- The original project and its initial data model
- A real Chevrolet small‑block casting CSV (target dataset)
- Crafting prompts to refactor the app to the new schema
- Running the migration and handling errors
- Validating the refactored API
Project background and original model
The original SQLAlchemy model used generic fields (material, weight, manufacturer, etc.). That general shape doesn’t match the Chevrolet small‑block casting CSV we want to ingest, which uses fields like Years, Casting, CID, factory power ratings, and notes about main caps or comments. Original SQLAlchemy model:Why this matters
Chevrolet casting datasets are organized around production years, casting IDs, displacement (CID), factory power ranges, main cap counts, and free‑form comments. For salvage or parts selection, these attributes are more important than generic material/weight fields. For example, casting330817 corresponds to engines built 1973–1980 with two‑bolt mains and use in cars and trucks—details that determine interchangeability.
Example: sample generic CSV (incorrect for this domain)
Below is the simple CSV Cline initially inferred from the original model—note it’s the wrong shape for Chevrolet casting information:Target dataset: Real Chevrolet casting CSV
This is the actual Chevy small‑block CSV format we want to adopt. Notice fields oriented to engine specs and application context:Mapping the change: old model → new schema
Use this table to anchor the refactor mapping between the original generic model and the Chevrolet casting schema:Prompt design principles used in this lesson
- Intention first, not syntax first — describe what you want (the refactored schema and behavior) rather than low‑level implementation steps.
- Anchor with context — provide example rows and the target schema so the assistant can reliably infer field mappings.
- One‑shot vs iterative prompts — show a one‑shot example and demonstrate a Plan → Act workflow for large refactors to reduce risk.
Crafting the refactor prompt
Context files provided to the assistant:chev-casting.csv(target data)- example CSV(s) and current codebase snapshot
- Refactor the application to ingest the Chevrolet schema.
- Update models, Pydantic schemas, import utility, CRUD functions, and migrations.
- Provide a migration plan (alter in place or drop/recreate + reimport).
- Show example mappings: a current row and a desired target row.
Messy input example (real CSV pitfalls)
Real CSVs can have inconsistent quoting, missing headers, or unnamed columns. The import utility must be defensive. Example of messy rows:Refactor plan and the assistant’s plan-mode output
The assistant’s plan-mode outline included:- Inventory of the current application: data model, DB, API endpoints, import utility.
- New requirements:
years,casting,cid,low_power,high_power,main_caps,comments. - Files to update: SQLAlchemy models, Pydantic schemas, import utilities, CRUDs, migration scripts.
- Migration approach: either alter existing tables or drop and recreate followed by a reimport.
Applying the plan (Act mode) and migration issues
In Act mode the assistant implemented changes—updated SQLAlchemy model, Pydantic schemas, created a defensive import utility and attempted a migration. During migration a CSV parsing issue (an unnamed column) caused a model instantiation error: Example migration trace (cleaned):- Inspect and drop unnamed or empty CSV columns before creating model instances.
- Add a cleaning step in the import utility to remove columns with no header.
- If schema drift is significant, consider resetting the DB and reimporting (only in development or with backups in production).
Improved model (refactored)
The refactored SQLAlchemy model now mirrors the Chevrolet CSV:Pydantic schemas and API changes
Schemas were updated to match the new fields and to use Pydantic v2 ergonomics:orm_mode setting is replaced by from_attributes. The assistant updated schemas accordingly to ensure FastAPI can return ORM models as Pydantic objects.
Import utility and cleaning strategy
Make the CSV import robust:- Use pandas to read CSV robustly (
pd.read_csv(..., dtype=str)). - Drop columns where header names start with
Unnamed. - Normalize column names (lowercase, strip whitespace) and map them to expected fields.
- Coerce numeric fields (
cid) with safe casting andNaNhandling. - Handle duplicates via skip or upsert logic based on
castinguniqueness.
- Load CSV as strings to avoid silent numeric coercion.
- Drop unnamed/empty headers.
- Rename columns to the expected schema.
- Validate rows and coerce types.
- Insert with upsert/skip duplicate semantics.
Reset and re-import script
Because in-place ALTER migrations failed in this iteration, a reset script was provided to drop and recreate tables and reimport the cleaned Chevrolet CSV. This is useful for development and iterative testing—do not run in production without backups. Example reset/import script skeleton:Note on virtual environments and dependencies
Make sure your virtual environment is activated before running installs or migrations. If a script requires newer packages, update them inside the venv:
Running the app and validating the API
After refactor and import, the FastAPI app exposes Swagger UI at/docs. Common endpoints:
- GET /api/castings/
- GET /api/castings?skip=…&limit=…
- POST /api/castings
API docs screenshot
Here’s the API documentation (Swagger / OpenAPI) showing the GET /api/castings endpoint and the interactive “Try it out” control: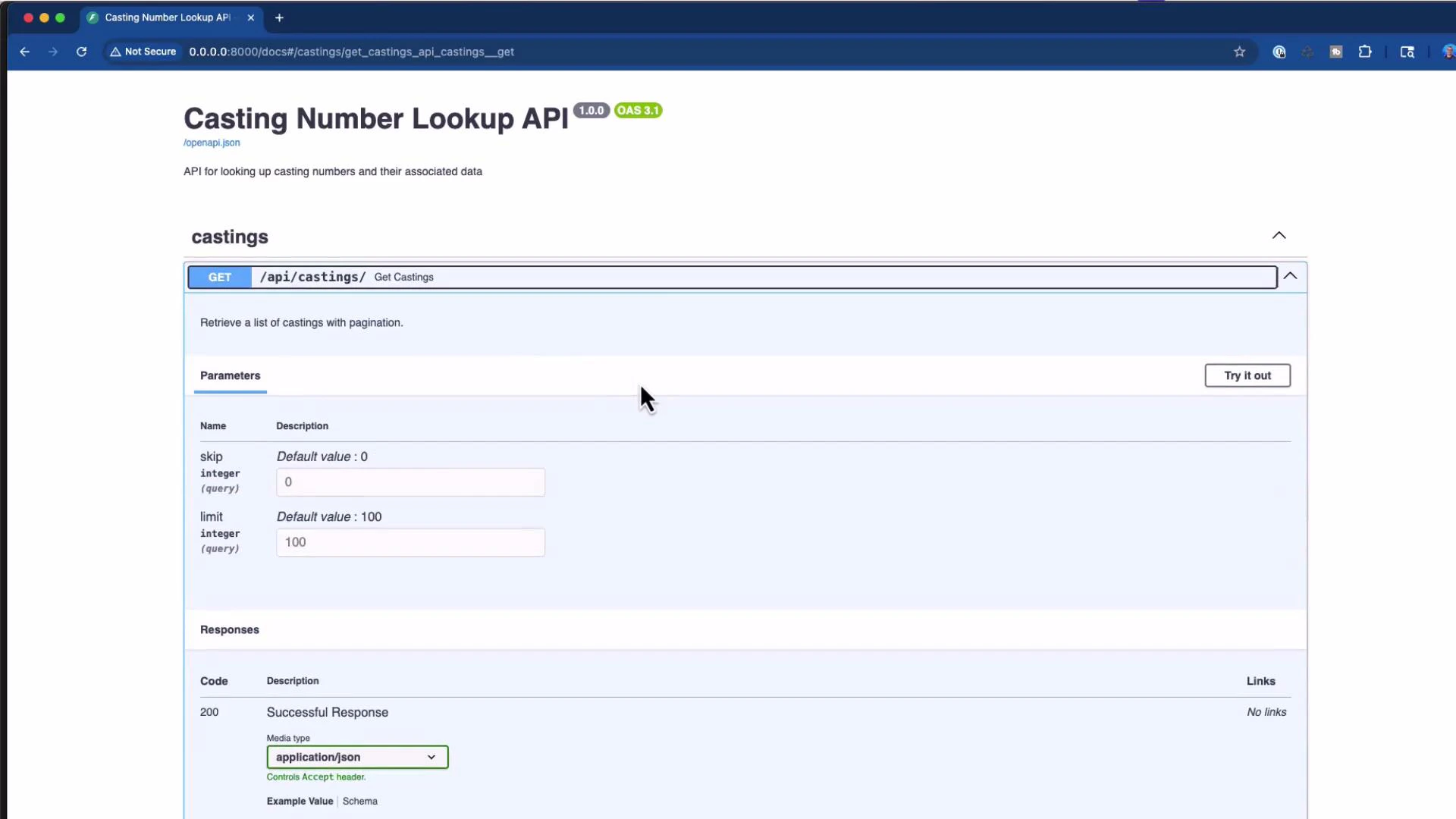
Troubleshooting and iteration
When migrations fail because of unnamed CSV columns or UNIQUE constraint conflicts:- Drop unnamed columns produced by malformed CSVs.
- Add a cleaning pass in the import utility to normalize headers and drop empties.
- Use Plan → Act workflow: validate the assistant’s plan before applying large structural changes.
- For repeated in-place migration failures, use a reset + reimport workflow in development and keep backups for production.
Screenshot: diagnosing UNIQUE/CSV issues
The assistant diagnosed a UNIQUE constraint / CSV header problem and the developer fixed it in the CSV/editor: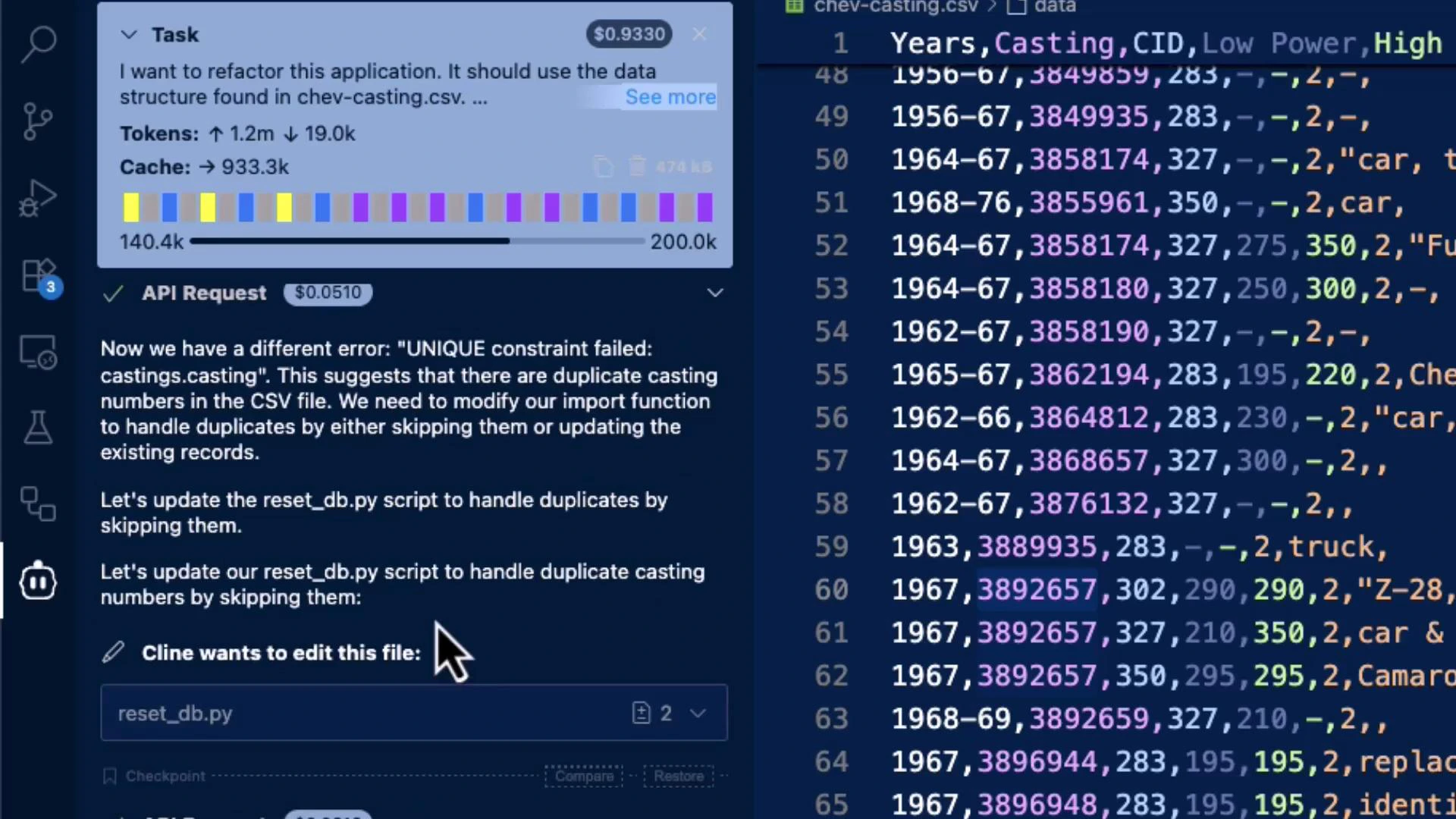
Plan vs Act workflow
Recommended workflow for large codebase changes:- Plan mode: ask the assistant to produce a refactoring plan (files to change, mapping, migration approach) and review the plan.
- Act mode: have the assistant apply changes, update files, run migrations, import data, and start the server.
- Iterate: address issues uncovered during Act mode (CSV quirks, duplicates, type errors), update the plan, and re-run.
Key takeaways
- Start prompts with intent — describe the desired result, not every implementation detail.
- Anchor the assistant with example inputs and the target output schema to reduce ambiguity.
- When changing a data model, update models, schemas, import utilities, migrations, and API endpoints consistently.
- Add robust CSV cleaning steps (drop unnamed columns, normalize headers) to handle messy real‑world data.
- Use Plan mode to review the assistant’s proposed changes, then switch to Act mode to apply them.
- Validate the API with Swagger or curl and test edge cases (duplicate rows, malformed CSVs).
Next steps and extension ideas
Consider extending the application with:- Fuzzy matching on casting numbers (tolerant search)
- Mobile-friendly web UI for quick lookups in junkyards
- Batch import with validation reports and error summaries
- Caching layers for frequently queried castings
References
- SQLAlchemy: https://www.sqlalchemy.org/
- Pandas: https://pandas.pydata.org/
- FastAPI: https://fastapi.tiangolo.com/
- Pydantic v2: https://docs.pydantic.dev/latest/