- GPT: Large language model for text tasks
- DALL·E: Text-to-image synthesis
- Whisper: Automatic speech recognition and translation
Generative Pre-trained Transformer (GPT)
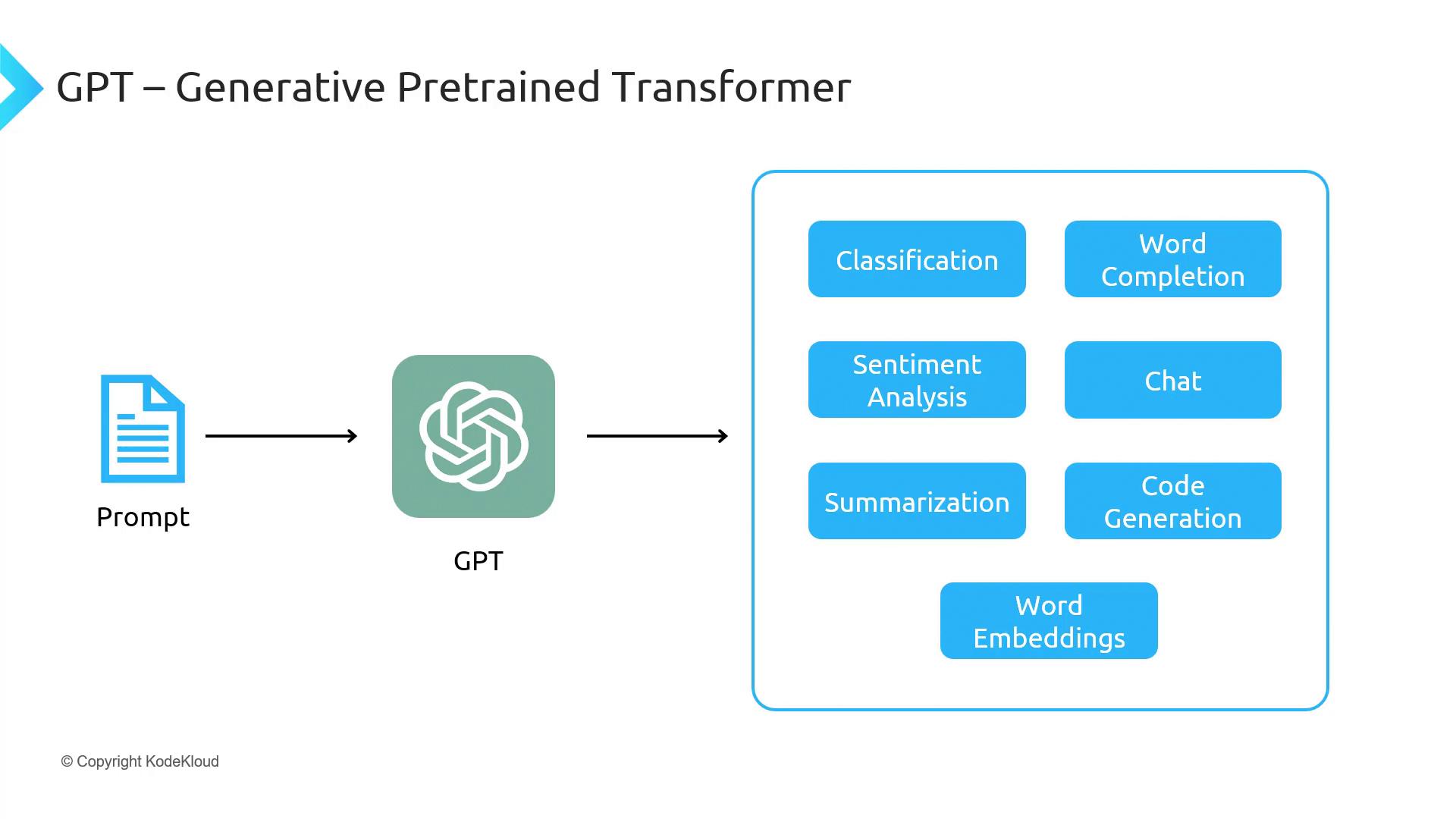
The Generative Pre-trained Transformer (GPT) is a transformer-based large language model trained on massive public-domain text corpora. It excels at generating contextually relevant text and supports a wide range of natural-language tasks.GPT-3.5 is the current public release with 175 billion parameters. GPT-4 offers enhanced capabilities but is accessible only to approved users via the OpenAI waitlist.
Key Capabilities of GPT-3.5
| Task | Description | Example API Call |
|---|---|---|
| Text Generation | Continue or complete text | openai.chat.completions.create({ model: "gpt-3.5-turbo", ... }) |
| Code Generation | Produce code snippets in multiple languages | openai.chat.completions.create({ prompt: "Write Python sort...", ... }) |
| Summarization | Condense long documents | openai.chat.completions.create({ prompt: "Summarize research...", ... }) |
| Sentiment Analysis | Classify emotional tone | openai.chat.completions.create({ prompt: "Analyze sentiment of...", ... }) |
| Chat & Q&A | Interactive conversations | openai.chat.completions.create({ messages: [...], ... }) |
| Embeddings | Vector representations for search & clustering | openai.embeddings.create({ model: "text-embedding-ada-002", ... }) |
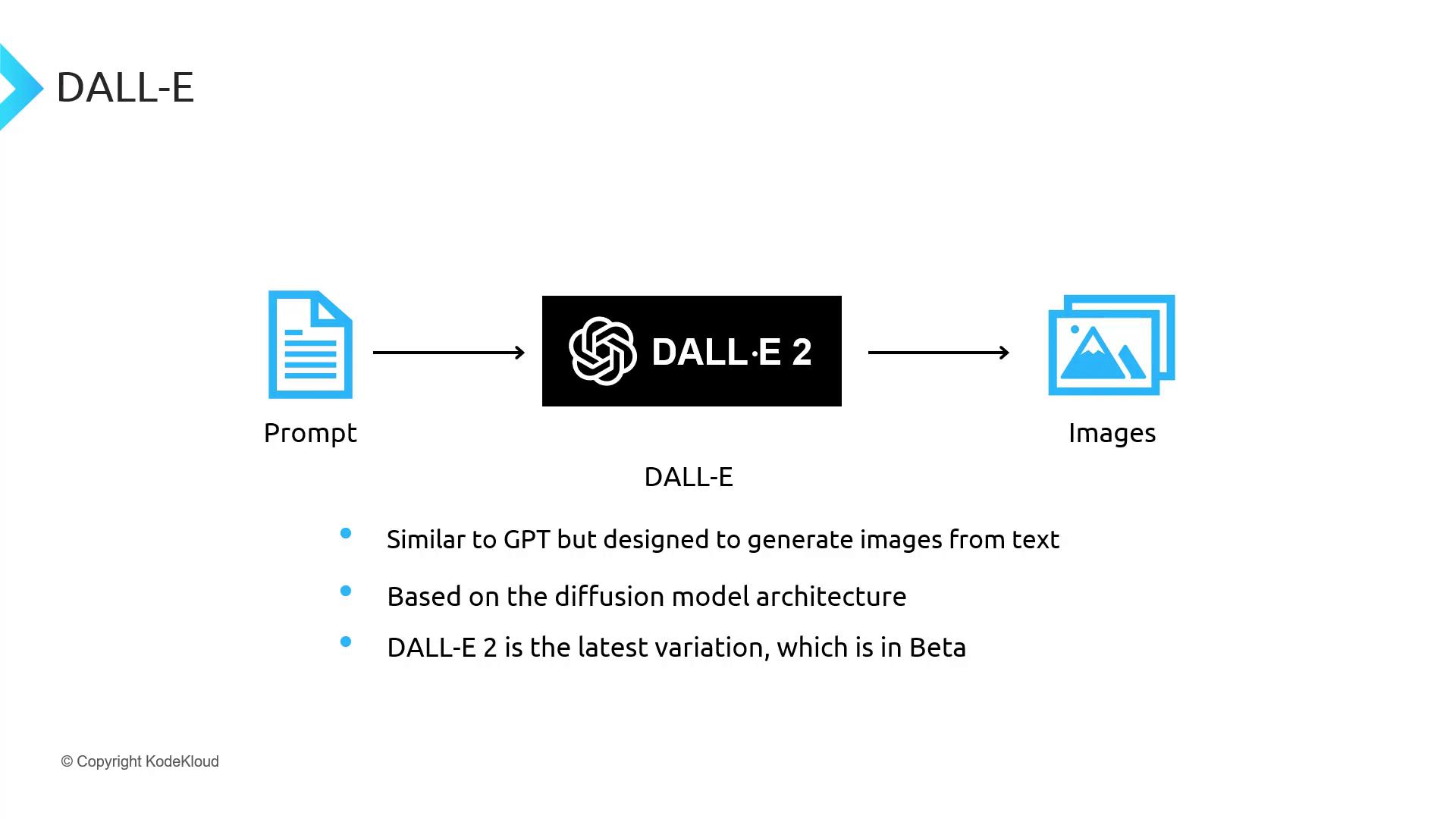
DALL·E: Text-to-Image Generation
DALL·E 2 is a diffusion-based model that transforms textual descriptions into high-fidelity images. It uses a two-step process: first generating a low-resolution image, then upscaling it.Generating an Image with DALL·E 2
DALL·E 2 is currently in beta. Image credits and usage rights vary—review the OpenAI Image Policy before deploying.
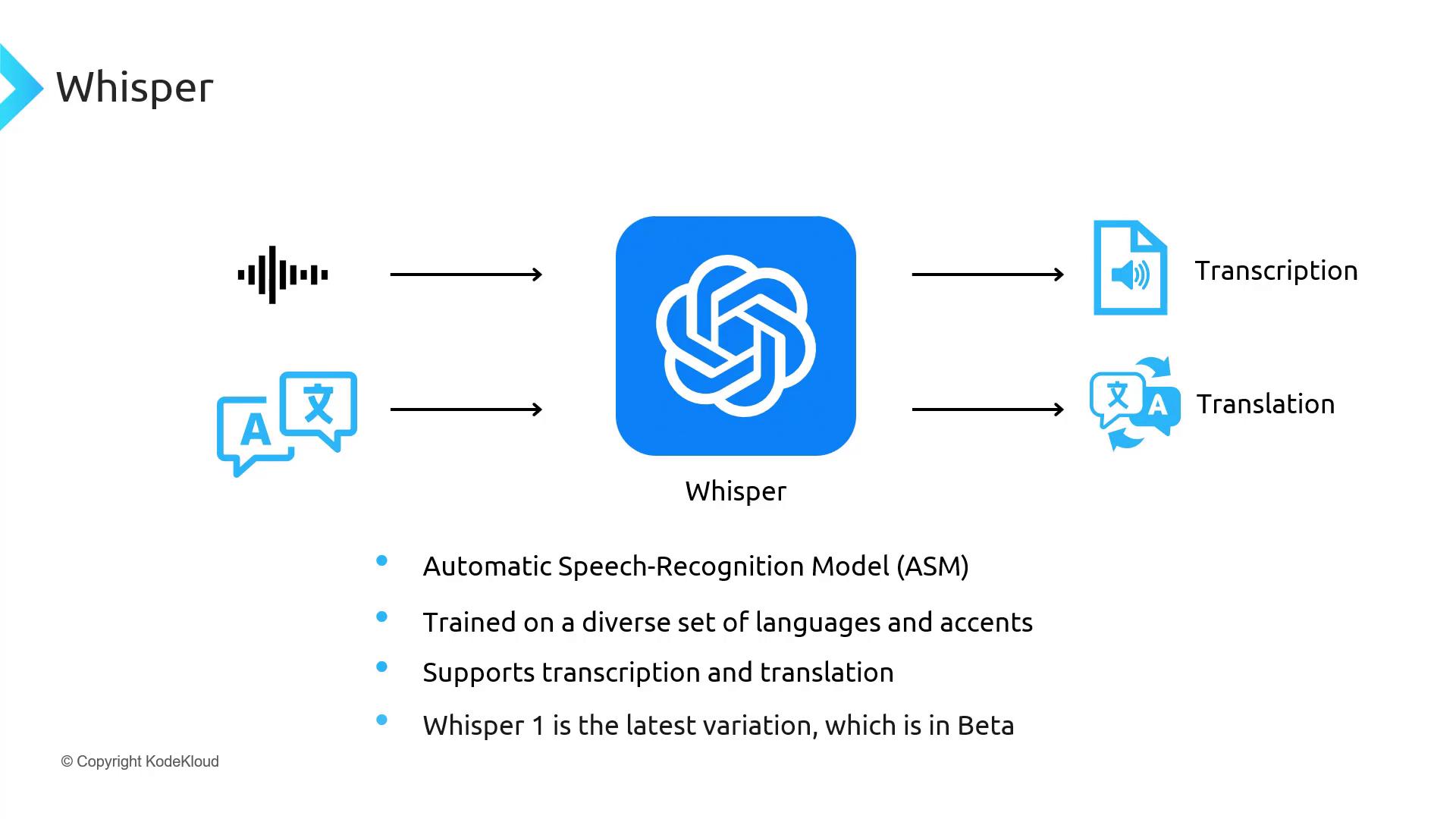
Whisper: Automatic Speech Recognition
Whisper is a versatile ASR model trained on diverse languages, accents, and audio qualities. It provides both transcription and translation features out of the box.Transcribing Audio with Whisper
Audio files with background noise or overlapping speakers may reduce transcription accuracy. Preprocess audio with noise reduction when possible.
Summary of OpenAI Foundation Models
| Model | Primary Function | Release Status | Example Use Cases |
|---|---|---|---|
| GPT-3.5 | Text generation & comprehension | Production | Chatbots, content creation, code gen |
| DALL·E 2 | Text-to-image synthesis | Beta | Marketing art, concept design |
| Whisper | Speech transcription & translation | Beta | Meeting transcriptions, subtitles |