
- The demo runs a compute task that can be executed on a single core or split across multiple cores (up to 8).
- For each run it measures elapsed time, then prints the time for that number of cores.
- Finally, it plots execution time (vertical axis) against number of cores (horizontal axis).
Notes on variability and OS behavior
- The operating system schedules tasks across available cores; background processes or OS services may run on any core, so you can observe minor activity on apparently idle cores.
- The biggest jump usually occurs from 1 to 2 cores because the workload can be divided. Further cores continue to reduce time but with decreasing gains.
- Diminishing returns arise from two main sources:
- Parts of the task that must run serially (cannot be parallelized).
- Shared hardware resources (memory bandwidth, caches, buses) and synchronization/coordination overhead.
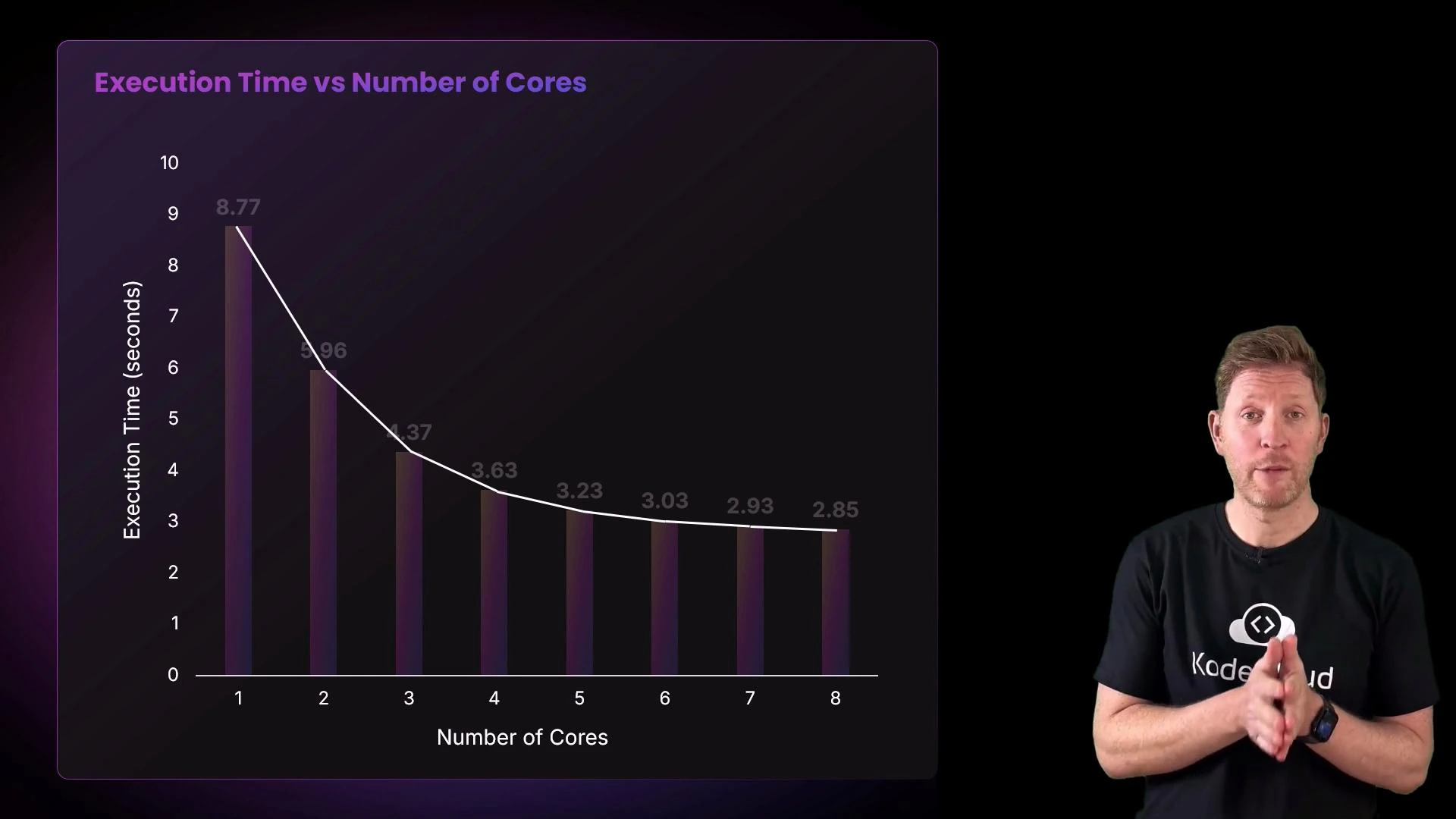
Adding cores speeds up parallelizable work, but coordination overhead and contention for shared resources cause diminishing returns. The actual speedup depends on how well the workload can be divided and on system-level bottlenecks like memory bandwidth and cache behavior.
- Adding processors or cores increases throughput for parallel workloads, but improvements diminish as core count increases due to contention and coordination costs.
- If a workload has little or no parallelizable portion, additional cores will remain idle and not improve performance.
- For problems that require massive parallelism (e.g., many graphics or ML workloads), GPUs or other accelerators are better suited than CPUs because they offer thousands of parallel execution units.

- CPUs execute instructions via the fetch–decode–execute cycle.
- Multiple cores can improve throughput for parallel workloads.
- Scaling is eventually limited by resource contention and the portion of a workload that is inherently serial.
- Amdahl’s Law: https://en.wikipedia.org/wiki/Amdahl%27s_law
- GPUs and parallel accelerators: https://en.wikipedia.org/wiki/Graphics_processing_unit