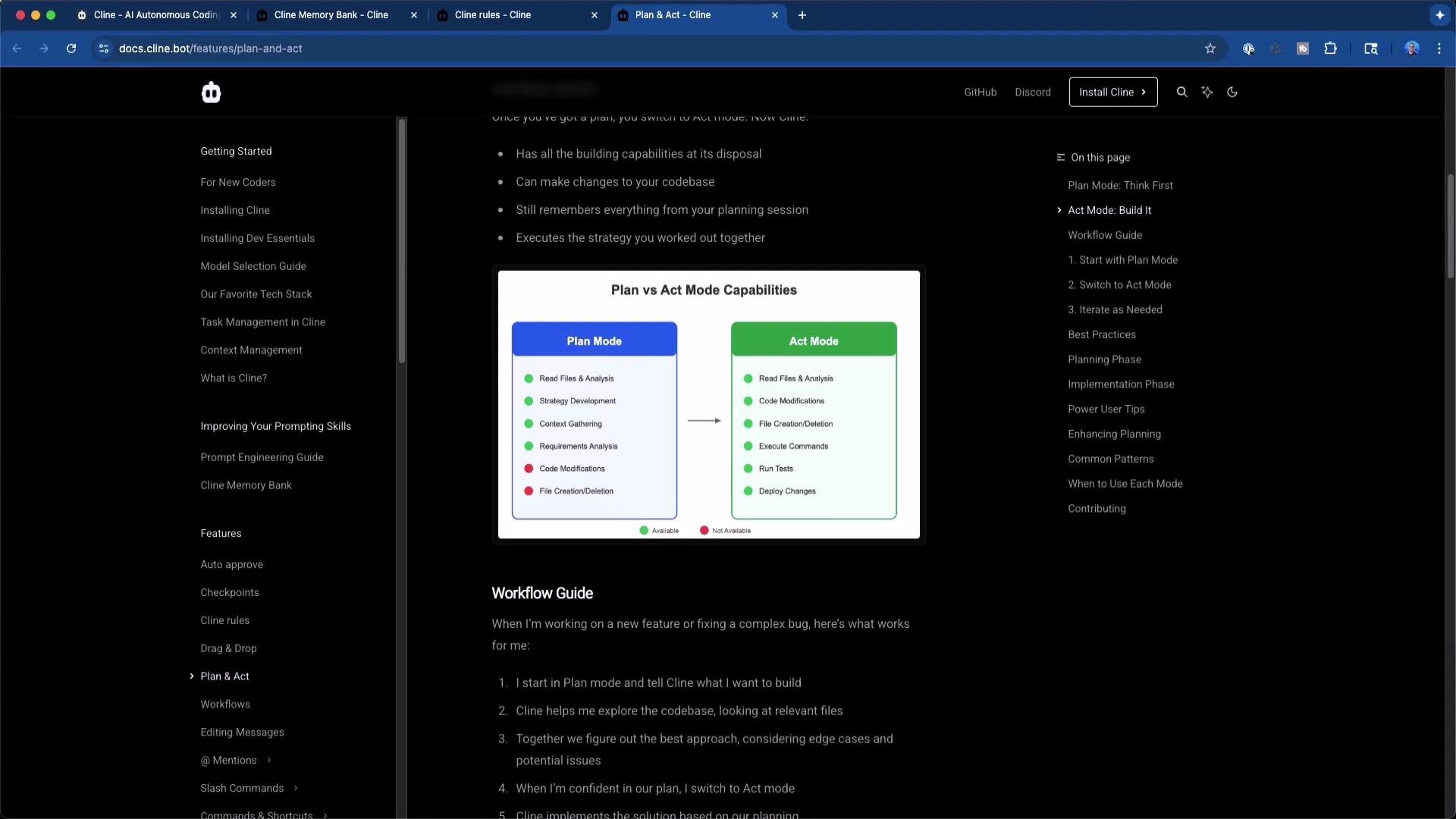
Plan mode is for analysis, architecture, and step-by-step strategy (no file changes). Act mode performs the actual modifications and commands when you’re ready.
- Consumer sends an integer casting number; API returns metadata for that number.
- Data persisted in SQLite.
- Implementation in Python + FastAPI.
- CSV import for bulk data.
- Start in Plan mode and provide a clear task prompt. Example goals:
- Build a FastAPI service to expose casting lookup endpoints.
- Use SQLAlchemy with SQLite for persistence.
- Provide a CSV import utility to populate the DB.
- Add Pydantic schemas, basic validation, and tests.
- Create a standard FastAPI project layout.
- Add SQLite + SQLAlchemy database setup.
- Build SQLAlchemy models matching the CSV schema.
- Create import script to ingest CSV into DB.
- Implement API endpoints for list and single lookup.
- Add tests and a small runner to execute them.
- Review and approve the plan. In Act mode, Cline can create the skeleton and files. For example, the initial shell command to create a typical FastAPI layout:
- The assistant may repeatedly create or modify the same files if prompts or tests keep triggering new edits.
- Large numbers of edits increase context size and token usage, raising costs.
- Applying changes without reviewing diffs may introduce regressions.
Warning: Act mode can loop (creating tests to test tests, repeatedly editing files). Monitor the sequence of edits, review diffs, and limit or stop the workflow if it becomes repetitive to avoid unnecessary costs and regressions.
- Prefer Plan mode when you want to review and understand every change; export the plan and implement it manually or selectively accept Act steps.
- If using Act mode, inspect diffs, run tests frequently, and approve batches of related changes rather than single-file edits in isolation.
- Disable intrusive inline suggestions in your editor; trigger the assistant intentionally when ready.
- If the model repeatedly fails a step, step in manually and consult resources like Stack Overflow or official docs for the specific library.
- A FastAPI application with routes and middleware.
- Database layer using SQLAlchemy + SQLite.
- Models and Pydantic schemas for validation.
- A CSV import utility to populate the database.
- Tests, runners, and CI-friendly scripts.