This guide explores transformer architecture and its essential role in generative AI, covering core components and real-world applications.
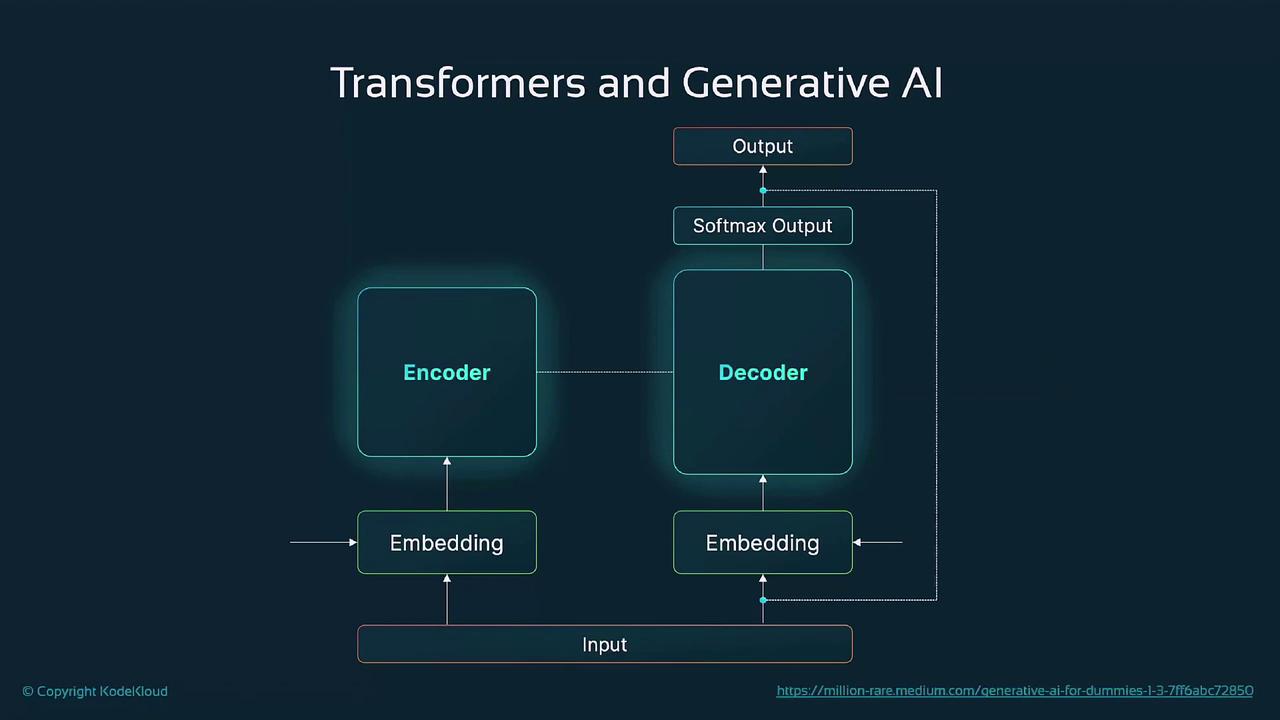
In this guide, we’ll dive into the transformer architecture and its critical role in modern generative AI. We start with an overview of the encoder–decoder design, break down core components like self-attention, multi-head attention, and positional encoding, then demonstrate how transformers underpin models such as GPT and DALL·E. Finally, we’ll explore real-world use cases that showcase their versatility.
Before transformers, RNNs and LSTMs processed tokens sequentially, which limited long-range dependency capture and slowed down training. Transformers introduced self-attention, allowing all tokens to interact simultaneously and harness parallel hardware like GPUs/TPUs.
Benefit
Description
Self-Attention
Models the relationships between any two tokens in the sequence, regardless of distance.
Parallelization
Processes entire sequences at once, drastically reducing training and inference time.
Scalability
Easily scales to billions of parameters, handling massive datasets efficiently.
Cross-Domain Use
Extends beyond NLP to images, audio, code, and more, thanks to its flexible architecture.
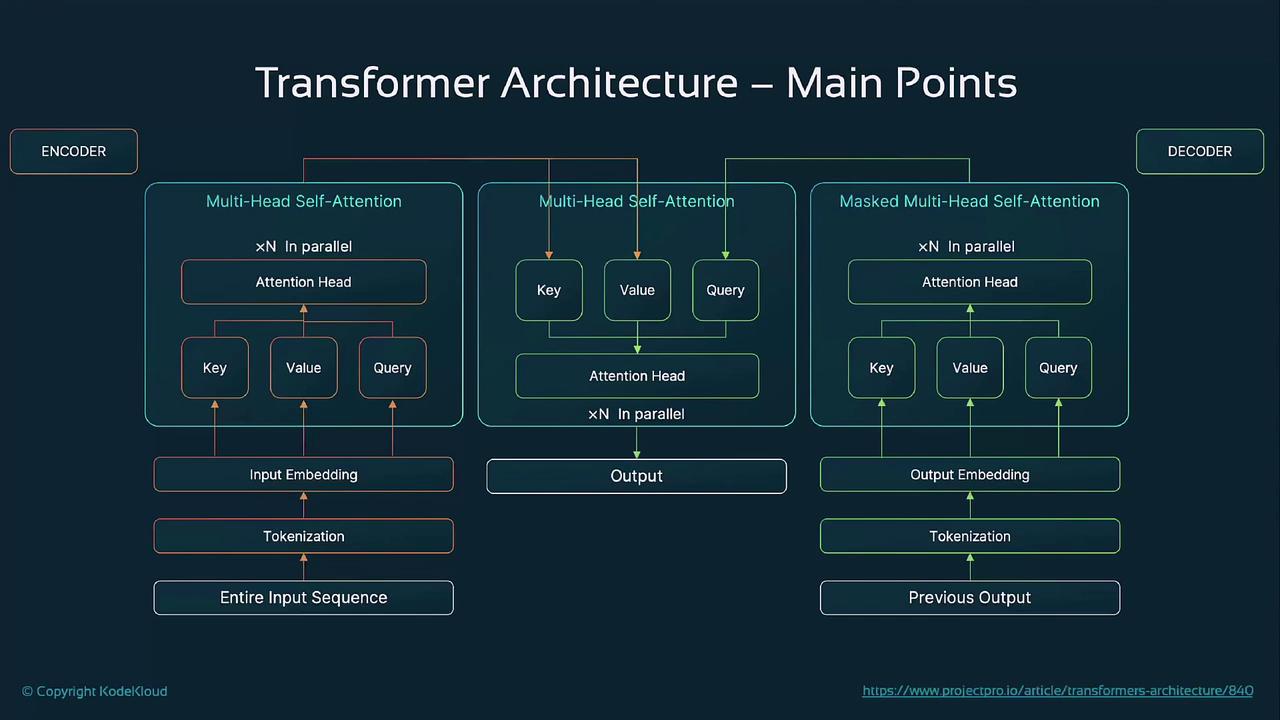
Self-attention computes attention scores by projecting token embeddings into query, key, and value vectors, enabling the model to weigh the importance of each token pair in a single step.
Multiple attention “heads” run in parallel, each learning different relationships. Their outputs are concatenated and linearly transformed, improving representation richness.
Since attention is position-agnostic, transformers add sinusoidal positional encodings to embeddings. This injects information about token order without requiring recurrence.
Training large transformer models can demand hundreds of GPUs/TPUs and vast memory. Ensure you have sufficient compute resources before scaling up.
Generative AI synthesizes new data—text, images, code, audio—by learning patterns from large datasets. Unlike traditional AI, which focuses on classification or prediction, generative models create novel content.
Transformer-based models like GPT-4 use a next-token prediction objective:
Pre-training
The model learns to predict the next token across billions of text sequences, capturing grammar, facts, and reasoning patterns.
Fine-tuning or Direct Use
After pre-training, you can specialize the model on domain-specific data or use it directly for tasks such as summarization, translation, or creative writing.
Generation
At inference, self-attention considers the full prompt context, and a softmax layer chooses each next token to produce coherent, contextually relevant output.
Transformers are at the heart of many production systems:
Domain
Use Case
Example
Text & Chatbots
Conversational AI
ChatGPT
Content Generation
Articles, social media copy
Automated marketing copy
Code Assistance
Auto-completion, refactoring
GitHub Copilot
Image Synthesis
Text-to-image generation
DALL·E
Marketing & Design
Ad creatives, mockups
AI-driven visual mockups
Transformers have reshaped AI by enabling models that learn from massive data, understand intricate context, and generate high-quality content across domains. Their efficiency, scalability, and adaptability make them the cornerstone of today’s generative AI landscape.