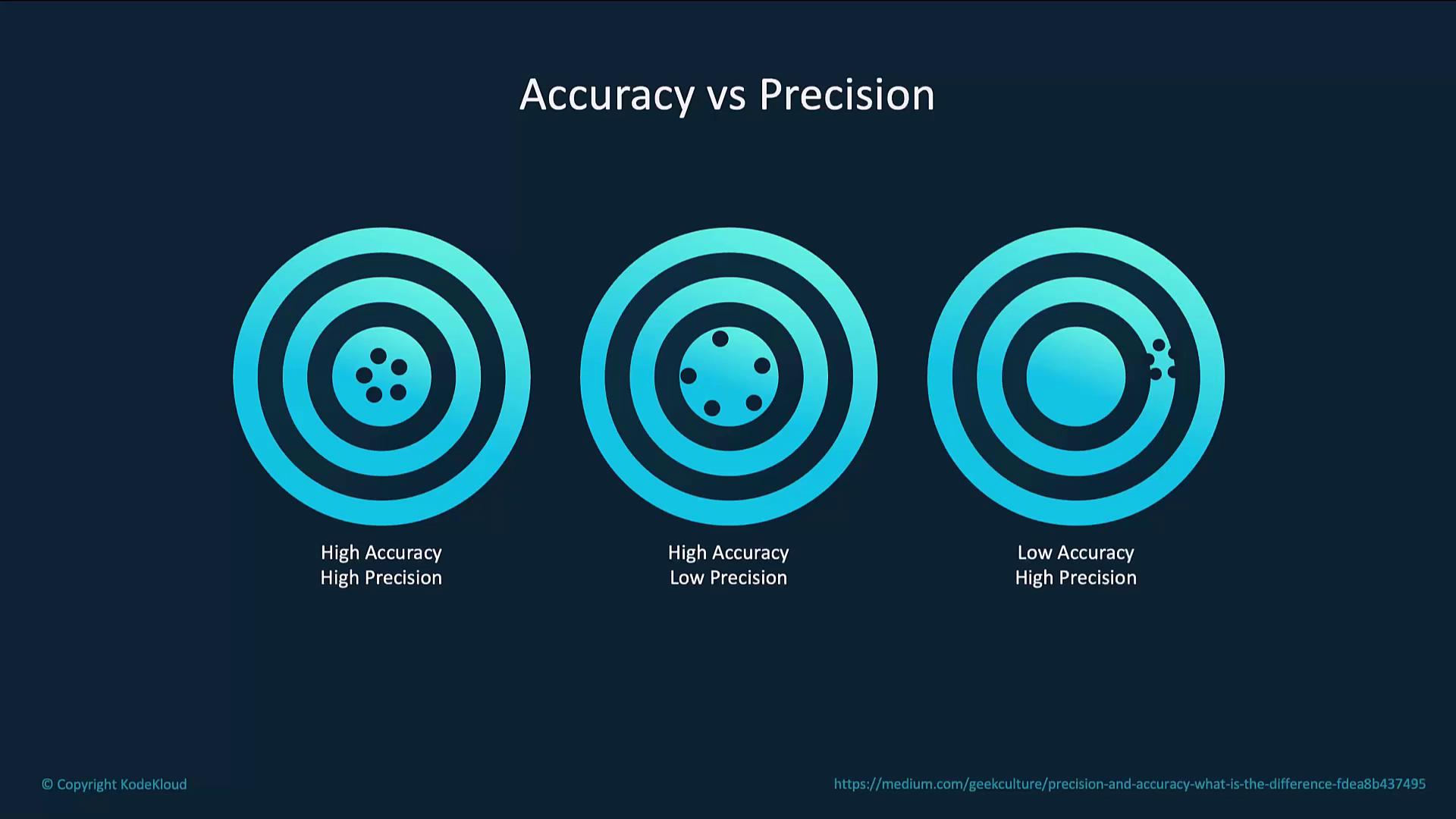
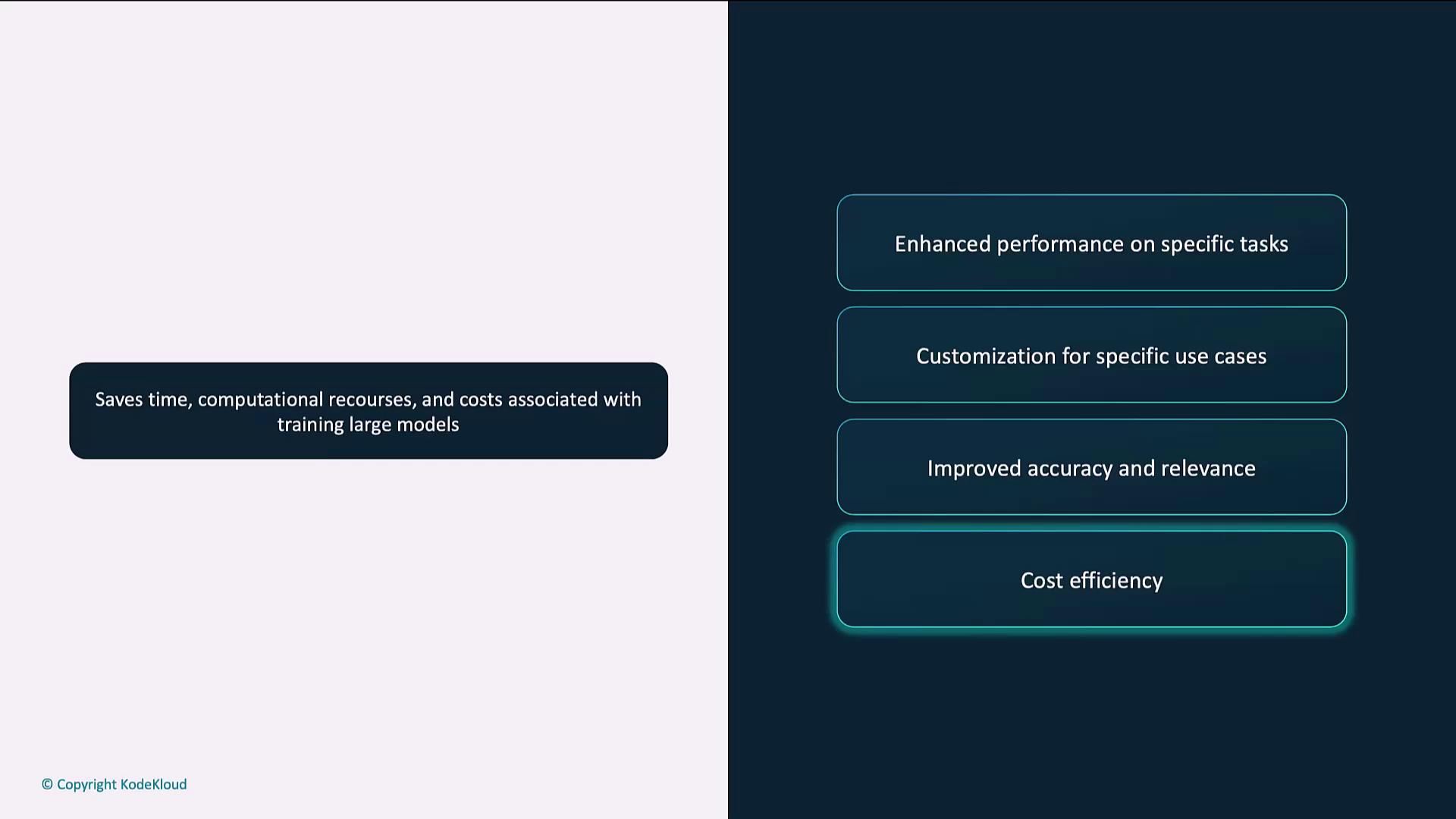
Fine-tuning enhances pre-trained language models for specific tasks, improving relevance, accuracy, and efficiency without starting from scratch.
Fine-tuning teaches a pre-trained language model to excel on your specific tasks. By training on a domain-focused dataset, you improve relevance, accuracy, and cost efficiency without starting from scratch.
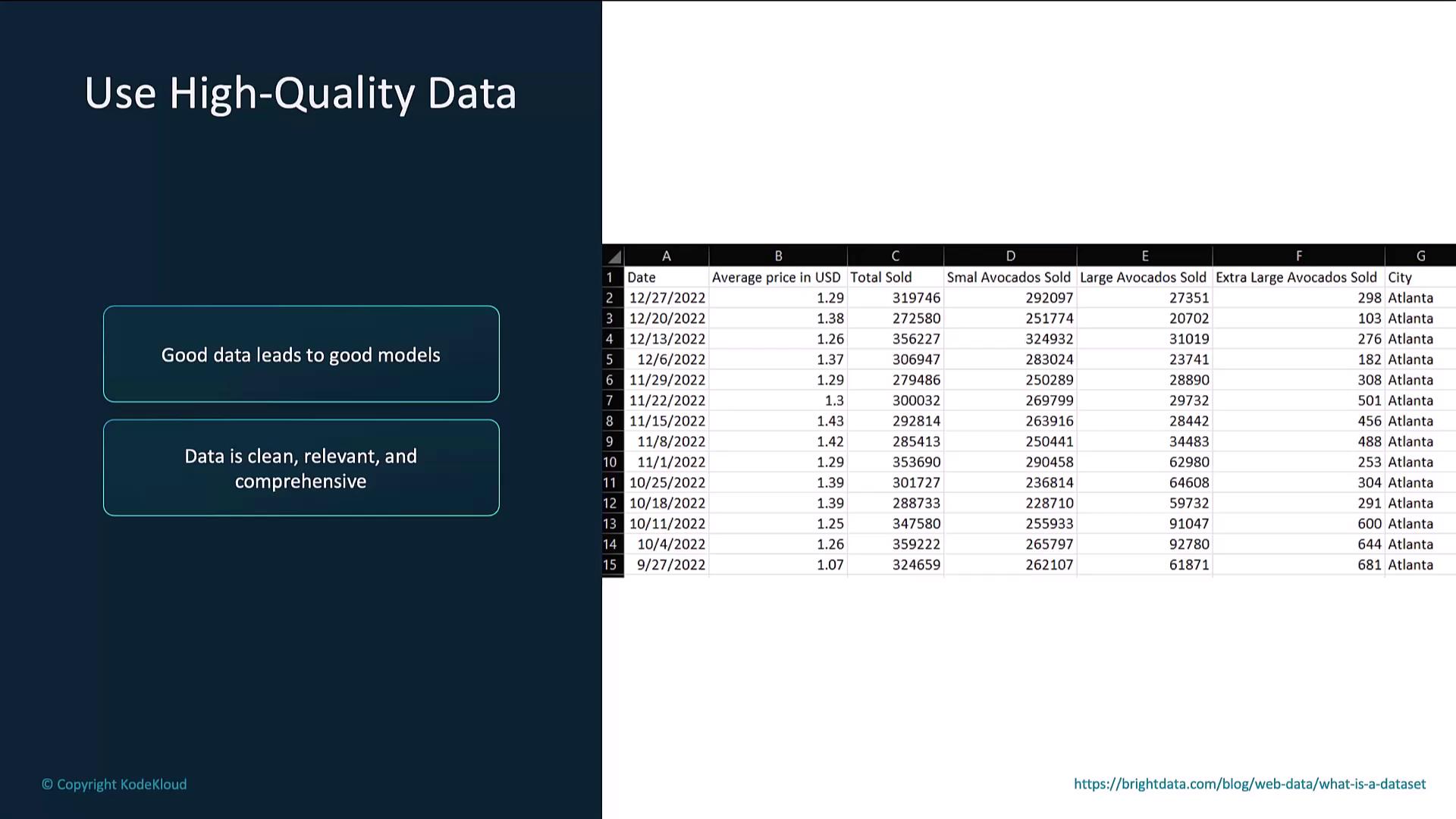
Each line in a JSONL file should contain a prompt and completion object.
{"prompt": "Generate a confidentiality agreement clause:", "completion": "The Parties agree to keep all information confidential..."}{"prompt": "Create a termination clause for a contract:", "completion": "This Agreement may be terminated by either party upon written notice..."}
Ensure your JSONL file follows the JSONL specification and that prompts/completions accurately reflect your target style.
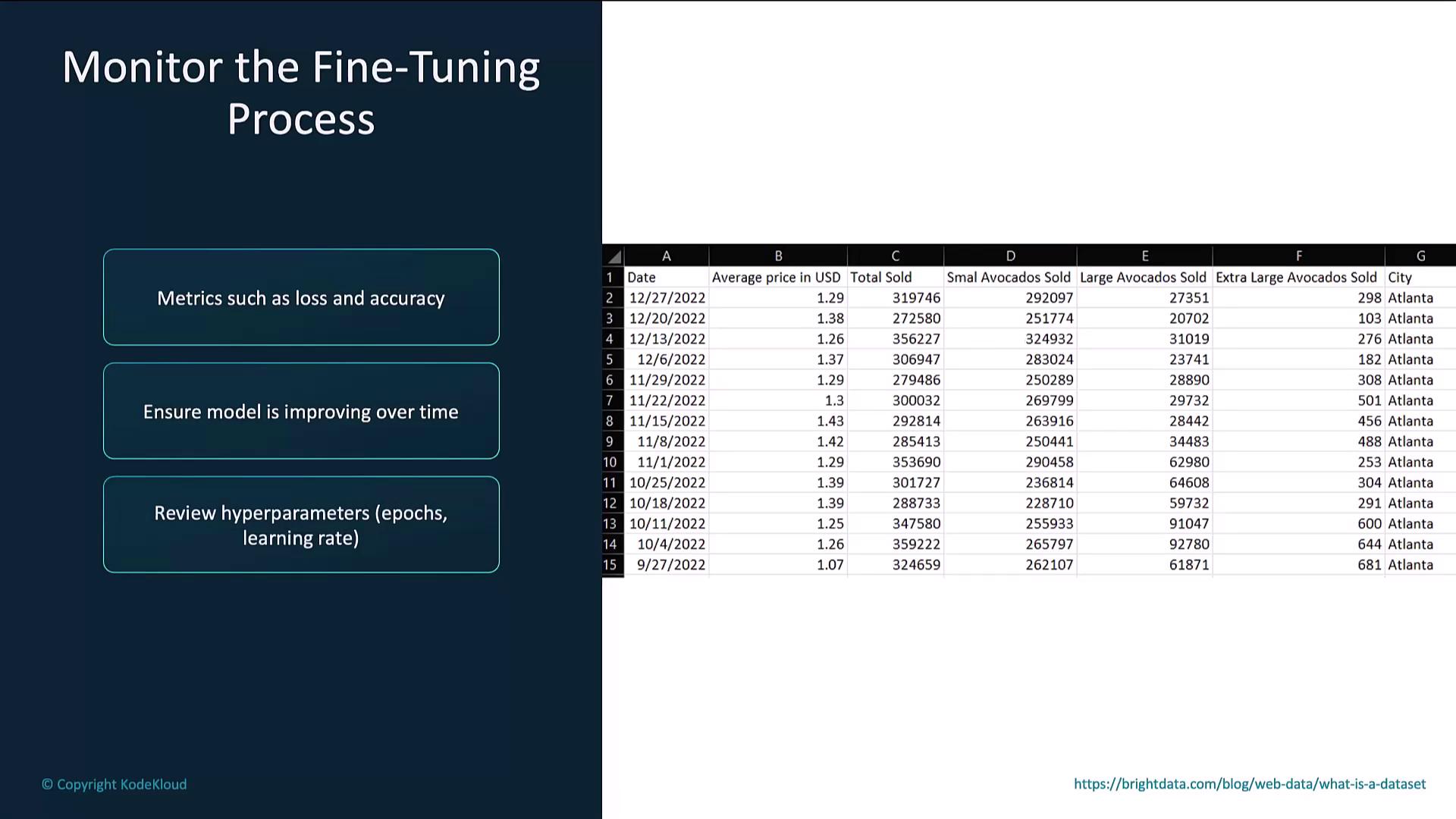
After fine-tuning, send test prompts to verify performance.
from openai import OpenAIclient = OpenAI()completion = client.chat.completions.create( model="your-fine-tuned-model-id", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Write a haiku about recursion in programming."} ])print(completion.choices[0].message.content)