Core Components of Prometheus
Prometheus is built around three primary components:-
Data Retrieval Worker
This component is responsible for scraping metrics data from targets. It sends HTTP requests to the designated endpoints—typically at/metrics—to retrieve data, which is then forwarded for storage. -
Time Series Database
Collected metrics are stored in a time series database. This database maintains all numerical data, allowing for efficient retrieval and analysis over time. -
HTTP Endpoint
The built-in HTTP endpoint serves dual purposes:- It allows users to execute queries using PromQL.
- It supports visualization and further analysis through tools like the Prometheus web UI and Grafana.
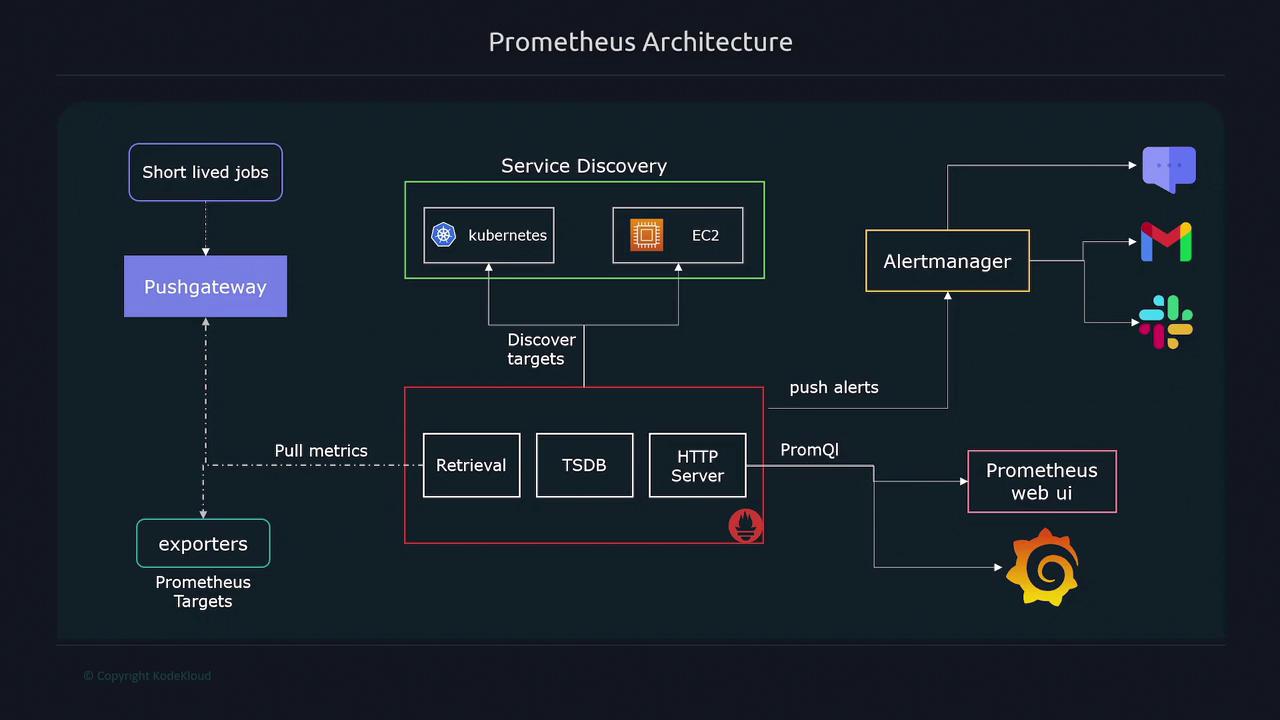
/metrics endpoint of each target. For targets that expose metrics at an alternative URL, you can easily adjust your Prometheus configuration to accommodate the change.
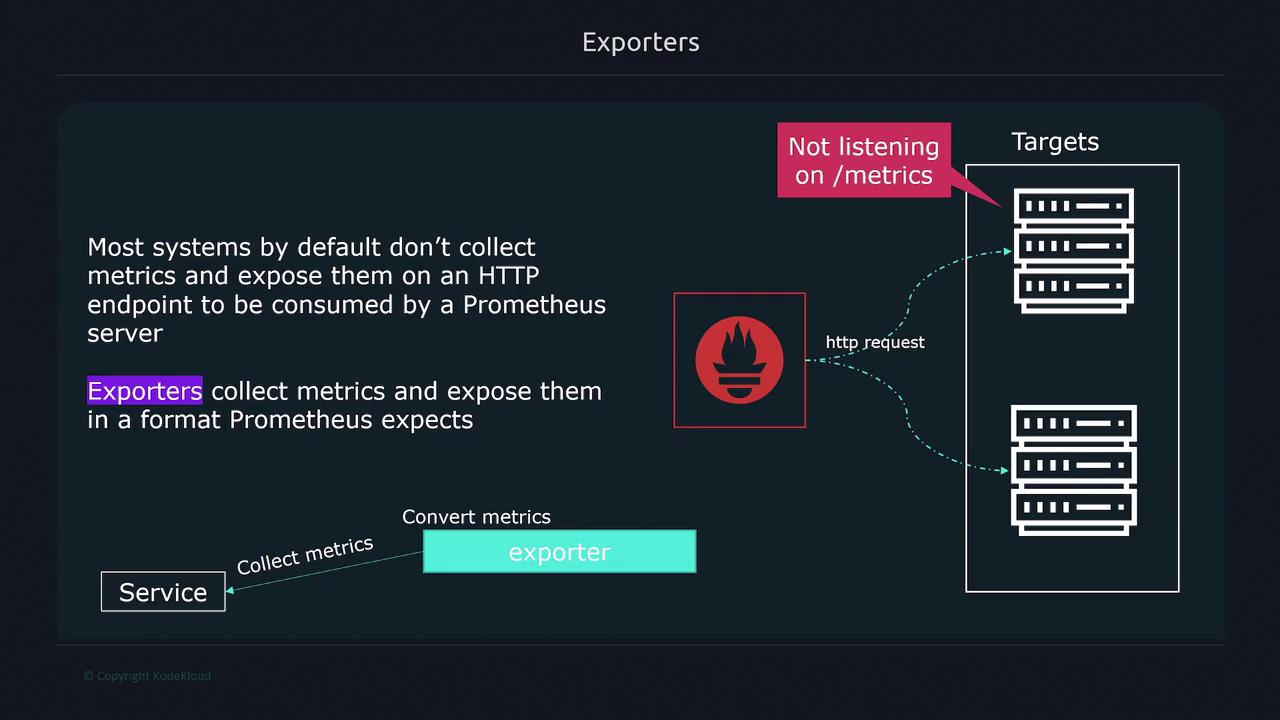
Exporters
In many cases, applications and servers do not natively expose metrics in a format that Prometheus can parse. Exporters serve as the bridge in these situations. They:- Collect metrics from a designated system, service, or application.
- Translate internal data into a format that Prometheus understands.
- Expose the metrics via a
/metricsendpoint for Prometheus to scrape.
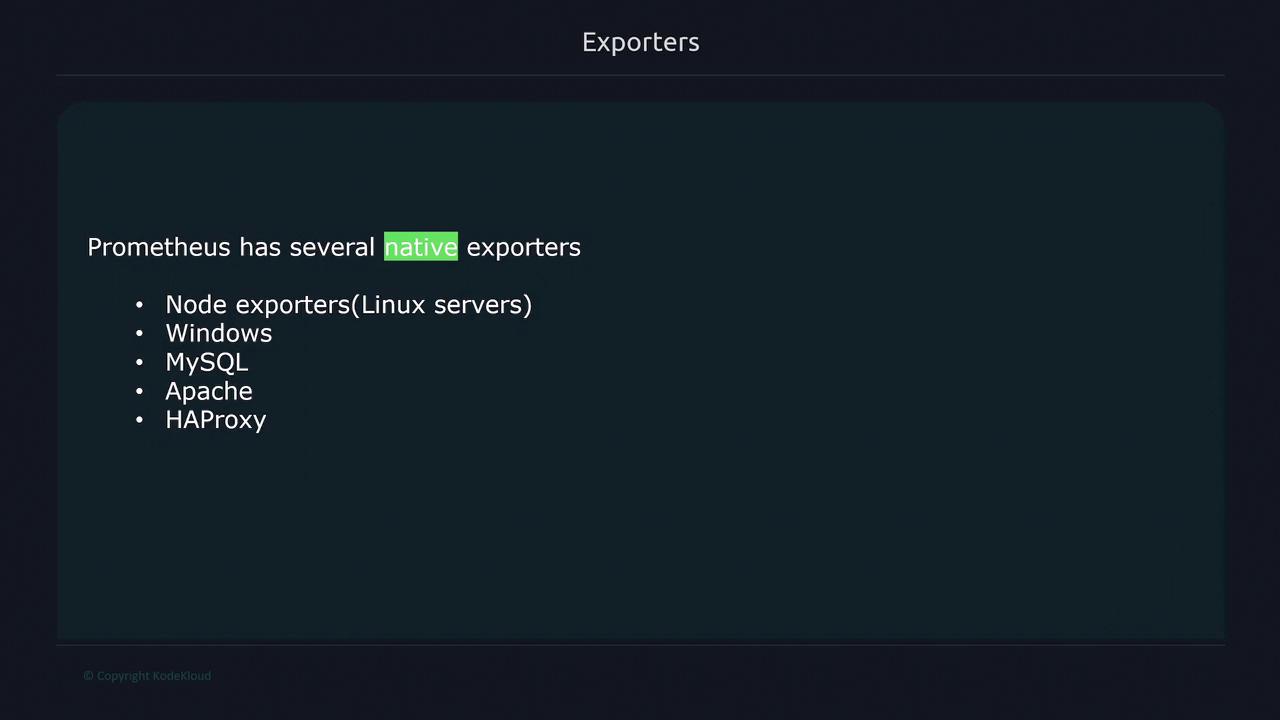
- Node Exporter for Linux server metrics.
- Exporters for Windows, MySQL, Apache, HAProxy, and more.
Custom Application Metrics
For scenarios where you need to monitor custom application metrics—such as error rates, request latency, or process execution time—Prometheus offers a range of client libraries. These libraries support popular programming languages including Go, Java, Python, Ruby, and Rust, among others. Third-party libraries extend support to even more languages, enabling you to instrument your application without extra overhead.
How Prometheus Discovers Targets
Prometheus operates primarily on a pull-based model, actively scraping metrics from a predefined list of targets. This list can be configured manually or dynamically populated using service discovery mechanisms in environments such as Kubernetes or cloud infrastructures. This pull-based approach delivers several benefits:- Clear Target Visibility: It immediately identifies when a target is down.
- Centralized Monitoring: Keeps a definitive list of all monitored targets.
- System Protection: Helps prevent potential overload of the metrics server.

Comparing Pull and Push Models
While Prometheus is fundamentally designed around the pull model, understanding both approaches is essential:- Pull-Based Model
Prometheus scrapes data directly from targets, which ensures:- Every target is known and consistently monitored.
- Verification of target availability during each scrape cycle.

-
Push-Based Model
In contrast, the push-based model requires targets to actively send data to a monitoring server. This model is particularly useful for:- Event-driven systems.
- Short-lived jobs that might not be available during scraping cycles.
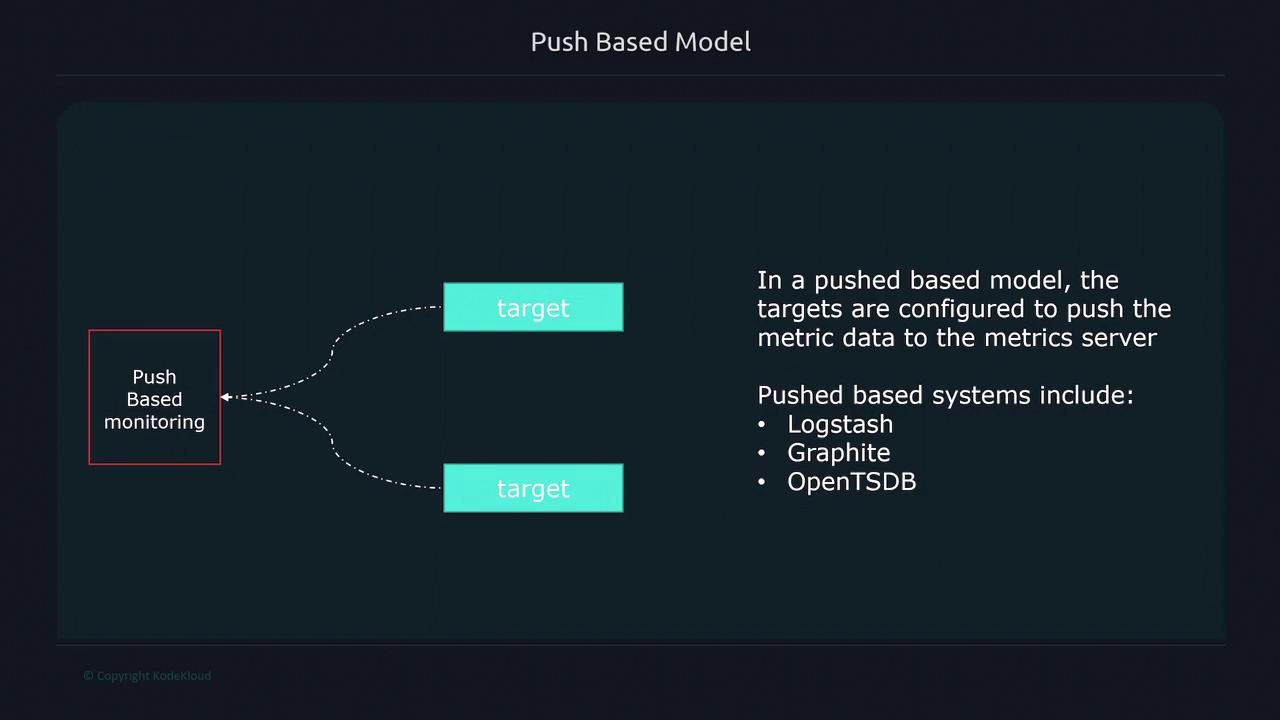
When using the push-based model, consider integrating the Pushgateway to bridge the gap for transient jobs. This ensures that even metrics from short-lived processes are captured accurately.
