This lesson explores the storing phase of the data pipeline in Azure, focusing on optimal storage solutions for analytics and batch processing.
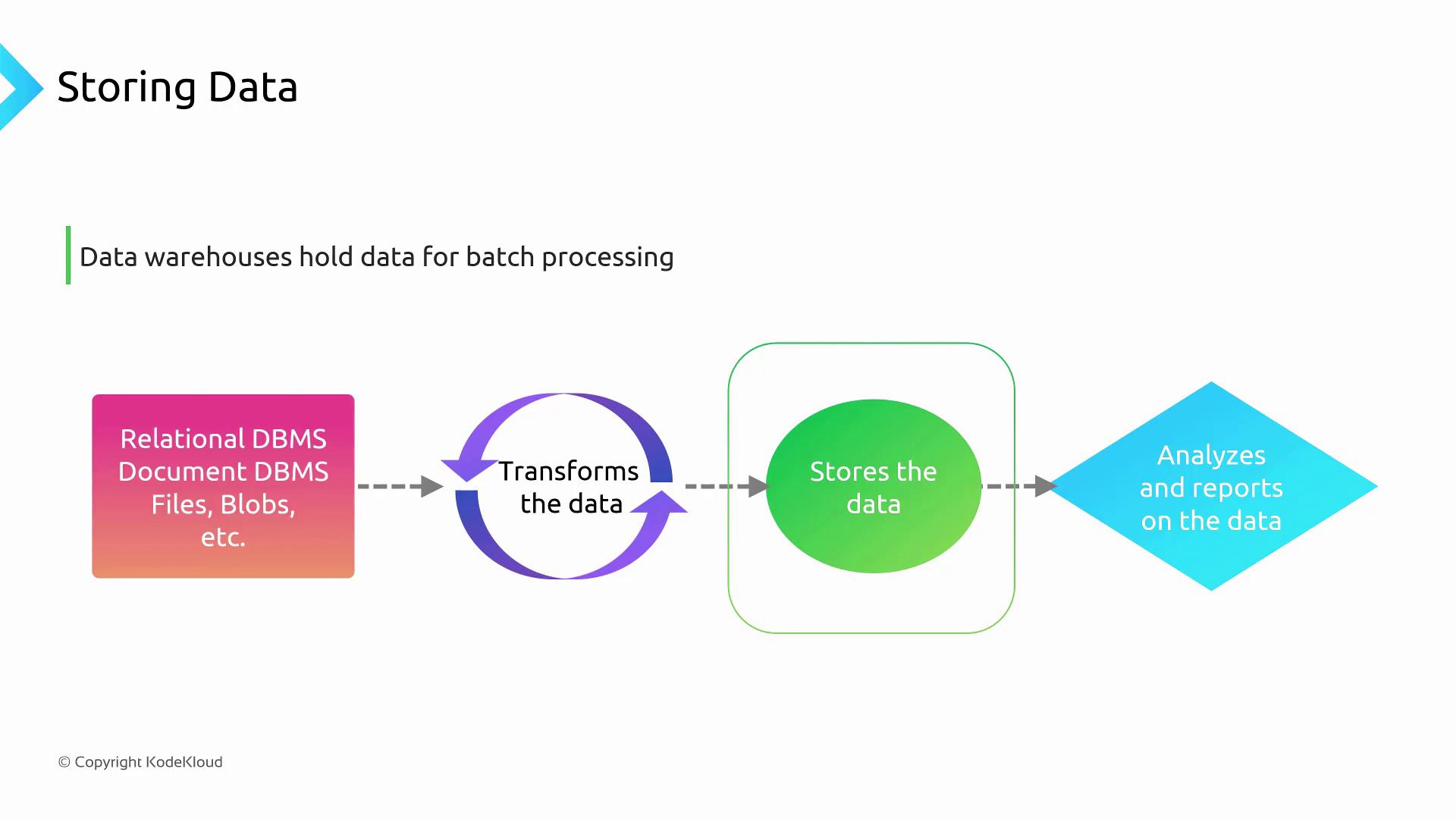
In this lesson from the Azure Data Fundamentals (DP-900) course, we explore the Storing phase of the data pipeline. After extracting and transforming data with Azure Data Factory, the next step is to load your cleansed data into the optimal storage solution for batch processing, reporting, and analytical workloads.
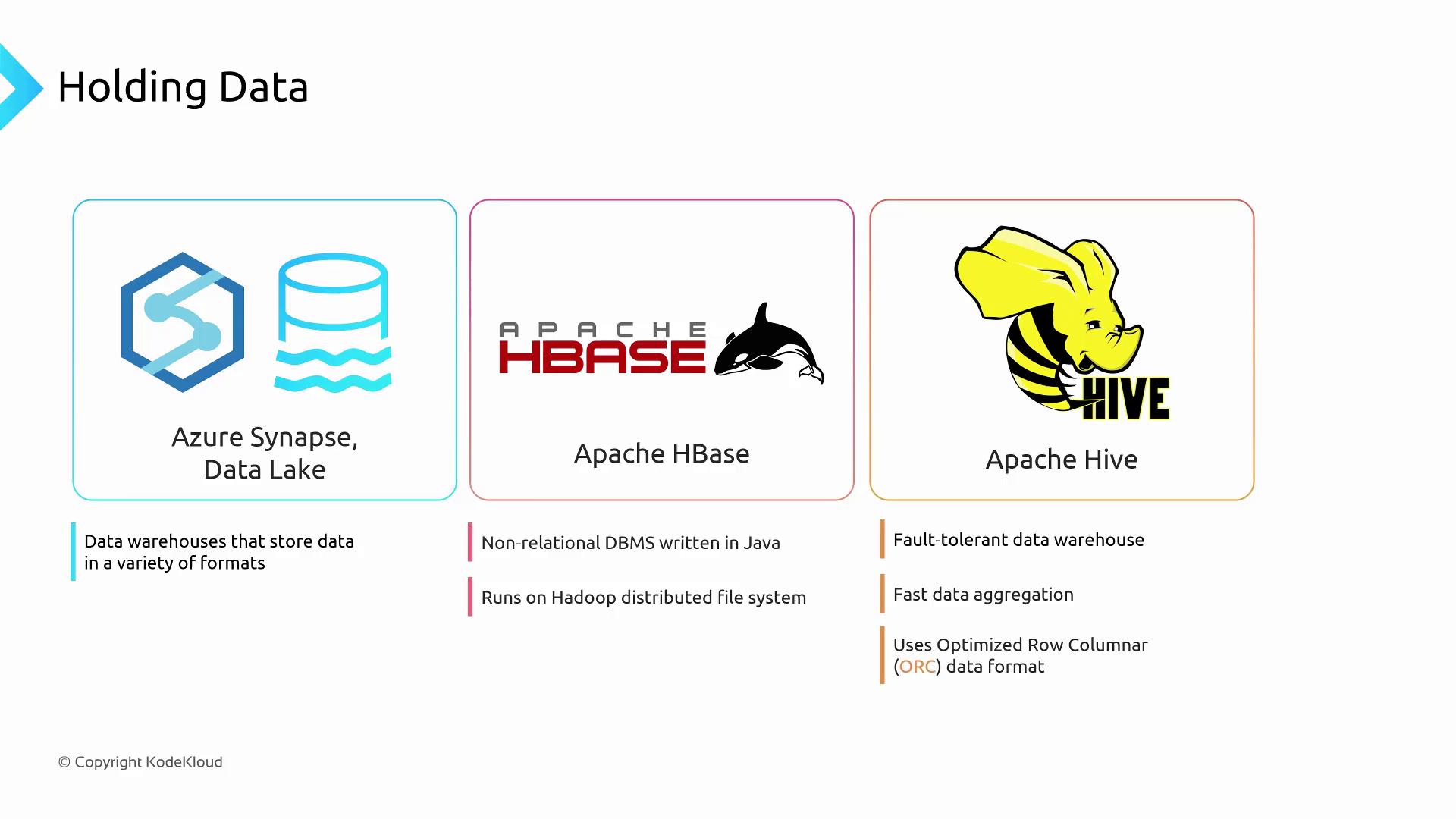
Azure Synapse Analytics and Azure Data Lake Storage
Azure Synapse Analytics integrates seamlessly with Azure Data Lake Storage (ADLS). You can store data in multiple formats—CSV, Parquet, JSON, and more—and use PolyBase to run T-SQL queries directly against your files.
No ETL is required before querying. PolyBase pushes computation down to ADLS, boosting performance and reducing costs.
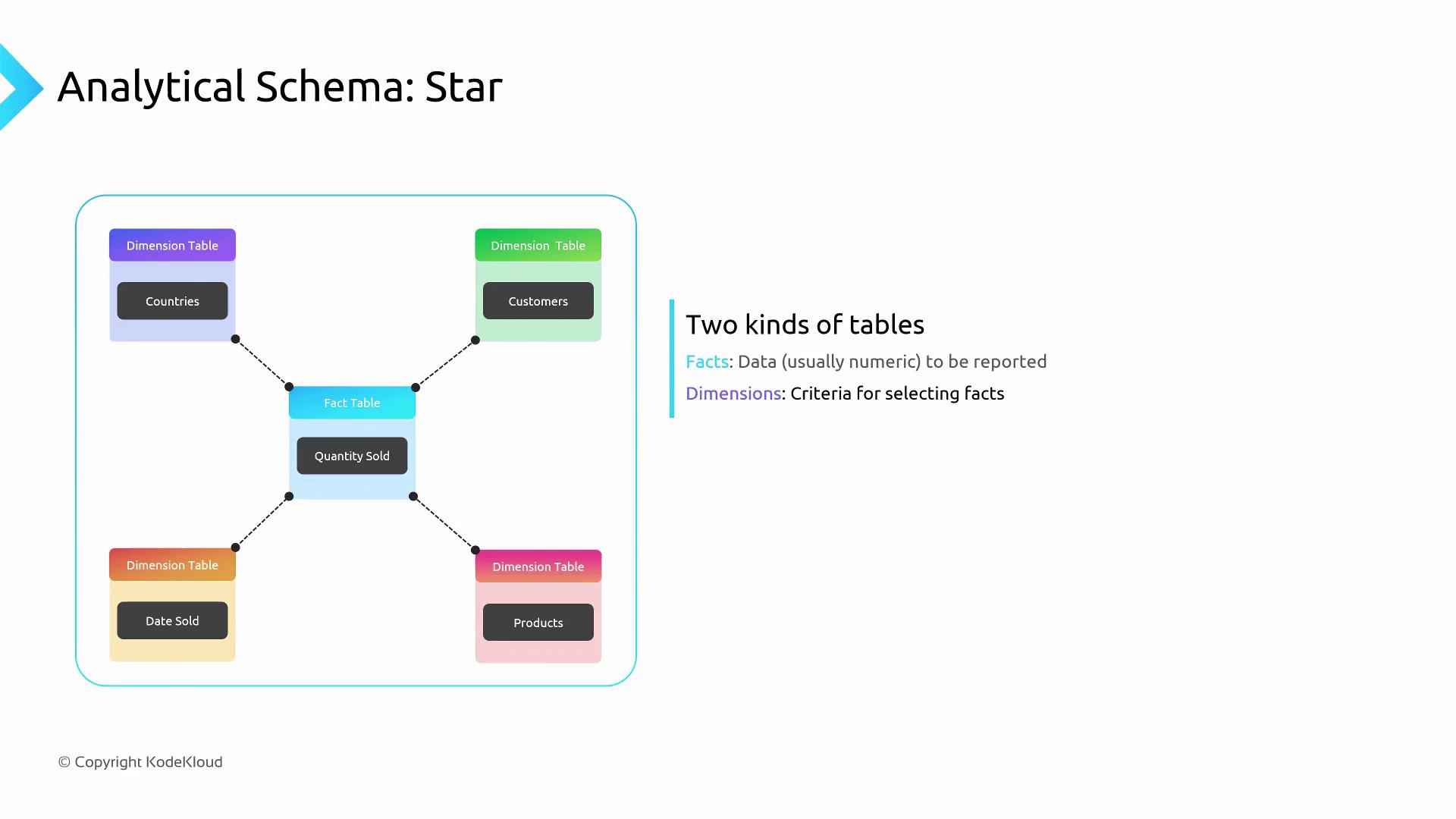
When designing for analytics, your table schemas often deviate from OLTP patterns. Two popular modeling techniques are the Star Schema and the Cube Schema.
A star schema centers around a fact table containing numeric measures (e.g., sales amounts), linked to multiple dimension tables (e.g., Customer, Product, Date).
Fact table: Holds transactional metrics over time.
Dimension tables: Store descriptive attributes for filtering and grouping.
This model simplifies SQL joins and enhances query performance, especially in Azure Synapse dedicated SQL pools.
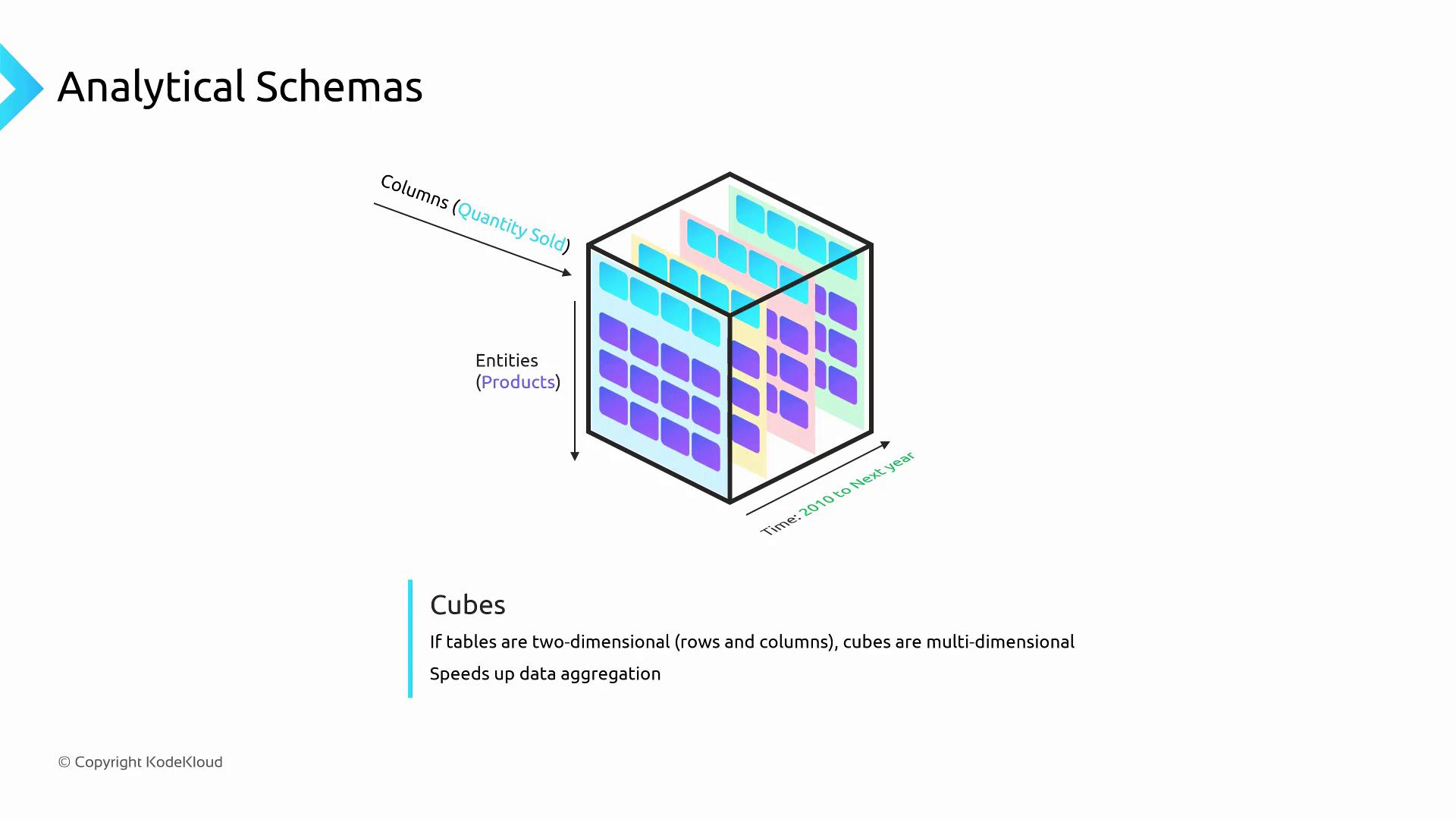
A cube schema extends beyond two dimensions by stacking multiple slices of data—each slice represents the fact table at a specific dimension value (e.g., year).
Fast aggregations along time, geography, and product axes.
Pre-aggregated views reduce query runtime.
Scales to 4+ dimensions in many OLAP systems.
Cubes optimize dashboards and BI tools that require instant drill-downs and rollups.
Some OLAP solutions support even more dimensions—each tailored for specialized analytical queries.