Foundation models may produce biased, inaccurate, or unsafe outputs if not properly monitored. Always implement human-in-the-loop review and adhere to ethical AI frameworks.
Training Data and Capabilities
Foundation models are typically pre-trained on massive datasets tailored to each modality:- Text: Web text, Wikipedia, books
- Images: Public domain image collections, extensive visual datasets
- Audio/Video: Speech corpora, video repositories
Multimodal Support
Many foundation models handle multiple modalities—text, images, video, and audio—enabling seamless cross-modal applications.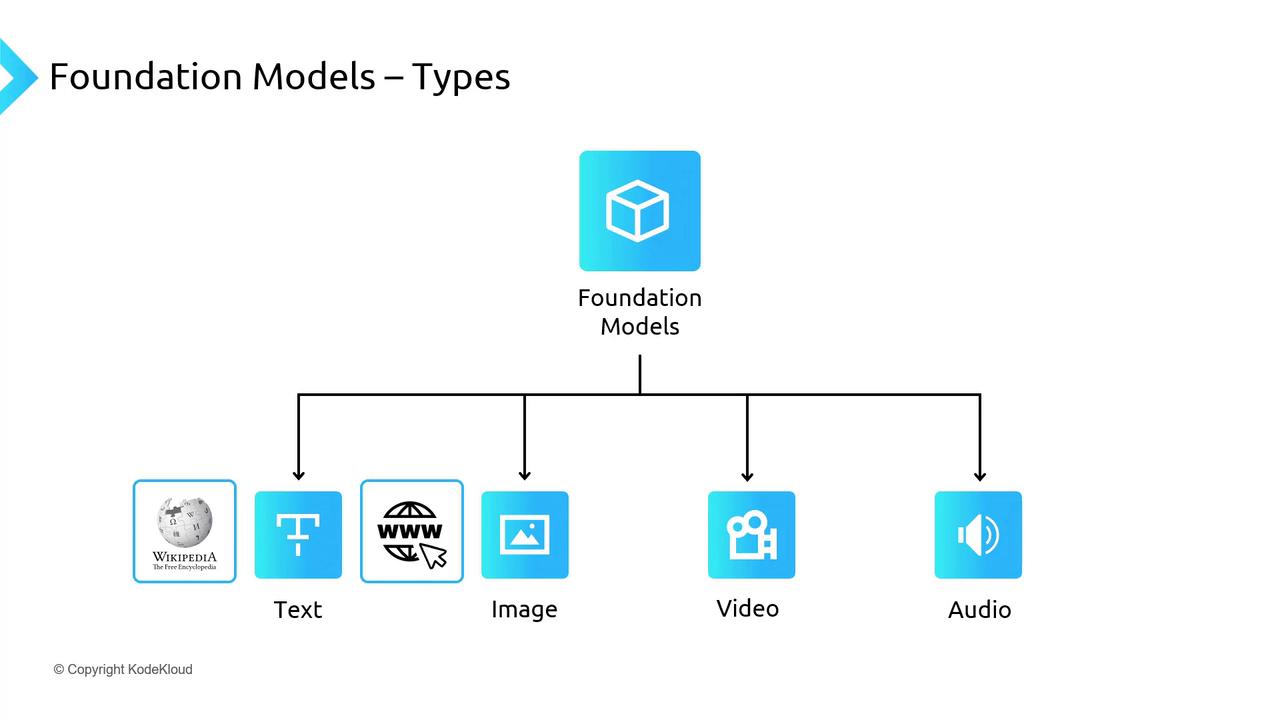
Multimodal models can be extended to new domains by fine-tuning on task-specific datasets, such as adding domain-specific images or specialized speech recordings.
Common Use Cases
After pre-training, foundation models can be adapted to a wide array of scenarios: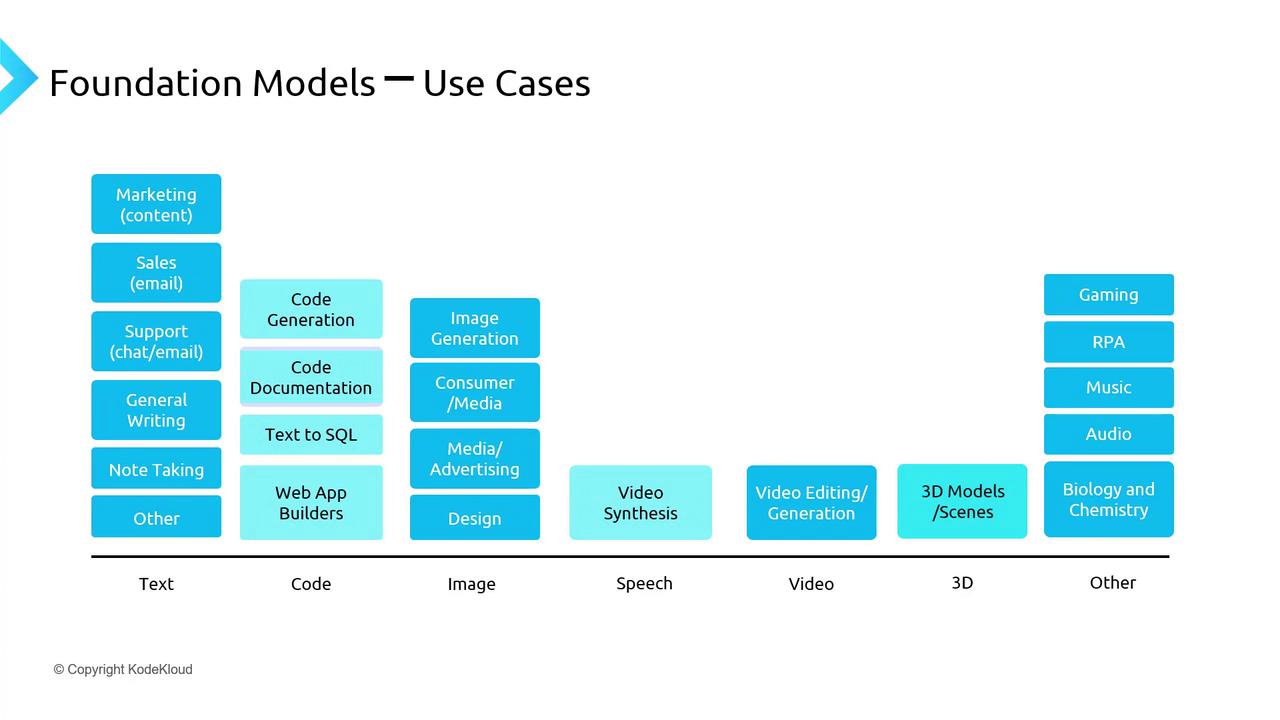
| Category | Example Applications |
|---|---|
| Text | Blog writing, summarization, translation |
| Code | Completion, refactoring, generation |
| Images | Captioning, generation, upscaling |
| Speech | Transcription, synthesis |
| Video | Resolution enhancement, video synthesis |
| 3D | Modeling, rendering |
| Other | Entity extraction, diagnostics, knowledge retrieval |
Real-World Applications
Generative AI powered by foundation models is already transforming industries:
- ChatGPT: Conversational AI for interactive text generation
- GitHub Copilot: Contextual code suggestions within developer tools
- MidJourney: Photorealistic image generation from textual prompts
- Runway: AI-driven video editing, synthesis, and VFX
Getting Started with OpenAI Foundation Models
Ready to build your own applications? Begin by exploring the OpenAI API documentation for guides on authentication, model endpoints, and best practices. Sign up for an API key, experiment with prompts, and fine-tune models to suit your use case.Links and References
- OpenAI API Documentation
- Generative Pre-trained Transformer – Wikipedia
- Stanford CRFM on Foundation Models