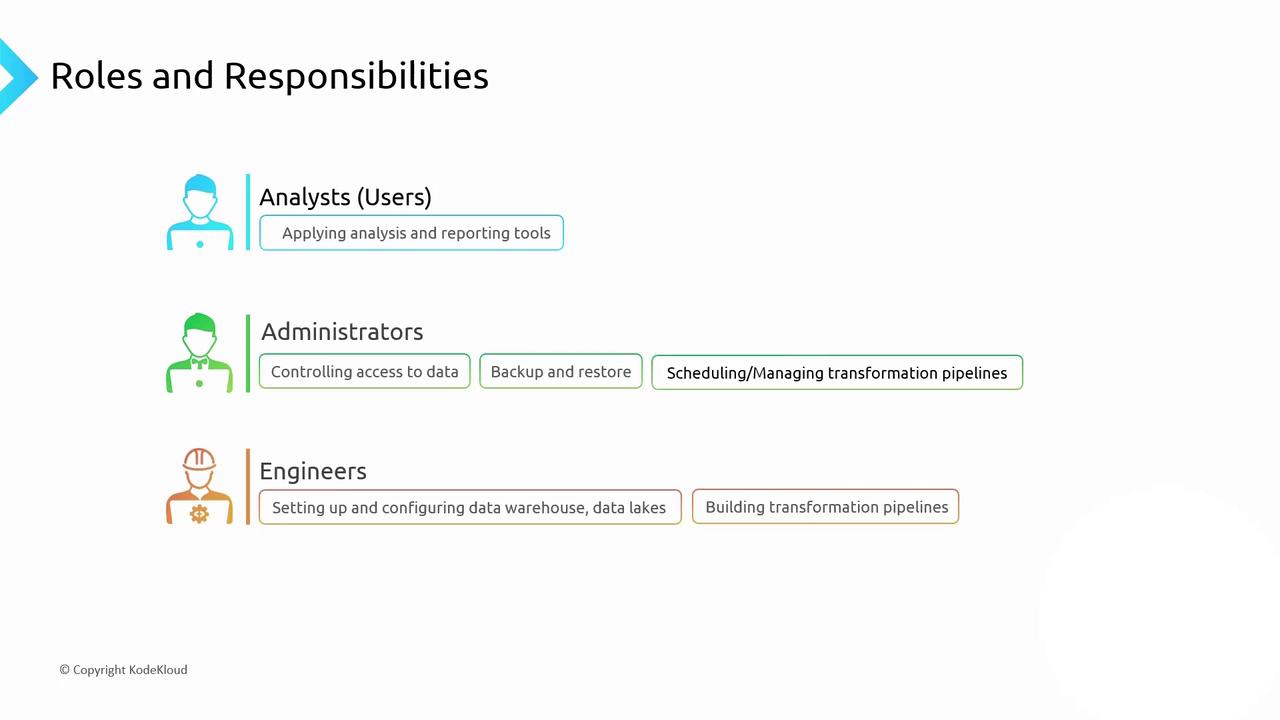
Perform backups and restores |
| Data Engineers| Pipeline architecture & data integration | - Design & build ETL/ELT workflows
Integrate heterogeneous data sources
Optimize performance and resource configurations |
Analysts only need access to their datasets and BI tools, while administrators and engineers require broader interfaces to manage, secure, and optimize pipelines.
Power BI Desktop: Free authoring environment with integrated Power Query for ETL
Power BI Service: Cloud-hosted platform for sharing dashboards, paginated reports, and real-time monitoring
Carefully manage dataset permissions in Power BI Service to maintain data privacy and security.
This concludes our module on analyzing data. You now have a clear understanding of the roles, responsibilities, and tools that form the foundation of any analytics lifecycle.