- Difficulty reliably extracting structured fields (IDs, statuses, severities).
- Inconsistent severity labels (low/medium/high) across responses.
- Unpredictable formats that break downstream integrations (databases, APIs, analytics).

- Agent-level schemas (input and output models).
- Tool-level structured results (tools that return typed objects).

Agent-level schemas (typed agents)
Agent-level schemas let you give an ADK agent explicit input and output models (for example, Pydantic classes). This makes the agent behave like a typed function: it accepts structured inputs and is guided to return a fixed JSON shape.
output_schema. ADK steers the model to emit JSON matching that schema so the system reliably receives a capital field instead of a paragraph.
- invoke tools,
- perform retrieval-augmented generation (RAG),
- or hand off to other agents.

Agent-level output schemas are excellent when your agent should behave like a deterministic function and return a fixed schema. If your workflow requires calling tools or RAG, prefer structured tool outputs instead.
Tool-level structured outputs (recommended for help desk)
The second approach is to make each tool return a strictly structured object (dict or Pydantic model). ADK can generate schemas from type hints and docstrings so the LLM sees tools as reliable, JSON-shaped building blocks. This is the pattern we’ll use for ticket creation. Benefits:- Tools guarantee the return shape (e.g., ticket fields), making downstream integration deterministic.
- Agents remain free to orchestrate multiple tools, call external services, and perform RAG.
- Easier to log, persist, and analyze outputs because the shape is standardized.
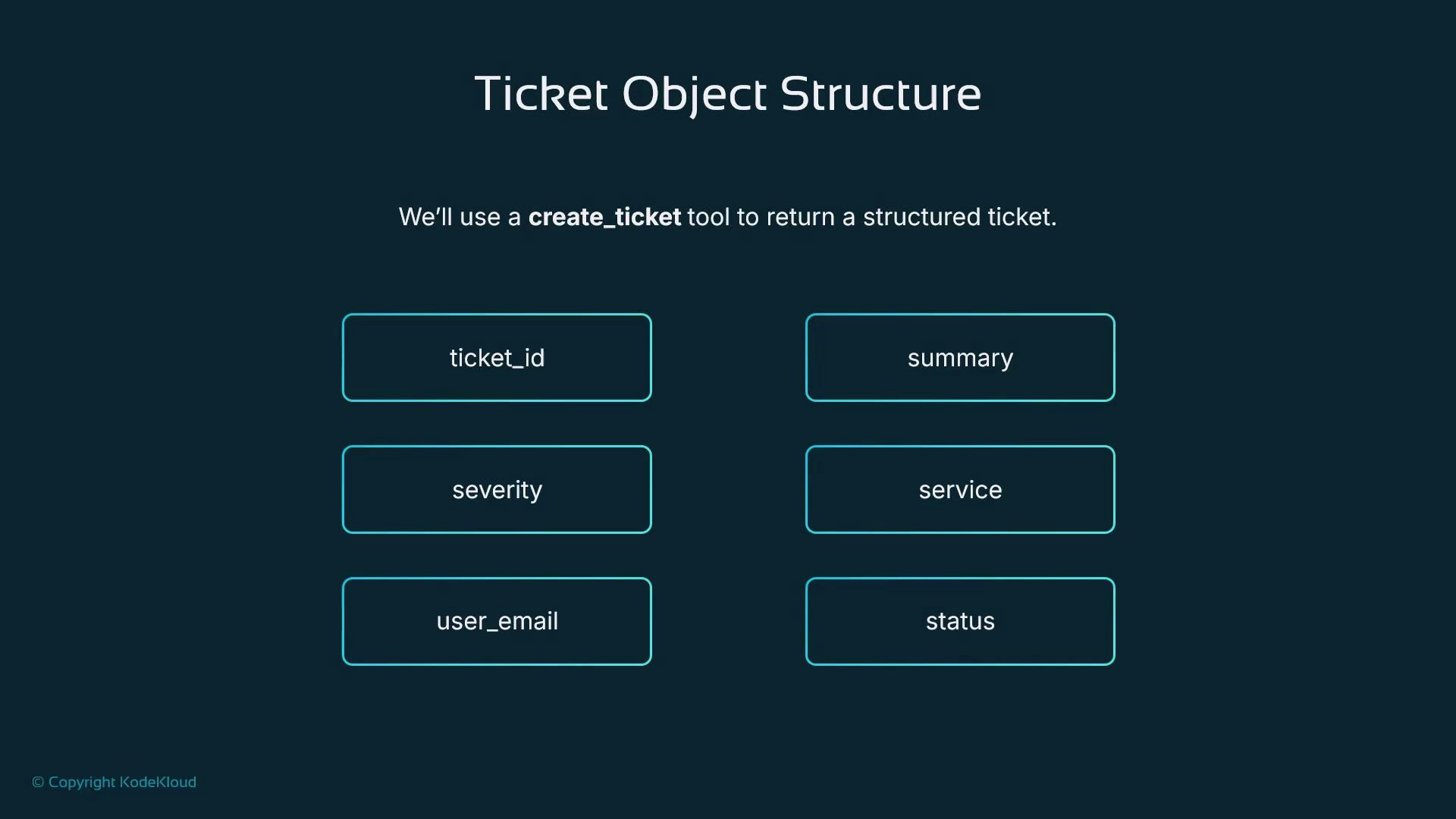
ticket_id, summary, severity, service, user_email, and status. Once that contract is enforced, other systems (databases, dashboards, external platforms) can consume tickets without extra parsing.
- decides whether a ticket is needed,
- calls the
create_tickettool when appropriate, - receives a structured ticket object back, and
- responds to the user with a clear confirmation such as: “I’ve created ticket IT-1234 with severity high for the VPN outage.”

Implementation plan — concrete next steps
To move from concept to working ADK code, we’ll:- define the ticket Pydantic schema,
- implement the
create_ticketfunction tool that returns a typed ticket object, - register and wire that tool into the help desk agent flow so the agent can open tickets when needed,
- log and persist tickets (DB / external API / analytics).

References and further reading
- Large language model — Wikipedia
- Pydantic documentation
- Retrieval-augmented generation (RAG) — Wikipedia
- Kubernetes Documentation (for related orchestration patterns)
When you choose agent-level schemas, remember you trade off orchestration and tool calls. For help desk workflows that must interact with services or perform multi-step logic, use tool-level structured outputs.