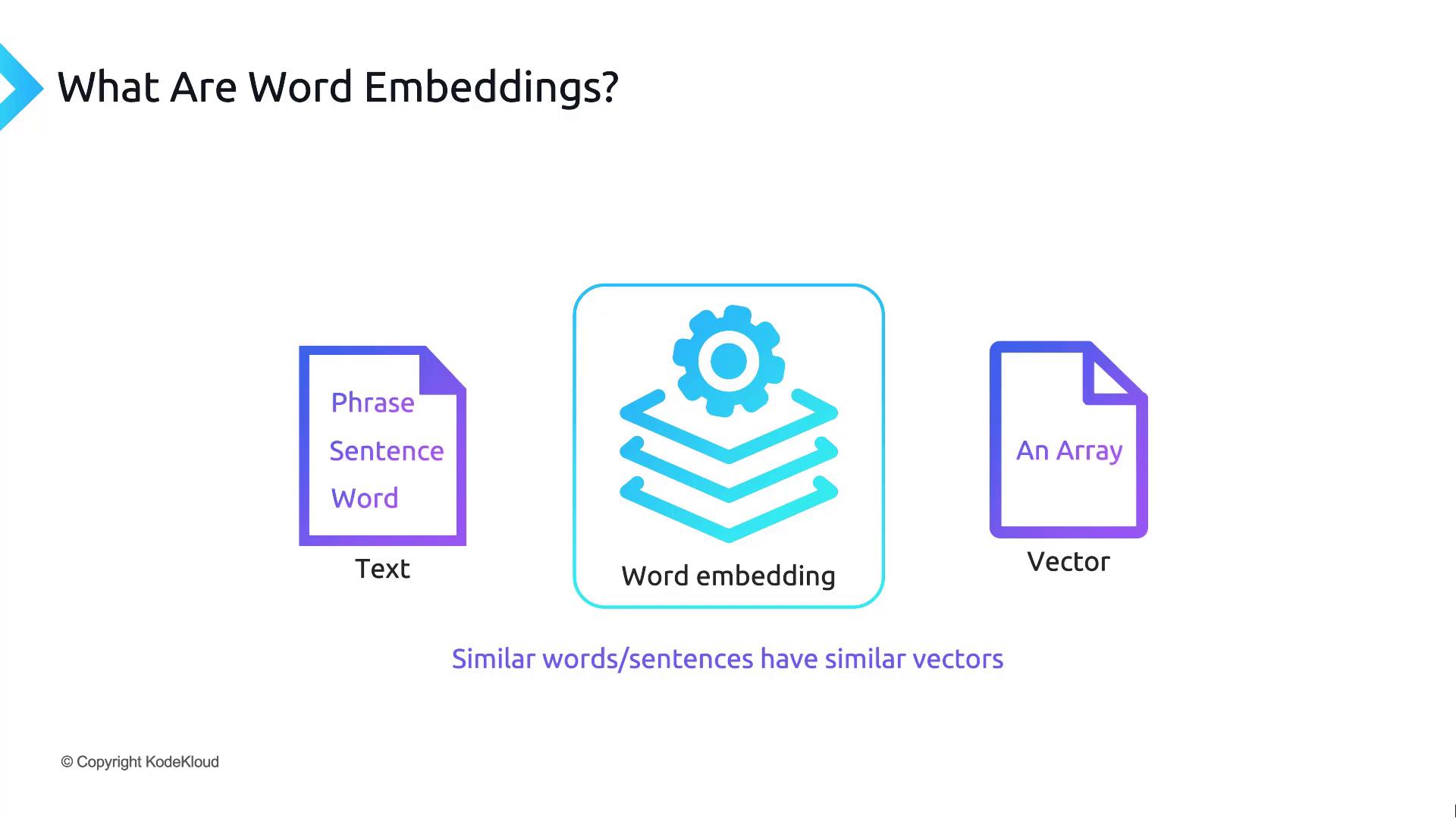
How Embeddings Power Language Models
Large language models (LLMs) use embeddings as a foundational building block. Before processing text, they tokenize the input and transform those tokens into dense vectors, capturing semantic and syntactic features.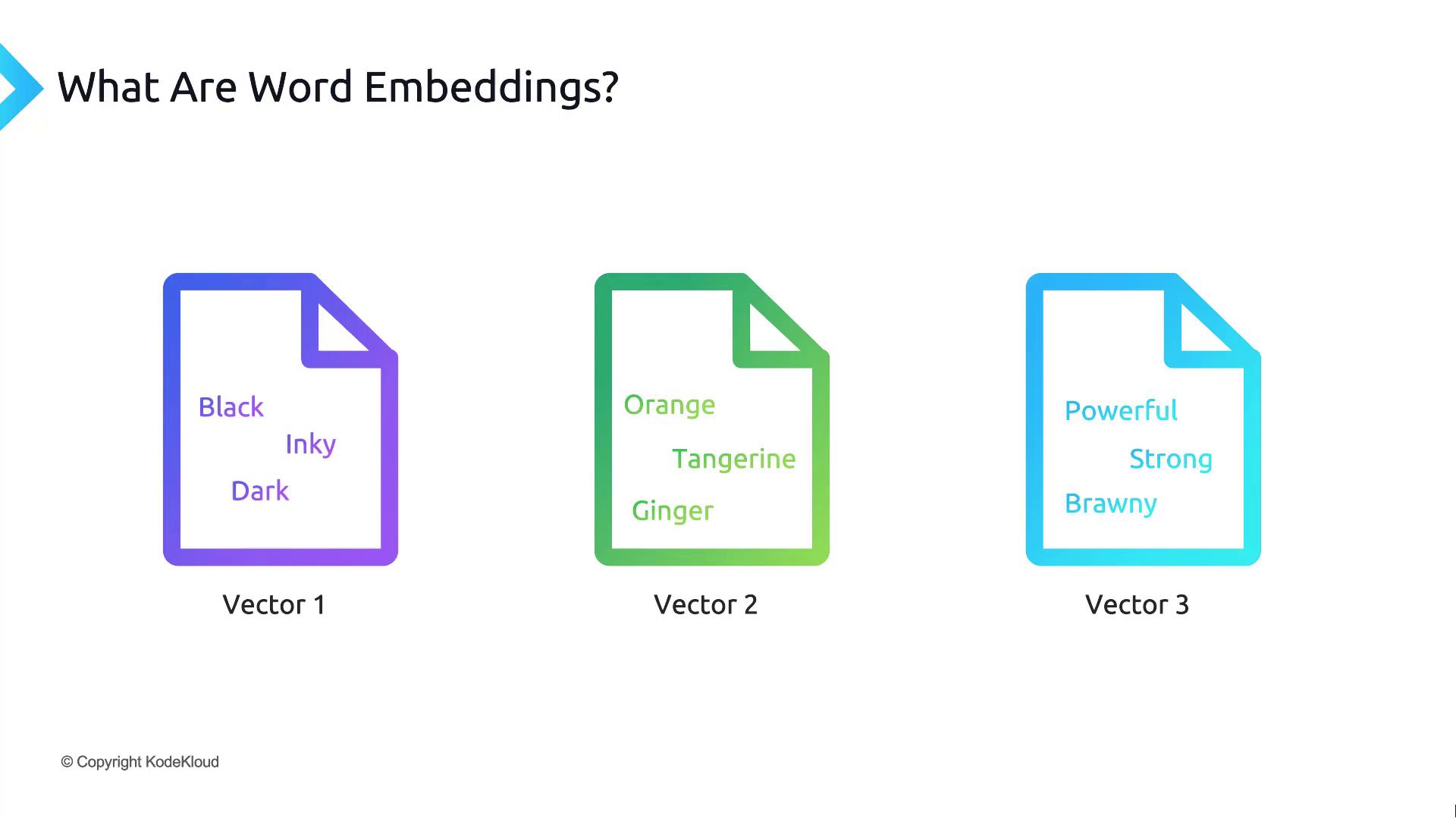
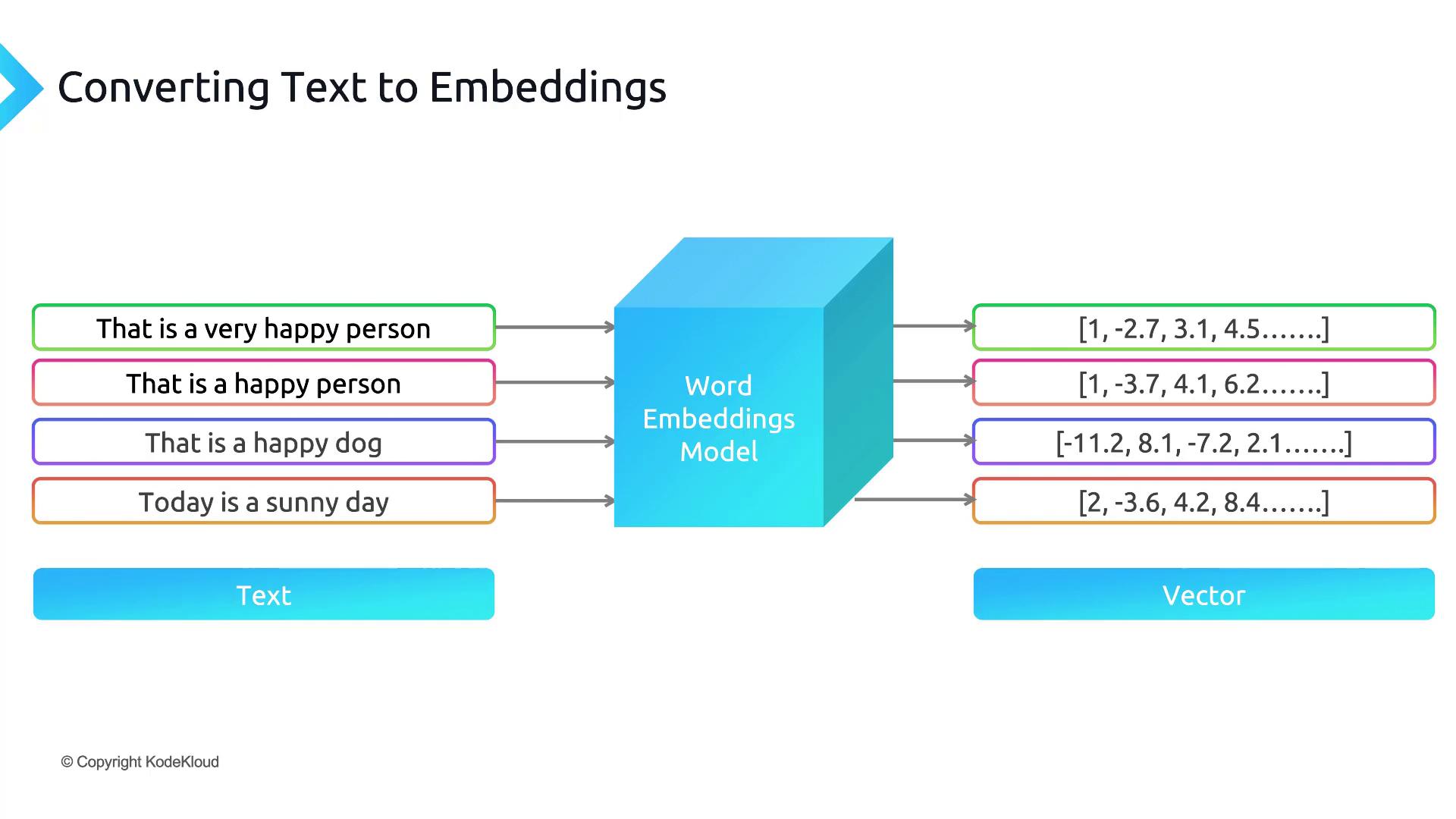
Embedding Workflow
- Prepare any text (a single word up to a large document).
- Send it to an embedding model API.
- Receive a numerical vector encoding its meaning.
Embeddings typically have hundreds to thousands of dimensions. Despite their size, they enable efficient similarity computations and downstream tasks such as clustering, recommendation, and semantic search.
Measuring Similarity: Cosine Similarity
To compare two embedding vectors, we often use cosine similarity, which measures the cosine of the angle between them: cos(θ) = (A · B) / (||A|| ||B||)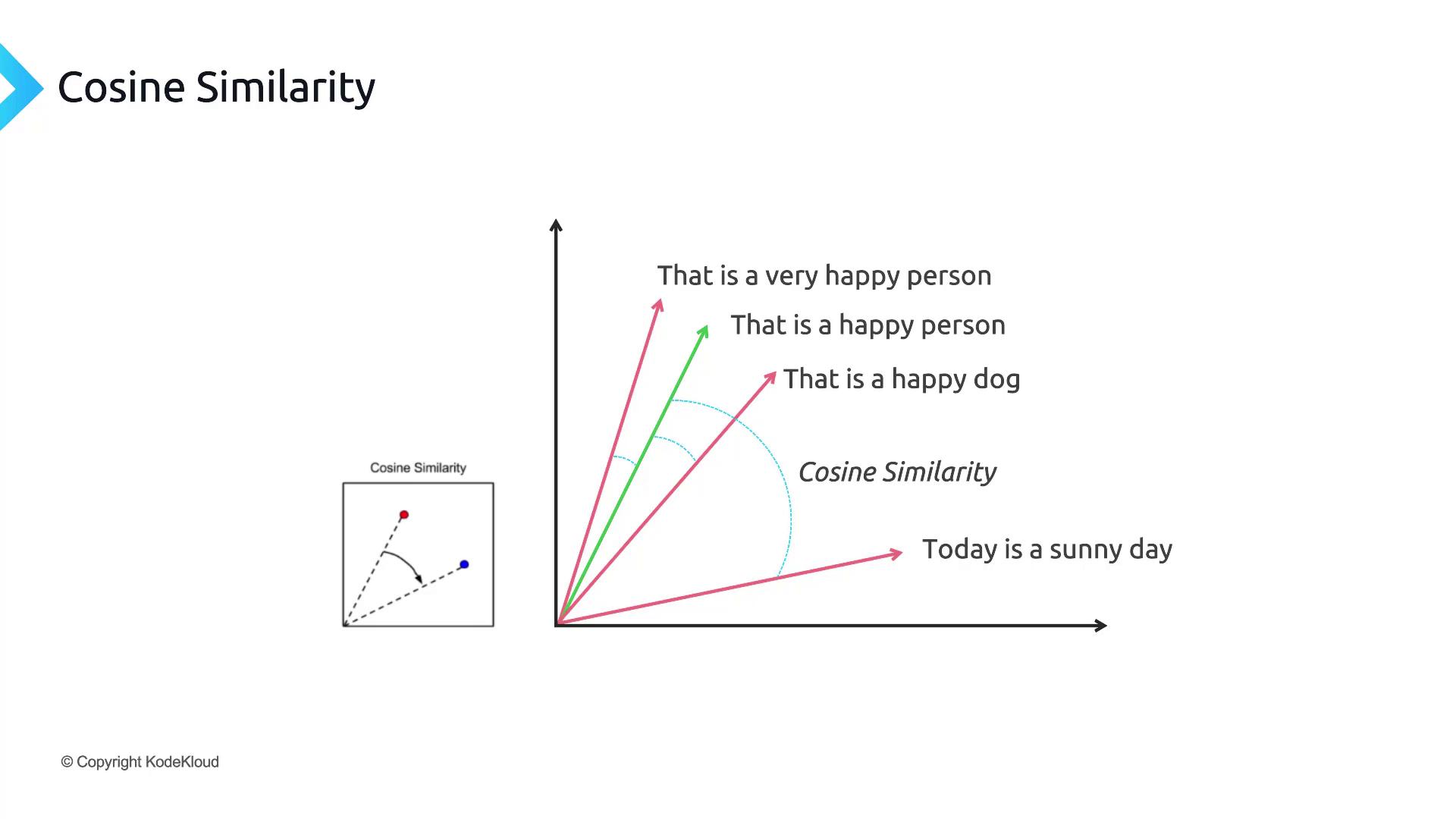
| Similarity Range | Interpretation |
|---|---|
| 0.9 – 1.0 | Nearly identical meaning |
| 0.5 – 0.9 | Related concepts |
| 0.0 – 0.5 | Weak or no relation |
| Negative values | Opposing or dissimilar topics |
Semantic Search with Embeddings
Traditional keyword-based search can miss relevant results when phrasing differs. Semantic search converts both queries and documents into embeddings and retrieves items whose vectors lie closest to the query vector. Instead of exact string matches, semantic search finds content by meaning, powering applications like:- Document retrieval
- FAQ matching
- Contextual recommendation
Generating Embeddings with OpenAI
Below is an example of how to generate embeddings using the OpenAI Python SDK:Keep your API keys secure. Never expose them in client-side code or public repositories.