Subjective Quality and Custom Needs
Assessing the quality of LLMs is inherently challenging because a “good” model is subjective. Criteria for model performance and behavioral traits vary from user to user. When incorporating proprietary data with Retrieval Augmented Generation (RAG), the evaluation process becomes twofold:- Measure the effectiveness of the retrieval component to ensure that the most relevant context is consistently fetched.
- Verify that the model leverages that context to produce accurate and useful responses.
Blind Testing and Community Benchmarks
A widely accepted approach to evaluating models is to consider public and blind test feedback. In blind tests, evaluators compare two models and choose the one that generates higher-quality responses. One notable example is the Chatbot Arena, which displays rankings and scores for various AI models. Currently, the leaderboard indicates that proprietary models generally perform exceptionally well. The image below illustrates the leaderboard provided by Chatbot Arena: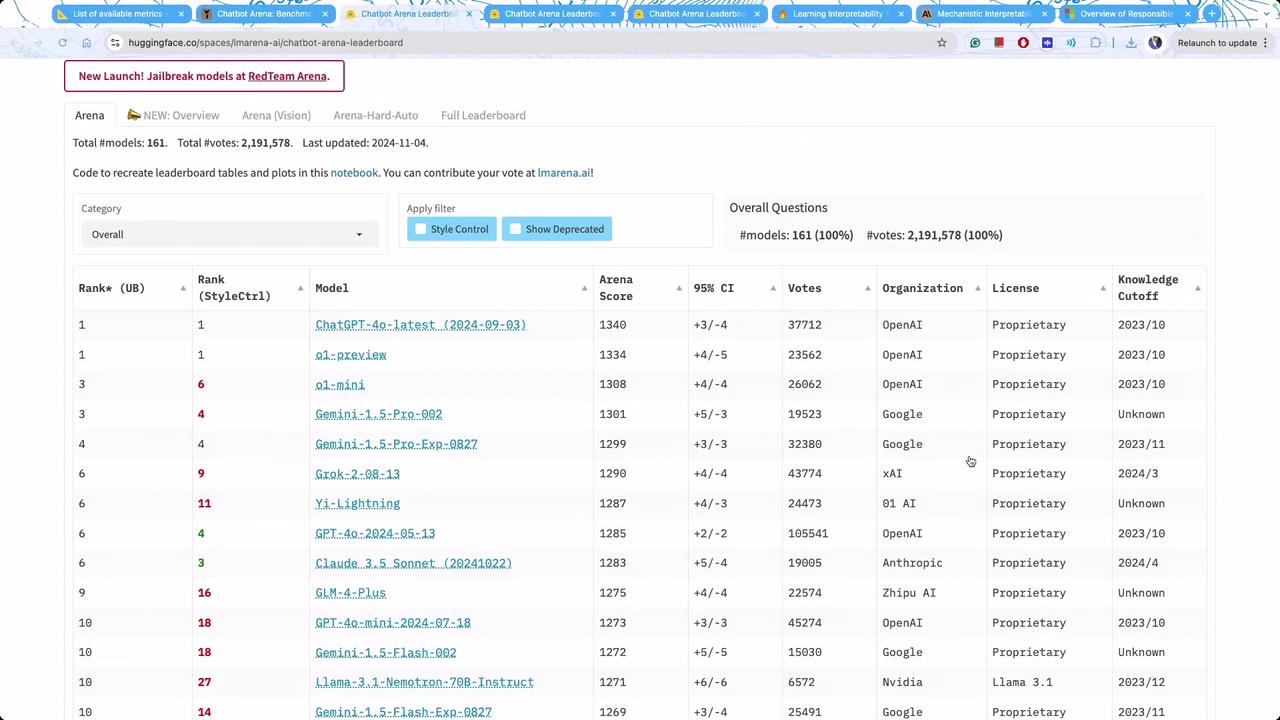
Proprietary models often outperform meta models in user interaction contexts despite sometimes ranking lower on standardized tests such as MMLU.
Evaluating Technical and Conversation Metrics
Techniques like reinforcement learning from human feedback (or even AI-driven reinforcement) have been pivotal in aligning proprietary models closely with human expectations. When evaluating models through both technical metrics (like MMLU) and human preferences, a strong correlation emerges between user satisfaction and model ranking. However, it’s important to note that models developed by major organizations (“meta models”) may excel in standardized testing but may not perform as naturally or effectively in conversational settings. For RAG systems, additional metrics become critical:- Context Recall: Ensures relevant context is correctly retrieved for the model.
- Noise Sensitivity: Assesses how distractions or irrelevant data affect model performance.
Conclusion
A comprehensive evaluation framework is essential for building robust Generative AI applications. By combining standardized tests with custom RAG metrics, organizations can accurately identify both strengths and areas for improvement in their models. Establishing clear evaluation criteria is fundamental to continuously enhancing the performance of LLMs and RAG systems.A well-defined evaluation framework enables a balanced view of model capabilities, ensuring that both technical performance and user experience improvements are tracked effectively.