maintain dependency isolation and consistent scaling.


Advanced task placement strategies like random, spread, and binpack help determine how tasks are allocated across hosts. Although more relevant for the professional-level exam, understanding these strategies can further enhance resiliency.
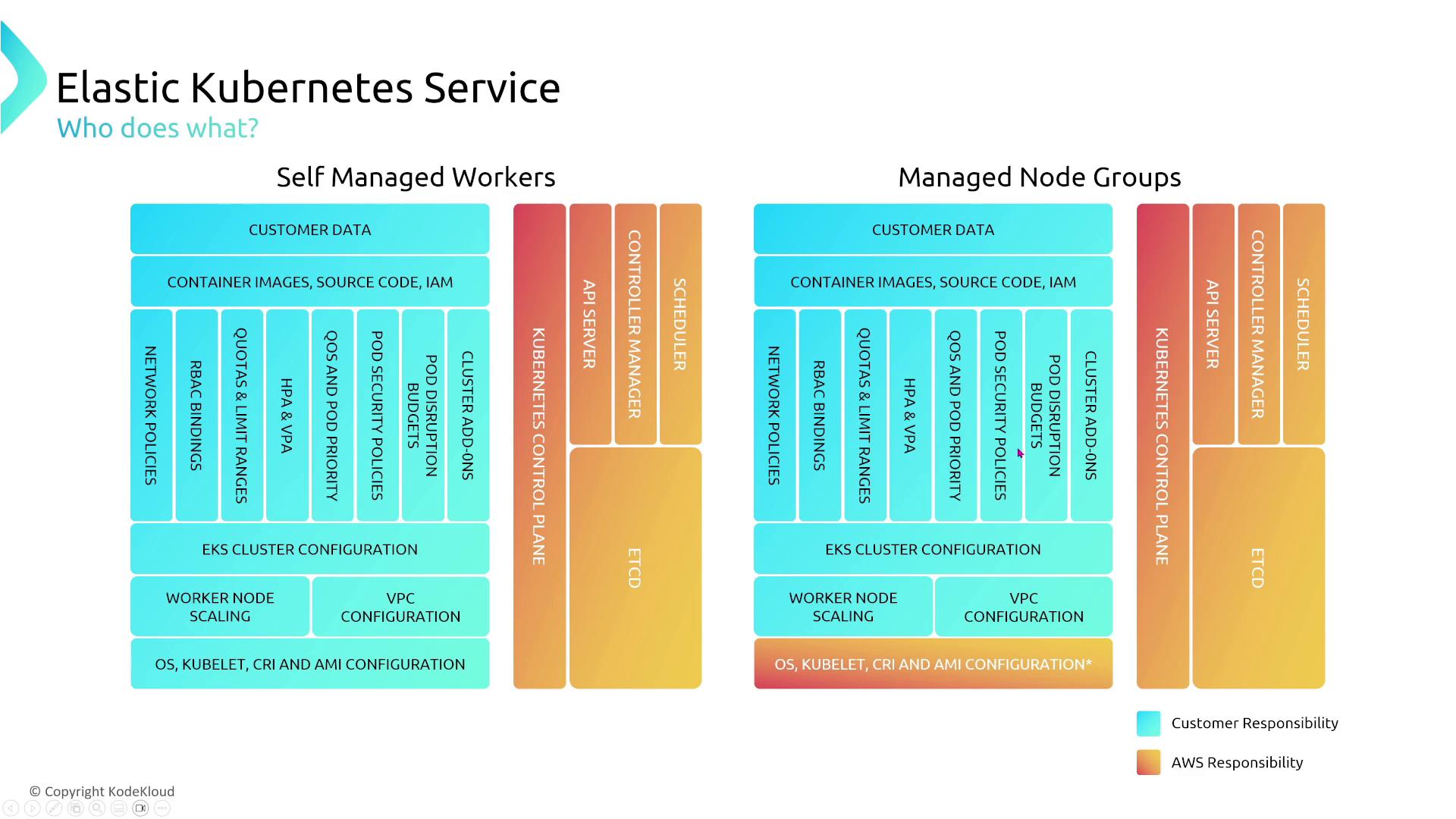
Amazon Elastic Kubernetes Service (EKS)
EKS leverages Kubernetes’ inherent resiliency features, yet additional strategies are essential for maximizing availability.- Multi-AZ and Node Distribution:
Distribute your cluster nodes across at least three AZs for maximum resiliency. Whether using EC2 launch type or self-managed node groups, this multi-AZ strategy prevents single-point failures.
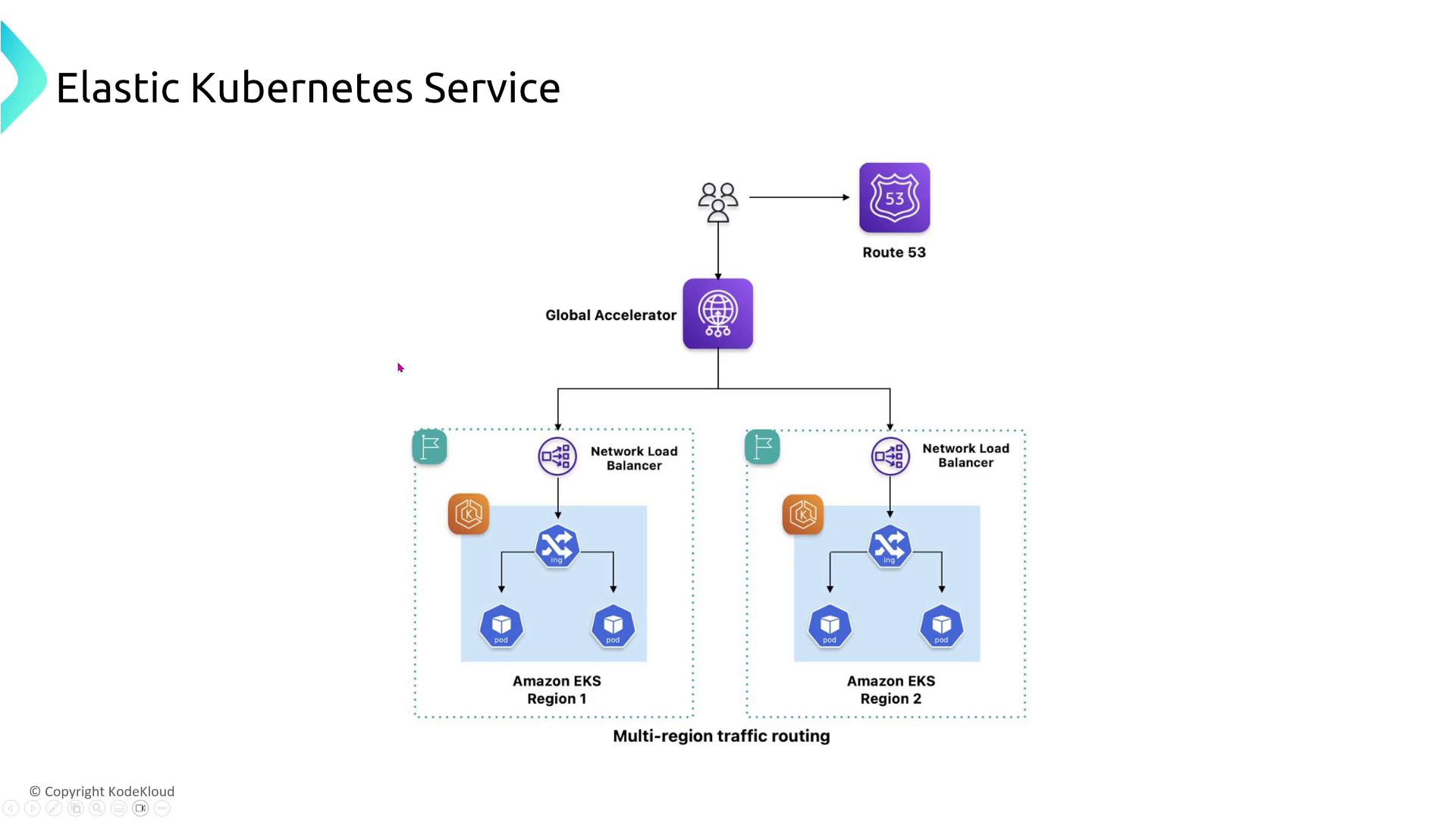
- EKS Cluster Architecture:
Spread nodes across AZs and consider using an Application Load Balancer (ALB) for TLS over TCP. For even greater redundancy, AWS Global Accelerator can route traffic across multiple regions.
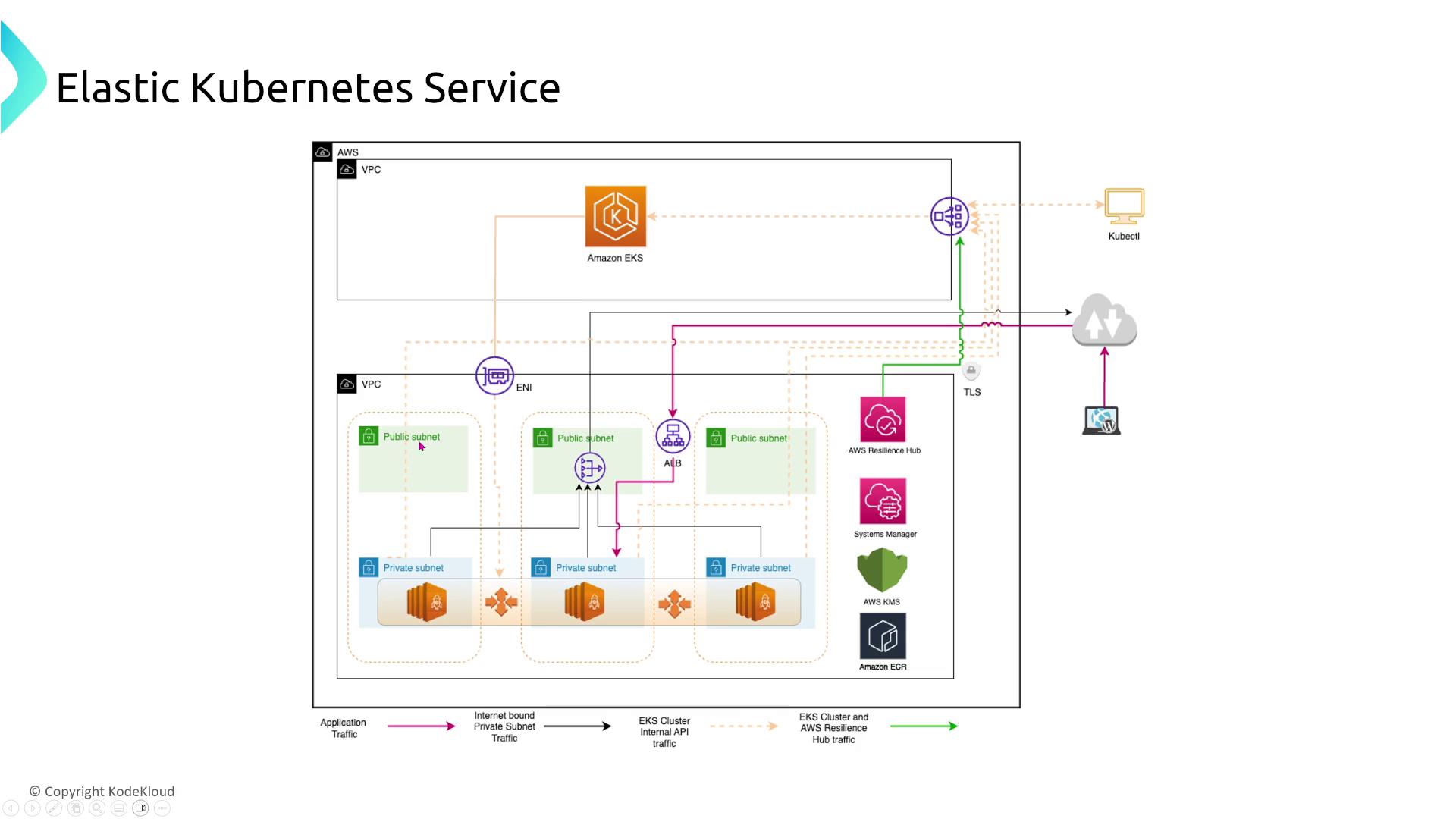
- Persistent Storage:
For stateful applications, use Kubernetes StatefulSets with Amazon EFS. Unlike EBS, which is limited to a single AZ, EFS provides shared storage across multiple AZs.
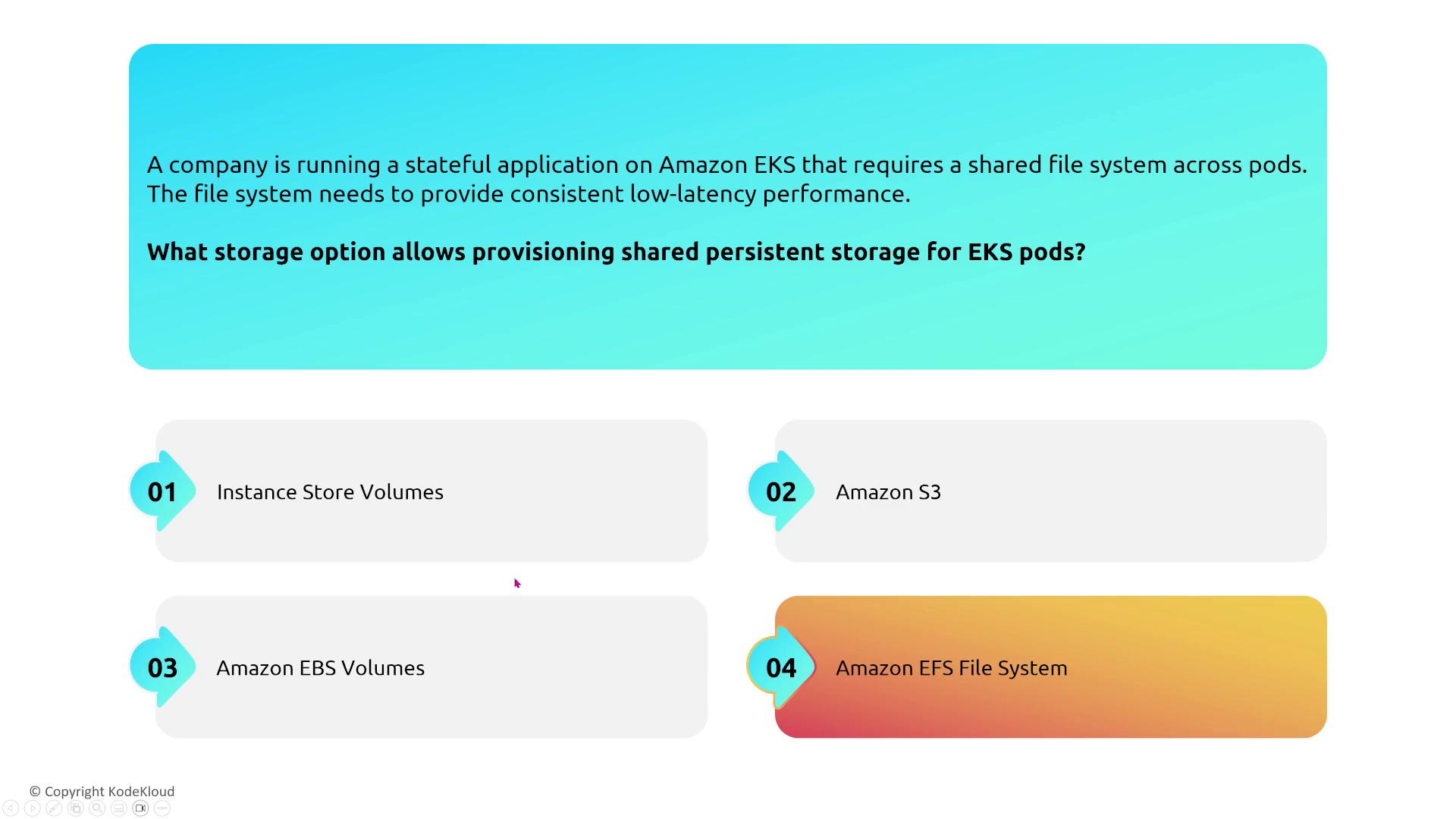
- Scalability Benefits:
Utilize pod autoscaling with the Horizontal Pod Autoscaler. Tools like Carpenter also aid in achieving both cluster-level and node-level scalability.
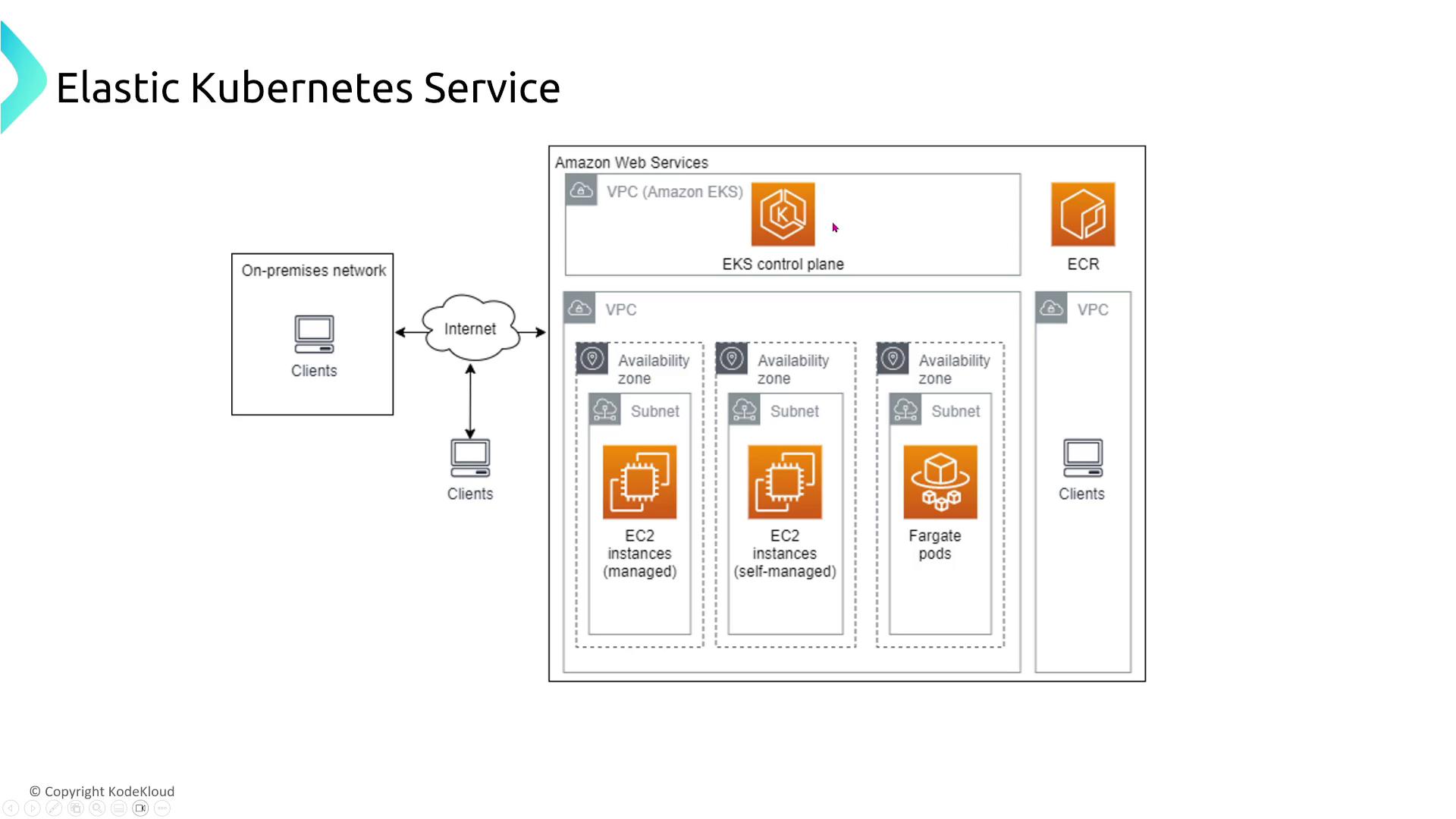
- Management Considerations:
Managed node groups in EKS automatically replace unhealthy nodes, whereas self-managed nodes require manual intervention or custom auto scaling groups.
-
Service Discovery and Logging:
Kubernetes’ DNS-based service discovery enables loosely coupled microservices. Ensure that logging and monitoring (using CloudWatch Logs and optionally OpenSearch) are set up for enhanced operational visibility. -
Shared Persistent Storage (Revisited):
For applications requiring shared storage across AZs, Amazon EFS is the preferred solution over instance storage or EBS volumes.
Amazon Elastic Container Registry (ECR)
ECR is a managed container image repository ideal for storing and managing Docker images. Although its configuration options for resiliency are limited, consider the following:-
Cross-Region Redundancy:
For businesses operating on a global scale, replicate ECR repositories across multiple regions using the new cross-region replication feature. This ensures image availability even during regional outages. -
CI/CD Pipeline Integration:
ECR integrates seamlessly with CI/CD pipelines—similar to Docker Hub or Quay. Images stored in ECR can be easily pulled into ECS or EKS clusters for deployment.
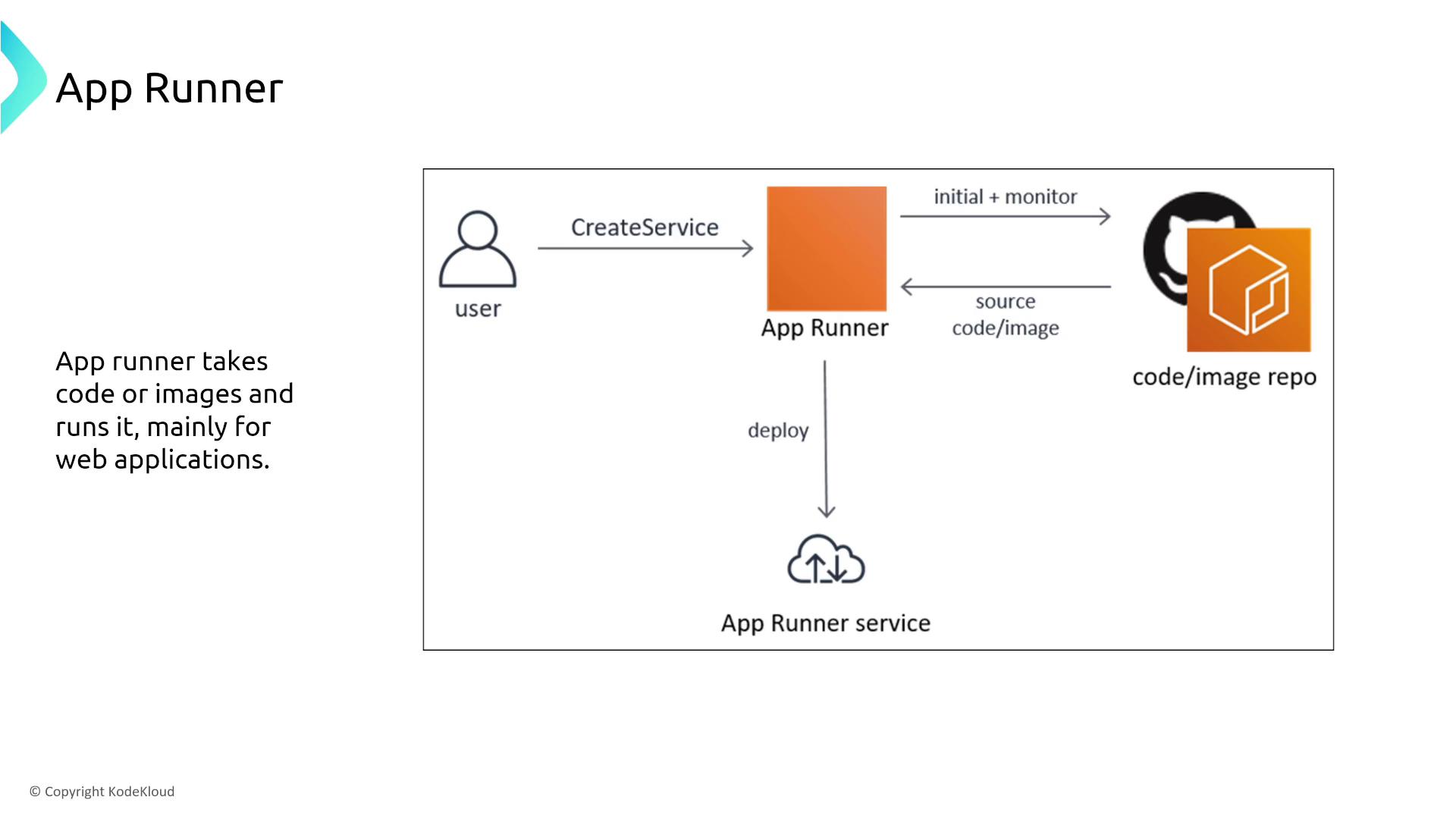
AWS App Runner
AWS App Runner is designed for developers who want to run containerized web applications without managing the underlying servers.- Resiliency and Load Distribution:
App Runner deploys container images across multiple AZs with built-in load balancing. Specify the desired number of application instances to meet your fault tolerance requirements.
-
Integration with Load Balancers:
For additional redundancy, App Runner can be paired with a Network Load Balancer (NLB). This results in a robust, serverless deployment model for containerized web applications. -
Comparison with Fargate:
While AWS Fargate offers serverless computing within ECS and EKS, App Runner abstracts even more infrastructure complexity, making it an ideal choice for developers focused on code over configuration.
AWS Batch
AWS Batch is intended for running large-scale batch jobs on containerized workloads. It orchestrates compute environments (using EC2, ECS, EKS, or Fargate) to process data-intensive tasks in parallel.- Job Resiliency:
Enhance resiliency by configuring your Batch jobs to automatically retry upon failure. Although AWS Batch distributes jobs across multiple compute instances, retry strategies are crucial to address transient issues.
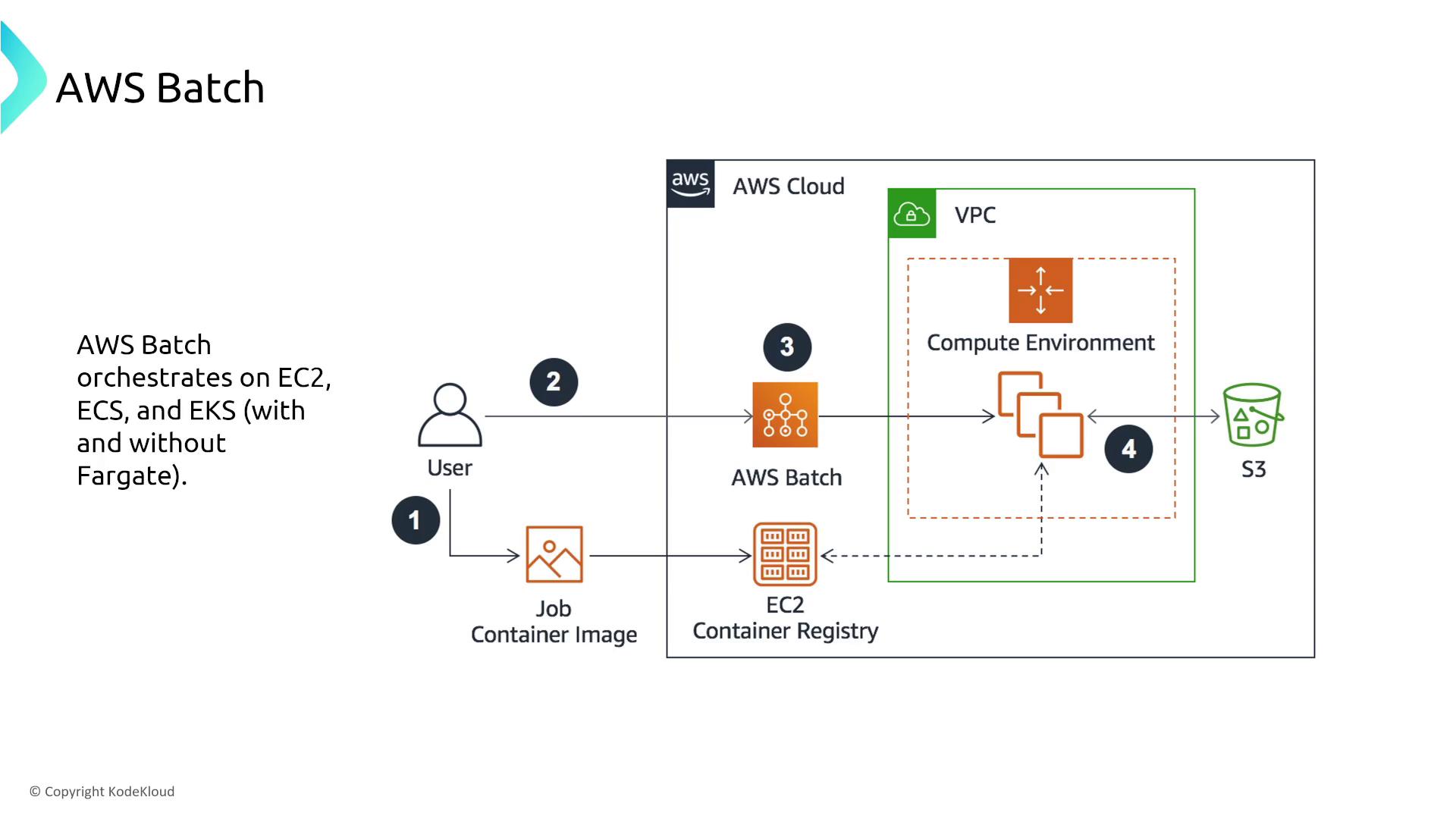

- Integration Example:
A typical AWS Batch workflow might involve an S3 file upload triggering a Lambda function, which in turn submits a Batch job (for example, on ECS Fargate). The job processes the data and writes the results to DynamoDB. Including retry strategies in your Batch job definitions further improves reliability.
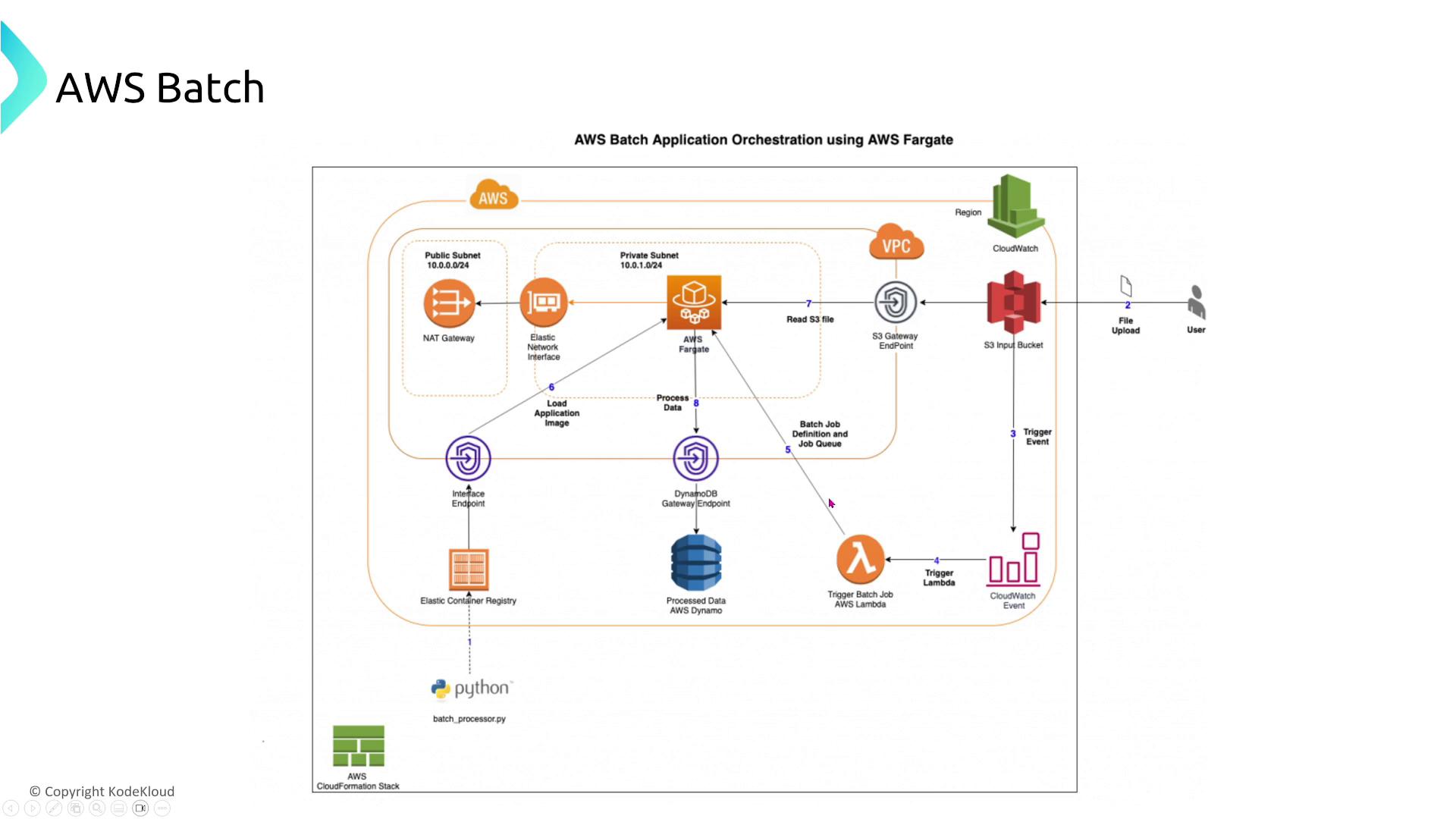

Beyond leveraging automatic retries, AWS Batch is engineered to self-manage capacity, scaling, and workload distribution. This minimizes manual configuration at the associate level.
Summary
Across all AWS compute services—whether deploying containerized applications via ECS or EKS, running web apps with App Runner, or processing batch workloads with AWS Batch—the cornerstone of achieving reliability is to:- Deploy multiple instances across diverse AZs.
- Enable auto scaling and health checks for automatic recovery.
- Use shared storage (e.g., Amazon EFS) for stateful workloads.
- Integrate comprehensive logging and monitoring for operational transparency.